Amazon Web Services ブログ
Amazon Aurora PostgreSQL の共有プランキャッシュの使用
本記事は 2026 年 1 月 20 日 に公開された「Using the shared plan cache for Amazon Aurora PostgreSQL」を翻訳したものです。
本記事では、Amazon Aurora PostgreSQL 互換エディションの共有プランキャッシュ機能により、高い同時実行性環境で汎用 SQL プランのメモリ消費を大幅に削減できることを説明します。40GB のメモリ負荷を 400MB まで削減できます。
Aurora PostgreSQL データベースクラスターが数千の同時接続を処理し、それぞれが同じプリペアドステートメントを実行している状況を想像してください。クエリ自体はシンプルなのに、メモリ使用量が数十 GB まで増加しています。何が起きているのでしょうか。これはプランの重複による隠れたコストが発生している可能性があり、共有プランキャッシュで解決できます。
PostgreSQL の汎用プランを理解する
プリペアドステートメントは、アプリケーションで (データベースとやり取りする関数やメソッドを定義する際に) 一般的に使われます 。これらのステートメントは、データベースアクセスコードやメソッドに含まれます。準備フェーズには SQL ステートメントの構造とプレースホルダーが含まれ、アプリケーションがプリペアドステートメントを実行する際に実際の値が入ります。準備フェーズでステートメントが解析、分析、書き換えられるため、実行時の解析と分析作業の繰り返しが省けます。
ソリューションに入る前に、PostgreSQL がプリペアドステートメントをどう扱うかを理解しましょう。PostgreSQL と Aurora PostgreSQL では、プリペアドステートメントは 2 種類のプランで実行できます。
- カスタムプラン: 実行ごとに特定のパラメータ値で新しく作成され、リテラルが含まれます。
- 汎用プラン: パラメータに依存しないプランで、実行間で再利用され、リテラルは含まれません。
デフォルトでは、PostgreSQL はこれら 2 つのプランタイプの選択にインテリジェントなアプローチを用います。
- プリペアドステートメントの最初の 5 回の実行ではカスタムプランを使用
- これらのカスタムプランの平均コストを計算
- 6 回目の実行で汎用プランを作成
- 汎用プランのコストがカスタムプランの平均コストと同等かそれ以下なら、以降の実行で使用
このアプローチは頻繁に実行されるクエリのプラン作成時間を節約できますが、多数の同時データベース接続がある環境では隠れたコストが発生します。
問題: 大規模環境でのメモリ非効率
このアプローチは個々の接続ではうまく機能しますが、多数の同時データベース接続がある環境では 2 つの大きな非効率が生じます。
- 不要なプラン生成: 汎用プランが使われない場合 (カスタムプランの方が効率的なため) でも、コスト比較のためにシステムは汎用プランを作成してメモリに保存します。たとえば、パーティションテーブルでは、コストがリーフパーティションごとに計算されて合計されるため、汎用プランが使われない可能性が高くなります。
- プランの重複: 同じクエリが数百または数千のセッションで実行される場合、各セッションが同一の汎用プランのコピーを保持し、大量のメモリ重複が発生します。
この問題を具体例で示してみましょう。
テスト環境のセットアップ
この例では、新しいセッションで各 1000 パーティションを持つテーブル t1 と t2 を作成します。次に、各ループで 1000 個の値を挿入する処理を 100 回ループし、各テーブルに 100,000 行を挿入します。最後に両方のテーブルの統計情報を更新します。
注意: 共有プランキャッシュ機能を使うには、Aurora PostgreSQL バージョン 17.6 以降、またはバージョン 16.10 以降を使用する必要があります。
\gexec スイッチを使って、select の出力を独立した SQL ステートメントとして実行できます。\pset pager で psql pager を無効にすると、テーブルパーティション作成時に何度も Enter を押す必要がなくなります。
メモリ消費の観察
Session 1 で、次のプリペアドステートメントを作成して実行します。
次に、メモリ消費を確認します。
このテストでは、汎用プランが約 4MB を消費し、プリペアドステートメントが解放されるか接続が終了するまでメモリに残ることがわかります。
重複の問題
次に、別のセッション (Session 2) で同じプリペアドステートメントを実行します。
Session 2 も全く同じ汎用プランで 4MB を消費しています!
