AWS 기술 블로그
AWS 관리형 서비스를 활용한 실시간 지능형 뉴스 기반 주가 영향도 분석 시스템
머리글
주식 가격은 기업의 실적, 경제 지표, 정치적 사건, 산업 동향 등 다양한 정보에 민감하게 반응하며, 이러한 정보의 대부분은 뉴스를 통해 전파되고 시장에 영향을 끼칩니다. 예를 들어 중요한 뉴스 발표 직후 주식 가격이 급등하거나 급락하는 현상은 우리 주변에 자주 볼수 있는 현상입니다. 이 때문에 다양한 기업은 Batch성 뉴스 영향도 분석을 시도해왔습니다. 하지만 주가 데이터가 초 단위의 실시간 변동 데이터 스트림인 반면 뉴스는 불규칙적이고 저빈도로 발생되는 이벤트기 때문에 두 데이터를 결합하여 분석하는 데에는 한계가 존재했습니다.
Apache Flink는 이처럼 빈도 및 라이프사이클이 다른 데이터 스트림을 결합하여 실시간 분석을 하기 위한 좋은 선택지입니다. Flink는 실시간 분석을 진행할 때 record-by-record(데이터가 들어올 때마다 한 건씩 즉시 처리) 처리 메커니즘을 활용하기 때문에 뉴스 이벤트가 발생하는 순간 해당 시점 전 후의 주식 거래 데이터를 조회하고 결합한 후에 분석을 진행할수 있습니다. 하지만 Apache Flink를 직접 운영하기 위해서는 클러스터 관리, 확장성 처리, 장애 복구 등 복잡한 인프라 관리가 필요합니다. 이러한 운영 부담을 해결하기 위해 AWS는 Apache Flink를 Managed Service 형태로 제공하며, 그 이점은 다음과 같습니다.
- 운영 부담 최소화: 클러스터 프로비저닝, 확장, 패치, 장애 복구를 AWS가 관리
- 자동 확장: 데이터 양과 처리량에 맞춰 리소스를 자동으로 늘리거나 줄임
- 통합 보안: IAM, VPC, KMS, CloudWatch 등 AWS 보안·모니터링 서비스와 네이티브 통합
- 비용 최적화: 사용한 만큼만 비용을 지불(Pay-as-you-go)
- 고가용성 보장: 다중 AZ 기반으로 안정적인 스트리밍 애플리케이션 운영 가능
- 개발 집중 가능: 인프라 운영이 아닌 애플리케이션 로직과 분석 모델 개발에만 집중
이번 블로그에서는 Amazon Managed Service for Apache Flink를 활용해 뉴스-주식 상관관계 실시간 분석 시스템을 구축하는 방법에 대해 논의 해보겠습니다.
Architecture
![]()
아키텍처 안에 포함된 AWS 서비스
1. Amazon Managed Service for Apache Flink
Amazon Managed Service for Apache Flink(이하 Amazon MSF)는 AWS에서 제공하는 완전 관리형 Flink 서비스로 스트리밍 데이터를 실시간으로 변환 및 분석이 가능합니다. Flink의 가장 큰 차별화 요소는 진정한 실시간 스트림 처리 방식에 있습니다. Spark Streaming과 같은 기존 도구들이 마이크로 배치(micro-batch) 방식으로 실시간 데이터를 처리하는 반면, Flink는 record-by-record 처리를 통해 하나의 데이터가 도착하는 즉시 분석하여 결과를 제공합니다. 이러한 접근 방식은 마이크로 배치의 고유한 지연 시간을 제거하여 진정한 저지연 실시간 응답을 가능하게 합니다. 또한 Flink의 UDF(User Defined Function) 란 기능을 통해 사용자가 Java, Scala, Python으로 커스텀 함수를 작성하여 복잡한 비즈니스 로직을 스트림 처리 파이프라인에 직접 통합할 수 있게 해줍니다. 이를 통해 외부 API 호출, 머신러닝 모델 추론, 복잡한 데이터 변환 등을 실시간 스트림 내에서 수행할 수 있으며, 뉴스 분석 시나리오에서는 UDF를 활용해 Amazon Bedrock의 LLM API를 호출하여 뉴스 텍스트의 감정 분석과 요약을 실시간으로 처리할 수 있습니다.
2. Amazon Managed Streaming for Apache Kafka
Amazon Managed Streaming for Apache Kafka(이하 Amazon MSK)는 AWS에서 제공하는 완전 관리형 Apache Kafka 서비스로, 대용량 실시간 데이터 스트리밍을 위한 메시지 브로커 역할을 수행합니다. MSK는 높은 처리량과 내구성을 제공하며, 프로듀서로부터 수집된 데이터를 안정적으로 저장하고 컨슈머에게 전달하는 중간 계층 역할을 합니다. 특히 MSK는 Flink와 연동될 때 핵심 데이터 인프라로서 세 가지 주요 역할을 수행합니다. 첫째, MSK는 파티션 기반 병렬 처리를 통해 대용량 실시간 데이터를 고속으로 전송하며, Kafka 파티션과 Flink 태스크가 1:1 맵핑되어 트래픽 증가 시 선형적 확장성을 제공합니다. 둘째, MSK는 데이터를 특정 기간 동안 디스크에 영구 저장하고 복제본을 유지하여 Flink 장애 발생 시에도 데이터 손실 없이 재처리할 수 있도록 내결함성을 보장합니다. 셋째, MSK는 메시지 타임스탬프와 순서를 보존하여 Flink의 정확한 이벤트 시간 기반 분석과 워터마크 처리를 지원합니다. 이를 통해 MSK는 Flink가 안정적이고 정확한 실시간 스트림 처리를 수행할 수 있는 필수적인 기반을 제공합니다.

실제 구현에서 MSF는 MSK를 source와 sink로 활용하여 완전한 스트림 처리 파이프라인을 구성합니다. Kafka 토픽으로부터 데이터를 Flink로 읽어 오는 것을 Source라고 합니다. MSF는 이 데이터를 실시간으로 처리하여 뉴스 감정 분석, 주가 변동 계산 등의 복잡한 연산을 수행한 후, 처리된 결과를 다시 MSK의 다른 토픽으로 전송하는데 이를 Sink라고 합니다. 이러한 구조를 통해 데이터의 흐름이 끊어지지 않고 연속적으로 처리되며, 각 컴포넌트 간의 느슨한 결합을 통해 시스템의 유연성과 확장성을 극대화할 수 있습니다.
