Amazon Web Services ブログ
Amazon MSK でマルチテナントデータをストリーミングする
本記事は 2024 年 6 月 20 日 に公開された「Stream multi-tenant data with Amazon MSK」を翻訳したものです。
リアルタイムデータストリーミングは、即時性が求められる現代のデジタル体験に欠かせない技術です。あらゆる業界の最新の SaaS (Software as a Service) アプリケーションは、Web やモバイルアプリケーション、IoT (Internet of Things) デバイス、ソーシャルメディアプラットフォーム、EC サイトなど、さまざまなデータソースから継続的に生成されるデータを活用しています。データストリームをリアルタイムに処理すれば、応答性の高いパーソナライズされたソリューションを提供でき、イベント発生時刻に近いタイミングで処理するほどデータの価値を高められます。
AWS は、Amazon Kinesis Data Streams や Amazon Managed Streaming for Apache Kafka (Amazon MSK) によるストリーミングアプリケーション、Amazon Managed Service for Apache Flink によるリアルタイム処理アプリケーションの実装に必要な構成要素を提供し、SaaS ベンダーを支援しています。
本記事では、ストリーミングプラットフォームを内部コンポーネント間の統合手段として使用する場合に、SaaS ベンダーが採用できる実装パターンを紹介します。ストリーミングデータをサードパーティに直接公開しないユースケースを対象とし、特に Amazon MSK に焦点を当てます。
ストリーミングにおけるマルチテナンシーパターン
ストリーミングアプリケーションを構築する際には、以下の観点を考慮する必要があります。
- データパーティショニング – イベントのストリーミングとストレージは、テナントの所有権に基づいて物理的または論理的に適切なレベルで分離する必要があります
- パフォーマンスの公平性 – 異なるテナントのストリーミングデータを処理するアプリケーション間のパフォーマンスへの相互影響を制御する必要があります
- テナント分離 – テナントが自身のデータにのみアクセスできるよう、堅牢な認可戦略を策定する必要があります
マルチテナントシステムにおけるあらゆる操作の基盤となるのが、SaaS アイデンティティの概念です。詳細については、SaaS Architecture Fundamentals を参照してください。
SaaS デプロイモデル
テナント分離は SaaS プロバイダーにとって必須であり、分離のアプローチはデプロイモデルによって異なります。モデルはビジネス要件に影響を受け、相互に排他的ではありません。分離、複雑さ、コストのバランスを取るために、サービスごとにトレードオフを検討する必要があります。万能な解決策はなく、SaaS ベンダーはビジネスと顧客のニーズを慎重に検討し、サイロ、プール、ブリッジ (またはそれらの組み合わせ) の 3 つの分離戦略から選択する必要があります。
以降のセクションでは、データ分離、パフォーマンスの公平性、テナント分離の観点から各デプロイモデルを詳しく見ていきます。
サイロモデル
サイロモデルはデータ分離のレベルが最も高い一方、運用コストも最も高くなります。テナントごとに専用の MSK クラスターを持つことで、オーバープロビジョニングのリスクが高まり、管理・監視ツールの重複が必要になります。
テナントごとに専用の MSK クラスターを持つことで、Amazon MSK Provisioned モデルを使用する場合、テナントデータのパーティショニングがディスクレベルで実現されます。Amazon MSK Provisioned と Serverless クラスターの両方がサーバーサイドの保存時暗号化をサポートしています。Amazon MSK Provisioned ではさらに、カスタマーマネージドの AWS Key Management Service (AWS KMS) キーを使用できます (Amazon MSK encryption を参照)。
