AWS 기술 블로그
Amazon Bedrock으로 해보는 Nova 모델 지식 증류, 배포, 평가
Bedrock 모델 커스터마이제이션 개요
Amazon Bedrock은 생성형 AI 애플리케이션 및 에이전트 구축을 위한 완전 관리형 서비스입니다. LLM포함 다양한 AI 모델들을 통합 API를 통해서 쉽게 사용할 수 있으며 미세 조정하고 애플리케이션에 연결하는 데 필요한 도구와 기능을 제공하여 개발자가 인프라 관리 부담 없이 빠르고 안전하게 생성형 AI 애플리케이션을 개발하고 배포할 수 있도록 해줍니다.
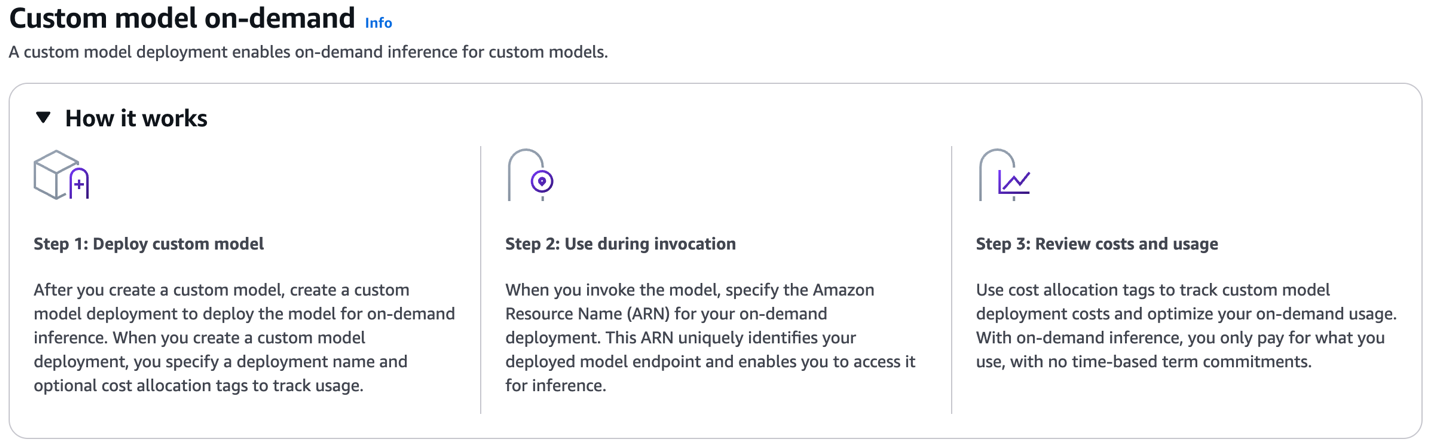
Bedrock 온디맨드(on-demand) 배포 기능 출시
Amazon Bedrock은 기업이 자체 모델을 구축할 수 있도록 지속적인 사전 훈련(Continued pre-training), 미세 조정(Fine-tuning), 지식 증류(Knowledge distillation)라는 세 가지 유형의 모델 커스터마이제이션 기능을 제공합니다. 2025년 7월, 이러한 커스텀 모델을 위한 커스텀 모델 온디맨드(Custom model on-demand) 배포 기능이 새롭게 출시되었습니다. 이전에는 Bedrock에서 학습한 커스텀 모델을 배포할 때 사전 용량 예약 방식인 프로비전드 처리량 모드(Provisioned Throughput mode)만 지원했었습니다. 이번 새로운 기능 출시로 커스텀 모델을 온디맨드 방식으로 배포할 수 있게 되었으며, 모델 배포 후에는 기본(Base) 모델 기준으로 과금 됩니다. 이를 통해 비용 효율적으로 빠른 실험과 운영이 가능 해졌습니다.