3. Amazon Bedrock
Amazon Bedrock은 AWS에서 제공하는 완전 관리형 생성형 AI 서비스로, Anthropic Claude, Amazon Titan, Meta Llama 등 다양한 파운데이션 모델(Foundation Model)을 API를 통해 쉽게 활용할 수 있습니다. Bedrock의 핵심 장점은 별도의 모델 학습이나 인프라 관리 없이도 텍스트 생성, 요약, 감정 분석, 질의응답 등의 AI 기능을 즉시 사용할 수 있다는 점입니다. 특히 실시간 스트리밍 환경에서 뉴스 데이터의 감정 분석이나 요약과 같은 자연어 처리 작업을 수행할 때 Bedrock의 서버리스 특성과 빠른 응답 시간은 매우 유용합니다. MSF의 UDF와 연결 되어 MSF 작업시에 LLm을 활용한 분석이 가능합니다.
4. Amazon Data Firehose
Amazon Data Firehose는 AWS에서 제공하는 완전 관리형 스트리밍 데이터 전송 서비스로, MSK에 저장된 MSF 처리 결과를 자동으로 수집하여 Amazon S3로 안정적으로 전송하는 역할을 수행합니다. 뉴스 기반 주식 분석 시스템에서 Firehose는 분석 결과가 담겨있는 MSK의 토픽을 실시간으로 읽어서 S3 버킷에 배치 형태로 저장하는 역할을 수행합니다.
Firehose의 주요 장점은 서버리스 특성으로 인프라 관리가 불필요하며, MSK에서 가져온 데이터를 자동으로 압축, 암호화, 포맷 변환(JSON, Parquet 등)하여 S3에 최적화된 형태로 저장한다는 점입니다. 특히 실시간으로 생성되는 분석 결과를 일정 시간 간격(예: 5분)이나 데이터 크기 단위(예: 128MB)로 배치하여 S3에 저장함으로써, 실시간 분석과 배치 분석을 연결하는 브리지 역할을 하며, 저장된 데이터는 뉴스-주식 상관관계의 히스토리컬 분석, 머신러닝 모델 학습용 데이터셋 구축에 활용 될수 있습니다.
5. Amazon S3
Amazon S3(Simple Storage Service)는 AWS에서 제공하는 객체 스토리지 서비스로, 무제한 용량의 데이터를 99.99%의 내구성으로 안전하게 저장할 수 있는 클라우드 스토리지입니다. S3는 웹 인터페이스나 API를 통해 언제 어디서나 데이터에 접근할 수 있으며, 사용한 만큼만 비용을 내고, 데이터 접근 빈도에 따라 저렴한 스토리지 옵션을 선택해서 비용을 절약할 수 있습니다. 뉴스 기반 주식 분석 시스템에서 Firehose가 분석 결과를 자동으로 S3로 전달합니다. S3에 저장된 데이터는 이후 Amazon Athena를 통해 SQL 쿼리 분석, Amazon QuickSight를 통해서는 대시보드 시각화, 그리고 머신러닝 모델 학습용 데이터셋 등 다양한 용도로 활용할 수 있습니다. 더하여 S3의 라이프사이클 정책을 통해 오래된 데이터를 자동으로 저비용 스토리지로 이동시켜 장기적인 비용 효율성을 제공합니다.
시스템 설계 방법
1. 데이터 설명
뉴스 기반 주식 분석 시스템의 데이터 구조는 두 개의 서로 다른 특성을 가진 스트림으로 구성됩니다. 다음은 시스템에서 처리되는 데이터의 예시로, 모두 임의로 생성된 샘플 데이터입니다. 이 샘플 데이터는 MSK로 지속적으로 전송되고 있는 상황입니다.
뉴스 데이터 스트림은 symbol, news_id, news_time, news_content 필드로 구성되어 있으며, 불규칙적으로 발생하는 저빈도 이벤트 특성을 보입니다. (예시: 데이터에서 아마존(AMZN)의 뉴스는 2025년 7월 1일 오전 9시 1분 47초에 발생한 단일 이벤트로, 200억 달러 클라우드·AI 투자 확대라는 뉴스 내용을 포함하고 있습니다. 이러한 뉴스는 하루에 몇 건 정도만 발생하지만 주식 가격에 즉각적이고 큰 영향을 미칠 수 있습니다.)

반면 주식 거래 데이터 스트림은 symbol, stock_time, price, volume 필드로 구성되어 있으며, 시장 개장 시간 동안 초 단위로 연속 발생하는 고빈도 스트림입니다. MSF의 이벤트 드리븐 처리를 통해 뉴스 이벤트 발생 즉시 해당 시점 주변의 주식 거래 데이터와 결합하여 뉴스가 주식에 미치는 실시간 영향도 분석이 가능합니다.
2. MSF와 MSK를 연동하고 Amazon Bedrock을 활용하여 분석 파이프라인 설계 방법
(1) MSF의 FlinkSQL을 활용해 Kafka 기반 Source / Sink 테이블을 설정하는 방법
![]()
Flink 프로세서 안에서 Kafka Source 와 Sink의 흐름
Kafka connector는 Flink 테이블 생성 시 속성에 따라 Source 또는 Sink로 고정됩니다. 그 이유는 Flink가 Kafka에서 데이터를 읽을때는 Kafka Consumer를 생성해야 하고 Kafka에 데이터를 적재할때는 Kafka Producer를 만들어야 하기 때문입니다. 따라서 하나의 Kafka topic에 Read(Kafka Consumer)와 Write(Kafka Producer) 작업을 하기 위해선 Source 와 Sink를 각각 만들어 줘야 합니다. 보통 Kafka connector는 append-only 방식이므로 항상 새로운 데이터만 추가되며, 기존 데이터를 수정하거나 업데이트 하지 않습니다.
Kafka connector에서 properties.group.id와 scan.startup.mode 설정의 존재 여부로 Source와 Sink를 구분할 수 있습니다. Kafka Source는 데이터를 읽어올때 properties.group.id를 통해 Kafka Consumer ID를 설정합니다. 또한 scan.startup.mode를 활용해 Kafka Consumer의 Offset를 결정합니다. 반면 Kafka Sink는 데이터를 토픽에 쓰기만 하기때문에 위의 두 설정이 불필요하며, Kafka producer 관련 설정만 있으면 됩니다.
