Amazon Web Services ブログ
MeetMe での S3 データレイクへのリアルタイムデータのストリーミング
本日のゲスト投稿では、MeetMe の Anton Slutsky 氏が、自社のデータレイク用の実装プロセスについて説明します。
— Jeff;

現在のビッグデータシステムには、しばしばデータレイクと呼ばれる構造が含まれています。データレイクという業界用語は、大量の構造化データと非構造化データを吸収し、多数の同時分析ジョブを実行する機能を備えた大規模なストレージおよび処理サブシステムのことです。Amazon Simple Storage Service (S3) はスケーラブルで信頼性が高く、レイテンシーが短いストレージソリューションを低いオペレーションのオーバーヘッドで提供するため、データレイクインフラストラクチャとして現在人気の高い選択肢となっています。ただし、S3 によってペタバイト規模のストレージのセットアップ、設定、管理に関連する多くの問題が解決される一方で、S3 へのデータの取り込みがしばしば課題となっています。これは、ソースデータのタイプ、ボリューム、速度が組織によって大きく異なっているためです。このブログでは、Amazon Kinesis Firehose を使用して MeetMe で大規模なデータ取り込みを最適化、合理化する当社のソリューションについて説明します。これは毎日数百万人のアクティブなユーザーに対応している人気の高いソーシャル検出プラットフォームです。MeetMe のデータサイエンスチームは、1 日あたり約 0.5 TB のさまざまなタイプのデータを、データマイニングタスク、ビジネス向けレポート、高度な分析に公開するような方法で収集、保存する必要がありました。チームはターゲットのストレージ機能として Amazon S3 を選択し、大量のライブデータを堅牢で信頼性が高く、スケーラブルで運用費用が低い方法で収集するという課題に直面していました。ここでの全体的な目的は、可能な限り低いオペレーションのオーバーヘッドで、AWS データインフラストラクチャに大量のストリーミングデータをプッシュするプロセスをセットアップすることでした。Flume、Sqoop など多くのデータ取り込みツールが現在入手可能ですが、当社は、その自動的なスケーラビリティと伸縮性、設定と管理の容易さ、それに S3、Amazon Redshift、Amazon Elasticsearch Service など他の Amazon サービスとの即座の統合機能により、Amazon Kinesis Firehose を選択しました。
ビジネス価値 / 正当化
![]() 多くのスタートアップ企業と同じように、MeetMe は最大のビジネス価値をできるだけ低いコストで提供することに焦点を置いています。したがって、データレイクについては次のような目標がありました。
多くのスタートアップ企業と同じように、MeetMe は最大のビジネス価値をできるだけ低いコストで提供することに焦点を置いています。したがって、データレイクについては次のような目標がありました。
- 効果的な意思決定のための高レベルなビジネスインテリジェンスでビジネスユーザーに力を与える。
- 収益を生み出す洞察の発見に必要なデータをデータサイエンスチームに提供する。
Scoop や Flume といったよく使われているデータ取り込みツールを検討した結果、データサイエンスチームはデータ取り込みプロセスをセットアップ、設定、調整、維持するためにフルタイムの BigData エンジニアを追加する必要があり、冗長性のサポートを可能にするために、エンジニアリングの時間がさらに必要であると予測されました。このようなオペレーションのオーバーヘッドは MeetMe でのデータサイエンスの費用を増やし、全体的な速度に影響する不要な範囲をチームにもたらします。Amazon Kinesis Firehose サービスにより多くの運用面の懸念が軽減され、それによりコストも削減されました。それでもある程度の社内の統合開発は必要でしたが、データコンシューマーのスケーリング、管理、アップグレード、トラブルシューティングは Amazon によって行われるため、データサイエンスチームの規模と範囲は大幅に減りました。
Amazon Kinesis Firehose Stream の設定
Kinesis Firehose には、複数の Firehose システムを作成する機能があり、それぞれの対象を異なる S3 の場所、Redshift テーブル、または Amazon Elasticsearch Service インデックスにすることができます。当社の場合、主要な目標はデータを S3 に保存し、将来的には上記のような他のサービスも検討するというものでした。Firehose の配信ストリームのセットアップは 3 ステップのプロセスです。ステップ 1 では、送信先タイプを選択する必要があります。これにより、データの統合先を S3 バケット、Redshift テーブル、または Elasticsearch インデックスに定義できます。当社ではデータを S3 に配置することを希望したため、統合先オプションとして “Amazon S3″ を選択しました。S3 を統合先として選択すると、Firehose でその他の S3 オプション (S3 バケット名など) が求められます。Firehose のドキュメントで説明したように、Firehose では自動的にデータを日時で整理し、”S3 プリフィックス” 設定が、特定の Firehose ストリームオブジェクトのすべての S3 キーの前に付加されるグローバルプレフィックスとなります。プレフィックスは、データを使用中のライブストリームにおいてさえ後日に変更できるため、最初から命名規則について深く考える必要はまったくありません。
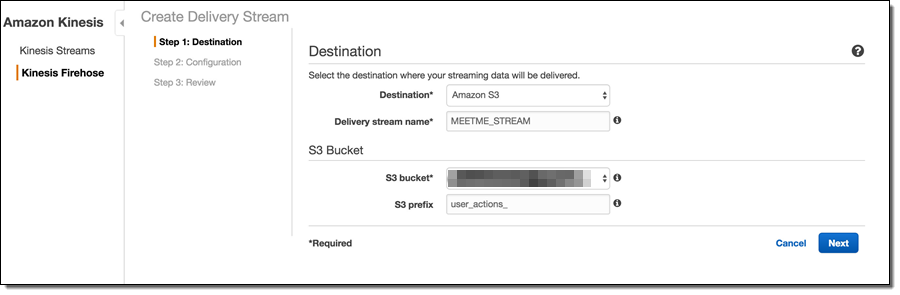
