Amazon Web Services ブログ
Amazon Bedrock で TwelveLabs Marengo を使用した動画理解の実現
本記事は 2025 年 12 月 16 日 に公開された「Unlocking video understanding with TwelveLabs Marengo on Amazon Bedrock」を翻訳したものです。
メディア・エンターテインメント、広告、教育、企業研修などのコンテンツは、視覚、音声、動きの要素を組み合わせてストーリーを伝え、情報を届けます。個々の単語に明確な意味があるテキストと比べて、はるかに複雑です。このため、動画コンテンツを理解する必要がある AI システムには独自の課題が生じます。動画コンテンツは多次元的であり、視覚要素 (シーン、オブジェクト、アクション)、時間的ダイナミクス (動き、トランジション)、音声コンポーネント (会話、音楽、効果音)、テキストオーバーレイ (字幕、キャプション) を組み合わせています。この複雑さは、組織が動画アーカイブを検索したり、特定のシーンを見つけたり、コンテンツを自動的に分類したり、効果的な意思決定のためにメディア資産からインサイトを抽出したりする際に、大きなビジネス上の課題を生み出します。
このモデルは、異なるコンテンツモダリティに対して個別の埋め込みを作成するマルチベクトルアーキテクチャでこの問題に対処します。すべての情報を 1 つのベクトルに圧縮するのではなく、モデルは特化した表現を生成します。このアプローチにより、動画データの豊かで多面的な性質が保持され、視覚、時間、音声の各次元にわたってより正確な分析が可能になります。
Amazon Bedrock は、同期推論によるリアルタイムのテキストおよび画像処理で TwelveLabs Marengo Embed 3.0 モデルをサポートするように機能を拡張しました。この統合により、企業は自然言語クエリを使用したより高速な動画検索機能を実装できるようになり、高度な画像類似性マッチングによるインタラクティブな製品発見もサポートします。
この記事では、Amazon Bedrock で利用可能な TwelveLabs Marengo 埋め込みモデルが、マルチモーダル AI を通じて動画理解をどのように強化するかを紹介します。Marengo モデルからの埋め込みと、ベクトルデータベースとしての Amazon OpenSearch Serverless を使用して、動画のセマンティック検索および分析ソリューションを構築します。これにより、単純なメタデータマッチングを超えたセマンティック検索機能でインテリジェントなコンテンツ発見を実現します。
動画埋め込みの理解
埋め込みは、高次元空間でデータの意味的な意味を捉える密なベクトル表現です。これは、機械が理解し比較できる方法でコンテンツの本質をエンコードする数値的な指紋と考えることができます。テキストの場合、埋め込みは「king」と「queen」が関連する概念であること、または「Paris」と「France」に地理的な関係があることを捉えることができます。画像の場合、埋め込みは見た目が異なっていても、ゴールデンレトリバーとラブラドールがどちらも犬であることを理解できます。以下のヒートマップは、「two people having a conversation」、「a man and a woman talking」、「cats and dogs are lovely animals」という文章フラグメント間の意味的類似度スコアを示しています。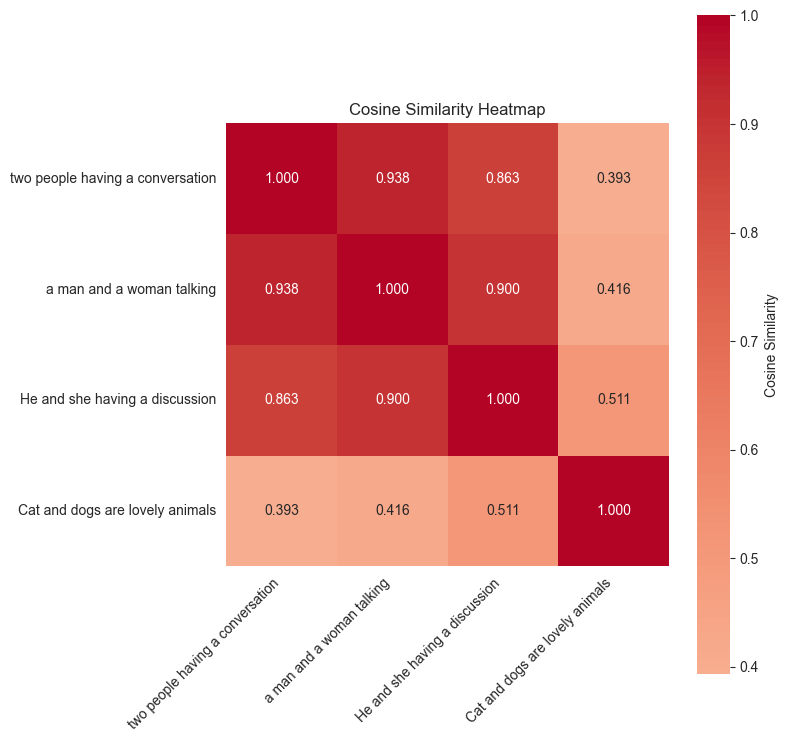
動画埋め込みの課題
動画は本質的にマルチモーダルであるため、独自の課題があります:
- 視覚情報: オブジェクト、シーン、人物、アクション、視覚的な美しさ
- 音声情報: 音声、音楽、効果音、環境音
- テキスト情報: キャプション、画面上のテキスト、音声から書き起こされたテキスト
従来の単一ベクトルアプローチでは、この豊富な情報をすべて 1 つの表現に圧縮するため、重要なニュアンスが失われることがよくあります。ここで TwelveLabs Marengo のアプローチがこの課題に効果的に対処する点でユニークです。
Twelvelabs Marengo: マルチモーダル埋め込みモデル
Marengo 3.0 モデルは、動画コンテンツのさまざまな側面を捉える複数の特化したベクトルを生成します。典型的な映画やテレビ番組は、視覚要素と聴覚要素を組み合わせて統一されたストーリーテリング体験を作り出します。Marengo のマルチベクトルアーキテクチャは、この複雑な動画コンテンツを理解するために大きな利点を提供します。各ベクトルは特定のモダリティを捉え、多様なデータタイプを単一の表現に圧縮することによる情報損失を回避します。これにより、視覚のみ、音声のみ、または組み合わせたクエリなど、特定のコンテンツの側面をターゲットにした柔軟な検索が可能になります。特化したベクトルは、複雑なマルチモーダルシナリオで優れた精度を提供しながら、大規模なエンタープライズ動画データセットに対する効率的なスケーラビリティを維持します。
