Amazon Web Services ブログ
Amazon Timestream でのマルチメジャーレコード、マグネティックストレージへの書き込み、スケジュールドクエリを利用した時系列データの格納と分析
時系列は特にアプリケーションやインフラストラクチャー、IoT デバイス等から情報を収集する際の一般的なデータフォーマットの 1 つです。Amazon Timestream はサーバレスの時系列データベースであり、格納するデータに合わせてスケールし、一般的なリレーショナルデータベースよりもはるかに低コストでイベントの保存や分析が可能です。AWS re:Invent 2021 で Timestream は多くのユースケースにおいて有用な新しい機能のアップデートを発表しました。
- マルチメジャーレコード – Timestream に複数のメジャー値を書き込めるようになりました。データの書き込みが簡単になり、より多くのユースケースで扱うレコードの数が減る事になります。例えば、同じソースから同じ時間に放出された複数のメトリックを追跡する際にマルチメジャーレコードを使用出来ます。また、リレーショナルデータベースから Timestream へのデータ移行を考える際に、マルチメジャーレコードであればスキーマの変更が多くの場合不要となる為、Timestream へのデータ移行が簡単になるというメリットもあります。
- マグネティックストレージへの書き込み – Timestream はデータのライフサイクルを直近データのメモリストアと履歴データのマグネティックストアという 2 つのストレージ階層で管理しています。メモリストアからマグネティックストアへのデータの移動は設定したポリシーに応じて自動的に実施されます。以前はデータはメモリストアにしかロード出来ず、遅れて到着するデータを格納する為には、メモリストアの保持時間を拡張して対応する必要がありました。今回、直接マグネティックストアに書き込む事が出来るようになり、ストレージコストを削減する事が出来ます。
- スケジュールドクエリ – ダッシュボードやレポートを作成する際、ソースとなるテーブルに直接クエリを実行する代わりに、スケジュールされたクエリを実行して別テーブルに結果を格納する事が出来るようになりました。例えば、大規模なデータから頻繁に集約や合計の為のクエリを実行している場合、これらの結果を別テーブルに格納して、待ち時間とコストの削減が可能となります。
以上の新機能を様々なユースケースに適用してみましょう。
マルチメジャーレコードを使ったデータ形式の簡素化
Timestream の一般提供が開始された時には、サーバの CPU、メモリ量、スワップ、ディスクの使用状況を取得するシンプルな監視アプリケーションを作成しました。その際、4 つの測定値はシングルメジャーレコードのデータモデルを利用してそれぞれ別のレコードとして書き込んでいました。これをマルチメジャーレコードを使うと、4 つの測定値は同時に取得されるので、1 つのレコードとして格納され、まとめてクエリを実行する事が出来ます。
各サーバは、ホスト名と country 、city として表される場所により識別されます。このユースケースでは、データを分類するディメンジョンは全てのレコードで同じとなります。
countrycityhostname
収集するメジャーは以下の 4 つです。
cpu_utilizationmemory_utilizationswap_utilizationdisk_utilization
ここでは、新しい Timestream のデータベースとテーブルを作る為に、以下の AWS CloudFormation テンプレートを利用します。
AWSTemplateFormatVersion: '2010-09-09'
Description: Create a Timestream database and a table
Resources:
MyDatabase:
Type: AWS::Timestream::Database
MyTable:
Type: AWS::Timestream::Table
Properties:
DatabaseName: !Ref rDatabase
RetentionProperties:
MemoryStoreRetentionPeriodInHours: "24"
MagneticStoreRetentionPeriodInDays: "7"
Outputs:
DatabaseName:
Description: Timestream Database Name
Value: !Ref MyDatabase
TableName:
Description: Timestream Table Name
Value: !GetAtt MyTable.NameAWS CLI を利用して stack を作成します
aws cloudformation create-stack \
--stack-name devops-time-series \
--template-body file://template.yamlスタックが準備出来たら、マルチメジャーレコードを使ってデータをロードするようにアプリケーションを更新します。以前はタイムスタンプ毎に 4 つのレコードを挿入する必要がありましたが、全ての収集したメジャーを 1 レコードとして挿入する事が可能となっています。シングルメジャー用に作成していた collect.py アプリケーションをマルチメジャー用に以下のように更新しました。
import time
import boto3
import psutil
import os
from botocore.config import Config
DATABASE_NAME = os.environ['DATABASE_NAME']
TABLE_NAME = os.environ['TABLE_NAME']
COUNTRY = "UK"
CITY = "London"
HOSTNAME = "MyHostname" # You can make it dynamic using socket.gethostname()
INTERVAL = 1 # Seconds
def prepare_common_attributes():
common_attributes = {
'Dimensions': [
{'Name': 'country', 'Value': COUNTRY},
{'Name': 'city', 'Value': CITY},
{'Name': 'hostname', 'Value': HOSTNAME}
],
'MeasureName': 'utilization',
'MeasureValueType': 'MULTI'
}
return common_attributes
def prepare_record(current_time):
record = {
'Time': str(current_time),
'MeasureValues': []
}
return record
def prepare_measure(measure_name, measure_value):
measure = {
'Name': measure_name,
'Value': str(measure_value),
