Amazon Web Services ブログ
OpenSearch スナップショットへのゼロコピー、調整不要のアプローチ
本記事は 2025 年 5 月 13 日 に公開された「Zero-copy, Coordination-free approach to OpenSearch Snapshots」を翻訳したものです。
Amazon OpenSearch Service は、顧客データのバックアップとリカバリのために、1 時間ごとの自動スナップショットを提供しています。スナップショットはポイントインタイムバックアップとして機能し、OpenSearch ドメインを以前の状態に復元してデータの耐久性とビジネス継続性を確保できます。スナップショット機能は不可欠ですが、スナップショットプロセスがドメインのコア操作に影響を与えずにシームレスに動作することも同様に重要です。スナップショットのワークフローは、検索とインデックス作成操作の最適なパフォーマンスを維持し、増大するワークロードに対応するドメインのスケーリング能力を保持し、クラスター全体の安定性をサポートするのに十分な効率性が求められます。
本記事では、Amazon OpenSearch Service のスナップショット効率を向上させながら、これらの重要な運用面を慎重に維持した方法について説明します。スナップショットの最適化は、バージョン 2.17 以降のすべての OpenSearch 最適化インスタンスファミリー (OR1、OR2、OM2) ドメインで有効になっています。
背景
OpenSearch の従来のスナップショットメカニズムでは、各シャードから Amazon Simple Storage Service (Amazon S3) に増分セグメントファイルをアップロードするプロセスが含まれます。ワークフローは、クラスターマネージャーノードがスナップショット作成を開始し、プライマリシャードを保持するノードと連携してそれぞれのスナップショットをキャプチャすることから始まります。プロセス全体を通じて、データノードはクラスターマネージャーノードと継続的に通信してスナップショットの進行状況を報告します。リーダー障害に対する耐障害性を提供するために、クラスター状態は進行中のすべてのスナップショットの詳細な追跡を維持します。クラスター状態はすべてのデータノードと共有されます。しかし、従来のアプローチは特に大規模なデプロイメントで大きな通信負荷をもたらします。
M 個のノードと N 個のプライマリシャードを持つクラスターを考えてみましょう。各スナップショット操作には少なくとも N 回のクラスター状態更新が必要で、クラスターマネージャーノードとデータノード間で M*N 回のトランスポート呼び出しが発生します (各プライマリシャードに対して 1 回のクラスター状態更新と、各更新に対して M 回のトランスポート呼び出しで構成)。次の図のように、数百のノードと数千のシャードを持つ大規模ドメインでは、集中的な通信パターンがクラスターマネージャーノードに過負荷を与え、他の重要なクラスター管理タスクを処理する能力に影響を与える可能性があります。
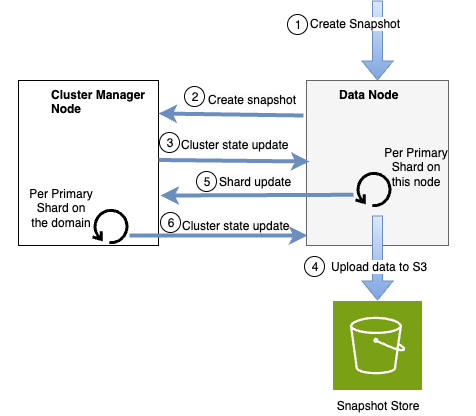
OpenSearch 最適化インスタンスファミリーは、データの耐久性とスナップショット効率において大きな進歩をもたらしました。11 ナインの耐久性で高スループットを提供するように構築された OpenSearch 最適化インスタンスは、インデックスされたすべてのデータのコピーを Amazon S3 に保持します。アーキテクチャ設計により、スナップショット作成時にデータを再アップロードする必要がなくなりました。代わりに、システムはスナップショットメタデータ内の既存のデータチェックポイントを参照します。データチェックポイントは、一貫性と耐久性を確保するために、特定の時点でのシャード上のデータの状態を追跡します。また、スナップショットメタデータで参照されているデータが Amazon S3 からクリーンアップされないようにしています。参照ベースのアプローチにより、従来の方法と比較してスナップショットが大幅に軽量化され、高速化されました。
