Amazon Web Services 한국 블로그
Amazon Aurora Storage 엔진 소개
Amazon Aurora는 re:Invent 2014에서 발표한 이후, 2015년 7월에 정식으로 출시 및 2016년 4월 1일 서울 리전에 출시함으로써 국내외 많은 고객들이 RDBMS가 필요한 워크로드에 이미 도입을 하였거나 현재 도입을 고려하고 있습니다. Amazon Aurora는 AWS 역사상 가장 빠른 성장세를 보이고 있는 서비스 입니다. Amazon Aurora의 빠른 성능과 안정성을 지원하는 핵심인 Aurora 스토리지 엔진에 대한 좋은 블로그 글을 소개합니다.
원문은 AWS Database Blog의 Introducing the Aurora Storage Engine (https://aws.amazon.com/blogs/database/introducing-the-aurora-storage-engine/)입니다.
Amazon Aurora 는?
Amazon Aurora 는 고성능 상용 데이터베이스의 속도와 가용성에 오픈소스 데이터베이스의 간편성과 비용 효율성을 결합한 MySQL 호환 관계형 데이터베이스 서비스입니다. Amazon Aurora는 MySQL 보다 5배 뛰어난 성능과 상용 데이터베이스의 보안성, 가용성 및 안정성을 10분의 1의 비용으로 제공합니다. Aurora 에는 곧 출시 될 PostgreSQL 호환 에디션이 평가판으로 제공됩니다.
이 글에서 우리는 Aurora가 이러한 성능, 가용성 및 안정성을 제공할 수 있는 혁신적인 기술 중 하나인 스토리지 계층에 대해서 깊이 살펴볼 것입니다.
데이터베이스 스토리지의 진화
많은 고객들이 Direct Attached Storage(DAS)를 사용하여 데이터베이스 데이터를 저장합니다. 대기업 고객은 Storage Area Network(SAN)을 사용하기도 합니다. 이러한 접근 방식에는 다음과 같은 여러가지 문제가 있습니다:
- SAN은 비용이 많이 듭니다. 많은 수의 소규모 고개들은 SAN을 관리하는데 필요한 물리적인 SAN 인프라 또는 스토리지 전문성을 확보하기 힘듭니다.
- 디스크 스토리지는 성능을 위해 수평 확장이 복잡합니다. 효율적으로 운영하더라도, DAS와 SAN은 확장할 수 있는 한계가 여전히 존재합니다.
- DAS 및 SAN 인프라는 단일 물리적 데이터 센터에 존재합니다. 정전이나 네트워크 중단으로 단일 데이터 센터가 손상되면 데이터베이스 서버를 사용할 수 없습니다.
- 홍수, 지진 또는 기타 자연 재해로 인해 데이터 센터가 파괴되면 데이터가 손실 될 수 있습니다. 데이터 백업을 오프 사이트에 보관하면 새 위치에서 데이터베이스 서버를 다시 온라인 상태로 복구하는 데 몇 분에서 며칠 정도 걸릴 수 있습니다.
Amazon Aurora 스토리지 엔진 소개
Amazon Aurora는 클라우드를 활용하도록 설계되었습니다.
개념적으로 Amazon Aurora 스토리지 엔진은 한 리전(Region)의 여러 AWS 가용 영역(Availability Zone)에 걸친 분산된 SAN 입니다. AZ는 단일 또는 복수개의 물리적 데이터 센터로 구성된 논리적 데이터 센터입니다. 각 AZ는 해당 리전의 다른 AZ와의 신속한 통신을 가능하게 하는 낮은 대기시간 링크를 제외하고는 다른 AZ와 완벽히 격리됩니다. Amazon Aurora의 핵심인 분산형 저 지연 스토리지 엔진은 여러 AZ에 걸쳐서 구성됩니다.
스토리지 할당
Amazon Aurora는 보호 그룹(protection groups) 이라고 하는 10GB 논리 블록에 스토리지 볼륨을 구축합니다. 각 보호 그룹의 데이터는 6개의 스토리지 노드에 복제됩니다. 그런 다음 해당 스토리지 노드는 Amazon Aurora 클러스터가 운영되는 리전의 3개 AZ에 할당됩니다.
클러스터가 생성된 직후에는 스토리지가 거의 사용되지 않습니다. 데이터 양이 증가하여 현재 할당된 스토리지를 넘어서면 Aurora는 요건을 충족시키기 위해 볼륨을 자연스럽게 확장하고 필요에 따라 새로운 보호 그룹을 추가합니다. Amazon Aurora는 64TB라는 현재의 제한에 도달 할 때까지 이러한 방식으로 계속 확장합니다.

Amazon Aurora 가 쓰기를 처리하는 방법
Amazon Aurora에 데이터를 쓰면 6개의 스토리지 노드로 병렬로 전송됩니다. 이러한 스토리지 노드는 세 개의 AZ에 분산되어 있어 내구성과 가용성을 크게 향상시킵니다.