(2) 분석 플로우
- news_stream_source : 원본 news 데이터 Read 테이블(Kafka Topic : news)
- stock_transaction_source : 원본 주식 데이터 Read 테이블(Kafka Topic : stock)
- news_summary_source : Bedrock API를 통해 변환된 news 데이터 Read 테이블 (Kafka Topic : n-summary)
- news_summary_sink : Bedrock 통해 변환된 news 데이터 적재하는 테이블 (Kafka Topic : n-summary)
- news_result_sink : 주식데이터와 뉴스 데이터 결한 뒤 분석 완료한 값을 적재하는 테이블 (Kafka Topic : analysis)
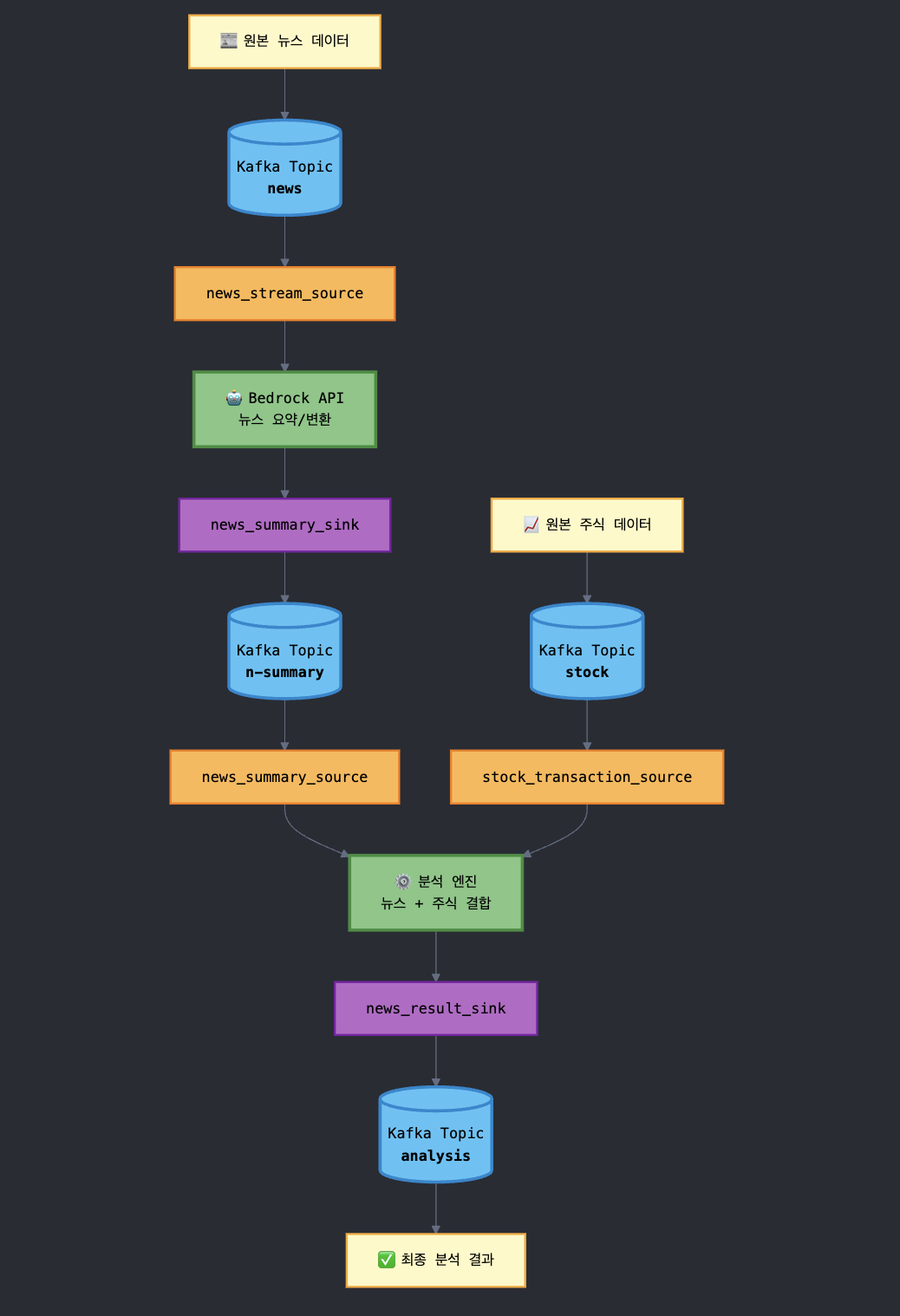
실시간 분석 시스템 사용 되는 Kafka Source / Sink 흐름도
%flink.ssql
-- 테이블( source/ sink ) 설정 방법
--<Source table>
--MSK의 news 데이터를 Flink 파이프라인으로 연결하는 테이블
--특징: Kafka Consumer ID(properties.group.id)가 존재 -> Kafka Consumer
CREATE TABLE news_stream_source (
symbol STRING,
news_id INT,
news_time STRING,
news_content STRING,
event_time AS TO_TIMESTAMP(news_time, 'yyyy-MM-dd HH:mm:ss'),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'news',
'properties.bootstrap.servers' = '<MSK Broker Endpoint>:9098',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'AWS_MSK_IAM',
'properties.sasl.jaas.config' =
'software.amazon.msk.auth.iam.IAMLoginModule required;',
'properties.sasl.client.callback.handler.class' =
'software.amazon.msk.auth.iam.IAMClientCallbackHandler',
'properties.group.id' = 'flink-news-stream-consumer',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
--MSK의 주식 거래 데이터를 Flink 파이프라인으로 연결하는 테이블
--특징: Kafka Consumer ID(properties.group.id)가 존재 -> Kafka Consumer
CREATE TABLE stock_transaction_source (
symbol STRING,
stock_time STRING,
price DOUBLE,
volume INT,
event_time AS TO_TIMESTAMP(stock_time, 'yyyy-MM-dd HH:mm:ss'),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'stock',
'properties.bootstrap.servers' = '<MSK Broker Endpoint>:9098',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'AWS_MSK_IAM',
'properties.sasl.jaas.config' =
'software.amazon.msk.auth.iam.IAMLoginModule required;',
'properties.sasl.client.callback.handler.class' =
'software.amazon.msk.auth.iam.IAMClientCallbackHandler',
'properties.group.id' = 'flink-consumer-group-news',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
--Bedrock을 통해 감정 분석 및 요약이 완료된 news_summary 데이터를 Flink 파이프라인으로 연결하는 테이블
--특징: Kafka Consumer ID(properties.group.id)가 존재 -> Kafka Consumer
CREATE TABLE news_summary_source (
symbol STRING,
news_id INT,
event_time TIMESTAMP(3),
summary STRING,
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'n-summary',
'properties.bootstrap.servers' = '<MSK Broker Endpoint>:9098',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'AWS_MSK_IAM',
'properties.sasl.jaas.config' =
'software.amazon.msk.auth.iam.IAMLoginModule required;',
'properties.sasl.client.callback.handler.class' =
'software.amazon.msk.auth.iam.IAMClientCallbackHandler',
'properties.group.id' = 'flink-news-summary-group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
--<Sink table>
--MSK의 news contents를 Bedrock을 통해 감정 분석 및 요약한뒤 msk n-summary토픽으로 전송
--특징: Kafka Consumer ID(properties.group.id)가 없음 -> Kafka Producer
CREATE TABLE news_summary_sink (
symbol STRING,
news_id INT,
event_time TIMESTAMP(3),
summary STRING,
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'n-summary',
'properties.bootstrap.servers' = '<MSK Broker Endpoint>:9098',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'AWS_MSK_IAM',
'properties.sasl.jaas.config' =
