Amazon Web Services ブログ
Prometheus を用いた、Amazon EKS API server のトラブルシューティング
“クラスターで問題が発生した” と朝3時に監視システムからのアラート通知で起こされれば、オンコール担当者にとっては悪夢です。その場合、問題が Amazon EKS のマネージドコントロールプレーンにあるのか、それとも先週ロールアウトした新規のアプリケーションにあるのか、即座に切り分けなければなりません。たとえブログで推奨されたデフォルトのダッシュボードをインストールしたとしても、参照するメトリクスの意味を理解することはやはり難しいでしょう。
よくある問題にフォーカスしたダッシュボードの用意があれば、すぐに全てが意味することを理解でき、不明瞭な問題を効率的に素早くスキャンできるようになります。
API サーバーのトラブルシューティング
上記は野心的な目標なので、Prometheus を用いて Amazon Kubernetes Service ( Amazon EKS ) の API サーバーをトラブルシューティングするのに役立つスターターダッシュボードを作りました。ダッシュボードを使用することで、商用環境のクラスターに対するトラブルシューティングをする際、参照しているメトリクスを理解するのに役立ちます。これらのメトリクスが意味することや、これらのメトリクスが重要と考える理由にフォーカスを当てます。
今回は、新しい Grafana 8.5.0 の機能を用います。最初は混乱するかもしれませんが、適度な時間で複雑な問題を素早く特定するためにも効果的だと理解することを願っています。
前提条件
下記の手順は、本番環境の Kubernetes に対して経験があるオペレーターに役立つようにデザインされています。ガイドの残りの部分は、 Prometheus/Grafana が既にセットアップしていることを前提としています。
セットアップ
- もし、Grafana ではない別の監視プラットフォームを利用しているならば、こちらのブログに沿って進めてください。
- Grafanaにログインしたら、こちらの Troubleshooting-Dashboards をダウンロードしてください。
- ダッシュボード配下の Manage タブに遷移してください。
- Manage ウィンドウで Import をクリックします。

- その後、チャートをインポートするため Upload JSON file をクリックします。

問題の理解
クラスターにインストールしたい興味深いオープンソースプロジェクトを見つけたとしましょう。そのオペレーターは、クラスターに DaemonSet を展開しますが、その DaemonSet は不正なリクエストをしていたり、不必要に大量の LIST コールを使用していたり、1,000 ノードすべての DaemonSet が、クラスターの 50,000 ポッドの状態を 1 分ごとに要求しているかもしれません! これは本当にしばしば発生することでしょうか?はい。そうです! では、このような事態がどのようにして起きるのか寄り道して見ていきましょう。
LIST と WATCH の理解
アプリケーションによっては、クラスターのオブジェクトのステータスを理解する必要があります。例えば、機械学習 ( ML ) のアプリケーションは、いくつのポッドが Completed でないステータスであるかを理解することでジョブのステータスを知りたいでしょう。
Kubernetes ではこれを実現するため、WATCH と呼ばれるオブジェクトのステータスを理解する良い方法と ポッドの最新ステータスを見つけるため、クラスターの全てのオブジェクトをリスト化する あまりよくない方法があります。
WATCH について
プッシュモデルを介してアップデートを受け取るため、WATCH または 単一で長寿命なコネクションを利用することは、Kubernetes でアップデートをする最もスケーラブルな方法です。より単純化すると、システムの完全な状態を要求し、そのオブジェクトの変更を受信したときにのみキャッシュ内のオブジェクトを更新し、更新を見逃さないように定期的に再同期を実行します。
以下の画像では、API サーバー間で長寿命コネクション数のアイディアを得るために apiserver_longrunning_gauge を利用しています。

効率的なシステムでさえ、まだやれることはたくさんあります。例えば、多くのとても小さいノードを利用した場合、各ノードにAPI サーバーと通信する必要がある 2 つまたはそれ以上の DaemonSet が配置され、不必要にシステムで WATCH コール数が劇的に増加することはよくあるからです。例えば、8 つの xlarge ノードと 1 つの 8xlarge ノードについて違いを見てみましょう。ここでは、システムで WATCH コールが 8 倍に増加しています。