모델 커스터마이제이션 유형
LLM의 성능을 개선하는 데 많이 활용되는 모델 커스터마이제이션 방법으로 미세 조정과 지식 증류가 있습니다. 미세 조정은 이미 사전 학습된 모델을 특정 작업이나 도메인에 맞게 추가로 훈련시키는 과정입니다. 이 과정에서 모델은 원래의 크기와 복잡성을 그대로 유지하면서 특정 작업에 대한 성능이 향상됩니다. 반면 지식 증류는 큰 모델(교사 모델)의 지식을 작은 모델(학생 모델)로 전달하는 기술입니다. 이는 마치 경험 많은 선생님이 학생에게 지식을 전수하는 것과 비슷합니다. 대규모 데이터셋으로 사전 훈련된 교사 모델이 입력에 대하여 출력을 생성하면, 이 출력이 학생 모델의 학습 데이터로 사용됩니다. 작은 학생 모델은 이 데이터를 사용해 교사 모델의 행동과 예측을 모방하도록 훈련됩니다. 이렇듯 미세 조정이 모델의 크기를 유지하면서 특정 작업에 대한 성능을 향상시키는 것이라면, 지식 증류는 모델의 크기를 줄이면서 성능을 최대한 유지하는 것이 목적입니다. 모델 크기가 작아져 제한된 환경에서도 쉽게 배포할 수 있고, 운영 비용도 절감됩니다. 또한 작은 모델은 지연 시간이 낮고 처리량이 높아 성능 면에서도 이점이 있습니다. 아래의 그림처럼 지식 증류에는 2가지 접근 방법이 있습니다. 작업 특화 증류(Task-specific distillation)는 대형 모델을 특정 작업에 미세 조정 후, 그 지식을 작은 모델로 증류하여 특정 작업에 최적화된 모델을 만들고요. 작업 독립(Tast-agnostic)은 미세 조정 단계 없이 바로 특정 작업에 최적화된 증류 작업을 실행하는 방식입니다.
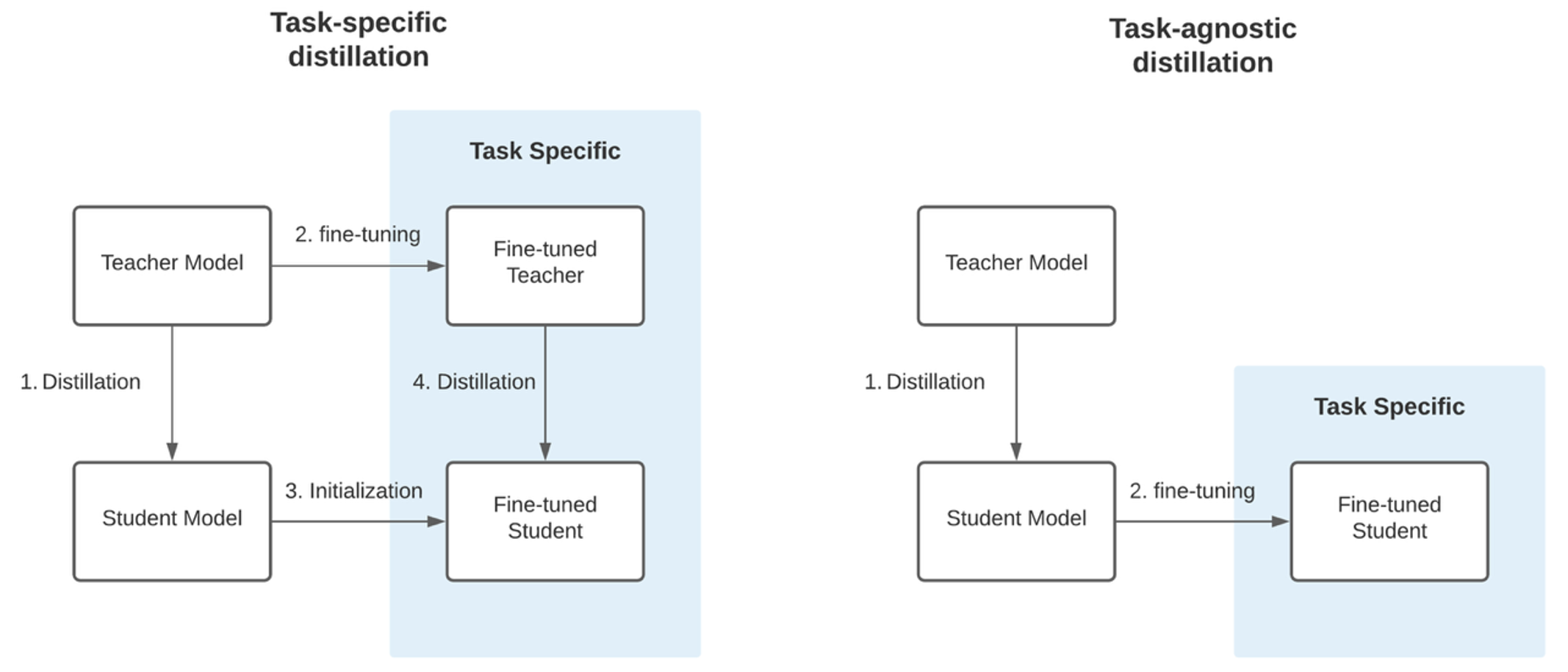
<출처: Figure from FastFormers>
본 블로그에서는 대형 모델의 주요 특성을 선택적으로 가져와서 특정 응용 분야에 맞춤 화 할 수 있는 기술인 지식 증류를 작업 독립 방식으로 단계적으로 실행 하려고 합니다.