'software.amazon.msk.auth.iam.IAMLoginModule required;',
'properties.sasl.client.callback.handler.class' =
'software.amazon.msk.auth.iam.IAMClientCallbackHandler',
'format' = 'json'
);
--MSK에서 분석이 완료된 결과를 MSK의 analysis-result 토픽으로 전송
--특징: Kafka Consumer ID(properties.group.id)가 없음 -> Kafka Producer
CREATE TABLE news_result_sink (
symbol STRING,
news_id STRING,
news_time TIMESTAMP(3),
summary STRING,
window_start TIMESTAMP(3),
window_end TIMESTAMP(3),
avg_price DOUBLE,
avg_volume DOUBLE,
event_count BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'analysis',
'properties.bootstrap.servers' = '<MSK Broker Endpoint>:9098',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'AWS_MSK_IAM',
'properties.sasl.jaas.config' =
'software.amazon.msk.auth.iam.IAMLoginModule required;',
'properties.sasl.client.callback.handler.class' =
'software.amazon.msk.auth.iam.IAMClientCallbackHandler',
'format' = 'json'
);(3) Amazon Bedrock 호출 가능한 함수 (Flink UDF)를 MSF에 등록
%flink.pyflink
import json
import boto3
from pyflink.table.udf import udf
from pyflink.table import DataTypes
@udf(result_type=DataTypes.STRING())
def analyze_news(text):
try:
bedrock = boto3.client('bedrock-runtime', region_name='ap-northeast-2')
prompt = f"""다음 뉴스를 분석해주세요:
{text}
다음 JSON 형식으로만 답변해주세요:
{{"label": "good" 또는 "bad", "summary": "한 줄 요약"}}"""
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 200,
"messages": [{"role": "user", "content": prompt}]
})
response = bedrock.invoke_model(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
body=body,
contentType='application/json'
)
response_body = json.loads(response['body'].read())
return response_body['content'][0]['text']
except Exception as e:
return json.dumps({"label": "bad", "summary": f"Error: {str(e)}"})
st_env.create_temporary_function("analyze_news", analyze_news)MSF는 Bedrock 이 제공하는 LLM을 활용하여 기존의 뉴스 데이터를 요약 하고 긍정인지 부정인지 판단할수 있습니다. 예를 들어서 뉴스 데이터 “아마존, 2024년 클라우드·AI 분야 200억 달러 투자 확대 발표 아마존(AMZN)이 1일 클라우드 컴퓨팅과 인공지능(AI) 사업 확장을 위해 올해 200억 달러를 추가 투자한다고 발표했다. 앤디 재시 아마존 CEO는 ‘AWS 클라우드 서비스와 생성형 AI 솔루션에 대한 기업 수요가 예상을 크게 웃돌고 있다‘며 ‘전 세계 데이터센터 확충과 AI 인프라 구축에 집중 투자할 것’이라고 밝혔다. 아마존은 특히 아시아태평양 지역에 50억 달러를 투입해 새로운 데이터센터 15개소를 신설하고, 생성형 AI 서비스 ‘베드록(Bedrock)’의 처리 용량을 현재 대비 300% 확대할 예정이다. 월가 애널리스트들은 이번 투자 확대로 아마존의 클라우드 부문 매출이 올해 35% 이상 성장할 것으로 전망한다고 밝혔다. 모건스탠리는 목표주가를 기존 220달러에서 250달러로 상향 조정했다. 아마존 주가는 발표 직후 장외거래에서 7% 급등했다.” 를 Bedrock LLM을 활용해 Json 형태 ({"label": "good", "summary": "아마존이 클라우드 컴퓨팅과 AI 사업 확대를 위해 향후 2024년까지 200억 달러를 투자할 계획이라고 발표했으며, 이는 아마존의 클라우드 부문 매출 35% 이상 성장이 기대됨."}) 로 변환할수 있습니다.
(4) 뉴스 데이터를 MSF UDF를 활용해 감정 분석 및 요약 한뒤 새로운 스트림으로 만들고 Kafka Sink를 통해 데이터를 전달하는 파이프라인
%flink.ssql
INSERT INTO news_summary_sink
SELECT symbol, news_id, event_time, analyze_news(news_content) as summary
FROM news_stream_source;- 데이터 소스:
news_stream_source: 뉴스 데이터 (symbol, news_id, event_time, news_content)news_summary_sink: 뉴스 감정 분석 안료 데이터 ((symbol, news_id, event_time, summary)
- Flink UDF:
analyze_news: 뉴스 감정 분석 및 summary를 해주는 Flink UDF
- 데이터 write:
INSERT INTO news_summary_sink: kafka sink로 데이터 송출
(5) Amazon Managed Service for Flink에서 뉴스 데이터와 주식 거래 데이터를 Interval Join 하는 파이프라인 구축
MSF는 다양한 조인 메카니즘을 가지고 있습니다. 하지만 그 중에서 레코드 단위로 실시간 조인하는 프로세스에 대해 설명하는 시간을 갖도록 하겠습니다. 실시간 조인 메카니즘을 이해하기 위해 먼저 Flink watermark 메커니즘에 대한 이해가 필요합니다.