これは効率的な呼び出しですが、それが上記でほのめかした不正な呼び出しであったらどうでしょうか?想像して見てください。もし、上記の 1000 ノードのそれぞれに配置されたDaemonSets の一つが、クラスター内の全 50,000 ポッドにアップデートをリクエストした場合のことを。次のセクションでは、無制限の LIST コールのアイディアについて考えて見たいと思います。
話を続ける前に少し注意事項を記載しますが、上記の例のようなノードを減らしスケールアップすることは、慎重にする必要がありますし、他にも多くの考察事項もあります。システムで利用できる CPU をめぐりスレッド間で競合が発生することによる遅延や、ポッドのチャーンレート、ノードが安全に扱えるボリュームアタッチメントの最大数などです。しかし、フォーカスすべきはメトリクスであり、それが問題の発生を防ぐ実用可能なステップを示してくれます。おそらく、設計の新しいインサイトを与えてくれるでしょう。
WATCH メトリクスはシンプルですが、WATCH数が問題であれば、それを追跡し減らすために利用されます。ここで、ウォッチ数を減らすために検討できるオプションをいくつか記載します。
- 履歴を追跡するため、Helm が作成する ConfigMap の数を制限します。
- WATCH を使用しないイミュータブルな ConfigMap や Secrets を利用します。
- ノードのサイズや統合について検討します。
無制限の LIST コール
ここから、LIST コールについて記載します。LIST コールは Kubernetes オブジェクトの状態を知る必要があるたびに、そのオブジェクトの全履歴を取得します。ここでは、キャッシュに何も保存されていないとします。
これには、どの程度のインパクトがあるでしょう?これは、どの程度のエージェント数でデータをリクエストしたか、どんな頻度でエージェントがリクエストしたか、そしてどの程度の量のデータをエージェントがリクエストしたかに依存して変化します。エージェントがクラスターの全てのデータを要求したのか、それとも特定の namespace のデータを要求したのか?それはノードで毎分発生するのか?等々。
ここでは、ノードから送られる全てのログに Kubernetes メタデータを付加するロギングエージェントの例を用いましょう。大きいクラスターの場合、圧倒的なデータ量になります。エージェントが、LIST コールを用いてそのデータを取得する方法は多数あります。これから、そのいくつかを見て見ましょう。
このリクエストは、特定の namespace のポッドに要求をします。
/api/v1/namespaces/my-namespace/pods
次に、クラスター内の全 50,000 ポッドを 500 のずつのポッド群にまとめてリクエストします。
/api/v1/pods?limit=500
次は、最も破壊的です。クラスターの全 50,000 ポッドのデータをリクエストします。
/api/v1/pods
これは一般的によく発生し、ログから確認できます。
悪しき振る舞いを止めるには
どのようにして、悪しき振る舞いからクラスターを守ることができるでしょうか? Kubernetes 1.20 以前では、API サーバーは 1 秒あたりに処理される inflight リクエスト数の制限によって自身を保護していました。etcd は、パフォーマンスの高い方法で一度に非常に多くのリクエストを処理することしかできません。なので、etcd の読み取りと書き込みを妥当なレイテンシー帯域で維持するため、秒間リクエスト数が制限されていることを確認する必要があります。残念ながら、この記事の執筆時点ではこれを動的に行う方法はありません。
以下のチャートでは、読み取りリクエストの内訳が見れます。デフォルトとして API サーバーごとに最大 400 の inflight リクエスト 及び 最大 200 の同時書き込みリクエストがあります。デフォルトの EKS クラスターでは、トータル 800 の読み取りリクエスト、400 の書き込みリクエストを受け付ける 2 つの API サーバーが確認できます。しかしながら、これらのサーバーには、アップグレード直後など、さまざまな時点で非対称の負荷がかかる可能性があるため、注意が必要です。

