AWS 기술 블로그
Amazon Braket으로 양자-고전 하이브리드 알고리즘 실행하기 (1편)
고전 컴퓨팅 자원과 양자 컴퓨팅 자원을 결합한 하이브리드 알고리즘은 현재 NISQ (Noisy Intermediate-Scale Quantum) 시대의 양자 컴퓨터 기술 수준에서 실질적인 문제 해결에 접근할 수 있는 효과적인 방법론으로 주목받고 있습니다. 이번 블로그에서는 Amazon Braket을 활용하여 하이브리드 환경을 구성하고 사용할 수 있는 두 가지 방법, 즉 코드 기반 방식과 콘솔 기반 방식을 소개합니다. 이를 통해 독자들은 Amazon Braket에서 하이브리드 양자 작업을 수행하는 방법을 이해하고, 실제 문제에 적용할 수 있는 기반을 마련할 수 있을 것입니다. Amazon Braket에서 제공하는 하이브리드 잡의 개념에 대해서는 이미 지난 블로그에서도 설명한 바 있습니다.
Amazon Braket 하이브리드 잡의 개요
Amazon Braket의 하이브리드 잡(Hybrid Jobs) 기능은 양자 컴퓨팅과 고전 컴퓨팅 자원을 결합하여, 양자-고전 혼합 알고리즘의 실행과 관리를 자동화하는 데 최적화된 관리형 서비스입니다. 사용자는 별도의 인프라 구성 없이, 고전 AWS 컴퓨팅 자원(Amazon EC2 인스턴스)과 양자 하드웨어(QPU) 또는 시뮬레이터를 동시에 활용하는 반복적 알고리즘을 실행할 수 있으며, 실제 사용한 리소스에 대해서만 비용을 지불하는 구조로 운영 효율성도 높습니다.
하이브리드 잡은 크게 두 가지 방식으로 구성하고 실행할 수 있습니다. 첫째, 사용자가 Python 등으로 작성한 알고리즘 스크립트를 직접 제출하는 방식이며, 둘째는 Amazon Braket Python SDK에서 제공하는 @hybrid_job 데코레이터를 이용해 함수 단위로 하이브리드 잡을 정의하고 실행하는 방식입니다. 두 방식 모두 Amazon Braket이 자동으로 필요한 Amazon EC2 인스턴스를 프로비저닝하고, 사용자가 정의한 양자 디바이스(QPU 또는 시뮬레이터)와 연동하여 알고리즘을 실행합니다. 실행이 끝나면 인스턴스는 자동으로 해제되므로, 사용자는 양자-고전 워크플로우의 오케스트레이션을 직접 관리할 필요가 없습니다.
알고리즘 스크립트 방식 (AwsQuantumJob.create())
첫 번째 방식은 Python 스크립트나 Jupyter 노트북으로 작성한 알고리즘 파일을 소스 모듈로 지정하여 하이브리드 잡을 생성하는 방식입니다. 제출 경로는 두 가지이며, Braket Python SDK에서 AwsQuantumJob.create()를 호출하거나 AWS 콘솔의 Hybrid Jobs 페이지에서 UI 입력만으로 생성할 수 있습니다.
SDK를 사용하는 경우 다음과 같이 간단하게 잡을 제출할 수 있습니다.
from braket.aws import AwsQuantumJob
from braket.devices import Devices
job = AwsQuantumJob.create(
Devices.Amazon.SV1,
source_module="algorithm_script.py",
entry_point="algorithm_script:start_here",
wait_until_complete=True
)콘솔에서 생성하는 경우에는 “Create hybrid job” 마법사에서 알고리즘 스크립트를 업로드하고, 런타임, 양자 디바이스, 인스턴스 타입 등을 UI로 선택하여 잡을 제출할 수 있습니다. 즉 알고리즘 스크립트만 준비되어 있다면 코드 호출 없이 콘솔 UI만으로 잡 생성이 가능하며, 구체적인 콘솔 생성 절차는 본 블로그 후반부에서 실습과 함께 자세히 다룹니다. 이 방식은 내부적으로 AwsQuantumJob.create() API 호출과 동일한 결과를 만들어냅니다.
@hybrid_job 데코레이터 방식
두 번째 방식은 로컬 Python 함수에 @hybrid_job 데코레이터를 붙여서 해당 함수를 그대로 하이브리드 잡으로 실행하는 방식입니다. 별도의 스크립트 파일을 작성하거나 엔트리 포인트를 지정할 필요 없이, 로컬에서 개발 중인 코드에 데코레이터만 추가하면 Amazon Braket이 함수를 자동으로 컨테이너화하여 잡으로 실행합니다. 샘플 코드는 다음과 같습니다.
from braket.devices import Devices
from braket.jobs.hybrid_job import hybrid_job
@hybrid_job(device=Devices.Amazon.SV1) # 함수에 데코레이터만 추가
def run_hybrid_job():
# 여기에 양자-고전 알고리즘 로직 작성
...
job = run_hybrid_job() # 함수를 호출하면 잡이 생성·제출됨이 방식은 기존 로컬 Python 코드를 최소한의 변경으로 빠르게 하이브리드 잡으로 전환할 수 있어, 연구·개발 단계의 빠른 실험과 반복에 특히 유용합니다. 다만 이 방식은 로컬 Python 환경 또는 Braket 관리형 노트북에서 해당 함수를 실제로 실행해야 Braket이 잡을 제출하는 구조이므로, AWS 콘솔 UI만으로 잡을 생성할 수는 없습니다.