MSF watermark 메카니즘이란?
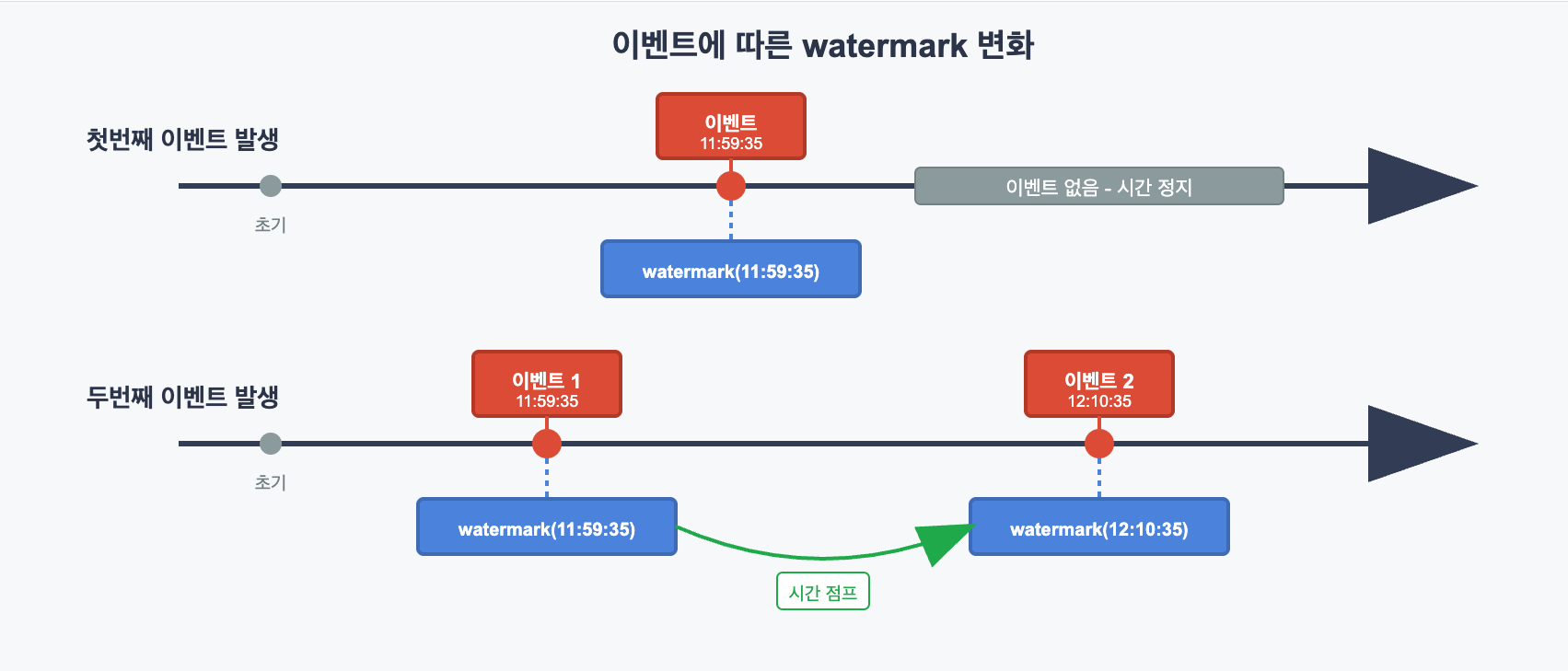
MSF의 실시간 분석에서 watermark는 시간 진행의 핵심 메커니즘입니다. watermark는 실제 데이터가 아닌 메타 레코드로, 마치 시계의 시침처럼 Flink 프로세스 안에서 현재 어느 시점까지 시간이 흘렀는지 알려주는 시간 신호입니다. watermark의 첫 번째 특징은 이벤트 기반으로 시간이 움직인다는 것입니다. 현실의 물리적 시간은 우리가 가만히 있어도 1초, 2초, 3초 이렇게 흘러갑니다.
하지만 Flink의 watermark는 실제로 아무런 이벤트가 없을 경우 진행되지 않고 이전 값에서 정지 상태를 유지합니다. 대신 이벤트가 들어올 때 그 이벤트 시간만큼 시간을 움직입니다. 예를 들어, 사용자가 11:59:35에 음식을 결제한다고 가정해 봅시다. 이 이벤트가 Flink의 처리 파이프라인에 도달하는 순간, watermark라는 메타 레코드가 스트림에 삽입되어 “현재 시간이 11:59:35까지 진행되었다”는 신호를 보냅니다. 이후 다른 사용자가 12:10:35에 결제하여 두 번째 이벤트가 생성됩니다. 이 두 번째 이벤트가 Flink의 스트림에 유입될 때, 새로운 watermark 메타 레코드가 생성되어 “현재 시간이 11:59:35에서 12:10:35로 진행되었다”라는 신호를 보냅니다. 그리고 watermark는 신호안에 두 가지 중요한 의미를 담고 있습니다. 첫 번째는 “현재 12:10:35까지 시간이 진행되었으니, 12:10:35 이전 데이터로 수행 가능한 모든 분석을 진행해“라는 처리 진행 신호이며, 두 번째는 “12:10:35 이후로는 그보다 이른 시간의 늦은 데이터(late data)를 더 이상 받지 않겠습니다”라는 지연 데이터 차단 메시지입니다.
이를 통해 Flink는 특정 시점까지의 데이터 완성도를 보장하여 안전한 분석 작업을 하는 동시에, 지연 데이터 처리 한계를 명확히 하여 무한 대기를 방지함으로써 실시간 스트림 처리에서 정확성과 성능의 균형을 맞춥니다. 정리하면 watermark는 데이터 스트림 사이사이에 끼어들어가는 특수한 메타레코드로서, Flink 시스템 전체에 시간 진행 흐름을 전달하고 분석 실행을 명령합니다.