모델 지식 증류 과정
지식 증류에 사용할 모델들을 선정할 때에는 성능 목표, 응답속도(Latency), 운영 비용(TCO) 등을 종합적으로 고려합니다. 지식 증류 실험에 사용할 Amazon Nova 모델들의 성능은 Premier, Pro, Lite, Micro 순이고 모델 응답속도와 운영 비용은 반대 순서입니다. Nova Premier를 교사모델로 선택한 상황에서 학생 모델로 Nova Pro를 선택한다는 것은 응답속도 보다는 전체적인 성능을 유지하면서 특정 태스크를 개선하고자 하는 경우일 것이고요. 학생 모델로 Nova Lite 나 Micro를 선택한다면 빠른 응답속도와 운영 비용을 줄이면서 특정 태스크의 성능을 높이고자 할 때 사용할 수 있는 옵션일 것입니다. 본 블로그에서는 이커머스 고객 Q&A 챗봇 애플리케이션 개발하는 환경을 가정하고, 이를 위한 교사 모델로 Nova Premier 1.0, 학생 모델로 Nova Lite 1.0을 선택하였습니다.
학습 데이터 생성
첫 번째로 할 일은 지식 증류를 수행하기 위해서 학습 데이터를 생성하는 일입니다. 학습 데이터는 아래의 OpenAI 메시지 포맷을 따릅니다. 이 포맷에 맞게 시스템 프롬프트와 사용자 프롬프트를 만들고 어시스턴트 응답 데이터를 생성합니다.
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": <Your-System-Prompt>
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": <Your-Prompt-And-OR-Context>
}
]
},
{
"role": "assistant",
"content": [
{
"text": <Your-Ground-Truth-Response>
}
]
}
]
}본 블로그에서는 전반적인 모델 증류 과정을 설명하는 용도로 기존 LLM 모델을 통해서 간단한 포맷의 합성 데이터를 만들어서 학습과 평가에 사용하려고 합니다. 비즈니스 환경에서는 실제 데이터로 도메인 특성을 반영하는 데이터 포맷으로 구성하여 학습 하는 것이 필요합니다. 우선 가상의 이커머스 Q&A 챗봇 애플리케이션이 간결하면서도 핵심적인 내용 위주로 답변을 하도록 다음과 같은 시스템 프롬프트를 만들었습니다.
다음으로 Bedrock 플레이그라운드에서 Anthropic Sonnet 3.7 모델을 사용하여, 위의 시스템 프롬프트를 포함한 학습 용 사용자와 어시스턴트 응답 프롬프트 쌍을 100개 만들었습니다. 아래 그림과 같이 사용자 데이터는 <context> 태그를 이용하여 질문과 관련된 맥락 정보를 제공하며, 바로 이어서 질의 하면 맥락 정보를 참고하여 답변할 수 있도록 생성하였습니다. 증류 작업 실행 후 모델 성능 측정하는 데 사용할 테스트 프롬프트 쌍도 20개 만들었습니다. 데이터 셋은 아래의 OpenAI 메시지 포맷을 따릅니다. 이러한 데이터 셋으로 모델 증류를 하는 목적은 맥락 정보를 바탕으로 답변의 톤 앤 매너를 선호 스타일로 맞추기 위한 것이라고 할 수 있습니다

지식 증류 작업 실행
앞에서 생성한 학습 데이터를 S3에 업로드하고 작업을 위한 적절한 IAM 권한 설정 후, boto3 클라이언트의 create_model_customization_job 함수를 호출하여 지식 증류 작업을 실행할 수 있습니다.