サイロモデルでは、ビジネス要件で求められない限り、Kafka ACL やクォータは厳密には必要ありません。MSK クラスター全体のリソースを単一テナントが専有するため、パフォーマンスの公平性は保証されます。特定のテナントのトラフィックスパイクが他のテナントに影響を与えることはなく、テナント間のデータアクセスのリスクもありません。一方、テナントごとにクラスターをプロビジョニングするため、個別のサイジングが必要となり、プールモデルやブリッジモデルよりもオーバープロビジョニングのリスクが高くなります。
テナント分離は、使用する認証スキームに応じて、AWS Identity and Access Management (IAM) ポリシーを使用して MSK クラスターレベルで実装し、クラスターごとの認証情報を作成できます。
プールモデル
プールモデルは、テナントがリソースを共有する最もシンプルなモデルです。すべてのテナントで単一の MSK クラスターを使用し、データはイベントタイプに基づいてトピックに分割されます (例: 注文に関連するすべてのイベントは orders トピックに送信)。すべてのテナントのイベントが同じトピックに送信されます。次の図はこのアーキテクチャを示しています。
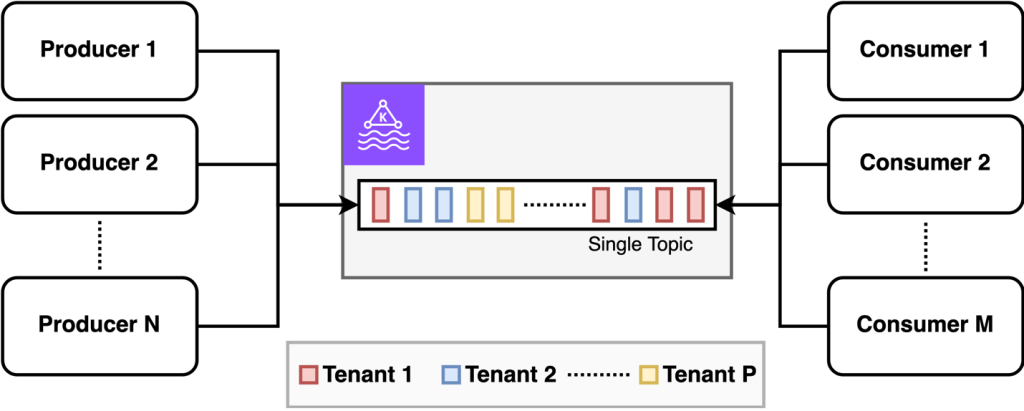
プールモデルは運用のシンプルさを最大化しますが、テナント分離のオプションは制限されます。SaaS プロバイダーはテナントごとの運用パラメータを差別化できず、分離の責任はすべて Kafka からデータを生成・消費するアプリケーションに委ねられます。プールモデルは物理的なデータパーティショニングやパフォーマンスの公平性のメカニズムも提供しません。データパーティショニングやパフォーマンスの公平性が必要な場合は、ブリッジモデルまたはサイロモデルを検討すべきです。テナントごとの暗号化キーやデータ操作が不要であれば、プールモデルは複雑さを抑えられる有効な選択肢です。トレードオフを詳しく見ていきましょう。
コンシューマー分離を実装する一般的な戦略は、テナント ID を使用して各イベント内のテナントを識別することです。Kafka で利用できるオプションは、テナント ID をイベントメタデータ (ヘッダー) として渡すか、ペイロード自体の明示的なフィールドとして含めるかです。テナント ID をメッセージペイロードとイベントヘッダーの両方に含め、アプリケーション間で標準化されたフィールドとして使用します。イベントヘッダーは処理フレームワークによって扱いが異なり、転送時に削除される可能性があるため、両方に含めることでメッセージ処理・転送時のセマンティックの乖離リスクを軽減できます。一方、イベントボディは通常単一のオブジェクトとして転送され、明示的に変換されない限り含まれる情報は失われません。テナント ID をイベントヘッダーにも含めることで、メッセージペイロードのデシリアライズなしにテナントを指定してリカバリやマイグレーションを行うサービスの実装が容易になります。
ヘッダーまたはイベントのフィールドとしてテナント ID を指定する場合、コンシューマーアプリケーションは特定のテナントのイベントを選択的にサブスクライブできません。Kafka では、コンシューマーはトピックにサブスクライブし、そのトピックに送信されたすべてのテナントのイベントを受信します。イベントを受信した後にのみ、コンシューマーはテナント ID を検査して対象のテナントをフィルタリングできるため、アクセスの分離は事実上不可能です。そのため、テナントが他のテナントのデータを読み取れないよう、機密データを暗号化する必要があります。Kafka では、サーバーサイド暗号化はクラスターレベルでのみ設定でき、クラスターを共有するすべてのテナントが同じサーバーサイド暗号化キーを共有します。