| 구분 | 알고리즘 스크립트 방식 | @hybrid_job 데코레이터 방식 |
| 코드 작성 위치 | 별도 스크립트 파일 (.py) | 로컬 Python 함수 |
| 제출 방법 | SDK AwsQuantumJob.create() 또는 콘솔 UI | 로컬에서 함수 실행 |
| 콘솔에서 클릭만으로 생성 | 가능 | 불가 |
| 콘솔에서 모니터링·결과 확인 | 가능 | 가능 |
| 주된 활용 시나리오 | 검증된 알고리즘을 여러 번 실행하거나 팀과 공유할 때 | 빠른 실험, 개발 단계 |
<표 1. Amazon Braket 하이브리드 잡 생성 방식 비교>
잡이 생성된 이후의 관리는 두 방식이 동일합니다. AWS 콘솔의 Hybrid Jobs 페이지에서 진행 상황을 모니터링하고, Amazon CloudWatch Logs에서 실행 로그를 조회하며, S3에 저장된 결과 아티팩트를 확인할 수 있습니다. 실행 환경(컨테이너, 인스턴스 타입, 지원 디바이스)도 양 방식 모두 동일한 범위를 지원하므로, 선택의 차이는 주로 생성 및 관리의 편의성과 활용 시나리오에 있습니다.
어떤 방식을 선택할 것인가?
알고리즘 스크립트 방식은 작성된 스크립트를 파라미터만 바꿔가며 여러 번 실행하거나, 팀 내에서 공유해야 할 때 유리합니다. 스크립트가 독립된 파일로 존재하므로 Git 저장소나 S3에 올려 팀원들이 동일한 알고리즘을 참조할 수 있으며, Python SDK 환경이 없는 팀원도 콘솔 UI를 통해 같은 스크립트를 그대로 제출할 수 있어 연구자, 개발자, 운영 담당자가 함께 사용하는 환경에 적합합니다.
@hybrid_job 데코레이터 방식은 기존 로컬 코드를 빠르게 클라우드로 이관하여 실험하려는 연구자 개인 또는 소규모 팀의 프로토타이핑에 적합합니다. 개발 반복 주기가 짧고 코드 구조가 자주 바뀌는 단계에서 특히 효율적입니다.
두 방식은 상호 배타적이지 않으며, 보통 다음 흐름으로 사용됩니다. 개발 및 실험 단계에서는 @hybrid_job 데코레이터로 빠르게 검증하고, 검증된 로직은 별도 스크립트 파일로 옮겨 AwsQuantumJob.create() 방식으로 반복 및 운영합니다.
본 블로그에서는 이 중 알고리즘 스크립트 방식을 기준으로 하이브리드 잡 생성 과정을 살펴봅니다. 콘솔 UI만으로 잡을 제출할 수 있어 처음 Braket을 접하는 독자도 단계별로 따라 하기 쉽고, SDK 기반 자동화 환경으로 확장하기에도 좋은 출발점이기 때문입니다.
알고리즘 스크립트 방식 — 코드 기반(SDK) 실행
알고리즘 스크립트 방식에서 사용될 예제는 ’0’번째 큐비트에 임의의 각도로 “X 축 회전 게이트(RX)”를 적용한 5개의 양자 회로를 각각 100번 실행하고, 1) 측정 결과(‘0’ 또는 ‘1’)와 2) 각도 값, 그리고 3) 총 실행 비용을 저장하는 작업을 수행합니다. 아래 코드는 파이썬(python)으로 작성된 알고리즘 스크립트(algorithm_script.py)의 일부이며, 이 알고리즘은 클래식 로직과 양자 작업 모두를 포함합니다.
for _ in range(5): # 아래 코드 5번 실행
angle = np.pi * np.random.randn() # 고전 컴퓨터 리소스를 사용
random_circuit = Circuit().rx(0, angle) # 양자 컴퓨터 리소스 사용
task = device.run(random_circuit, shots=100) # 양자 회로를 실행하고 측정
counts = task.result().measurement_counts # 측정 결과를 가져옴아래 코드는 Amazon Braket에서 위의 파이썬 코드를 이용하여 하이브리드 양자 작업(Hybrid Job)을 생성하고 실행하는 역할을 수행합니다.
from braket.aws import AwsQuantumJob
from braket.devices import Devices
job = AwsQuantumJob.create(
Devices.Amazon.SV1,
source_module="algorithm_script.py",
wait_until_complete=True # 실행 중 출력 결과를 실시간으로 확인
)위의 코드에 대해 자세히 알아보도록 하겠습니다. 우선 “from braket.aws import AwsQuantumJob”의 주요 역할은, 하이브리드 작업(Hybrid Job)을 생성하고 관리하는 것입니다. 위 코드의 3번째 라인의 ‘AwsQuantumJob.create()’ 메서드는 Amazon Braket에서 하이브리드 잡을 생성하기 위한 공식 API입니다. ‘source_module=”algorithm_script.py”’ 라인을 통해 사전에 정의된 외부 소스 파일을 지정하고 있습니다. 이는 하이브리드 잡 생성의 표준 패턴입니다. Devices.Amazon.SV1을 통해, 온디맨드 시뮬레이터인 SV1 양자 시뮬레이터를 양자 디바이스로 지정하고 있습니다. 참고로 하이브리드 잡은 QPU나 시뮬레이터(SV1, DM1, TN1 등)를 타겟 양자 디바이스로 선택할 수 있습니다.