上記は、完璧なスキームではないことがわかりました。例えば、インストールしたばかりの動作の悪い新しいオペレーターが、API サーバーの Inflight 書き込み全リクエストを獲得してしまい、ノードの keepalive メッセージなどの重要な要求を遅らせる可能性をどうすれば防げるでしょうか。
API の優先度と公平性
1 秒間に何回の読み取り/書き込み要求があるかを気にする代わりに、キャパシティーを 1 つの総数として扱い、クラスター上の各アプリケーションがその総数の公平な割合またはシェアを得るとしたらどうでしょう。それを効果的に行うには、誰がAPIサーバーにリクエストを送ったかを特定し、そのリクエストにある種のネームタグを付ける必要があります。この新しいネームタグを用いることで、すべてのリクエストは “Chatty” と呼ばれる新しいエージェントから送られていることがわかります。Chatty の全リクエストをフローと呼ばれるものにグループ化し、同じ DaemonSet からのリクエストであることを識別します。この概念により、この悪いエージェントを制限し、クラスター全体を消費させないようにできます。
しかし、すべてのリクエストが同じように作成されるわけではありません。クラスターの運用を維持するために必要なコントロールプレーンのトラフィックは、新しいオペレーターよりも高い優先度であるべきです。ここで、優先度という考え方が登場します。
もし、デフォルトで、“重要”、“高”、“低” の優先度がついたトラフィック用に いくつかの “buckets” またはキューを用意したらどうでしょうか?この場合、おしゃべりなエージェントフローが、優先度 “重要” のキューで、公平にトラフィックのシェアを得るのは望ましくありません。しかし、そのトラフィックを優先度 “低” のキューに入れれば、そのフローはおそらく他のおしゃべりなエージェントと競合することになります。それゆえ、それぞれの優先度レベルが適切なシェア数 または Kubernetes API Server が処理できる全体の最大値の割合を持つことを確認し、リクエストが遅れすぎないようにしたいと思います。
優先度と公平性を実現するためのアクション
これは比較的新しい機能なので、多くの既存のダッシュボードは、最大 inflight read と 最大 inflight write の古いモデルを利用してます。なぜこれが問題になっているのでしょうか?
仮に、優先度が高いネームタグを kube-system 名前空間の全てのリソースに付けた場合、重要な名前空間内に悪いエージェントがインストールされたり、非常に多くのアプリケーションをデプロイしたりするとどうなるでしょう?回避しようとしていた同様の問題を抱えることになります。なので、目を離さないようにしましょう。
これらの種類の問題を追跡するために筆者が最も興味深いと思ういくつかのメトリクスを紹介します。
- 優先グループのシェアの何パーセントが利用されていますか?
- キュー内でリクエストが滞留した最長時間はどれぐらいですか?
- 最もシェアを利用するフローはどれですか?
- システムで予期しない遅延が発生してますか?
使用率
ここで、クラスターのデフォルトの優先グループとそれぞれが最大値の何パーセントを使用しているかを確認できます。
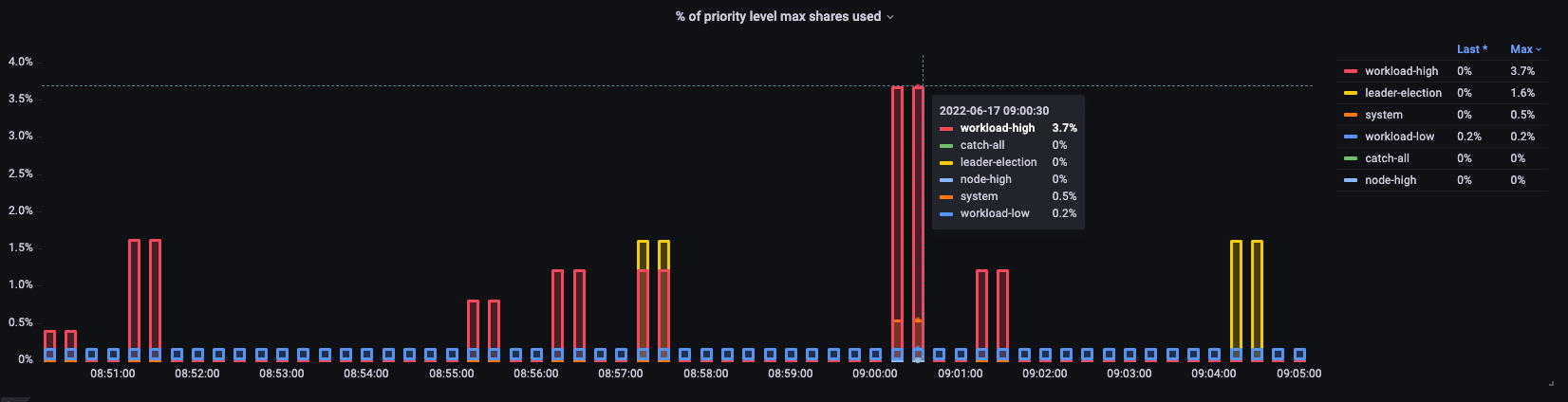
*Kubernetes 1.21 の新しいメトリクス
キュー内のタイムリクエスト
下記のチャートは、処理前に優先度付きキュー内にリクエストが存在した秒数を示します。

