AWS Database Blog
Using the MariaDB JDBC driver with Amazon Aurora with MySQL compatibility
September 2023 update: Version 3.0.3 of the MariaDB JDBC Driver (Connector/J) no longer supports Amazon Aurora. We recommend using the AWS Advanced JDBC Wrapper Driver . The Amazon Web Services JDBC Driver has been redesigned as an advanced JDBC wrapper. This wrapper is complementary to and extends the functionality of an existing JDBC driver to help an application take advantage of the features of clustered databases such as Amazon Aurora.
This blog post demonstrates how to use the MariaDB JDBC driver, known as MariaDB Connector/J, to connect to an Amazon Aurora cluster. In this post, we use the automatic failover capability of the connector to switch rapidly and seamlessly between master and replica in a failover situation. You can download MariaDB Connector/J from the MariaDB site.
Connecting to Aurora MySQL using MariaDB Connector/J
At the time of writing, the latest version of the connector is MariaDB Connector/J 2.3.0. You can install the connector in two ways:
- Through a package manager like Maven or Gradle
- Using the .jar file directly
In this blog post, we use a .jar file. You can find the complete installation guide on the MariaDB site.
After installing the connector, the next step is to create an Aurora MySQL cluster. First, sign in to the AWS Management Console. Choose RDS, then choose Databases, and then choose Create database. On the next page, leave the default selection for the Engine options as Amazon Aurora and choose the MySQL 5.6-compatible or MySQL 5.7-compatible edition. Fill out all required information until you are ready to choose Create database.
You should be able to see your Aurora cluster at the root level with your master and replica endpoints underneath it. It should look similar to the screenshot following.

