- クラウドコンピューティングとは?›
- クラウドコンピューティングコンセプトのハブ›
- データベース
Cassandra と HBase の違いは何ですか?
Cassandra と HBase の違いは何ですか?
Apache Cassandra と Apache HBase は、非表形式でデータを保存する 2 つの NoSQL データベースです。どちらもビッグデータインフラストラクチャにデータをキーバリューストアとして保存し、大量のデータを正確かつ効率的に管理します。ただし、アーキテクチャ上の違いがあるため、さまざまなユースケースに適しています。たとえば、Cassandra では読み取りと書き込みのパフォーマンスが速く、HBase ではデータ整合性が向上します。HBase は、大規模なスパースデータセットの処理に非常に効果的です。組織は、さまざまなビッグデータのユースケースに Cassandra と HBase を使用しています。
類似点:カサンドラと HBase
Cassandra と HBase は、何十億ものデータセットを格納、処理、取得できる 2 つの NoSQL データベースです。これらには、次の分野で重複する類似点があります。
ビッグデータアプリケーション
Cassandra と HBase の両方で、大量の非構造化/非リレーショナルデータを保存できます。データを単純な列行に格納する従来のデータベースシステムとは異なります。Cassandra と HBase を使用して、画像、音声、ビデオ、およびその他の非構造化データタイプを保存して大規模処理を行うことができます。
オープンソース
Apache ソフトウェア財団は、Cassandra と HBase をオープンソースプロジェクトとして公開および管理しています。HBase は Google BigTable によって導入されたコンセプトに基づいて開発され、2008 年に Apache によって公開されました。Cassandra は、Facebook の受信トレイ検索の問題を解決するために作成されたイニシアチブです。BigTable の特定の機能と Amazon Dynamo の他の機能を使用しています。
スケーラビリティ
HBase クラスターにリージョンサーバーを追加することで、増大するデータ需要に合わせて HBase を拡張できます。NoSQL データベースシステムは、データノードが一定の容量を超えると、新しいリージョンにデータノードを分散できます。Cassandra クラスタは、データ管理機能を拡張するために複数のノードをサポートすることもできます。ノードを追加することで、データを効果的に均等に分散し、トラフィックのボトルネックを防ぐことができます。
データの復元
Cassandra と HBase の両方のデータノードはフォールトトレラントです。Cassandra では、各ノードがデータ複製をサポートしています。書き込み操作は、特定のデータに割り当てられているすべてのノードに自動的に実行されます。HBase にも同様のデータ複製アプローチがあり、実行されている Hadoop 分散ファイルシステム (HDFS) によって自動化されています。HDFS は、異なるサーバー上でデータの複製を作成し、管理します。両方の NoSQL データベースは、レプリケーション係数に基づいて異なる物理ネットワーク内のデータノードを複製し、ネットワーク全体の障害のリスクを軽減します。
書き込みパス
カサンドラと HBase はどちらもデータを列に整理します。データを保存する際、各データベースは関連情報をまとめた適切な列ファミリーを探します。どちらのデータベースも、データベースが列にデータを追加または保存するときに、ログファイルにデータを書き込みます。
アーキテクチャの違い: Cassandra とHBase
カサンドラと HBase は、CAP 定理の異なる特性で動作します。CAP 定理では、分散システムはいつでも次のうちの 2 つの特性を持つことができると規定されています。
- 整合性
- 可用性
- 分断耐性
大量のデータセットを格納するデータベースには分断耐性が必須であるため、Cassandra と HBase では可用性と一貫性が異なります。Cassandra はピアツーピアノード配置のため、可用性が高く、分断耐性の許容範囲も広くなっています。HBase では、単一の HBase プライマリがすべてのノードにデータを複製するため、分断耐性の許容範囲に一貫性を持たせることができます。
次に、両方のデータベースがデータ要求を管理する方法のアーキテクチャ上の違いをさらに説明します。
データモデル
Cassandra と HBase はどちらもデータをグループ、行、列に整理しますが、データベースごとにレイアウトが異なります。Cassandraでは、関連データの列は、キースペースと呼ばれるより広いカテゴリの行に格納されます。たとえば、Cassandra データベースには、次のようなキースペース、列ファミリー、セル配置が含まれている場合があります。
- キースペース:CustomerOrders
- カラムファミリー:クライアント
- ID, FirstName, LastName
- カラムファミリー:オーダー
- ID、アイテム、価格
- カラムファミリー:クライアント
クライアント列ファミリーは、注文列ファミリーの上のパーティションにあります。実際のアプリケーションでは、キースペースは複数のファミリー列を積み重ねます。