response = bedrock_client.create_model_customization_job(
jobName=job_name,
customModelName=model_name,
roleArn=role_arn,
baseModelIdentifier=student_model,
customizationType="DISTILLATION",
trainingDataConfig={
"s3Uri": training_data
},
outputDataConfig={
"s3Uri": output_path
},
customizationConfig={
"distillationConfig": {
"teacherModelConfig": {
"teacherModelIdentifier": teacher_model,
"maxResponseLengthForInference": max_response_length
}
}
}
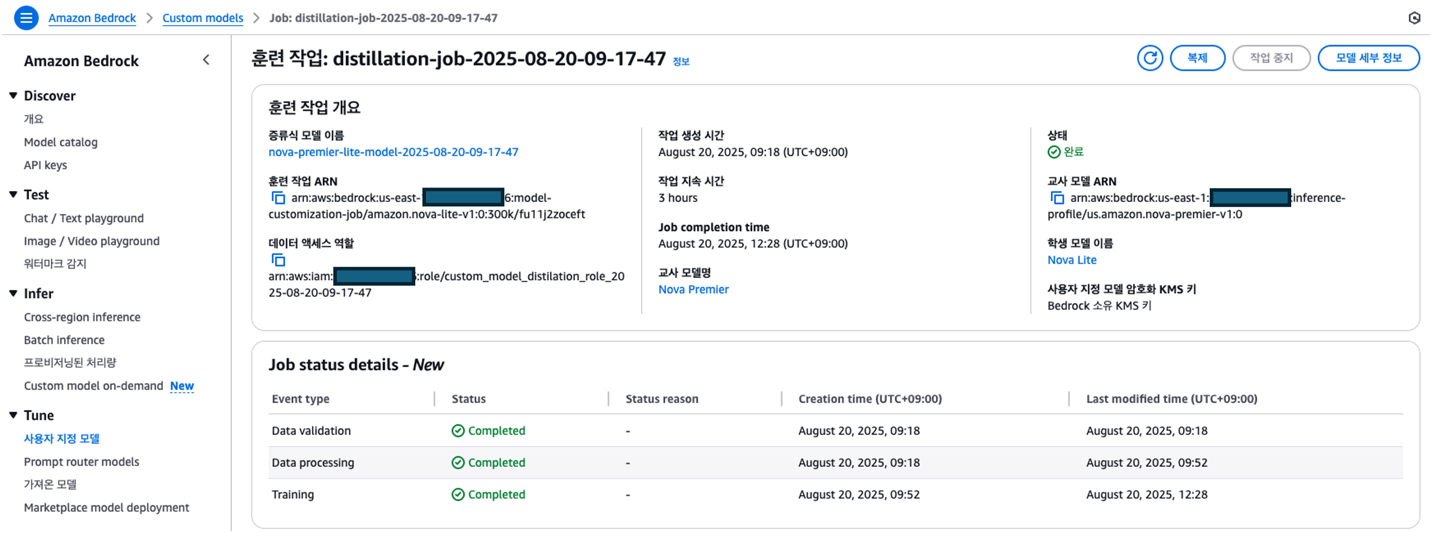
)지식 증류 작업 실행 후 진행 상황은 Amazon Bedrock 콘솔 (Amazon Bedrock > Custom models > Job)에서 확인할 수 있으며, AWS CLI 명령으로도 조회할 수 있습니다.
이와 같은 모델조합과 100개의 샘플 데이터셋으로 학습 하는데 약 3시간 소요 되었습니다.