ソリューション概要: Marengo モデルの機能
以下のセクションでは、コードサンプルを通じて Marengo の埋め込み技術の威力を実演します。これらの例は、Marengo がさまざまなタイプのコンテンツをどのように処理し、優れた検索精度を提供するかを示しています。完全なコードサンプルは、この GitHub リポジトリにあります。
前提条件
始める前に、以下を確認してください:
- 適切な権限を持つ AWS アカウント
- Amazon Bedrock へのアクセス
- OpenSearch Serverless コレクションとインデックスを作成するためのアクセス
- ベクトルデータベースと埋め込みに関する基本的な知識
サンプル動画
Netflix Open Content は、Creative Commons Attribution 4.0 International ライセンスの下で利用可能なオープンソースコンテンツです。Amazon Bedrock 上の TwelveLabs Marengo モデルのデモンストレーションには、Meridian という動画を使用します。

動画埋め込みの作成
Amazon Bedrock は、Marengo 動画埋め込み生成に非同期 API を使用します。以下は、S3 バケットの場所から動画を取得する API を呼び出す例を示す Python コードスニペットです。サポートされている完全な機能については、ドキュメントを参照してください。
上記の例では、1 つの動画から 280 個の個別の埋め込みが生成されます。各セグメントに 1 つずつ生成され、正確な時間的検索と分析が可能になります。動画からのマルチベクトル出力の埋め込みタイプには、以下が含まれる可能性があります:
- visual – 動画の視覚埋め込み
- transcription – 文字起こしされたテキストの埋め込み
- audio – 動画内の音声の埋め込み
音声または動画コンテンツを処理する際、埋め込み作成のために各クリップセグメントの長さを設定できます。デフォルトでは、動画クリップは自然なシーン変化 (ショット境界) で自動的に分割されます。音声クリップは、10 秒にできるだけ近い均等なセグメントに分割されます。例えば、50 秒の音声ファイルは 10 秒ずつの 5 セグメントになり、16 秒のファイルは 8 秒ずつの 2 セグメントになります。デフォルトでは、単一の Marengo 動画埋め込み API は visual-text、visual-image、audio 埋め込みを生成します。デフォルト設定を変更して、特定の埋め込みタイプのみを出力することもできます。Amazon Bedrock API で設定可能なオプションを使用して動画の埋め込みを生成するには、以下のコードスニペットを使用します:
ベクトルデータベース: Amazon OpenSearch Serverless
この例では、Marengo モデルを介して指定された動画から生成されたテキスト、画像、音声、動画の埋め込みを保存するためのベクトルデータベースとして Amazon OpenSearch Serverless を使用します。ベクトルデータベースとして、OpenSearch Serverless を使用すると、サーバーやインフラストラクチャの管理を心配することなく、セマンティック検索を使用して類似のコンテンツをすばやく見つけることができます。以下のコードスニペットは、Amazon OpenSearch Serverless コレクションを作成する方法を示しています:
OpenSearch Serverless コレクションが作成されたら、ベクトルフィールドを含むプロパティを持つインデックスを作成します:
Marengo 埋め込みのインデックス作成
以下のコードスニペットは、Marengo モデルからの埋め込み出力を OpenSearch インデックスに取り込む方法を示しています:
クロスモーダルセマンティック検索
Marengo のマルチベクトル設計により、単一ベクトルモデルでは不可能な異なるモダリティ間での検索が可能になります。視覚、音声、動き、コンテキスト要素に対して個別だが整合性のある埋め込みを作成することで、選択した入力タイプを使用して動画を検索できます。例えば、「jazz music playing」というクエリは、1 つのテキストクエリからミュージシャンの演奏動画クリップ、ジャズの音声トラック、コンサートホールのシーンを返します。