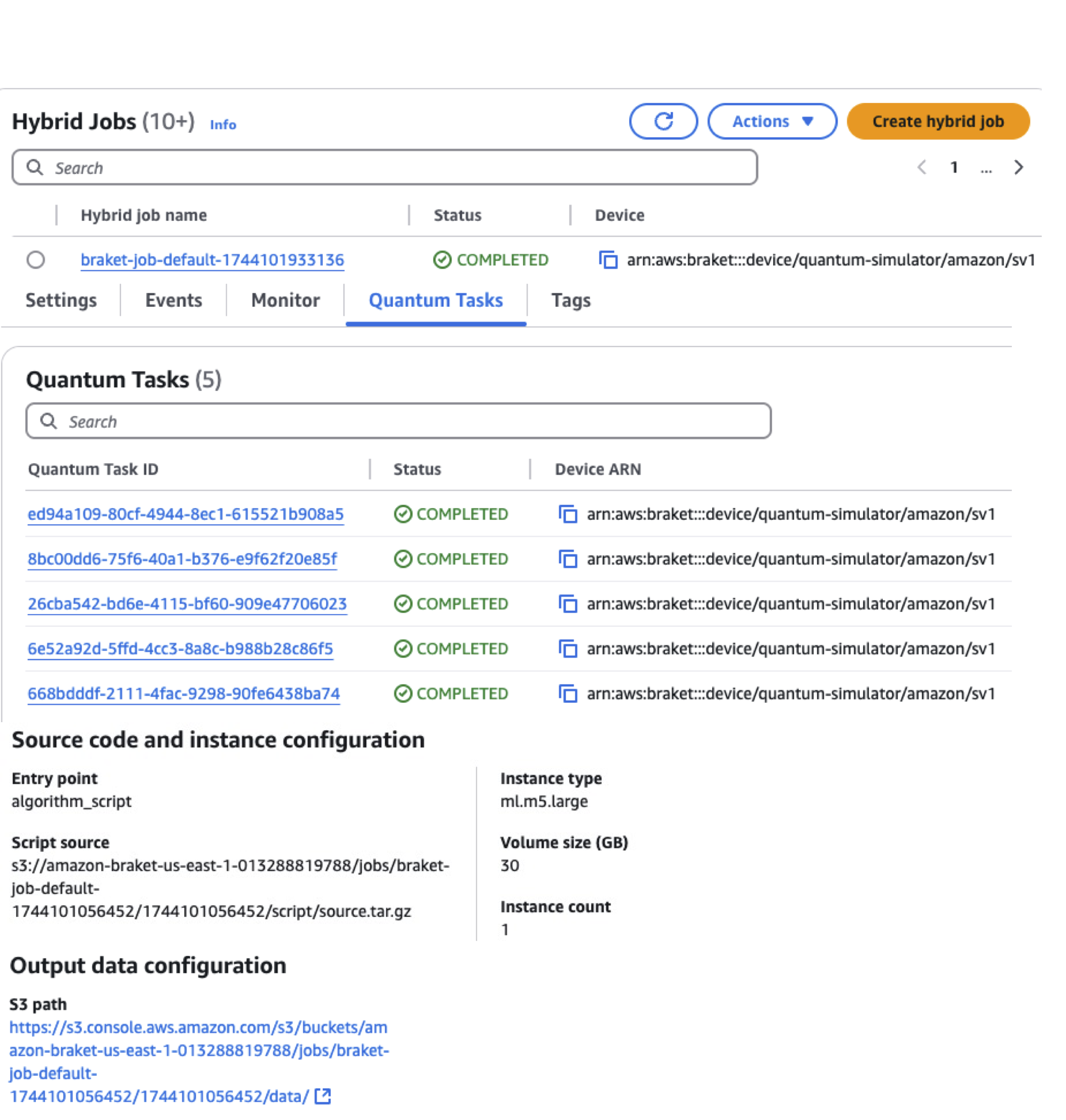
<그림 1.하이브리드 잡 실행 결과 정보 >
작업이 완료되면 그림1과 같이 Amazon Braket 콘솔의 ’Hybrid jobs’ 링크에서 실행 결과를 확인할 수 있습니다. 그림 1은 하이브리드 작업 실행 결과를 Amazon Braket 콘솔에서 확인하는 화면입니다. 하이브리드 잡 세팅 화면에서는 별도 설정을 추가하지 않으면 잡 이름이 braket-job-default-<타임스탬프> 형식으로 자동 생성됩니다. 관리 편의를 위해 의미 있는 이름을 직접 지정하는 것도 가능합니다. 특정 하이브리드 잡 이름을 클릭하면 작업 상태, 작업 시간, 작업 과정 등의 정보를 확인할 수 있습니다. 이 하이브리드 잡은 앞서 언급한 대로 “X축 회전 게이트(RX)”를 적용한 5개의 양자 회로로 구성되었기 때문에 이 하이브리드 잡은 5개의 태스크로 구성되었음을 그림1에서 확인할 수 있습니다. 이 태스크들은 또한 콘솔의 ‘Quantum tasks’ 링크에서도 별도로 확인 가능합니다. 그리고 이전 블로그의 그림5에서 언급된 잡 인스턴스(job instance)로, ml.m5.large 인스턴스가 자동 생성된 것을 확인할 수 있습니다. 이 경우에는 기본적으로 한 개의 인스턴스만 생성되었습니다.