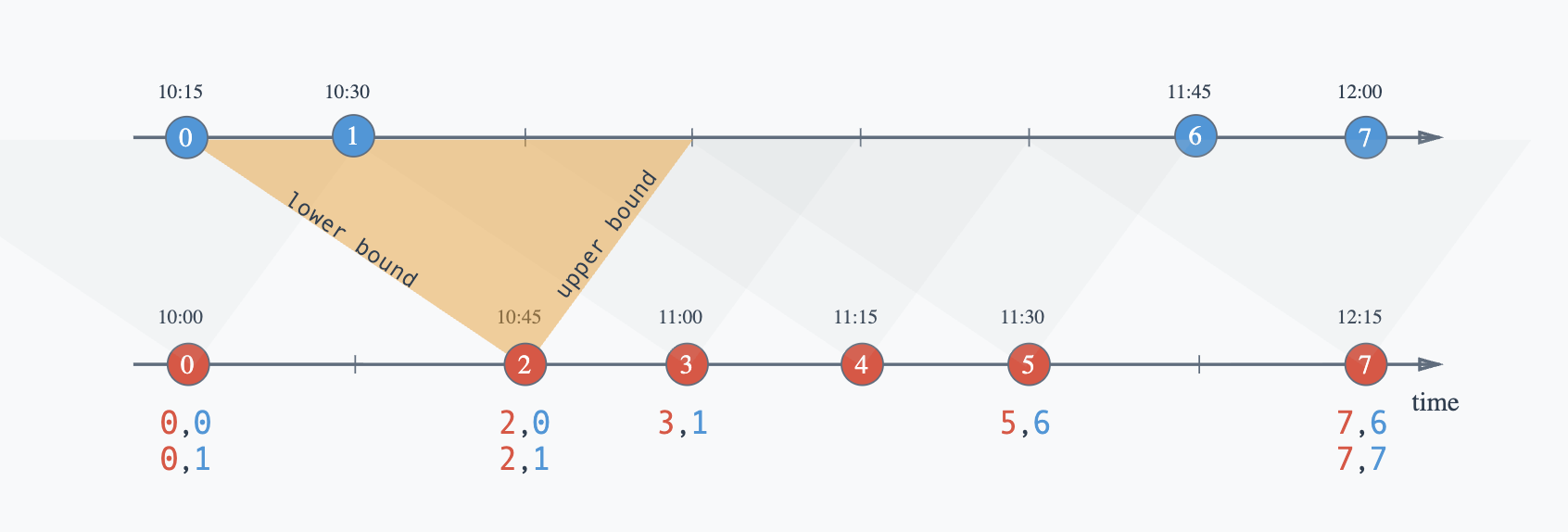
Interval Join 프로세서
Interval Join은 Flink에서 서로 다른 패턴을 가진 두 데이터 스트림을 record 기반으로 조인하는 프로세스입니다. 각 레코드가 도착할 때마다 해당 레코드의 타임스탬프를 기준으로 지정된 시간 범위 내에 있는 다른 스트림의 레코드들과 즉시 매칭을 시도합니다. 개별 레코드 단위로 조인 조건을 확인하여 매칭되는 레코드가 있으면 바로 결과를 출력합니다. 만약 Flink watermark 메카니즘이 없다면 어떻게 될까요 ?
두 스트림이 무한정 증가하면서 조인을 위해 메모리에 계속 누적되어 Out of Memory가 발생할 수 있습니다. 이를 방지하기 위해 Flink는 워터마크(Watermark)를 활용하여 더 이상 조인될 가능성이 없는 과거 데이터를 자동으로 메모리에서 제거합니다. 다시 말하면 워터마크는 Interval Join에서 메모리 관리에 중추적인 역할을 담당하며, 각 스트림의 진행 상황을 추적하며 제거 가능한 데이터를 식별합니다.
- Join 작업 예시: Red Event(news event)가 발생했을 때, Blue Event(stock event)가 다음 시간 범위 내에 있으면 Red Event(news event)와 조인하세요
- 범위 예시: Red Event Time(news event) – 30분 <Blue Event Time (stock event) < Red Event Time(news event)+ 15분
MSF를 활용하여 news와 stock데이터 Interval Join 후 분석하는 파이프라인
%flink.ssql
INSERT INTO news_result_sink
SELECT
n.symbol,
n.news_id,
n.event_time as news_time,
n.summary,
TUMBLE_START(s.event_time, INTERVAL '1' MINUTE) as window_start,
TUMBLE_END(s.event_time, INTERVAL '1' MINUTE) as window_end,
AVG(s.price) as avg_price,
AVG(s.volume) as avg_volume,
COUNT(*) as event_count
FROM news_summary_source n
JOIN stock_transaction_source s ON n.symbol = s.symbol
WHERE s.event_time BETWEEN n.event_time - INTERVAL '5' MINUTE AND n.event_time + INTERVAL '10' MINUTE
GROUP BY n.symbol, n.news_id, n.event_time, n.summary,
TUMBLE(s.event_time, INTERVAL '1' MINUTE);- 데이터 소스:
- news_summary_source: 뉴스 데이터 (symbol, news_id, event_time, summary)
- stock_transaction_source: 주식 거래 데이터 (symbol, price, volume, event_time)
- 조인 조건:
- 구문 : WHERE s.event_time BETWEEN n.event_time – INTERVAL ‘5’ MINUTE AND n.event_time + INTERVAL ’10’ MINUTE
- 뉴스 발생 시점 기준으로 5분 전 ~ 10분 후 범위의 주식 거래만 매칭
- interval join 패턴으로, 뉴스가 주식에 미치는 영향을 시간 범위로 제한
- 구문 : WHERE s.event_time BETWEEN n.event_time – INTERVAL ‘5’ MINUTE AND n.event_time + INTERVAL ’10’ MINUTE
- 윈도우 집계:
- TUMBLE(s.event_time, INTERVAL ‘1’ MINUTE): 주식 거래 시간을 1분 단위로 그룹화
- 뉴스 이벤트가 발생한 시점에서 5분 전과 10분후의 시간을 포함하여 윈도우별(1분 단위)로 평균 가격, 평균 거래량, 거래 건수 계산
- 데이터 write:
- INSERT INTO news_result_sink : kafka sink로 데이터 송출
3. 분석 결과


뉴스 이벤트(예시 : 아마존 주식)기반 주식 거래 패턴 분석은 다양한 목적으로 활용 될수 있습니다. 예를 들어 긍정적 뉴스와 부정적 뉴스에 대한 주가 반응 속도를 비교할수 있고 뉴스 주제와 실제 주가 움직임 간의 상관관계를 파악할 수 있습니다. 더하여 시계열 패턴 분석을 통해 각 뉴스 이벤트 후 주가 추세의 지속성과 및 시간대별 가격 변동성 패턴을 분석할수 있습니다. 이러한 패턴 분석은 비슷한 뉴스 이벤트가 발생했을때 주가가 어떤 흐름을 변할지 예측 할수 있는 중요한 지표로 사용될 수 있습니다. 더 나아가 Flink UDF에 다양한 ML모델을 추가해서 데이터를 생성하고 분석한다면 예측의 정확성을 더욱 높일수 있을 것 입니다.