Kafka では、データ保持期間はトピック単位でのみ設定できます。プールモデルでは、すべてのテナントのイベントが同じトピックに送信されるため、特定のテナントのデータをすべて削除するといったテナント固有の操作はできません。Kafka のイミュータブルな追記専用の性質上、トピック全体の削除のみが可能で、特定のテナントに属するイベントの選択的な削除はできません。ストリーム内の特定の顧客データに GDPR などの忘れられる権利が必要な場合、プールモデルはそのデータには適さず、該当するデータストリームにはサイロモデルを検討すべきです。
ブリッジモデル
ブリッジモデルでは、すべてのテナントで単一の Kafka クラスターを使用しますが、異なるテナントのイベントは異なるトピックに分離されます。このモデルでは、テナントごとに関連するイベントグループのトピックが存在します。トピック名にテナント ID を含める命名規則を採用すれば、テナントごとの名前空間が作成され、異なる管理者が異なるテナントを管理し、プレフィックス ACL で権限を設定し、名前の衝突を回避できます (例: テナント 1 の注文イベントは tenant1.orders に、テナント 2 の注文は tenant2.orders に送信)。次の図はこのアーキテクチャを示しています。
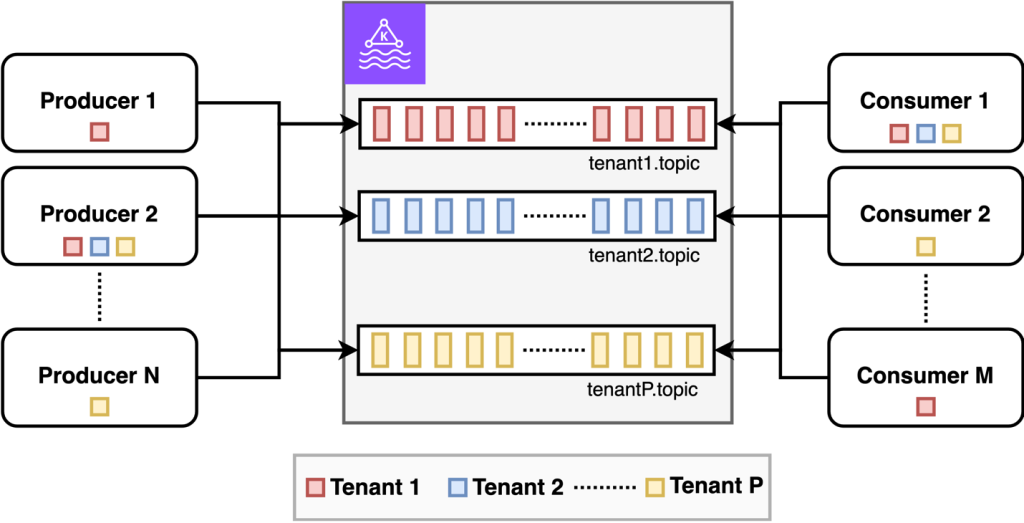
ブリッジモデルでは、テナントごとの暗号化キーによるサーバーサイド暗号化はできません。暗号化キーはクラスター単位でのみ指定でき、すべてのテナントのデータが同じ MSK クラスターに保存されるためです。データの分離はファイルレベルに限られます。トピックごとに別ファイルに保存されますが、Amazon MSK はすべてのトピックを同じ Amazon Elastic Block Store (Amazon EBS) ボリューム内に保存します。
ブリッジモデルでは、保持ポリシーや最大メッセージサイズなどをテナントごとにカスタマイズできます。Kafka でトピック単位の設定が可能なためです。また、テナントごとにイベント処理を分離・デカップリングしやすく、異なるテナントのデータを処理するアプリケーション間でより強力な分離を実現できます。
まとめると、ブリッジモデルは以下の機能を提供します。
- テナント処理の分離 – コンシューマーアプリケーションは特定のテナントに属するトピックを選択的にサブスクライブし、そのテナントのイベントのみを受信できます。SaaS プロバイダーは、特定のテナントに属するトピックを選択的に削除することで、テナント固有のデータを削除できます。
- 処理の選択的スケーリング – Kafka では、並列コンシューマーの最大数はトピックのパーティション数によって決まり、パーティション数はトピック単位、つまりテナント単位で設定できます。
- パフォーマンスの公平性 – Amazon MSK がサポートする Kafka クォータを使用してパフォーマンスの公平性を実装できます。特に負荷の高いテナントを処理するサービスがクラスターリソースを過剰に消費し、他のテナントに影響を与えることを防止します。Amazon MSK での Kafka クォータと IAM 認証の実装例については、こちらの 2 部構成のシリーズを参照してください。
- テナント分離 – Amazon MSK で使用する認証スキームに応じて、IAM アクセスコントロールまたは Apache Kafka ACL を使用してテナント分離を実装できます。IAM と Kafka ACL の両方で、トピック単位のアクセス制御が可能です。アプリケーションが処理対象のテナントに属するトピックにのみアクセスできるよう認可を設定できます。
SaaS 環境でのトレードオフ
各モデルはデータパーティショニング、パフォーマンスの公平性、テナント分離に対して異なる機能を提供しますが、コストと複雑さも異なります。計画段階では、一般的な顧客に対してどのようなトレードオフを許容するかを特定し、クライアントのサブスクリプションにティア構造を提供することが重要です。