プロセスの次のステップはストリーム設定です。ここで、さまざまなデフォルト値を上書きし、他の意味ある値を指定することができます。たとえば、非圧縮のデフォルト値の代わりに GZIP 圧縮を選択すると、S3 ストレージのフットプリントを大幅に減らし、それにより S3 のコストを減らすことができます。データ暗号化を有効にすると、保管時のデータが暗号化されます。これは機密データにとって重要です。
1 つの重要な注意点として、圧縮アルゴリズムの選択により、ストリームオブジェクトのファイル名 (S3 キー) に影響があります。したがって、これらの設定は後からライブストリームで変更することができるものの、処理スクリプトで発生する可能性がある問題を回避するため、最初から圧縮/暗号化手法を決定することが賢明かもしれません。
「Amazon Kinesis Firehose Limits」で述べたように、 Kinesis Firehose にはデフォルトのスループットクォータのセットがあります。これらのクォータを超えると、Firehose は “ServiceUnavailableException: Slow down.” というエラーメッセージで応答し、データを削除します。したがって、データ損失を避けるには、個別のスループット要件を予測することが重要です。これらの要件がデフォルトのクォータを超える可能性が高い場合、制限で説明されているように限度の引き上げリクエストを送信することで、追加のスループットをリクエストできます。最終ステップ (ここには示しません) では、目的の設定を確認し、ストリームを作成します。
アップロードプロセスのセットアップ
MeetMe では、RabbitMQ が、システムを通過するほとんどのデータのサービスバスとして機能しています。したがって、データ収集のタスクのほとんどの部分は、大量の RabbitMQ メッセージを使用し、Firehose ストリームを利用してそれらを S3 にアップロードすることになります。これを達成するため、軽量の RabbitMQ コンシューマーを開発しました。RabbitMQ コンシューマーは他の場所 (Flume など) に実装されていますが、Firehose API との統合を可能にするため、独自のバージョンを開発することにしました。
Firehose には、データをアップロードするために、単一のレコードとバルクレコードという 2 つの方法があります。単一のレコードの手法では、各個別のレコードが Amazon Firehose API フレームワークオブジェクトにパッケージ化され、各オブジェクトは HTTP/Rest を通じて Firehose エンドポイントにシリアル化されます。この手法は一部のアプリケーションにとって適切な場合がありますが、当社はバルク API 方法を使用することで、より良いパフォーマンスを達成しました。バルク方法では、最大 500 レコードを 1 つのリクエストで Firehose にアップロードできます。メッセージのバッチをアップロードするため、軽量 RabbitMQ コンシューマーは小規模な内部バッファを維持します。これは事前定義されたプロセッサスレッドのセットにより、可能な限り多く Firehose にシリアル化されます。以下にコードを示します。
new Thread(new Runnable()
{
public void run()
{
logger.info("Kinesis ライタースレッドが開始しました。 レコードの処理を待機しています...");
while(true)
{
try
{
if(!recordsQueue.isEmpty())
{
if(logger.isDebugEnabled())
logger.debug("現在のバッチを AWS にアップロードしています: "+recordsQueue.size());
List<MMMessage> records = recordsQueue;
recordsQueue = new CopyOnWriteArrayList<MMMessage>();
final int uploadThreshold = 499;
List<Record> buffer = new ArrayList<Record>(uploadThreshold);
for(int i = 0; i < records.size(); i++)
{
// 内部キューから独自のメッセージオブジェクトを取得します
MMessage mmmessage = records.get(i);
// バイト数を取得します
String message = new String(mmmessage.body, "UTF-8");
// データの新しい行とタブ文字を確認し
// Hadoop/Spark 処理行ベースの処理の問題を
// 後で回避します
message = CharMatcher.anyOf("\n").replaceFrom(message, "\\n");
message = CharMatcher.anyOf("\t").replaceFrom(message, "\\t");
// Amazon Firehose API ラッパーでメッセージバイトをラップします
Record record = new Record().withData(ByteBuffer.wrap(message.getBytes()));
buffer.add(record);
// 現在のバッファが十分に大きい場合、
if(buffer.size() == uploadThreshold)
{
// Firehose に送信し
uploadBuffer(buffer);
// 新しいバッファをインスタンス化します
buffer = new ArrayList<Record>(uploadThreshold);
}
}
// 最後のバッファのアップロードを忘れないでください!