별도의 인스턴스 타입이나, 2개 이상의 인스턴스(최대 5개)를 사용하고자 한다면 InstanceConfig의 instanceCount를 지정하면 됩니다. 단, 2개 이상의 인스턴스는 양자 디바이스로 임베디드 시뮬레이터(PennyLane lightning.gpu, CUDA-Q nvidia 백엔드 등)를 선택한 경우에만 사용 가능합니다. 이 경우 인스턴스들은 네트워크로 연결된 분산 컴퓨팅 클러스터로 동작하며, 두 가지 대표적인 활용 패턴이 있습니다:
- 데이터 병렬 학습(QML): SageMaker Distributed Data Parallel(SMDDP) 라이브러리를 통해 여러 GPU가 데이터 슬라이스를 나눠 병렬 학습
- 분산 양자 시뮬레이션(CUDA-Q): MPI를 통해 큰 양자 회로의 상태 벡터를 여러 GPU에 분산 저장 및 통신
EFA 지원 인스턴스(ml.p4d.24xlarge 등)에서는 EFA 기반 고속 통신이 활용되며, ml.g4dn.12xlarge 같은 인스턴스에서는 EFA 없이 일반 네트워크 통신이 사용됩니다.
QPU나 온디맨드 시뮬레이터(SV1, DM1, TN1)를 타겟으로 할 경우에는 인스턴스를 1개만 지정할 수 있습니다. 이는 QPU 큐 접근이 직렬적이고 실행 병목이 양자 디바이스 쪽에 있어, 고전 인스턴스를 여러 대로 늘려도 성능 이점이 크지 않기 때문입니다. 다만 이때도 고전 인스턴스는 단순 API 호출만 하는 게 아니라, QAOA·VQE 같은 변분 알고리즘에서 옵티마이저 실행, 비용 함수 및 그래디언트 계산, 데이터 전처리 및 후처리 등 필수 고전 연산을 수행합니다. 더 큰 규모의 분산 컴퓨팅이나 전통적인 HPC 워크로드(CFD·FEA 등)에는 Amazon SageMaker Training, AWS ParallelCluster, AWS PCS(Parallel Computing Service) 같은 전용 서비스가 적합합니다.
results = job.result()
print("counts: ", results["counts"])
print("angle: ", results["angle"])
print("estimated cost: ", results["estimated cost"])위 코드를 통해 5번 동안 매번 측정된 5개의 임의의 각도와 측정값을 출력합니다. 측정 결과는 표2에 정리하였습니다. 또한 이 코드를 실행한 비용도 확인이 가능합니다.