'Type': 'DOUBLE'
}
return measure
def write_records(records, common_attributes):
try:
result = write_client.write_records(DatabaseName=DATABASE_NAME,
TableName=TABLE_NAME,
CommonAttributes=common_attributes,
Records=records)
status = result['ResponseMetadata']['HTTPStatusCode']
print("Processed %d records. WriteRecords HTTPStatusCode: %s" %
(len(records), status))
except Exception as err:
print("Error:", err)
if __name__ == '__main__':
print("writing data to database {} table {}".format(
DATABASE_NAME, TABLE_NAME))
session = boto3.Session()
write_client = session.client('timestream-write', config=Config(
read_timeout=20, max_pool_connections=5000, retries={'max_attempts': 10}))
query_client = session.client('timestream-query') # Not used
common_attributes = prepare_common_attributes()
records = []
while True:
current_time = int(time.time() * 1000)
cpu_utilization = psutil.cpu_percent()
memory_utilization = psutil.virtual_memory().percent
swap_utilization = psutil.swap_memory().percent
disk_utilization = psutil.disk_usage('/').percent
record = prepare_record(current_time)
record['MeasureValues'].append(prepare_measure('cpu', cpu_utilization))
record['MeasureValues'].append(prepare_measure('memory', memory_utilization))
record['MeasureValues'].append(prepare_measure('swap', swap_utilization))
record['MeasureValues'].append(prepare_measure('disk', disk_utilization))
records.append(record)
print("records {} - cpu {} - memory {} - swap {} - disk {}".format(
len(records), cpu_utilization, memory_utilization,
swap_utilization, disk_utilization))
if len(records) == 100:
write_records(records, common_attributes)
records = []
time.sleep(INTERVAL)このコードでは、レコードのメジャー名として utilization を利用し、MULTI というメジャー値のタイプとしています。また、複数のメジャー値を名前、値、タイプとともに追加します。アプリケーションの実行には run.sh スクリプトを利用しますが、環境変数である DATABASE_NAME、TABLE_NAME として CloudFormation の output 値を AWS CLI で取得して設定しています。
export TABLE_NAME=`aws cloudformation describe-stacks --stack-name devops-time-series --query 'Stacks[0].Outputs' --output text | grep TableName | cut -f 3`
export DATABASE_NAME=`aws cloudformation describe-stacks --stack-name devops-time-series --query 'Stacks[0].Outputs' --output text | grep DatabaseName | cut -f 3`
python3 collect.py早速スクリプトを実行し、使用状況データを収集します。100 レコード毎に Timestream のテーブルにメジャーが書き込まれていきます。それぞれのレコードはタイムスタンプと、4 つのメジャー値 (CPU、メモリ、ディスク利用状況、スワップ) を含みます。
./run.sh
writing data to database MyDatabase-0XM3OgacnHQR table MyTable-XAX9sYiaV5Ig
records 1 - cpu 40.0 - memory 67.6 - swap 62.7 - disk 26.2
records 2 - cpu 14.4 - memory 67.6 - swap 62.7 - disk 26.2
records 3 - cpu 13.1 - memory 67.6 - swap 62.7 - disk 26.2
records 4 - cpu 12.1 - memory 67.7 - swap 62.7 - disk 26.2
records 5 - cpu 10.0 - memory 66.9 - swap 62.7 - disk 26.2
...
records 95 - cpu 9.2 - memory 66.2 - swap 62.7 - disk 26.2
records 96 - cpu 10.3 - memory 66.2 - swap 62.7 - disk 26.2
records 97 - cpu 11.4 - memory 66.2 - swap 62.7 - disk 26.2
records 98 - cpu 11.7 - memory 66.2 - swap 62.7 - disk 26.2
records 99 - cpu 13.7 - memory 66.2 - swap 62.7 - disk 26.2
records 100 - cpu 9.3 - memory 66.2 - swap 62.7 - disk 26.2
Processed 100 records. WriteRecords HTTPStatusCode: 200Timestream のコンソール画面で、テーブルにロードされた直近のデータをクエリで確認してみます。