4. Amazon Data Firehose 활용하여 MSK 데이터 S3 적재
Amazon Data Firehose는 MSK에서 생성되는 대용량 스트리밍 데이터를 Amazon S3로 자동 적재하는 서비스입니다. 이 서비스의 핵심은 편리성입니다. 단순히 MSK 토픽을 소스로 지정하고 S3 버킷을 대상으로 설정하는 것만으로 별도의 코드 작성이나 인프라 관리 없이 자동으로 데이터 전송이 시작할수 있습니다. 현재 Interval Join을 마친 분석 데이터가 MSK topic(analysis)에 적재되어 있는 상황입니다. Amazon Data Firehose를 통해 MSK에서 S3로 복잡한 구성 없이 적재 하는 파이프라인을 만들어 보도록 하겠습니다.
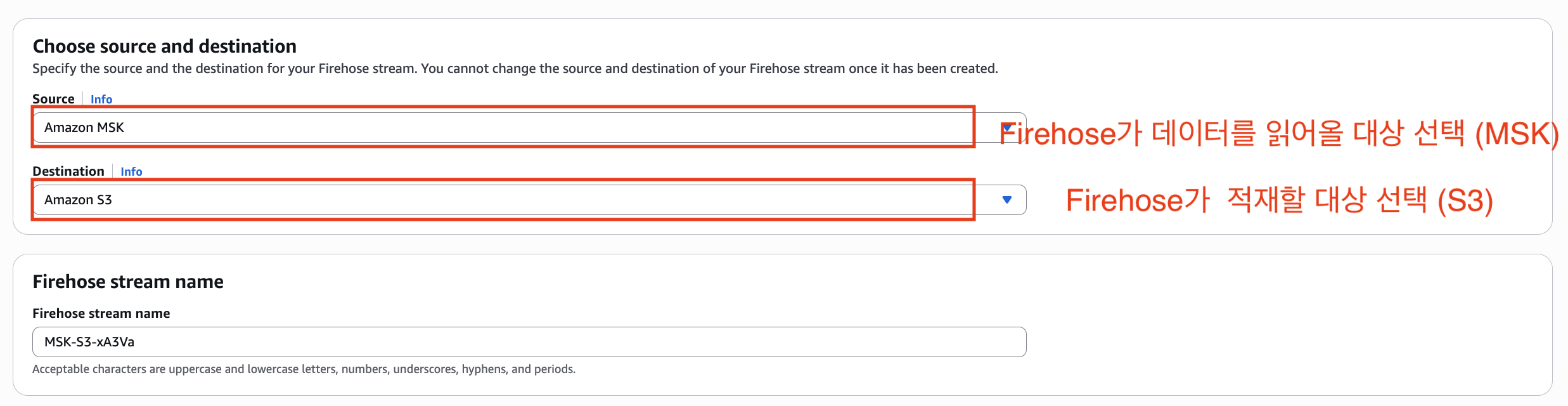
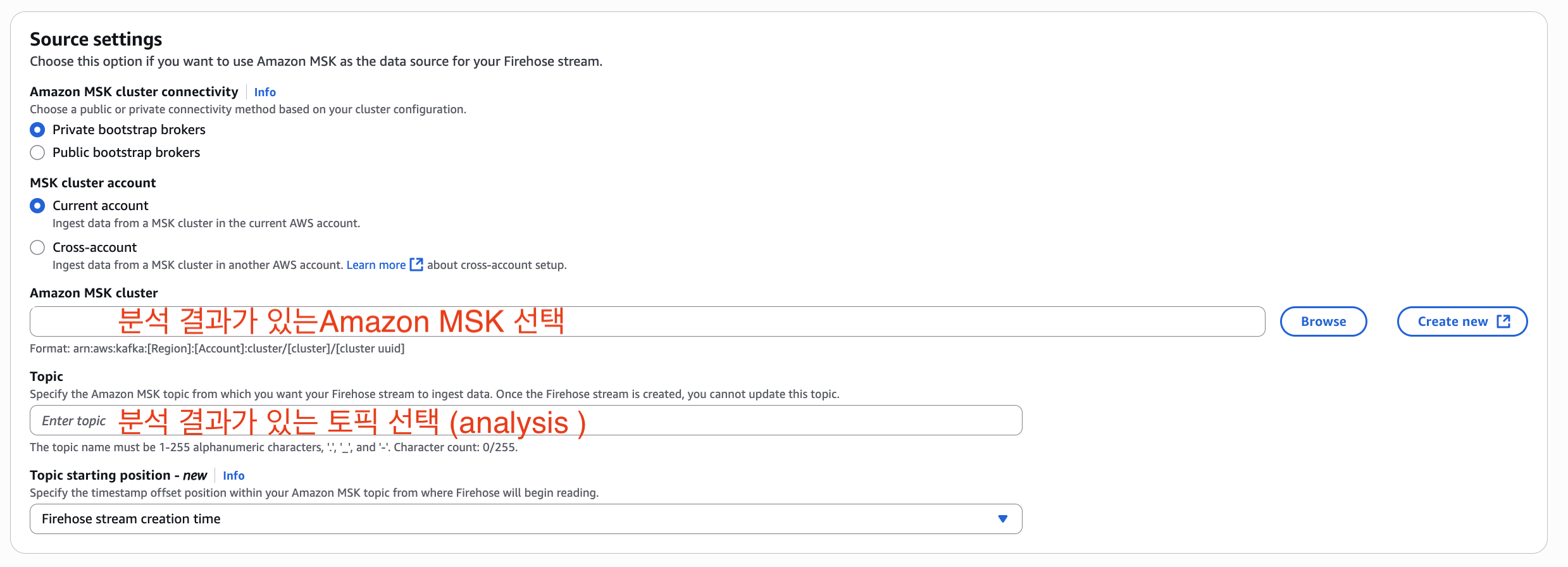
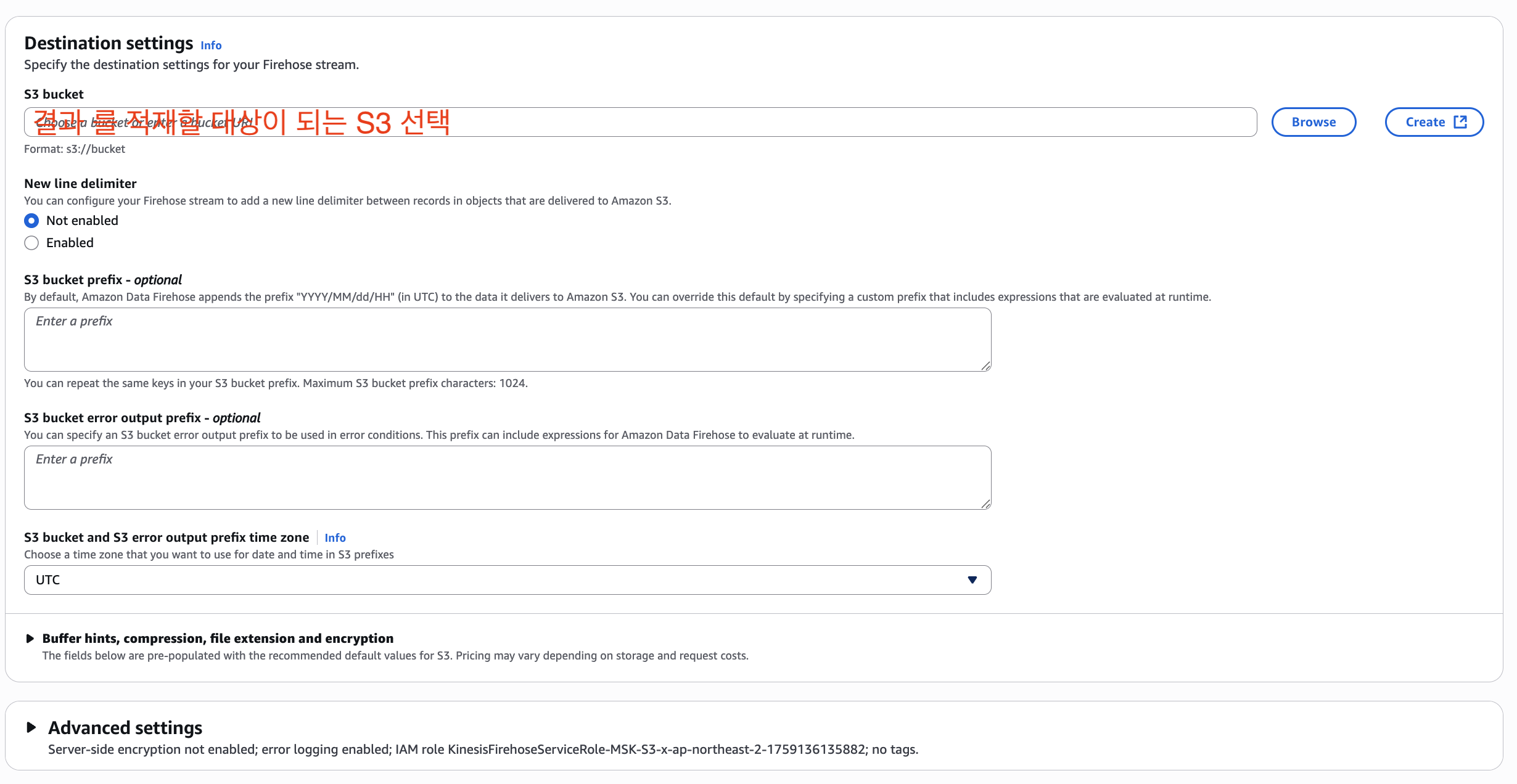
결론
뉴스 기반 주식 분석을 하기 위해선 주식 거래의 고빈도 연속 스트림과 뉴스의 저빈도 불규칙 이벤트를 결합하여 분석할 수 있는 메카니즘이 필요합니다. Flink는 이러한 문제에 대한 효율적인 해답을 제시합니다. Event Time 기반의 동적 분석, 그리고 UDF를 통한 실시간 LLM 연동이 가능하며 뉴스 발생 순간 해당 시점 전후의 주식 데이터를 즉시 결합하고 분석할 수 있습니다.