以下の例は、さまざまなモダリティにわたる Marengo の優れた検索機能を示しています:
テキスト検索
以下は、テキストを使用したクロスモーダルセマンティック検索機能を示すコードスニペットです:
テキストクエリ「a person smoking in a room」からの上位検索結果は、以下の動画クリップを返します:

画像検索
以下のコードスニペットは、指定された画像に対するクロスモーダルセマンティック検索機能を示しています:

上記の画像からの上位検索結果は、以下の動画クリップを返します:

動画に対するテキストと画像を使用したセマンティック検索に加えて、Marengo モデルは会話や音声に焦点を当てた音声埋め込みを使用して動画を検索することもできます。音声検索機能により、ユーザーは特定の話者、会話の内容、または話されているトピックに基づいて動画を見つけることができます。これにより、動画理解のためにテキスト、画像、音声を組み合わせた包括的な動画検索体験が実現します。
まとめ
TwelveLabs Marengo と Amazon Bedrock の組み合わせは、マルチベクトル、マルチモーダルアプローチを通じて動画理解の新しい可能性を切り開きます。この記事では、時間的精度を持つ画像から動画への検索や、詳細なテキストから動画へのマッチングなどの実践的な例を探りました。たった 1 回の Bedrock API 呼び出しで、1 つの動画ファイルをテキスト、視覚、音声クエリに応答する 336 個の検索可能なセグメントに変換しました。これらの機能は、自然言語によるコンテンツ発見、効率化されたメディア資産管理、および組織が大規模に動画コンテンツをより良く理解し活用するのに役立つその他のアプリケーションの機会を生み出します。
動画がデジタル体験を支配し続ける中、Marengo のようなモデルは、よりインテリジェントな動画分析システムを構築するための堅固な基盤を提供します。サンプルコードをチェックして、マルチモーダル動画理解がアプリケーションをどのように変革できるかを発見してください。
著者について
 Wei Teh は、AWS の機械学習ソリューションアーキテクトです。最先端の機械学習ソリューションを使用してお客様のビジネス目標達成を支援することに情熱を注いでいます。仕事以外では、家族とキャンプ、釣り、ハイキングなどのアウトドア活動を楽しんでいます。
Wei Teh は、AWS の機械学習ソリューションアーキテクトです。最先端の機械学習ソリューションを使用してお客様のビジネス目標達成を支援することに情熱を注いでいます。仕事以外では、家族とキャンプ、釣り、ハイキングなどのアウトドア活動を楽しんでいます。
 Lana Zhang は、AWS の Worldwide Specialist Organization に所属する生成 AI のシニアスペシャリストソリューションアーキテクトです。AI 音声アシスタントやマルチモーダル理解などのユースケースに焦点を当てた AI/ML を専門としています。メディア・エンターテインメント、ゲーム、スポーツ、広告、金融サービス、ヘルスケアなど、さまざまな業界のお客様と緊密に連携し、AI を通じてビジネスソリューションの変革を支援しています。
Lana Zhang は、AWS の Worldwide Specialist Organization に所属する生成 AI のシニアスペシャリストソリューションアーキテクトです。AI 音声アシスタントやマルチモーダル理解などのユースケースに焦点を当てた AI/ML を専門としています。メディア・エンターテインメント、ゲーム、スポーツ、広告、金融サービス、ヘルスケアなど、さまざまな業界のお客様と緊密に連携し、AI を通じてビジネスソリューションの変革を支援しています。
 Yanyan Zhang は、Amazon Web Services のシニア生成 AI データサイエンティストです。生成 AI スペシャリストとして最先端の AI/ML 技術に取り組み、お客様が生成 AI を使用して望む成果を達成できるよう支援しています。テキサス A&M 大学で電気工学の博士号を取得しました。仕事以外では、旅行、ワークアウト、新しいことの探求を楽しんでいます。
Yanyan Zhang は、Amazon Web Services のシニア生成 AI データサイエンティストです。生成 AI スペシャリストとして最先端の AI/ML 技術に取り組み、お客様が生成 AI を使用して望む成果を達成できるよう支援しています。テキサス A&M 大学で電気工学の博士号を取得しました。仕事以外では、旅行、ワークアウト、新しいことの探求を楽しんでいます。
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。