下のスクリーンショットは新しいマルチメジャーのレコードフォーマットを表しています。期待した通り、全レコードがデータを分類する為の 3 つのディメンジョン (hostname、city、country)、utilization で設定されたメジャー名、時間、及び、4 つのメジャー(cpu、memory、disk、swap)を持ちます。

マルチメジャーレコードを利用すると、テーブルに書き込まれるレコード数を削減する事が出来ます。以前はメジャー毎に 1 つずつ、計 4 レコードを書き込んでいましたが、今回のアップデートで同時に取得した 4 つのメジャー値を 1 行のマルチメジャーレコードとして書き込む事が出来ます。また、ストレージの使用料も減りますが、以前と同じ情報量を保持しています。処理するデータ量が減少する為、マルチメジャーレコードでクエリを実行する方が簡単で効率的です。例えば、結合を使用して同じクエリで複数のメジャーを取得する必要も無い為、全体的なコスト削減にもつながります。
マグネティックストレージへの書き込みを使った遅延データの管理
時系列データを扱う場合には、遅れて到着するデータ (タイムスタンプが過去) についても考慮する必要があります。データが遅れて到着する理由は多数ありますが、制御出来ない事が大半です。例えば、アプリケーションやデバイスが停止したり、一時的にネットワークから切断された後、オンラインに戻った際に滞留していたデータが一度に送信するようなケースが考えられます。
以前の Timestream ではメモリ保持期間外のデータを書き込むとエラーとして処理していた為、遅延したデータを取り込むには、テーブルのメモリストアの保持期限を増やす必要がありました。
今回、テーブルの設定を有効化するだけで、遅れて到着したデータをマグネティックストレージに直接書き込めるようになりました。メモリストアに書き込む場合と同様に、WriteRecord API を利用すると、書き込むデータのタイムスタンプとテーブルのメモリストア保持期間に応じて、メモリ/マグネティックストレージのいずれかに自動的にルーティングされます。
この機能を使って、データ取り込みのスループットとアプリケーションのクエリ要件に合わせ、メモリストアのデータ保持期間を適切な値に調節できるようになりました。マグネティックストレージへの書き込みは非同期で実行される為、書き込み後すぐにクエリする事は出来ません。但し、書き込みが正常終了した場合は、データは永続的なものとして保持されます。
IT 監視アプリケーションで遠隔地にてネットワークの問題が発生した場合、データは数日前のものが送信される事があります。尚、本投稿で作成したテーブルのメモリ保持期間は 24 時間となっています (テーブル作成に利用した CloudFormation テンプレートの MemoryStoreRetentionPeriodInHours プロパティを確認して下さい)
1 日以上遅れたデータを取り込む為、Timestream のコンソール上でテーブルを選択し更新ボタンを押します。データ保持期間の下に、Magnetic Storage Writes というセクションがあります。この設定を有効化し、エラーログを格納する Amazon S3 のパス情報を設定します。このログのパス情報は非常に重要です。なぜならマグネティックストレージへの書き込みは非同期で実行される為、レコードが正常に書き込めなかった場合、フィードバックを受ける場所が他にない為です。 (尚、エラーとなる場合は例えばバージョン情報のミスマッチ等が考えられます)