For testing the connection, I will demonstrate two ways:
- Connecting to Aurora MySQL using an open source DB management tool
- Connecting to Aurora MySQL from a Java program
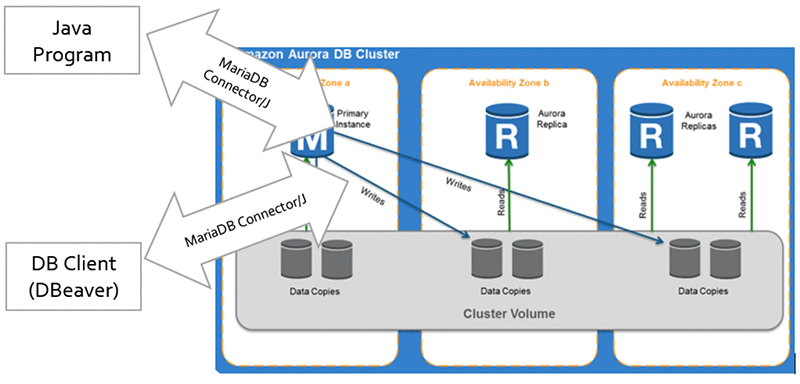
Use an open source DB management tool like DBeaver
To connect, you can use an open-source database management tool such as DBeaver. To access DBeaver, see this GitHub repo.
To use DBeaver, open the tool and create a new connection. For the connection type, choose MariaDB under AWS and fill out the requested information. For guidance, see the screenshot following.
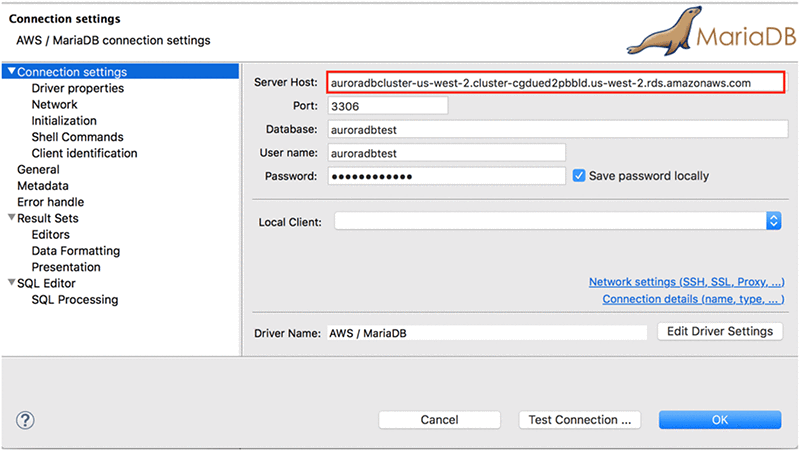
For Server Host, for versions 1.5.1 and later specify the cluster endpoint, for example:
auroradbcluster-us-west-2.cluster-cgdued2pbbld.us-west-2.rds.amazonaws.com
As stated in the Failover and High Availability with MariaDB Connector/J guide, using the cluster endpoint enables the driver to automatically discover the master and replicas of this cluster from the current cluster endpoint at connection time. Doing this enables you to add new replicas to the cluster instance, which are discovered without changing your driver configuration.
In versions before 1.5.1, cluster endpoint use was discouraged. In those versions, when a failover occurs, this cluster endpoint can point for a limited time to a host that is not the current master any more. The old recommendation was to list all specific endpoints. This kind of URL string still works, but now the recommended URL string specifies the cluster endpoint.
Add the .jar file mariadb-java-client-2.3.0.jar to the DBeaver libraries from your local computer. Doing this is required for connecting to Aurora MySQL.
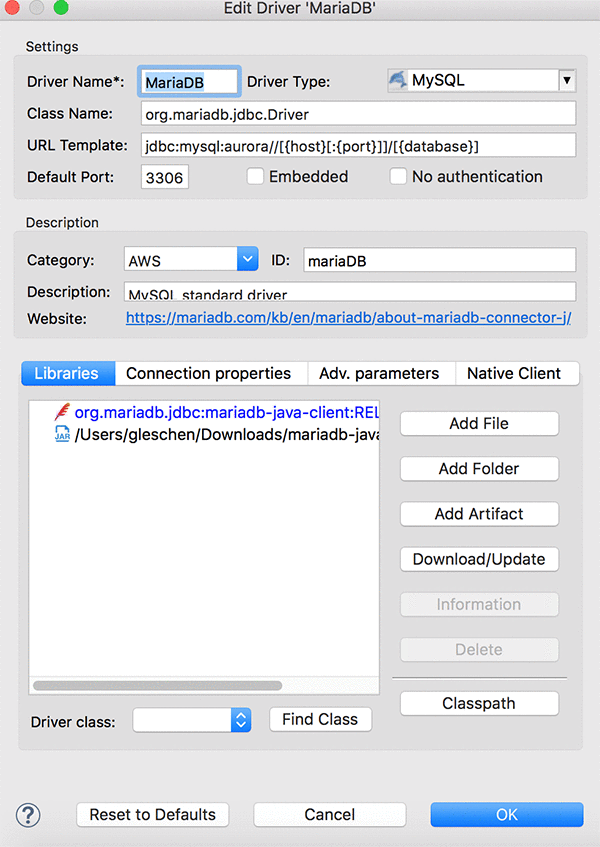
After uploading the jar file and filling out the mandatory fields, make sure you test the connection and receive confirmation that you are connected, as shown in the screenshot below.

After connecting, expand the Databases menu, which shows you the auroradbtest instance with no tables.

In the next step, we run the Java program, which creates a table in our database. We then go back and check in DBeaver to ensure that the table has been created.
Use a Java program from eclipse to connect to an Aurora MySQL instance
To connect using a Java program from eclipse, just as with the DB tool (DBeaver), we need to first install the JDBC driver for MariaDB. To do this, the following steps:
- In eclipse, right-click the project (auroradb), then choose Build Path, Configure Build Path to open the properties window for your project.
- Choose the Libraries
- Choose Add External JARs to upload the MariaDB Connector/J (.jar file) that you downloaded and saved on your local computer in the previous step.