특히 AWS 생태계를 활용하면 더 간편하게 구축할 수 있습니다. Amazon MSF는 완전 관리형 서비스로서 Amazon MSK와의 네이티브 통합을 통해 대용량 스트림 데이터 수집을 원활하게 할수 있으며, Amazon Bedrock과의 연동으로 고성능 AI 모델을 활용한 다차원적 뉴스 분석이 가능합니다. 예를 들어 Bedrock의 다양한 파운데이션 모델을 통해 감정 분석, 키워드 추출, 요약 생성뿐만 아니라 시장 영향도 예측, 뉴스 주제별 리스크 평가, 투자 심리 지수 산출 등 복합적이고 전문화된 금융 분석을 동시에 수행할 수 있습니다. 또한 Amazon MSF는 Amazon Data Firehose를 통해 Amazon S3 혹은 Amazon S3 Tables 서비스와의 seamless한 연결을 통해 분석 결과를 쉽고 편리하게 저장할수 있습니다.
저장된 데이터는 Amazon Athena를 통한 SQL 분석, Amazon QuickSight를 통한 시각화, Amazon OpenSearch를 통한 검색 등 다양한 AWS 서비스와 연계하여 활용할 수 있습니다. 결과적으로 MSF 기반의 Event Driven 아키텍처는 확장성, 속도, 편리성을 기반으로 뉴스와 주가 간의 정확한 인과관계을 실시간으로 제공함으로써, 금융 시장에서 정보의 가치를 극대화하고 투자의사결정의 속도와 정확성을 향상시킬 수 있는 기회를 제공합니다.