乗算効果
この重複は、プリペアドステートメントを実行するすべてのセッションで発生します。影響を計算してみましょう。
- 1 プリペアドステートメント × 100 接続 × 4MB = 400MB のメモリ
- 100 種類のプリペアドステートメント × 100 接続 × 4MB = 40GB のメモリ
この大量のメモリ消費は、セッションが同一の汎用プランのコピーを保存しているにもかかわらず発生します。多数の同時データベース接続がある環境では、利用可能なメモリをすぐに使い果たし、より大きく高価なインスタンスタイプを使わざるを得なくなります。
ソリューション: Aurora PostgreSQL 共有キャッシュプラン
Aurora PostgreSQL は共有キャッシュプラン (SPC) でこの問題を解決します。各汎用プランのコピーを 1 つだけ保持し、複数セッションが使えるようにします。プランキャッシュのパフォーマンス上の利点を維持しながら、メモリ消費を大幅に削減します。
共有プランキャッシュ (SPC) は、クラスターまたはインスタンスパラメータグループで有効にできます。
apg_shared_plan_cache.enable = ON
apg_shared_plan_cache.enable は動的パラメータであるため、変更を有効にするためにインスタンスを再起動する必要はありません。
SPC は動的ハッシュテーブルとして実装され、セッション間で共有されます。キャッシュ内のエントリ数は apg_shared_plan_cache.max で制御できます。次のパラメータでエントリの最小サイズと最大サイズも制御できます。
共有プランキャッシュの動作デモ
共有プランキャッシュを有効にして、先ほどの実験を繰り返してみましょう。
Session 1 (最初の接続):
最初のセッションは、ローカルメモリに 4MB のプランが表示されます (共有キャッシュに入力するために必要)。
Session 2 (後続の接続):
ローカルプランストレージなし! 2 番目のセッションは共有プランキャッシュを使っています。
キャッシュ使用状況の監視
次の SQL を実行して、キャッシュに保存された個々の共有プランが受け取ったキャッシュヒット数を表示します。各ヒットは、セッションメモリで重複する必要がなかったプランを表します。
クリーンアップ:
パフォーマンスへの影響
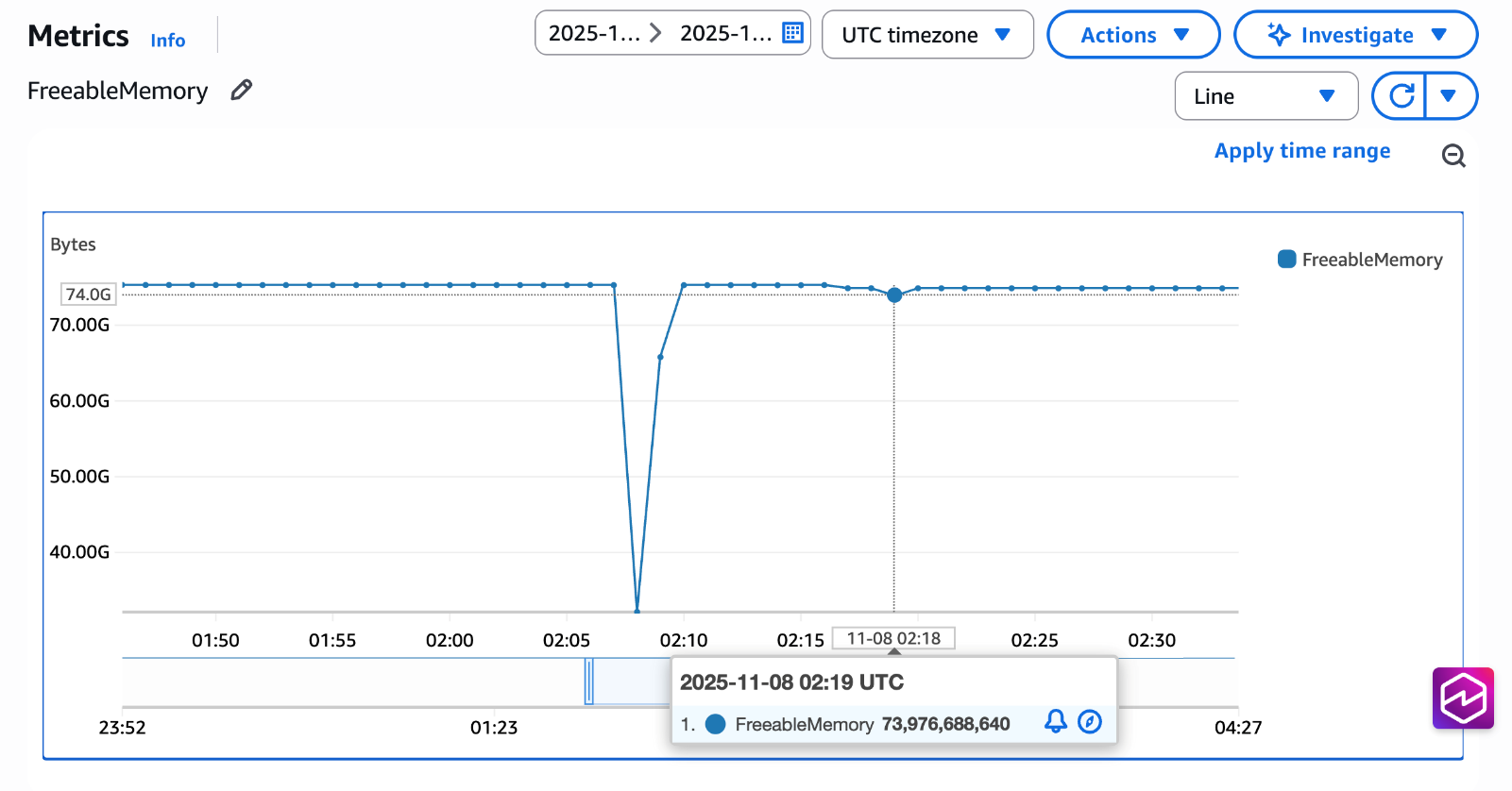