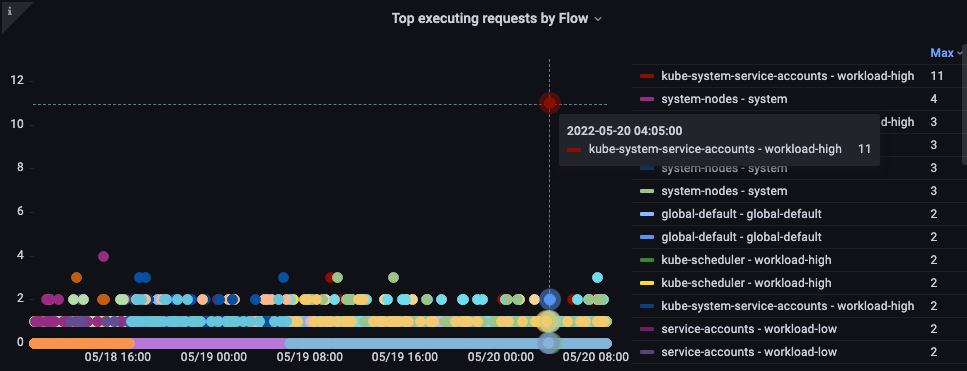
フロー別でトップの実行リクエスト
最もシェアを占めるフローはどれでしょう?
リクエスト実行時間
実行中に予期せぬ遅延がありましたか?