| 실행 | 각도 | 100번 측정 | |
| 0 측정 횟수 | 1 측정 횟수 | ||
| 1 | 4.530983660756246 | 41 | 59 |
| 2 | -4.496124252620623 | 36 | 64 |
| 3 | 5.610723575343932 | 92 | 8 |
| 4 | -4.171953434823786 | 25 | 75 |
| 5 | 0.1284269321481768 | 100 | 0 |
<표2. 측정 결과 요약 정리 >
마지막으로 이 결과는 그림2에서 볼 수 있는 것처럼, 자동적으로 AWS의 오브젝트 스토리지인 아마존 S3(Amazon S3)에 저장되어 있습니다.
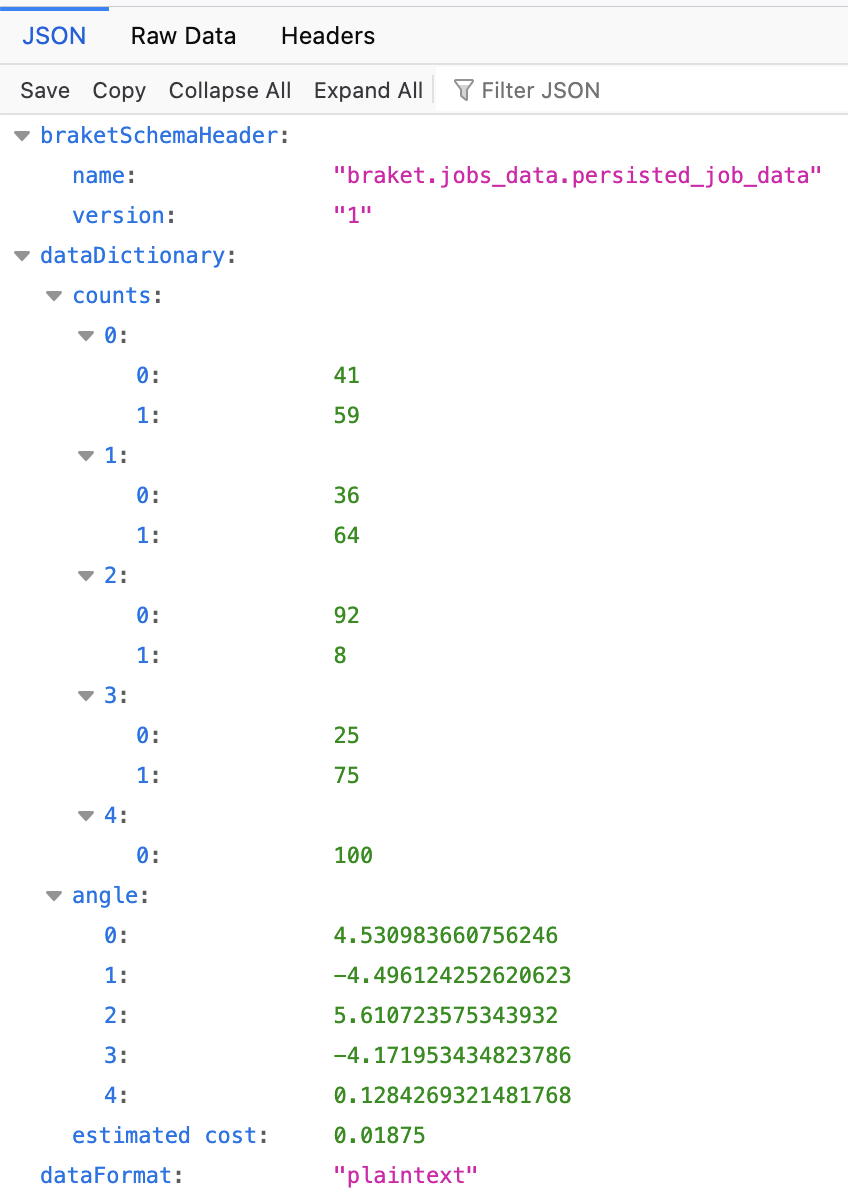
<그림 2. S3에 자동 저장된 Example 1 코드의 하이브리드 잡 실행 결과>
위와 관련된 일련의 내용은 다음의 Amazon Braket 개발자 가이드에서도 확인 가능합니다.
알고리즘 스크립트 방식 — 콘솔 UI 기반 실행
위의 방식이 주피터 노트북에서 코드를 이용하여 하이브리드 잡을 수행하였다면, 이번에는 동일한 내용을 Amazon Braket 콘솔에서 클릭 기반으로 구현해 보도록 하겠습니다. 우선 그림1의 우측 상단에 있는 ‘Create hybrid job’을 클릭합니다. 이 후 그림3의 화면을 만나게 되며, 여기서 알고리즘 소스 파일을 선택하게 됩니다. 여기서는 앞서도 사용된 소스 파일인 ‘algorithm_script.py’ 파일이 로컬 PC에 저장되어 있다고 가정합니다.
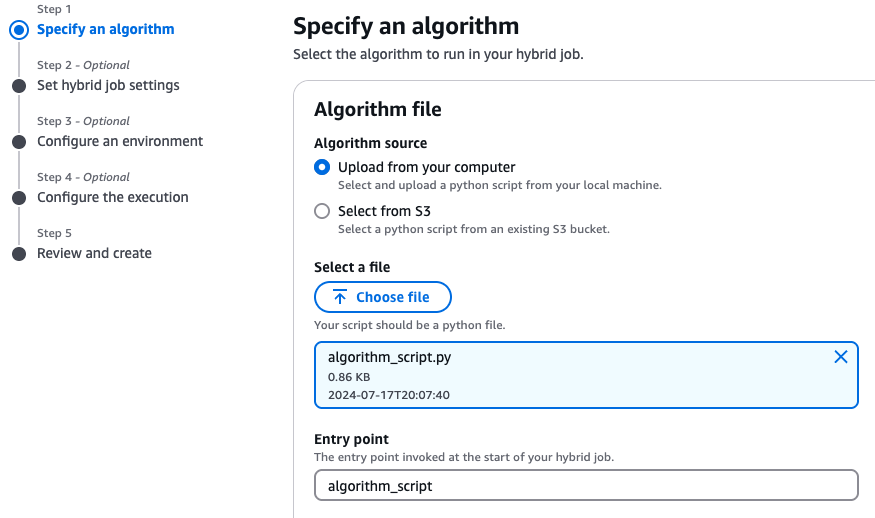
<그림 3. 하이브리드 알고리즘 소스 파일 선택>
설정을 완료하였다면 ‘Next’를 클릭합니다. 이번에는 하이브리드 잡 세팅 화면을 만나게 되고, 특별한 별도 세팅을 추가하지 않는다면, 하이브리드 잡의 이름만 설정합니다. 여기서는 그림4와 같이 이름을 ‘braket-hybrid-blog’로 설정하였습니다.
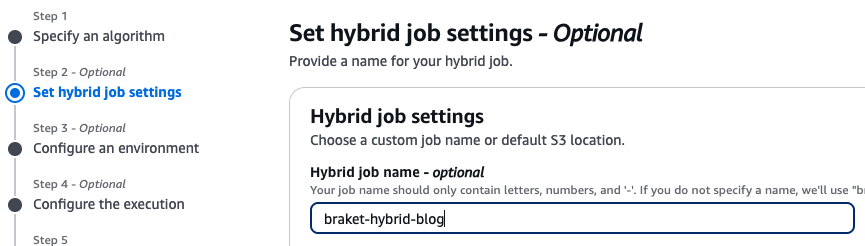
<그림 4. 하이브리드 잡의 이름 설정>
다음으로는 런타임 환경 구성을 선택합니다. 이 런타임 환경이 앞서 입력한 알고리즘 파일(‘algorithm_script.py’)을 실행하게 됩니다. 그림5의 5가지 런타임 환경은 다음과 같습니다.