HBase アーキテクチャは、従来のリレーショナルデータベースと同様のレイアウトになっています。HBase では、各列ファミリーの ID を設定する代わりに、テーブル内の連続した行キーを使用します。次に、同じ列ファミリーに属する列を並べて配置し、データを簡単に取得できるようにします。次に例を示します。
- 表; CustomerOrders
- 行キー、列ファミリ:クライアント {First Name, LastName}、列ファミリ:注文 {商品、価格}
主要コンポーネント
Cassandraは、コンシステント・ハッシュと呼ばれる手法を使用して、各ノードがピア・ツー・ピア・ネットワーク内の特定のデータをすばやく見つけられるようにします。その主なコンポーネントには、memtable、コミットログ、SS テーブルが含まれます。これらが一緒になって、Cassandra アーキテクチャーのノード、データセンター、クラスターの書き込み経路を形成します。
HBase は HDFS の上にあります。HBase プライマリ、リージョンサーバー、Zookeeper を使用してデータ管理を行います。
Cassandra はデータ管理とデータストレージを独立して提供しますが、HBase はデータストレージ機能のために外部システムを必要とします。
コアデザイン
Cassandra は、各ノードが書き込みと要求に応答するアクティブ-アクティブアーキテクチャで動作します。特定のノードが要求されたデータを保存していなくても、ゴシッププロトコルと呼ばれるピアツーピア通信方法を使用して他のノードからデータを取得します。
HBase は、プライマリ/セカンダリのセットアップを使用します。このセットアップでは、HBase プライマリが他のノードのリージョンサーバーを制御します。HBase のアーキテクチャでは、HBase プライマリのレプリカがないと単一障害点になります。複数の HBase プライマリノードを複製できますが、すべてのリージョンサーバーを担当するのは 1 つだけです。
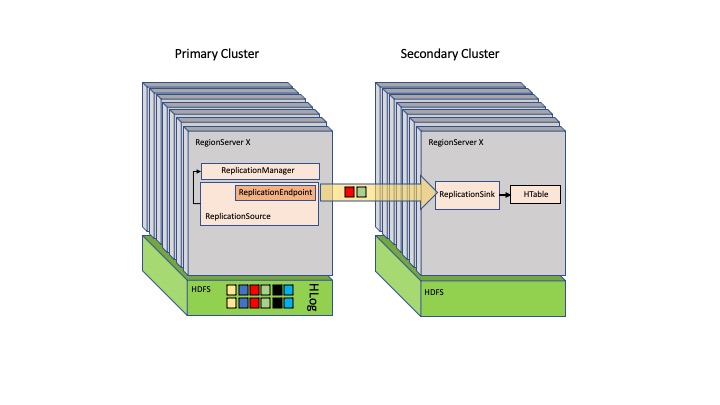
次の図は、HBase のプライマリ/セカンダリのセットアップを示しています。
クエリー言語
Cassandra は、Cassandra クエリー言語 (CQL) を使用してデータベース内のデータ操作を可能にします。CQL を使用すると、SQL と同様の説明文でレコードを追加、削除、または更新できます。HBase クエリ言語は、習得に手間がかかる基本的なシェルコマンドで構成されています。
パフォーマンス:カサンドラ vs.HBase
Cassandra と HBase はどちらも、ビッグデータ分析用の大規模データセットへの高速アクセスを提供します。データベースには、次の点でパフォーマンスの違いが示されています。
レイテンシー
レイテンシーは、データベースシステムに命令を送信してからデータを保存または取得するまでの時間ギャップです。一般的に、HBase はデータの読み取りと書き込みの回数が増えるほどレイテンシーが低くなります。Cassandra の場合は逆で、より多くのデータを取得するほど遅延が大きくなります。
スループット
スループットは、データベースが 1 秒間に処理する読み取りまたは書き込み操作の数を測定します。HBase は 10 ~ 20 万オペレーションという一貫したスループットを維持していますが、250,000 オペレーションに達すると増加することがわかります。Cassandra のスループットは、より多くのデータを書き込んだり読み込んだりするにつれて増加します。
読み取りパフォーマンス
Cassandra の読み取り操作では、格納されているデータの正確な位置をパーティションテーブル上で見つける必要があります。検索に二次キーまたは非パーティションテーブルが含まれる場合、Cassandra はクラスター内のすべてのノードを検索するのに時間がかかります。また、複数のノードに同じデータの異なるバージョンが含まれていると、データの不一致が発生します。
HBase はすべてのデータを単一のサーバーに書き込むため、Cassandra よりも読み取りパフォーマンスが優れています。Cassandra とは異なり、HBase でデータを読み取る場合、データベースシステムがパーティションテーブルを検索する必要はありません。HBase がデータの保存に使用する HDFS には、ブルームフィルターとブロックキャッシュが用意されているため、データ取得が高速化されます。
書き込みパフォーマンス
カサンドラは HBase よりも速く書き込み操作を完了します。Cassandra では、ログとキャッシュに同時にデータを書き込むことができます。HBase は同時書き込みをサポートしていません。代わりに、HBase クライアントアプリケーションが Zookeeper を経由して書き込み操作を開始し、HBase プライマリがデータを保存するためのアドレスを提供します。HBase に追加の手順があると、データ書き込み処理が遅くなります。
その他の主な違い:カサンドラ vs.HBase
Cassandra と HBase の両方を使用してデータサイエンスアプリケーションを構築できますが、わずかな違いがどちらを選択するかの決定に影響します。
セキュリティ
Cassandra では、レコードの行レベルへのアクセスを制限できます。また、ノード間のデータ交換を保護するための SSL 暗号化も提供します。Cassandra とは異なり、HBase にはセルレベルの暗号化、暗号化、認証機能が追加されています。
データのパーティション