OpenSearch 最適化インスタンスによる改善されたスナップショットフロー (shallow snapshot v1 とも呼ばれる) は、特定のシャードの各チェックポイントに対して明示的なロックファイルを作成することでチェックポイント参照を管理します。フローは次の図のとおりで、4 番目のステップでセグメントデータをアップロードする代わりに、チェックポイントロックファイルをアップロードします。
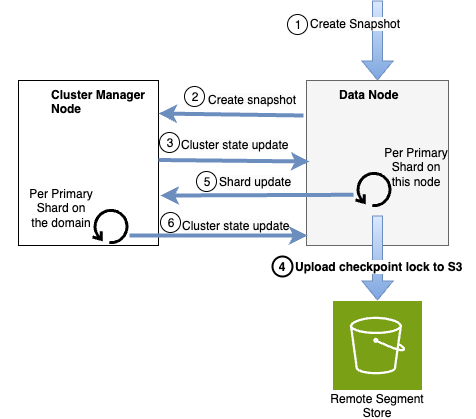
shallow snapshot v1 はセグメントデータのアップロードをチェックポイントロックファイルの作成に置き換えることでデータ冗長性の問題に対処しましたが、独自の課題も生じました。スナップショットの作成と削除操作中のノード間の通信負荷は変わりませんでした。さらに、システムはシャードがアクティブなトラフィックを受信しているかどうかに関係なく、各スナップショットのすべてのシャードに対してロックファイルを作成します。設計上、スナップショット操作中にシャードごとにロックファイルを作成するためのリモートストア呼び出しが過剰に発生し、大規模な OpenSearch ドメインでは特に問題となります。
改良された shallow snapshot (v2)
shallow snapshot v2 は、OpenSearch でのデータバックアップの処理方法を再考したものです。タイムスタンプベースの参照システムを実装することで、データの重複を削減しながら通信負荷を排除する、より効率的なアプローチを採用しています。次の図のように、shallow snapshot v2 では、シャードのリモートストアチェックポイントファイルに明示的なロックを設定する代わりに、スナップショットのタイムスタンプとチェックポイントファイルのタイムスタンプに基づいて暗黙的なロックを設定します。スナップショットタイムスタンプを pinned timestamp ファイルで追跡し、リモートストアにアップロードします。暗黙的なロックにより、pinned timestamp ファイル内のタイムスタンプと一致するチェックポイントは Amazon S3 からクリーンアップされません。アーキテクチャの変更により、データノードはクラスターマネージャーにシャード更新を送信する必要がなくなり、その後のクラスター状態更新も回避されます。スナップショットの復元プロセスは、スナップショットに対応する pinned timestamp ファイルを読み取ることで機能し、データノードが Amazon S3 から正しいバージョンのデータを見つけてダウンロードするのに役立ちます。
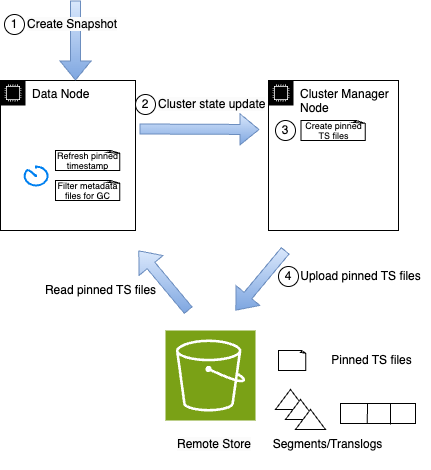
主なメリット
shallow snapshot v2 を使用する主な利点を見ていきましょう。
パフォーマンスの向上
shallow snapshot v2 のパフォーマンス上のメリットは大きく、多面的です。リモートストアにアップロードする必要があるデータ量と、スナップショット作成中にノード間で通信する必要があるクラスター状態更新の数を最小限に抑えることで、システムは I/O とネットワーク操作を大幅に削減します。削減により、スナップショット作成時間が短縮され、バックアップ操作中のシステムリソース使用率が低下します。
次の表の評価は、ドメインに大きな負荷がかかっている場合のスナップショット操作への影響を評価するために実施されました。
| ドメイン構成 | スナップショット作成時間 | |||
| ノード数 | シャード数 | 従来方式 | shallow snapshot v1 | shallow snapshot v2 |