- PennyLane:
- 퀀텀 머신 러닝, 자동 미분, 하이브리드 양자-고전 계산 최적화에 특화된 환경입니다.
- 특별한 요건이 없다면 일반적으로 이 옵션을 선택합니다.
- PennyLane with TensorFlow:
- PennyLane 기본 환경에 TensorFlow를 추가한 환경으로, 머신 러닝 및 인공지능 응용 프로그램 개발에 적합합니다.
- PennyLane과 TensorFlow가 함께 제공됩니다.
- PennyLane with PyTorch:
- PennyLane 기본 환경에 PyTorch를 추가한 환경으로, 컴퓨터 비전 및 자연어 처리 응용 프로그램 개발에 적합합니다.
- PennyLane과 PyTorch가 함께 제공됩니다.
- CUDA-Q:
- NVIDIA의 양자 컴퓨팅 프레임워크인 CUDA-Q(cudaq, cudaq-qec, cudaq-solvers)가 포함된 환경으로, GPU 가속 양자 시뮬레이션 및 하이브리드 양자-고전 애플리케이션 개발에 특화되어 있습니다.
- Custom (BYOC):
- 사용자가 직접 정의한 컨테이너 이미지를 가져올 수 있는 옵션입니다. BYOC는 “Bring Your Own Container”의 약자로, 사용자 맞춤형 환경을 구성할 때 유용합니다. 컨테이너 이미지는 Amazon ECR에 등록되어 있어야 합니다.
여기서는 특별한 요구 조건이 없기 때문에 기본 옵션인 ‘PennyLane’을 선택합니다.
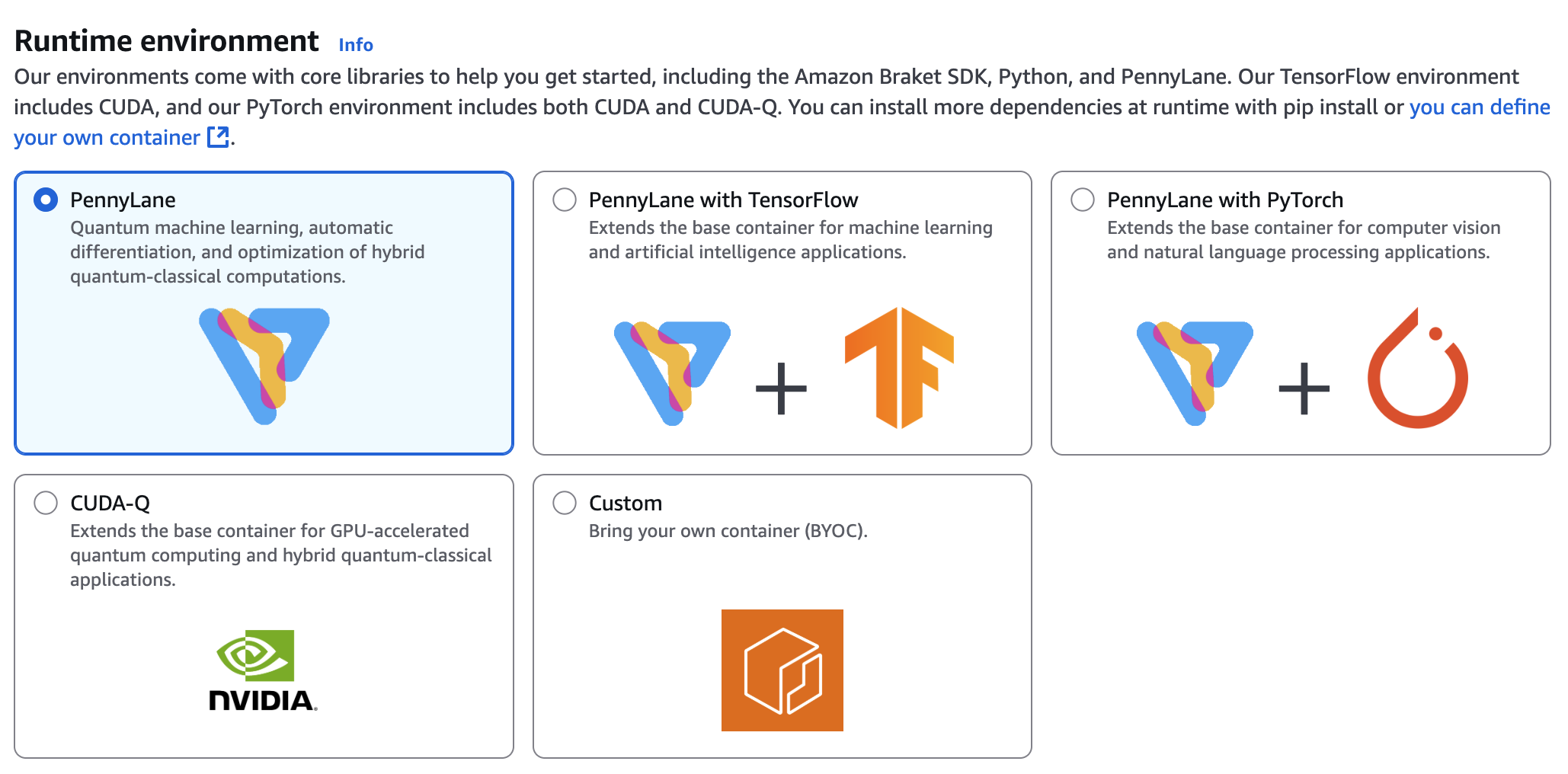
<그림 5. 하이브리드 잡 런타임 설정>
런타임 설정이 완료되었다면 그림6과 같은 양자 디바이스 설정 화면을 만나게 됩니다. 앞선 코드에서 양자 디바이스로 SV1을 선택하였기 때문에, 여기서도 동일하게 SV1으로 선택합니다. 그림6에서 볼 수 있는 것처럼 다양한 양자 디바이스를 선택할 수 있으며, Emerald QPU와 같이 음영으로 흐릿하게 표시된 QPU의 경우 현재 필자가 사용중인 AWS 리전(Region)인 버지니아 리전(us-east-1)에서는 지원하지 않기 때문에 양자 디바이스로 사용할 수 없습니다.