Cassandra は順序付きパーティショニングをサポートしており、列をパーティションキーとして使用することで順番に順序付けられたレコードをスキャンできます。これは便利かもしれませんが、順序付けされたパーティショニングは、1 つのノードで複数の書き込みが行われるため、負荷分散が複雑になります。HBase テーブルは順序付きパーティショニングをサポートしていません。
ノード通信
Cassandra アーキテクチャでは、シードノードはクラスター間通信の重要なポイントです。これらのノードは、ゴシッププロトコルを使用して異なるクラスター間でデータを移動します。HBase は、アクティブな HBase プライマリノードを使用して、複数のリージョンサーバー間の通信を調整します。このアーキテクチャでは、データ移動は Zookeeper プロトコルによってネゴシエートされます。
使用タイミング、Cassandra とHBase
Cassandra データベースと HBase データベースはどちらも、さまざまなタイプのビッグデータアプリケーションに役立ちます。次に、さまざまな状況でどの分散データベースが他の分散データベースよりもうまく機能するかを共有します。
可用性と一貫性
Cassandra は、頻繁にデータを書き込む必要があるユースケースには適していますが、頻繁にデータを更新または削除するようには最適化されていません。たとえば、組織は Cassandra を使用してメッセージングシステム、インタラクティブなデータ処理ソリューション、およびリアルタイムのセンサーデータストレージを構築しています。HBase は、データ整合性と頻繁な処理を必要とするアプリケーションに適しています。たとえば、銀行、医療、通信ソリューションでは、HBase を使用して大量のデータを分析します。
データベースセットアップ
Cassandra は、必要なデータベースコンポーネントをすべて備えたスタンドアロン製品であるため、セットアップが簡単です。カサンドラとは異なり、HBase は Zookeeper、HDFS プライマリ、HDFS DataNode など、いくつかの Hadoop コンポーネントを使用して実行されます。設定は簡単かもしれませんが、実際のアプリケーションでは複数の相互依存関係を維持するのは難しい場合があります。すでに Hadoop インフラストラクチャを使用している場合は、HBase への移行が Cassandra への移行よりも簡単だと思うかもしれません。
違いのまとめ: Cassandra とHBase
|
Cassandra |
HBase |
|
|
コアデザイン |
アクティブ-アクティブアーキテクチャを使用します。すべてのノードが読み取り/書き込み要求を処理します。 |
一次/二次アーキテクチャを使用します。HBase プライマリは複数のリージョンサーバーを制御します。 |
|
主要コンポーネント |
メモリテーブル、コミットログ、および SS テーブル。 |
HBase プライマリ、リージョンサーバー、およびズーキーパー。 |
|
データモデル |
関連する列ファミリーの行をキースペースに格納します。 |
連続した行キーで水平に配置された列ファミリー。 |
|
クエリー言語 |
カサンドラクエリ言語を使用します。 |
シェルコマンドを使用します。 |
|
レイテンシー |
データフェッチが多いほど待ち時間が長くなります。 |
より多くのデータ操作でレイテンシを低減。 |
|
スループット |
データ操作が多いほどスループットは向上します。 |
一定回数の操作を行うと、スループットは向上します。 |
|
読み取りパフォーマンス |
読み込みが遅い。読み取り場所のパーティションテーブルを参照します。データの不一致が発生する可能性があります。 |
読み取りパフォーマンスとデータ整合性が向上します。 |
|
書き込みパフォーマンス |
書き込みパフォーマンスが向上しました。ログとキャッシュに同時に書き込みます。 |
その他の手順。ズーキーパーと HBase プライマリを経由します。 |
|
セキュリティ |
ロールレベルまでアクセスを規制します。 |
アクセスをセルレベルまで規制します。 |
|
データのパーティショニング |
順序付けられたパーティショニングをサポートします。 |
順序付けられたパーティショニングはサポートしていません。 |
|
ノード通信 |
ゴシッププロトコルを使用します。 |
ズーキーパープロトコルを使用します。 |
AWS は御社の Cassandra と HBase の要件にどのように対応できますか?
Amazon Web Services (AWS) は、データサイエンステクノロジを効率的かつ手頃な価格で実装するために使用できるスケーラブルなクラウドデータベースサービスを提供します。基盤となるインフラストラクチャを手動でプロビジョニングする代わりに、次の AWS サービスを使用して Cassandra および HBase データベースをサポートできます。
- Amazon キースペース (Apache Cassandra 用) は、高スループットの Cassandra ワークロードを実行するためのオンラインデータベースサービスです。Amazon Keyspaces を使用すると、応答時間を 1 桁ミリ秒の応答時間で維持しながら、アプリケーションをスケーリングできます。
- Amazon EMR では、大規模なデータ処理アプリケーション用に HBase クラスターをデプロイできます。EMR で HBase を実行すると、 Amazon シンプルストレージサービス (Amazon S3) に保存されたデータをバックアップできるため、データの回復性が向上します。
今すぐアカウントを作成して、AWS でのビッグデータ分析を始めましょう。