I use the following Java code to connect to Aurora MySQL and run a query to create a VENDORS table in the auroradbtest database.
We need to make sure to include the packages containing the JDBC classes. This is done with the following line of code: import java.sql.*;
Run the program on eclipse and check that it runs fine on the console.

Next, check the DBeaver tool to verify that a table has been created. From the screenshot below, we can now see a new table, VENDORS, under our auroradbtest DB with three columns (name, CEO and VAT_Number).

We have just demonstrated how to use the MariaDB JDBC driver known as MariaDB Connector/J to connect to an Aurora MySQL DB in two ways: first with an open-source client (DBeaver) and then with a small Java program.
Working with failover
In the second part of this blog post, we demonstrate how the MariaDB Connector/J failover capability works with Aurora automatic failover.
To do that, let’s first modify our Java program so it runs a query. This query reads from the INFORMATION_SCHEMA table which endpoint (master or replica) the current connection is pointing to.
Each Amazon Aurora DB cluster is a master/replicas DB cluster composed of one master instance with a maximum of 15 replica instances. Amazon Aurora includes automatic promotion of a replica instance in case of the master instance failing. The MariaDB connector/J implementation for Aurora is specifically designed to handle this automatic failover.
The format of the JDBC connection string is as follows:
jdbc:mariadb:aurora://[clusterInstanceEndPoint[:port]]/[database][?<key1>=<value1>[&<key2>=<value2>]…]
Here <hostDescription> represents the DNS of the nodes (master and slaves separated by a comma).
Notice that in the program, we use the keyword aurora in the connection URL:
This instructs the driver to use Aurora failover support.
After running the preceding Java program and also the SELECT SERVER_ID, SESSION_ID FROM INFORMATION_SCHEMA.REPLICA_HOST_STATUS"; query from DBeaver, we get the following results from the eclipse console and DBeaver respectively.

We can see from the preceding screenshots that the current sessions are hooked to the master endpoint.
Now let’s try to run a query to insert data into the VENDORS table created in the previous step. To better illustrate the failover scenario, we connect to each node endpoint separately and run queries to try adding data to the VENDORS table. That way, we can show that we can’t insert data to the database while connected to the replica endpoint because it has read-only permissions.
Let’s connect to the master endpoint as shown in the screenshot following:

Next, run the query SELECT * FROM VENDORS; to ensure that the table is empty before inserting data.

As seen in the preceding screenshot, our VENDORS table is empty. Now let’s run the following query to insert data in the table:









Running the Java program from eclipse also provides the same output as shown in the screenshot following. The output of the Java program is similar to the query run in DBeaver displayed in the previous screenshot.

From the screenshots preceding, we can see the results of the query. These show that the driver that was using the connection to the master endpoint has switched automatically to the replica. After simulating the failover from the AWS console, the replica now has the MASTER_SESSION_ID, which changed the role of the replica to writer.
Now let’s rerun the insert query to add data to the VENDORS table while connected to the replica endpoint that has now been promoted to master.

This time the query runs fine and we can see from the SELECT * FROM VENDORS; query that data has been inserted in the table as shown in the screenshot following:

In the same way if we switch the connection in DBeaver to the master endpoint and try to run the INSERT query we get an error as shown in the screenshot following:


In summary, this blog post explains how to use the MariaDB JDBC driver to connect to Aurora MySQL. It demonstrates how to make the best use of the driver and take advantage of its fast and seamless failover capabilities.
 Georges Leschener is a Partner Solutions Architect in the Global System Integrator (GSI) team at Amazon Web Services. He works with our GSIs partners to help migrate customers’s workloads to AWS cloud, design and architect innovative solutions on AWS by applying our best practices.
Georges Leschener is a Partner Solutions Architect in the Global System Integrator (GSI) team at Amazon Web Services. He works with our GSIs partners to help migrate customers’s workloads to AWS cloud, design and architect innovative solutions on AWS by applying our best practices.