각 스토리지 노드에서 레코드는 먼저 인-메모리(in-memory) 큐에 들어갑니다. 이 큐의 로그 레코드는 중복 제거됩니다. 예를 들어, 마스트 노드가 스토리지 노드에 성공적으로 쓰고 난 후, 마스터 노드와 스토리지 노드 사이의 연결이 중단 된 경우 마스터 노드는 로그 레코드를 재전송 하지만 중복된 로그 레코드는 폐기됩니다. 보관할 레코드는 핫 로그(hot log)에서 디스크에 저장됩니다.
레코드가 지속 된 후, 로그 레코드는 업데이트 큐라는 인-메모리 구조에 기록됩니다. 업데이트 큐에서 로그 레코드는 먼저 병합 된 다음 데이터 페이지로 만들어 집니다. 하나 이상의 로그 시퀀스 번호(LSN)가 누락 된 것으로 판단되면 스토리지 노드는 볼륨의 다른 노드에서 누락 된 LSN을 검색하는 프로토콜을 사용합니다. 데이터 페이지가 갱신 된 후 로그 레코드가 백업되고 가비지 컬렉션으로 표시됩니다. 그리고 데이터 페이지는 비동기식으로 Amazon S3에 백업됩니다.
핫 로그에 기록되어 쓰기가 지속되면 스토리지 노드는 데이터 수신을 확인합니다. 6개 스토리지 노드 중 4개 이상이 수신 확인을 하면 쓰기 작업은 성공한 것으로 간주되고 답신은 클라이언트 애플리케이션에 반환됩니다.
Amazon Aurora가 다른 엔진보다 빠르게 쓸 수 있는 이유 중 하나는 스토리지 노드에만 로그 레코드를 보내고 이러한 쓰기 작업이 병렬로 수행된다는 것입니다. 실제로 MySQL과 비교할 때, Amazon Aurora는 데이터가 6개의 다른 노드에 쓰여지고 있지만 유사한 워크로드 대해 IOPS가 약 1/8 정도 필요합니다.
이 모든 작업의 단계는 비동기적으로 진행됩니다. 쓰기는 지연을 줄이고 처리량을 향상시키기 위해 그룹 커밋(Group Commit)을 사용하여 병렬로 수행됩니다.
쓰기 대기 시간이 짧고 입출력 풋프린트(footprint)가 줄어든 Amazon Aurora는 쓰기 집약적인 애플리케이션에 이상적입니다.
내결함성(Fault Tolerance)
다음 다이어그램은 3개의 AZ에 저장된 데이터를 보여줍니다. 복제 된 데이터는 99.999999999%의 내구성을 제공하도록 설계된 Amazon S3에 지속적으로 백업됩니다.

이 설계는 Amazon Aurora가 클라이언트 애플리케이션에 대한 가용성 영향 없이 전체 AZ 또는 2개의 스토리지 노드에 대한 손실을 견딜 수 있게 합니다.
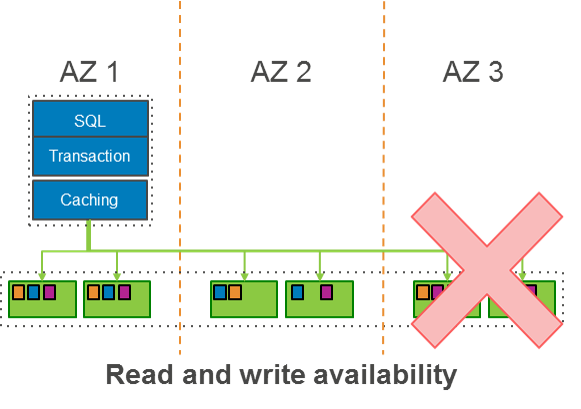
복구 과정에서 Aurora는 데이터 손실없이 보호 그룹에 있는 AZ와 또 다른 스토리지 노드의 손실에 견딜 수 있도록 설계되었습니다. 보호 그룹에 있는 4개의 스토리지 노드가 가용할 경우에만 Aurora 에서 쓰기가 지속되기 때문입니다. 쓰기를 수신 한 3개의 스토리지 노트가 다운 된 경우에도 Aurora는 4번째 스토리지 노드에서 쓰기를 계속 복구할 수 있습니다. 복구 중에 읽기 쿼럼(read quorum)을 유지하기 위해서, Aurora는 3개의 스토리지 노드가 동일한 LSN을 따라잡을 수 있도록 합니다. 그러나 쓰기 작업을 위해 볼륨을 액세스 하기 위해서, Aurora는 4개의 스토리지 노드가 복구 될 때까지 기다려야하므로 향후 쓰기를 위해 쓰기 쿼럼(write quorum)을 획득할 수 있습니다.