スケジュールドクエリを利用したダッシュボードと、レポート作成時のパフォーマンスの改善とコスト削減
更なるコスト最適化の為に、スケジュールドクエリを利用して、ダッシュボードやレポート用に頻繁に利用されるデータを準備してみましょう。例えば、以前 IT 監視アプリケーション用に Grafana ダッシュボードを作成しました。その際、Timestream のテーブルをデータソースとして、以下のクエリを利用してデータを収集しました。 ($__databaseと$__tableはデータソースによって定義されるマクロです)
SELECT country, hostname, city, avg(cpu) AS avg_cpu,
avg(memory) AS avg_memory, avg(disk) AS avg_disk,
avg(swap) AS avg_swap, bin(time, 10m) AS binned_time
FROM $__database.$__table
GROUP BY country, hostname, city, bin(time, 10m)
ORDER BY binned_time結果として次のスクリーンショットが得られます。

Timestream でクエリがどのように実行されているかを理解する為、クエリのメタデータを確認してみます。

クエリのメタデータから、4 MB のデータが Timestream でスキャンされ (CumulativeBytesScanned) 、ダッシュボードにデータを反映するのに 400 ミリ秒 (fetchTime) かかっているのが分かります。スキャンされたデータ量はコスト、パフォーマンス両方に影響を与えます。

コストを最適化し、パフォーマンスを改善する為、スケジュールドクエリを設定し、事前に集計されたデータを別テーブルに入れてみましょう。毎回、大きなソーステーブルにクエリをかけるのではなく、ダッシュボードのクエリをこの新しいテーブルに向けてみます。
まず、CloudFormation のテンプレートに新しいリソース (MyAggregatedTable) を追加し、スケジュールドクエリの結果を格納するテーブルを作ります。
MyAggregatedTable:
Type: AWS::Timestream::Table
Properties:
DatabaseName: !Ref MyDatabase
RetentionProperties:
MemoryStoreRetentionPeriodInHours: "24"
MagneticStoreRetentionPeriodInDays: "7"次に AWS CLI を使って、CloudFormation スタックを更新します。
aws cloudformation update-stack --stack-name devops-time-series --template-body file://template.yamlTimestream のコンソールでスケジュールドクエリを設定してみましょう。まず、ターゲットとして作成した新しいテーブルを選択し、クエリの名前を入力します。 尚、スケジュールドクエリは CloudFormation でも作成出来ますが、どのように動作するかをより簡単に把握する為、コンソールを使っていきます。