uploadBuffer(buffer);
}
}
catch(Exception e)
{
logger.error("Error in sending to Kinesis:"+e.getMessage(), e);
}
}
}
}).start();
uploadBuffer メソッドは、バルクアップロード Firehose API に対するシンプルなラッパーです。
private void uploadBuffer(final List<Record> buffer)
{
// 新しいリクエストオブジェクトを作成します
PutRecordBatchRequest request = new PutRecordBatchRequest();
// ストリーム名を指定します
request.setDeliveryStreamName("MEETME_STREAM");
// データバッファを設定します
request.setRecords(buffer);
// Firehose への送信を試みます
PutRecordBatchResult result = getAmazonClient().putRecordBatch(request);
// 常に失敗について確認してください!
Integer failed = result.getFailedPutCount();
if (failed != null && failed.intValue() > 0)
{
// 失敗がある場合、その原因を見つけます
logger.warn("AWS upload of [" + buffer.size() + "] resulted in " + failed + " failures");
// 応答を調べ、さまざまな種類の失敗がないかどうか確認します
List<PutRecordBatchResponseEntry> res = result.getRequestResponses();
if (res != null)
{
for (PutRecordBatchResponseEntry r : res)
{
if (r != null)
{
logger.warn("Report " + r.getRecordId() + ", " + r.getErrorCode() + ", " + r.getErrorMessage()
+ ", " + r.toString());
}
else
{
logger.warn("Report NULL");
}
}
}
else
{
logger.warn("BatchReport NULL");
}
}
}
Firehose ストリームのモニタリング
Firehose ストリームをセットアップし、内部コンシューマープロセスがデータの送信を開始した後の一般的なタスクは、データフローのモニタリングを試みることです。データフローに注意する理由として、データボリュームの考慮事項、エラー状態の可能性、失敗の検出などがあります。Amazon Firehose では、モニタリングは Amazon CloudWatch を利用して達成されます。一般的な配信ストリームメトリックスは、各 Firehose ストリーム設定の [Monitoring] タブで表示でき、その他のメトリックスは CloudWatch コンソールから表示できます。
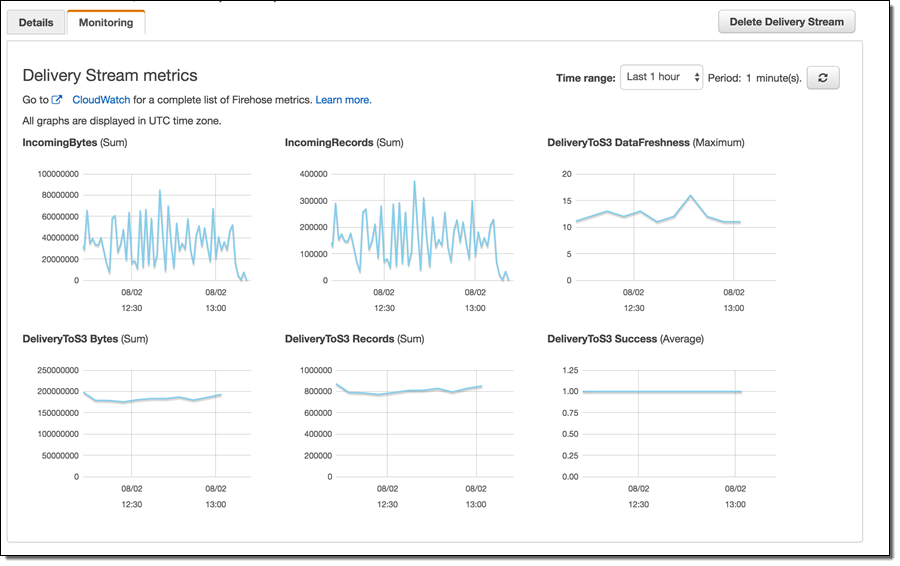
AWS は広範なモニタリング機能を提供していますが、当社の経験では、内部データプロデューサーログでエラーを慎重にモニタリングするのが重要であることがわかっています。syslog 機能、Splunk、およびその他のログモニタリングツールを使ってこのように注意深いモニタリングを行うことで、特定のエラーを検出して修正し、個別のレコードの失敗数を許容できるレベルにまで減らすことができました。さらに、内部ログのモニタリングにより、ボリュームが急速に Firehose のデフォルトのスループットクォータを超えていることを早期に認識できました (上記を参照)。
Anton Slutsky、データサイエンス担当ディレクター、MeetMe