지식 증류된 모델 배포
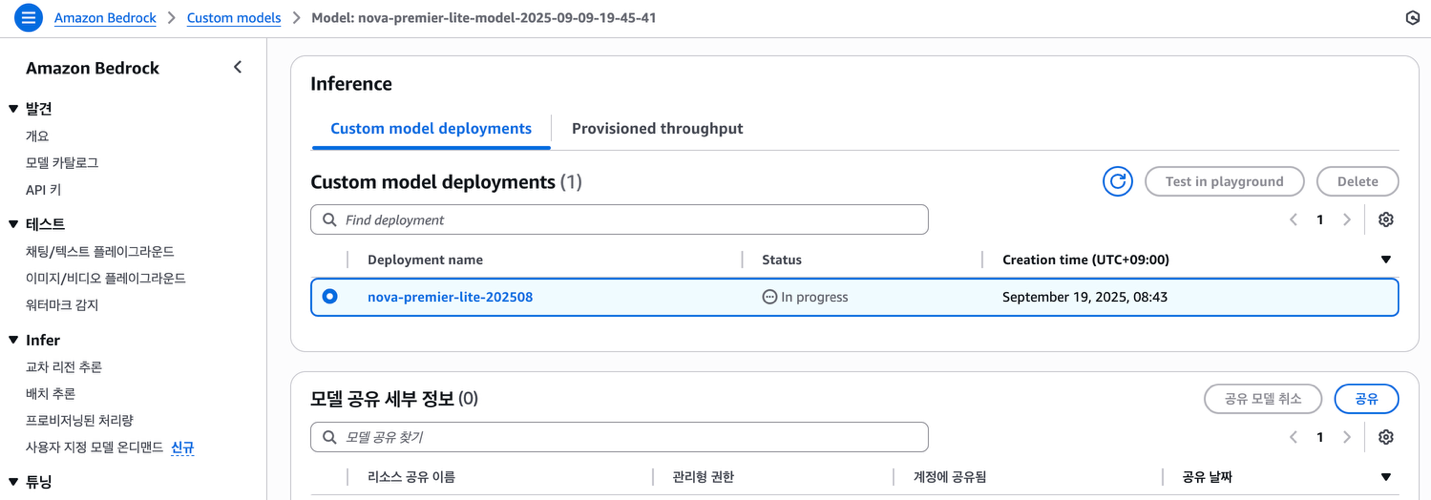
지식 증류 작업 완료 후 생성된 증류 모델은 Amazon Bedrock 콘솔을 통해서 배포할 수 있으며, boto3 client의 create_custom_model_deployment() 함수를 이용하여 배포 할 수 있습니다. 이후 진행 상황은 AWS CLI나 Bedrock 콘솔 (Amazon Bedrock > Custom models > Model)을 통해서 확인할 수 있습니다.
response = bedrock.create_custom_model_deployment(
modelDeploymentName="nova-premier-lite-202508",
modelArn=model_arn,
description=description,
tags=[
{'key': 'Environment', 'value': 'Development'},
{'key': 'CreatedBy', 'value': 'SimpleDeployScript'},
{'key': 'CreatedAt', 'value': datetime.now().isoformat()}
],
clientRequestToken=str(uuid.uuid4())
)
모델 성능 평가
LLM 벤치마크 개요
일반적으로 새로운 모델이 출시되거나 버전이 업그레이드 되면 MMLU(Massive Multitask Language Understanding), MMMU(Multilingual Q&A), GPQA Diamond(Graduate level reasoning) 등과 같은 벤치마크 결과도 함께 제공이 되며, 이러한 결과 리포트를 보고 모델의 성능을 비교하고 가늠할 수 있습니다. 이러한 벤치마크 테스트에서 좋은 점수를 얻는다는 것은 해당 모델의 언어 이해력과, 전문 지식 보유, 논리적인 추론 능력의 우수성을 객관화된 지표로 공개하는 것이기 때문에 모델 개발자 및 제공자들에게 벤치마크 테스트는 중요한 필수 과정이 되었습니다. 다만 높은 벤치마크 결과가 항상 비즈니스 요구 사항을 충족시키는 것은 아니기 때문에, 모델 활용 단계에서 비즈니스 상황에 맞는 휴리스틱 한 평가 과정이 필요할 수 있습니다. 비즈니스 요구사항을 잘 이해하는 사람이 직접 평가하는 것이 가장 좋겠지만 많은 시간과 비용이 드는 제약이 있습니다. 대안으로 LLM as a Judge를 고려해볼 수 있습니다. LLM as a Judge는 LLM이 다른 LLM이나 시스템의 응답을 평가하고 점수를 매기는 방식으로 시간과 비용 효율적으로 자동화된 평가를 수행할 수 있으며, 다양한 비즈니스 요구사항에 맞게 평가 기준도 쉽게 조정할 수 있습니다. 앞서 실행한 증류 작업의 경우 이커머스용 Q&A 라는 특정 태스크의 성능을 개선하려고 했기 때문에, 전체적인 성능을 측정하는 벤치마크 테스트에서는 유의미한 결과 차이가 나타나지 않을 수 있습니다. 반면 LLM as a Judge는 특정 태스크의 개선 여부를 측정하도록 기준도 직접 설계하고 만들어서 테스트 할 수 있습니다. 다만 이 방식은 앞선 벤치마크처럼 확률/통계 기반의 성능 측정이 아닌 LLM 기반의 주관적인 평가 방식이기 때문에, 기본적으로는 표준화된 벤치마크 결과를 고려하여 모델들을 선택하고, 이러한 모델들로부터 파생된 커스텀 모델들을 평가하는 방법 중의 하나로서 유용할 것 같습니다.