Query statement のセクションで次のクエリを設定し、10 分間隔で実行してデータを集計します。尚、ソーステーブルには 1 秒間隔でデータが取り込まれています。
SELECT country, hostname, city,
avg(cpu) AS avg_cpu,
avg(memory) AS avg_memory,
avg(disk) AS avg_disk,
avg(swap) AS avg_swap,
bin(time, 10m) AS binned_timestamp
FROM "MyDatabase-0XM3OgacnHQR"."MyTable-XAX9sYiaV5Ig"
GROUP BY country, hostname, city, bin(time, 10m)
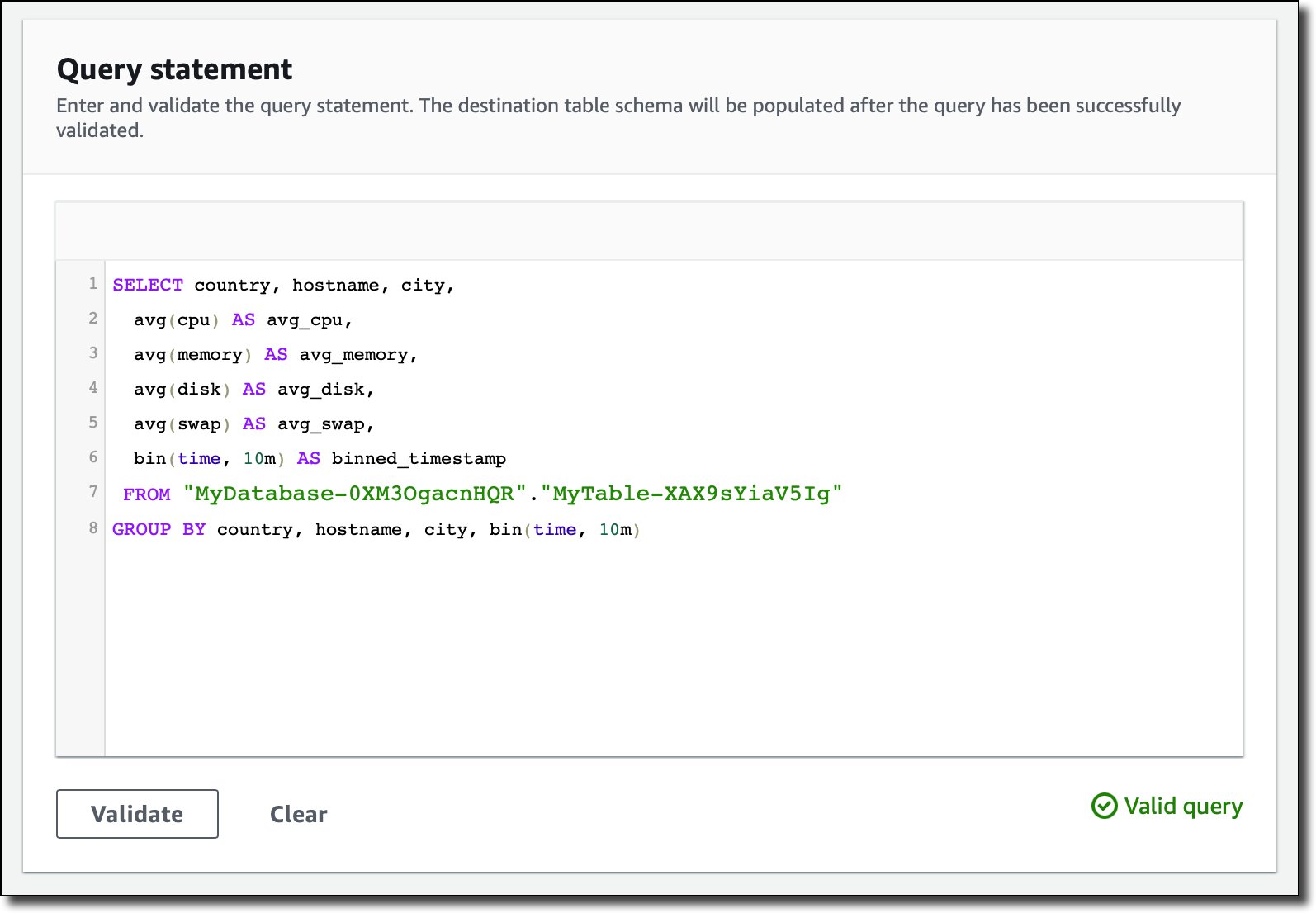
Validate を押して、クエリが間違いない事を確認します。次に Visual Editor で複数のマルチメジャーレコードのメジャー名をデフォルトのままとし、country、hostname、city の属性を Dimension に設定します。

10 分間隔でクエリを実行する事を選択してみます。ユースケースによりますが、間隔を短くしたり長くしたりも出来ますし、CRON 式を使って営業時間外にクエリを実行しないような制御も可能です。