읽기의 경우, Aurora는 읽기를 수행하기 위해 가장 가까운 스토리지 노드를 찾습니다. 각 읽기 요청은 타임 스탬프, 즉 LSN과 관련됩니다. 스토리지 노드는 LSN까지 따라잡은 경우(즉, 해당 LSN까지 모든 업데이트를 수신 한 경우) 읽기를 수행 할 수 있습니다.
하나 이상의 스토리지 노드가 다운되었거나 다른 스토리지 노드와 통신 할 수 없는 경우 해당 노드는 가십 프로토콜(gossip protocol)을 사용하여 온라인 상태가 되면 다시 동기화 합니다. 스토리지 노드가 손실되고 새 노드가 자동으로 만들어지면 가십 프로토콜을 통해 동기화 됩니다
Amazon Aurora를 사용하면 컴퓨팅 및 스토리지가 분리됩니다. 이를 통해 읽기 복제본(read replica)은 복제본 자체의 데이터를 유지하지 않고도 스토리지 계층에 대한 컴퓨팅 인터페이스로 작동 할 수 있습니다. 이렇게 하면 모든 데이터를 동기화 할 필요없이 인스턴스가 온라인 상태가 되는 즉시 읽기 복제본에서 트래픽 처리를 시작할 수 있습니다. 마찬가지로 읽기 복제본의 손실은 기본 데이터에 영향을 미치지 않습니다. 그리고 읽기 복제본이 마스터 노드가 되더라도 데이터 손실이 없습니다. Amazon Aurora는 최대 15개의 읽기 복제본을 지원하고, 읽기 복제본에 내장된 로드 밸런싱 기능을 통해 고 가용성 및 읽기 집약적인 워크로드에 이상적입니다.
백업 및 복구
Amazon Aurora를 사용하면 최종 사용자의 성능에 영향을 미치지 않으면서 데이터가 실시간으로 S3로 계속 백업됩니다. 따라서 백업 윈도우와 자동화된 백업 스크립트가 필요하지 않습니다. 또한 사용자가 사용자 정의 백업 보유기간 중 어느 시점 으로든 복원할 수 있습니다. 이와 더불어, 여러 데이터 센터에 데이터를 복제하여 99.999999999%의 내구성을 제공하도록 설계된, 내구성이 뛰어난 저장소인 S3에 모든 백업이 저장되기 때문에 데이터 손실 위험이 크게 줄어 듭니다.
때때로 사용자는 특정 시점에서 Aurora 클러스터의 데이터 스냅샷을 만들고 싶어합니다. Amazon Aurora를 사용하면 성능에 아무런 영향을 미치지 않고서 이 작업을 수행 할 수 있습니다.
Amazon Aurora 백업에서 복원할 때 각 10GB 보호 그룹은 병렬로 복원됩니다. 또한 보호 그룹이 복원된 후에는 로그를 다시 적용할 필요가 없습니다. 즉, Amazon Aurora 는 보호 그룹이 복원되자 마자 최고 성능으로 동작할 수 있습니다.
보안
Amazon Aurora를 사용하면 업계 표준인 AES-256 암호화를 사용하여 모든 데이터를 암호화 할 수 있습니다. 사용자는 AWS 키 관리 서비스(AWS KMS)를 사용하여 키를 관리할 수 있습니다. Amazon Aurora 클러스터에 TLS 연결을 통해 데이터를 안전하게 전송할 수 있습니다. 이러한 기능 외에도 Amazon Aurora는SOC 1, SOC 2, SOC 3, ISO 27001/9001, ISO 27017/27018 및 PCI를 포함한 여러 인증/증명을 보유하고 있습니다.
결론
Amazon Aurora는 클라우드를 위해 설계되었습니다. Amazon Aurora는 여러 AZ에 데이터를 분산시킴으로써 매우 견고하고 가용성이 높은 데이터베이스 엔진을 제공합니다. 데이터가 저장되는 방법과 장소의 많은 혁신으로 인해 읽기 및 쓰기 처리량이 다른 관계형 데이터베이스 엔진보다 크게 향상되었습니다. 데이터베이스 복원 작업이 발생할 때의 속도도 마찬가지 입니다. 마지막으로 Amazon Aurora는 관리형 서비스이기 때문에 AWS가 백업, 패치 및 스토리지 관리 등의 차별성 없는 어려운 업무들(undifferentiated heavy lifting)을 처리해 드립니다.
지금 바로 Amazon Aurora 콘솔에서 시작하십시오 :
최신 기능 중 일부를 포함하여 Amazon Aurora에 대한 자세한 내용을 보려면 아래 강연 동영상을 참고하세요.
- AWS Summit Seoul 2016 – 관계형데이터베이스의 새로운 패러다임 : Amazon Aurora
- AWS CLOUD 2017 | Amazon Aurora를 통한 고성능 데이터베이스 운용하기
- AWS Summit 2017 Amazon Aurora 성능 향상 및 마이그레이션 모범 사례
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 번역해주셨습니다.