| 10 | 100 | 15〜20 分 | 1〜2 分 | 1 秒未満 |
| 10 | 10,000 | 30〜40 分 | 5〜10 分 | 5 秒未満 |
| 100 | 100,000 | 1 時間以上 | 1 時間以上 | 10 秒未満 |
スケーラビリティ
スナップショット作成中のノード間通信呼び出し数が固定されているため、ノード、インデックス、シャード数が増加しても、スナップショット作成時間は 1 桁秒に収まります。Amazon OpenSearch Service ドメインで 1,000 ノードでテストした場合、shallow snapshot v2 の作成時間は 10〜20 秒でした。大規模な Amazon OpenSearch Service ドメインを管理する組織にとって、shallow snapshot v2 は特に有利です。shallow snapshot によるストレージコストの削減と shallow snapshot v2 による高速なスナップショット作成時間により、ストレージリソースを圧迫したりシステムパフォーマンスに影響を与えたりすることなく、より頻繁なバックアップを維持できます。
アーキテクチャの簡素化
shallow snapshot v2 のアーキテクチャの改善は、パフォーマンスの最適化にとどまりません。新しい実装は、より合理化された保守しやすいコードベースを特徴としており、問題のデバッグや将来の機能強化の実装に必要な労力を削減します。簡素化されたアーキテクチャにより、スナップショットと復元プロセスの複雑さが軽減され、コンプライアンス主導のシナリオや開発環境など、頻繁なバックアップを必要とするユースケースで、より信頼性の高い操作と潜在的な障害点の削減が実現します。つまり、ディザスタリカバリのための recovery point objective をより低く設定できます。shallow snapshot v2 の増分変更の効率的な処理により、パフォーマンスへの影響なしに、より細かいバックアップスケジュールを維持できます。
ストレージ効率
shallow snapshot v2 の基盤は、ストレージ管理への新しいアプローチです。変更されていないデータの複数のコピーを作成する代わりに、システムは既存のデータブロックへの適切な参照を維持します。暗黙的なタイムスタンプベースの参照カウントメカニズムにより、シャードごとに明示的なロックを作成する必要がなくなります。ストレージリソースが限られている環境では、shallow snapshot v2 のストレージ効率により大幅なコスト削減が可能です。参照ベースのアプローチにより、包括的なバックアップカバレッジを維持しながら、利用可能なストレージスペースを最適に使用できます。
今後の展望
shallow snapshot v2 の導入は、より効率的なデータバックアップソリューションへの取り組みの始まりです。shallow snapshot v2 によって作成されたフレームワークを基に、ポイントインタイムリカバリ (PITR)、クラスター状態統合の改善、さまざまなパフォーマンス最適化などの追加機能を実装できます。
まとめ
shallow snapshot v2 は、OpenSearch のバックアップ機能における大きな進歩です。ストレージ効率、パフォーマンスの向上、アーキテクチャの簡素化を組み合わせることで、現代のデータバックアップの課題に対する堅牢なソリューションを提供します。最適化インスタンスファミリーのインスタンスタイプを使用している場合、shallow snapshot v2 はすでに有効になっています。大規模なドメインを使用している場合でも、ストレージの制約内で作業している場合でも、shallow snapshot v2 は Amazon OpenSearch Service ドメインに具体的なメリットをもたらします。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。