セキュリティ設定で、事前に準備した以下の 3 つのポリシーがアタッチされた IAM ロールを選択します。
- Timestream のソーステーブルの読み込み、Desitination テーブルの書き込みのポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"timestream:Select",
"timestream:DescribeTable",
"timestream:ListMeasures"
],
"Resource": "arn:aws:timestream:eu-west-1:123412341234:database/MyDatabase-0XM3OgacnHQR/table/MyTable-XAX9sYiaV5Ig"
},
{
"Effect": "Allow",
"Action": [
"timestream:DescribeEndpoints",
"timestream:SelectValues",
"timestream:CancelQuery"
],
"Resource": ""
},
{
"Action": [
"timestream:WriteRecords"
],
"Resource": [
"arn:aws:timestream:eu-west-1:123412341234:database/MyDatabase-0XM3OgacnHQR/table/MyAggregatedTable-SWLoLKjEXrDC"
],
"Effect": "Allow"
},
{
"Action": [
"timestream:DescribeEndpoints"
],
"Resource": "",
"Effect": "Allow"
}
]
}- 選択した SNS トピックにメッセージを発行するポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sns:Publish",
"Resource": "arn:aws:sns:eu-west-1:123412341234:timestream-scheduled-query"
}
]
}- S3 バケットにログを書き込むポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-bucket/*"
}
]
}最後に、Assume Role する為に信頼ポリシーを設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "timestream.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}設定したロールで以下についても実行可能となります。
- クエリが実行された時に Amazon SNS トピックを通じて通知
- S3 バケットに対してログを出力

クエリを暗号化するキーはデフォルトの AWS KMS のキーを使います。また、SNS notification セクションで通知用の SNS トピックを選択します。スケジュールドクエリが正しく実行されたかどうかを確認する為には、この通知は非常に重要となります。

エラーログを格納する S3 バケットを設定します。

オプションとして、クエリにタグを設定する事で、検索しやすくしたり、コストのトラッキングが出来るようになります。最後に全ての設定を確認し、スケジュールドクエリを作成します。
少なくとも 1 回以上のスケジュールドクエリが実行された後で、集計データが格納されたターゲットテーブルをポイントした新しいダッシュボードを作ります。クエリは以前と同じですが、メジャーの名前は例えば cpu は avg_cpu 等のように若干変更しました。クエリの結果は以前と全く同じです。

集計されたテーブルを使う利点を確認する為、クエリのメタデータをまた見てみましょう。

元々はソーステーブルから 4 MB を読み込んでいましたが、同じチャートを表示するのに、クエリは 9 KB しか読み込んでいません。表示する時間も 400 ミリ秒から 250 ミリ秒に改善しています。これはそこまで改善していないと思うかも知れませんが、データ量が増えてくれば、よりレイテンシーの改善がみられる事でしょう。このようにして、ダッシュボードが高速で表示されるようになり、コスト削減にもつながる事が分かりました。スケジュールドクエリのその他の利用パターンについては、Scheduled Query Patterns and Examples を確認して下さい。
クリーンアップ
これ以上コストがかからないように、この投稿で作成したリソースは全て消す事にします。最初に、CloudFormation のスタックを以下のコマンドで削除します。この結果、データベースと 2 つのテーブルは削除されます。
aws cloudformation delete-stack —stack-name devops-time-seriesTimestream のコンソールで、作成したスケジュールドクエリを選択し、Actions メニューから Delete を選択して下さい。尚、本投稿では示しませんでしたが、スケジュールドクエリについても CloudFormation でリソース作成可能なので是非試してみて下さい。

まとめ
今回ご紹介した、マルチメジャーレコード、マグネティックストレージへの書き込み、スケジュールドクエリは Timestream が利用可能な全リージョンで使用可能な機能です。
これらの新しい機能は追加費用は不要で、実際にはコスト削減につながるものです。もちろん、スケジュールドクエリを実行する際には費用が発生します。しかし、もしもダッシュボードを何回もロードするような事をしているなら、事前に生成した結果に対するクエリのコスト削減の方が、スケジュールドクエリのコストよりも重要です。
Timestream はアプリケーションの要件に応じて、様々な方法でデータをモデル化する柔軟性を提供しています。コストとパフォーマンスを最適化する為のパターンとガイドを、Timestream のドキュメントに新たに Data Modeling のセクションとして追加しているので、是非ご確認下さい。
翻訳はテクニカルアカウントマネージャーの西原が担当しました。原文はこちらです。