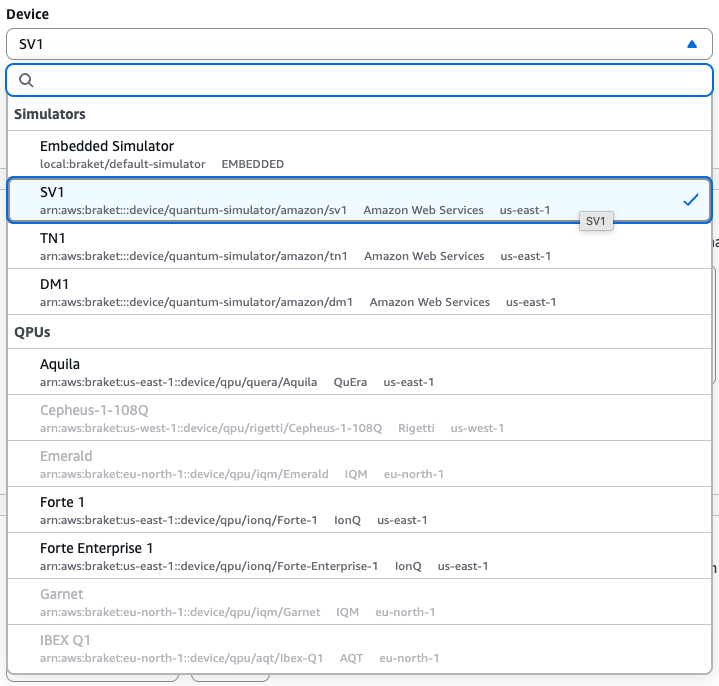
<그림 6. 양자 디바이스 옵션>
다음으로는 런타임 환경이 구동되는 고전 컴퓨팅 리소스를 선택합니다. 자동적으로 앞서 언급된 ‘ml.m5.large’ 인스턴스가 선택되나, 다른 요구 조건이 존재한다면 그림7과 같이 고성능 인스턴스나 GPU가 탑재된 인스턴스 선택도 가능합니다.
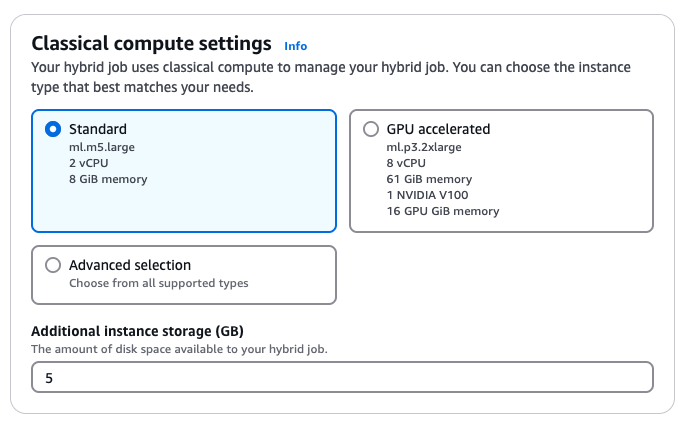
<그림 7. 고전 컴퓨팅 환경 설정>
모든 환경 설정이 완료되었다면, 그림 8과 같이 리뷰 화면으로 넘어갑니다. 특별한 문제가 없다면 화면 오른쪽 하단의 ‘Create Hybrid Job’을 선택하면 하이브리드 잡이 생성됩니다. 이후 이 잡의 결과 확인은 그림1 및 그림2와 동일한 방식으로 가능합니다.