100 接続で 100 種類のプリペアドステートメントを使う先のシナリオ例では、40GB の重複プランストレージからわずか 400MB の共有キャッシュに変換されました。以下のスクリーンショットは、apg_shared_plan_cache.enable = off で 100 接続で 100 種類のプリペアドステートメント (上記の例から使用) を使って pgbench でテストを実行したインスタンスから取得した Freeable Memory CloudWatch メトリックのグラフです。02:05 から 02:10 の間に、FreeableMemory が約 40GB 減少しています。これは予想される重複プランストレージのフットプリントと一致します。共有プランキャッシュを有効にして同じテストを再度実行すると、メモリへの影響は大幅に削減され、40GB ではなくわずかなメモリしか必要としませんでした。
この削減により、次のことが可能になります。
- 同じワークロードをより小さいインスタンスで実行し、AWS コストを大幅に削減
- メモリ制限に達することなくより多くの同時接続をサポート
- トラフィックスパイク時のメモリ不足エラーを回避
ベストプラクティス
この機能は次の場合に特に有益です。
- アプリケーションが数百または数千のデータベース接続を維持している
- プリペアドステートメントを多用している
- クエリにパーティションテーブルや複雑な演算子 (join や共通テーブル式など) が含まれ、大きなプランが生成される
- バックエンドプロセスからの高いメモリ使用量が観察される
- ワークロードに、パラメータ化されたクエリを使用した反復的なクエリパターンがある
共有キャッシュプランは大きな利点を提供しますが、次のシナリオには適さない場合があります。
- 一意性が高いアドホッククエリを用いるワークロード
- プリペアドステートメントをほとんど再利用しないアプリケーション
- 同時接続が少ない環境
まとめ
本記事では、Aurora PostgreSQL で共有キャッシュプランを有効にする方法を説明しました。多数の同時データベースセッションでプリペアドステートメントを使用する際に、同じ汎用クエリプランがメモリに重複して保存されるのを防げることを示しました。
セッション間で冗長なプランストレージを削除することで、より小さいインスタンスでより多くの接続を実行でき、運用の複雑さとコストの両方を削減できます。さまざまなプランタイプの詳細については PostgreSQL ドキュメントの the prepare statement を、空きメモリ測定の詳細については Amazon CloudWatch metrics for Amazon Aurora を参照してください。
著者について
翻訳は Technical Account Manager の石渡が担当しました。