LLM as a Judge 실험 결과
그러면 전 단계에서 생성된 증류 Nova 모델과 기존의 Nova 모델들을 LLM as a judge 로 성능을 비교해보겠습니다. 먼저 정확도, 완성도, 관련성, 유용성, 언어품질등 5개의 영역에서 1~5점 스케일로 아래와 같은 기준으로 평가 하도록 프롬프트를 만들었습니다. 평가 영역은 더 세분화 할 수 있으며 평가 기준이나 점수 스케일도 비즈니스 환경에 맞게 조절 하면 됩니다. 참고로 Bedrock의 빌트인 LLM as a Judge 평가 지표는 총 12개(품질 9개, 책임감AI 3개)이며 1~5점 스케일입니다.
평가 기준 용 프롬프트 데이터셋을 만든 후, 채점을 맡을 평가자(Evaluator) 모델로 Anthropic Sonnet 3.7을 선택하였습니다. 평가자로 신뢰할 수 있는 모델로 생각되는 다른 모델을 사용해도 됩니다. 다음으로 이커머스 Q&A 테스트용으로 생성한 20개의 프롬프트 데이터셋을 대상으로 Nova의 각 모델별로 응답하도록 하였습니다. 각 응답 내용에 대해 평가자 모델로 5개의 품질 영역에 대해 점수를 부여하고 피드백까지 생성하도록 하였습니다.

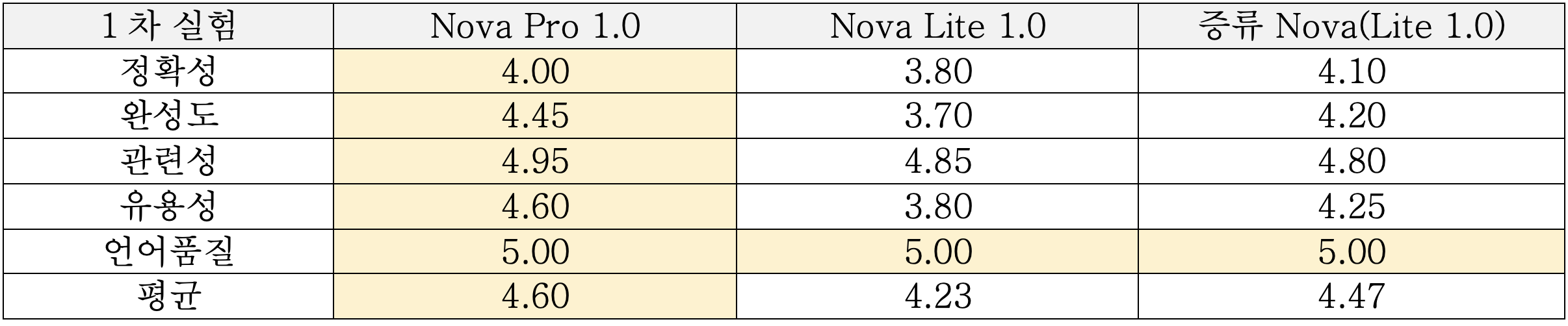
평가는 2차례 실행하였으며 결과를 요약해보면, 전체 평균 점수는 증류 Nova와 Nova Pro 모델이 비슷한 수준의 성능을 보였고, Nova Lite는 두 모델 대비 낮은 성능을 보였습니다. 증류 Nova 모델은 동일 아키텍처 모델인 Nova Lite 대비해서는 성능이 많이 개선되었습니다.