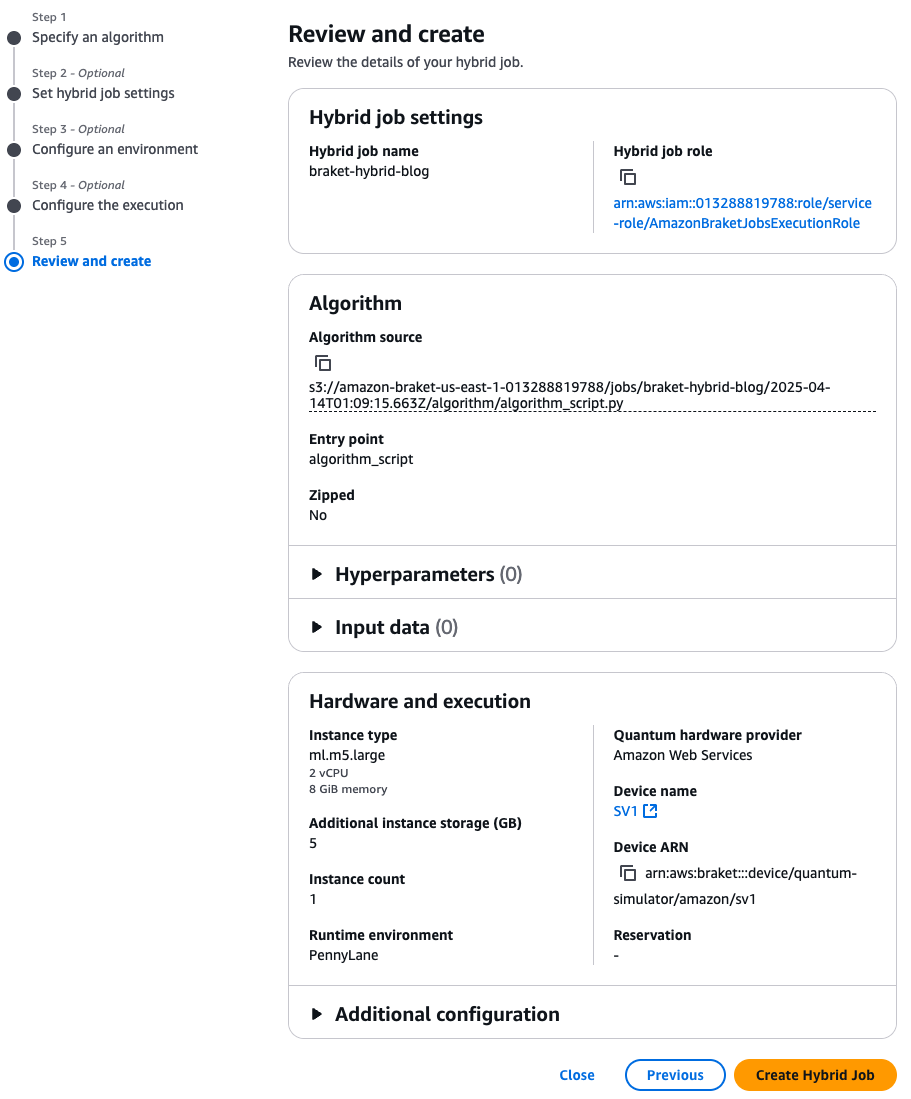
<그림 8. 하이브리드 잡 리뷰 화면>
그림9와 같이 하이브리드 잡이 정상적으로 잘 실행되었음을 확인할 수 있습니다.

<그림 9. 하이브리드 잡 실행 결과 화면>
아마존 클라우드와치(Amazon CloudWatch)를 통해 진행된 일련의 과정을 그림10처럼 확인하는 것도 가능합니다.
<그림 10. 하이브리드 잡 실행 로그 이벤트 화면>
지금까지 알고리즘 스크립트 방식 중 두 가지 방법으로 Amazon Braket에서 하이브리드 잡 환경을 구성하는 방법에 대해 알아보았습니다. 이 두 가지 방식의 장/단점은 다음과 같습니다.
| 구분 | 콘솔 기반 | 코드 기반 |
| 장점 |
· 시각적인 인터페이스로 설정이 간편 · 복잡한 코드 없이 작업 생성 가능 · 초보자에게 진입 장벽이 낮음 |
· 자동화 및 반복 작업에 용이 · 세밀한 설정 및 커스터마이징 가능 · 대규모 작업에 적합 |
| 단점 |
· 복잡한 설정이나 커스터마이징에 제약 존재 · 자동화된 작업 실행이 어려움 |
· 코드 작성 및 디버깅에 대한 이해 필요 · 콘솔 기반에 비해 상대적으로 복잡 |
<표3. 알고리즘 스크립트 방식의 하이브리드 잡 생성 방식 비교: 콘솔 기반 vs 코드 기반>
맺음말
본 블로그에서는 Amazon Braket에서 하이브리드 환경을 구성하는 방식 중에 하나인 알고리즘 스크립트 구성 방법에 대해 상세히 알아보았습니다. 주피터 노트북을 이용한 코드 기반 방식은 프로그래밍에 익숙한 사용자에게 유연성과 제어력을 제공하며, 콘솔 기반 방식은 클릭 몇 번으로 간편하게 하이브리드 작업을 수행할 수 있도록 지원합니다. 제시된 예제와 설명을 통해 독자들은 Amazon Braket을 활용한 하이브리드 양자 컴퓨팅의 가능성을 확인하고, 자신에게 적합한 방법을 선택하여 양자 컴퓨팅 연구 및 개발에 적용해 볼 수 있을 것입니다.
다음 블로그에서는 @hybrid_job 데코레이터를 이용한 하이브리드 잡 방식에 대해 좀 더 자세히 소개하도록 하겠습니다.