次の表は、ストリーミングアプリケーションにおける 3 つのモデルのサポート機能をまとめたものです。
| . | プール | ブリッジ | サイロ |
| テナントごとの保存時暗号化 | 不可 | 不可 | 可能 |
| 単一テナントの忘れられる権利の実装 | 不可 | 可能 | 可能 |
| テナントごとの保持ポリシー | 不可 | 可能 | 可能 |
| テナントごとのイベントサイズ制限 | 不可 | 可能 | 可能 |
| テナントごとのリプレイ | 可能 (コンシューマーのロジックで実装が必要) | 可能 | 可能 |
アンチパターン
ブリッジモデルでは、トピックによるテナント分離について説明しました。代替手段として、パーティションによる分離があります。特定のタイプのすべてのメッセージを同じトピック (例: orders) に送信しつつ、テナントごとに専用のパーティションを割り当てる方法です。パーティションによる分離には多くのデメリットがあり、推奨しません。Kafka では、パーティションはブローカーとコンシューマーの水平スケーリングとバランシングの単位です。テナントごとにパーティションを割り当てると、クラスターの不均衡が生じ、運用上およびパフォーマンス上の問題が発生し、解決が困難になります。
テナントごとの暗号化キーなど、ある程度のデータ分離はクライアントサイド暗号化で実現でき、暗号化と復号をプロデューサーとコンシューマーのアプリケーションに委任します。クライアントサイド暗号化ならテナントごとに個別の暗号化キーを使用できます。しかし、コンシューマーとプロデューサーの両方に高い複雑さをもたらすため、推奨しません。また、標準的なプログラミングライブラリ、Kafka ツール、Kafka Connect や MSK Connect などの Kafka エコシステムサービスのほとんどが使用できなくなる可能性があります。
まとめ
本記事では、SaaS ベンダーが Amazon MSK でマルチテナントストリーミングアプリケーションを設計する際に使用できる 3 つのパターン、プール、ブリッジ、サイロモデルについて説明しました。運用のシンプルさ、テナント分離のレベル、コスト効率のトレードオフはモデルごとに異なります。
サイロモデルはテナントごとに専用の MSK クラスターを割り当て、わかりやすいテナント分離を実現しますが、テナントあたりのメンテナンスとコストが高くなります。プールモデルはすべてのリソースをテナント間で共有することで運用とコストの効率を高めますが、データパーティショニング、パフォーマンスの公平性、テナント分離の機能は限定的です。ブリッジモデルは、運用とコストの効率性を維持しつつ、堅牢なテナント分離とパフォーマンスの公平性を実現する幅広いオプションを備えた、バランスの取れた選択肢です。
マルチテナントストリーミングソリューションを設計する際は、テナント分離、データプライバシー、テナントごとのカスタマイズ、パフォーマンス保証に関する要件を慎重に評価し、適切なモデルを選択してください。必要に応じてモデルを組み合わせ、ビジネスに最適なバランスを見つけてください。アプリケーションのスケールに合わせて分離のニーズを再評価し、必要に応じてモデル間の移行を行ってください。
マルチテナントアーキテクチャにおけるデータストリーミングに万能なパターンはありません。ストリーミングの目標と顧客のニーズを慎重に検討し、顧客データのセキュリティと監査可能性を確保しつつ、適切なトレードオフを判断してください。SkillBuilder の SaaS カリキュラムで学習を続けるか、AWS Serverless SaaS ワークショップや Amazon EKS SaaS ワークショップでハンズオンを体験するか、Amazon MSK Labs で深く学んでください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。