全体像
API レイテンシーの原因となるものの特性を理解したので、一歩下がって全体像を見ることができます。ダッシュボードのデザインは、もし調査すべき問題がある場合に素早くスナップショットを取得しようとするだけのものであることを覚えておくことが重要です。詳細な分析では、PromQLでアドホックなクエリを使用します。また、それ以上に良いのはクエリをロギングすることです。
高レベルメトリクスとして、どのようなものが考えられるでしょうか?
- どの API 呼び出しが完了までに最も時間がかかっていますか?
- 呼び出しは何をしていますか? ( オブジェクトのリスト化、オブジェクトの削除 etc )
- どのオブジェクトがそのオペレーションをしようとしていますか?( Pods, Secrets, ConfigMaps etc )
- API サーバー自身でレイテンシー問題が発生していますか?
- 優先度付きキューの 1 つで遅延があり、リクエストのバックアップが発生していますか?
- etcd サーバーで遅延が発生しているため、API サーバーが遅いように見えますか?
最も遅い API 呼び出し
下記のチャートでは、特定の期間で最も完了までに時間がかかった API 呼び出しを探しています。この場合、カスタムリソース定義 ( CRD ) は 05:40 の時間帯で最も潜在的な呼び出しである LIST 関数を呼び出していることがわかります。このデータを使用して、どのアプリケーションで発生しているかを確認し、その時間帯の監査ログから LIST リクエストを取り出すため CloudWatch Insights を用いることができます。
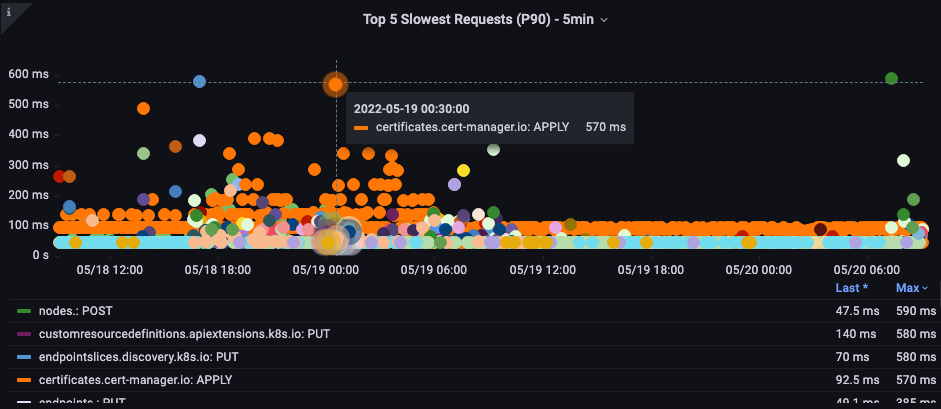
API リクエスト期間
いずれかのリクエストが 1 分のタイムアウト値に近づいている場合、この API レイテンシーチャートは、それを把握するのに役立ちます。折れ線グラフだと外れ値が隠れてしまうので、それが確認できる時間経過形式のヒストグラムが筆者は好きです。

バケットにカーソルを合わせるだけで、正確な値がわかります。下記の場合は、約 25 ミリセカンドかかっています。
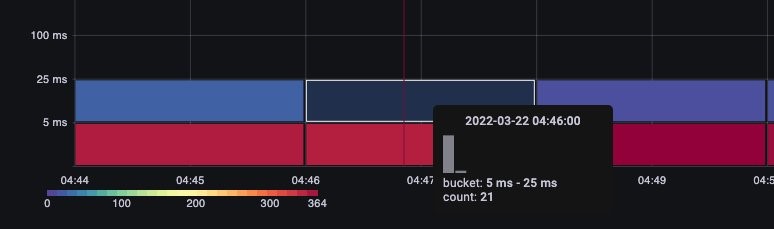
この概念は、リクエストをキャッシュする他のシステムと連携する場合に重要です。キャッシュリクエストは高速です。これらのリクエストのレイテンシーとより遅いリクエストのレイテンシーをマージしたくありません。このチャートでは、キャッシュされたリクエスト と キャッシュされていないリクエストの 2 つの明確な状況を見ることができます。

etcd リクエスト期間
etcd のレイテンシーは、Kubernetes のパフォーマンスにおいて最も重要なファクターの一つです。Amazon EKS では、request_duration_seconds_bucket メトリクスを見ることで API サーバー観点からこのパフォーマンスを見ることができます。

特定のイベントが相関しているかどうか確認することで、ここまで学んだことをまとめることができます。下記のチャートでは、API サーバーのレイテンシーが表示されていますが、その多くが etcd サーバーのレイテンシーだとわかります。チャートをちょっと見ただけで、正しい問題領域に素早く移動できることが、ダッシュボードを強力にする理由です。

結論
短時間でかなりの部分をカバーしました。もちろん、もっと検討や議論することはありますが、重要だと考える情報を表示するためのダッシュボードを作成する作業の足がかりになることを願っています。もし、ダッシュボードの作成が大変であるならば、ここから私がまとめたダッシュボードをダウンロードすることをオススメします。
Kubernetes の監視は好きですか?もしそうなら、こちらのダッシュボードもいくつかチェックしてみてください。もし、本番環境を監視する上で重要なことについての意見をもっていたり、共有したい良いヒントやトリックをもっているならば、私はあなたから話を聞いてみたいです。ぜひこちらまでご連絡ください。shancor@amazon.com
翻訳はソリューションアーキテクト祖父江が担当しました。原文はこちらです。