<표1: LLM as a Judge 1차 테스트 결과>
<표2: LLM as a Judge 2차 테스트 결과>
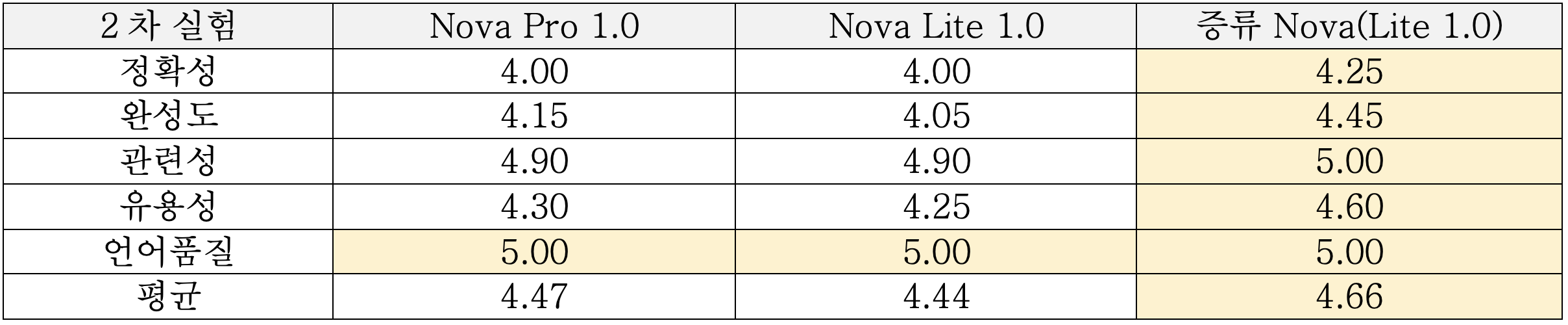
증류 Nova 모델을 학습 하는데 Bedrock 최소 요구 사항인 100개의 데이터 샘플만을 사용하였고, 데이터 샘플도 합성하여 만들었습니다. 차후에 프로덕트 환경에서 더 많은 실제 데이터 샘플로 학습했을 때 추가적인 성능 개선도 가능해 보입니다.
응답속도 및 비용
비즈니스 환경에서는 비용과 응답속도도 중요한 고려 사항이며, 이 영역에서 지식 증류의 장점은 명확합니다. 증류 Nova 모델은 Nova Premier의 지식과 전문성을 효과적으로 흡수하면서, Nova Lite 수준의 콤팩트한 모델 크기와 운영 비용, 그리고 응답속도를 그대로 유지합니다. 아래 데이터를 보면, 증류 Nova Lite는 Nova Pro대비 약 13.3배 더 저렴한 비용으로 운영 가능합니다. 입력 토큰 비용은 Nova Pro의 $0.80 대비 $0.06으로 낮고, 출력 토큰 비용 또한 $3.20에서 $0.24로 줄어듭니다. 응답속도 측면에서도 Nova Lite는 초당 약 146개 토큰을 처리하여, Nova Pro의 90개 토큰 대비 약 1.6배 빠른 처리 속도를 보여줍니다. 증류 Nova 모델의 경우 LoRA 어댑터를 활용함으로써 일반 Nova Lite 모델 대비 약간의 오버헤드는 있으나, 여전히 Nova Pro 대비 매우 저렴한 비용과 빠른 속도를 유지하면서 지식 증류의 비즈니스 가치를 잘 보여줍니다.

<출처: https://artificialanalysis.ai/ >
마치면서
이번 실험을 통해 지식 증류 기법이 갖는 장점을 확인할 수 있었습니다. 지식 증류는 대형 LLM의 지식을 작은 모델로 효과적으로 전달하는 방법입니다. 최소한의 합성 데이터만으로도 Nova Premier의 지식을 Nova Lite로 성공적으로 전달할 수 있었으며, 특히 기존 Nova Lite 대비 향상된 성능을 보이면서도 빠른 응답속도와 낮은 운영비용이라는 장점을 유지할 수 있었습니다. Bedrock의 완전 관리형 환경에서 손쉽게 구현할 수 있는 장점과 함께, 새롭게 출시된 커스텀 모델 온디맨드 배포 기능을 통해 실제 서비스 환경에서 비용 효율적으로 운영하는 것이 가능 해졌습니다. 이러한Bedrock 기반의 지식 증류가 엔터프라이즈 환경에서 생성형 AI 도입을 가속화할 수 있는 실용적이고 효과적인 방법이 되기를 기대합니다.