AWS 기술 블로그
Day1Company의 Amazon EKS와 Amazon Bedrock 기반 초개인화 학습 피드백 서비스 사례
개요
교육산업의 디지털 전환과 새로운 도전
최근 교육산업은 급격한 디지털 전환의 흐름 속에서 근본적인 변화를 맞이하고 있습니다. 특히 교육 시장에서는 개인화된 학습 경험과 데이터 기반 교육 효과 측정이 핵심 경쟁력으로 부상하고 있으며, 생성형 AI의 등장은 이러한 트렌드를 더욱 가속화하고 있습니다.
그러나 많은 교육 기업들이 디지털 전환 과정에서 공통적인 어려움에 직면하고 있습니다:
- 학습 데이터의 휘발성: 1:1 수업이나 실시간 상호작용에서 생성되는 가장 가치 있는 학습 데이터가 체계적으로 수집·분석되지 못하고 소실됩니다.
- 피드백 품질의 불일치: 강사의 역량과 상황에 따라 학습자가 받는 피드백의 품질이 달라져, 일관된 교육 경험 제공이 어렵습니다.
- 운영 효율성의 한계: 행정 업무와 반복적인 리포트 작성에 소요되는 시간이 실제 교육의 질을 높이는 데 투입될 리소스를 잠식합니다.
- 데이터 기반 의사결정의 부재: 학습자의 성장을 객관적으로 추적하고 교육 과정을 최적화할 수 있는 데이터 기반의 의사결정 체계가 절실합니다.
본 글에서는 1:1 언어 교육 서비스를 제공하는 데이원컴퍼니의 ’포도스피킹(PODO Speaking)’이 이러한 교육산업의 구조적 과제를 AWS 클라우드 기술과 생성형 AI를 결합하여 어떻게 해결했는지 소개합니다. Amazon EKS(Elastic Kubernetes Service), Amazon Bedrock 등을 활용하여 음성 대화 데이터를 실시간으로 분석하고, 모든 학습자에게 일관되고 개인화된 피드백을 자동으로 제공하는 시스템을 구축한 실제 사례를 통해, 교육 데이터의 활용 방안, AI 기반 개인화 전략, 그리고 클라우드 네이티브 아키텍처 설계의 실전 노하우를 공유하고자 합니다.
데이원컴퍼니 소개
데이원컴퍼니는 급변하는 직무 환경에 대응하는 실무 중심의 커리큘럼을 제공하는 대한민국 대표 성인 교육 기업입니다. 1:1 언어 교육 서비스 ‘포도스피킹(PODO Speaking)‘은 이러한 데이원컴퍼니의 핵심 브랜드 중 하나로, 기술을 통해 교육 효과를 극대화하는 것을 목표로 하고 있습니다.
프로젝트 진행 배경
핵심 문제 정의
‘포도스피킹’ 서비스는 WebRTC 기반의 안정적인 1:1 수업 환경을 제공하고 있었으나, 데이터 활용 측면에서 한계에 직면했습니다. 1:1 음성 대화라는 핵심 학습 데이터가 수업 종료와 함께 소실되어 객관적인 학습 분석과 데이터 기반 의사결정이 불가능했습니다. 또한 튜터의 역량과 컨디션에 따라 피드백 품질 편차가 발생했고, 리포트 작성 등 반복적인 행정 업무로 인해 튜터가 수업 준비 및 진행에 집중하기 어려운 리소스 비효율 문제도 존재했습니다.
프로젝트 목표
이러한 문제를 해결하기 위해, 본 프로젝트의 목표는 모든 학생에게 24시간 이내에 일관된 품질의, 객관적 데이터에 기반한, 초개인화된 학습 피드백을 완전 자동으로 제공하는 것으로 설정되었습니다.
이를 위한 핵심 성과 지표(KPI)는 다음과 같습니다:
- 리포트 작성 시간 제거: 튜터의 개입 제거
- 리포트 생성 속도: 수업 종료 후 24시간 이내 제공
- 운영 비용 최적화: 생성형 AI 비용 최적화
이러한 목표를 달성하기 위해, 운영 및 확장성의 이점을 제공하는 Amazon EKS 기반 컨테이너 환경과, Foundation Model 활용의 유연성을 극대화하는 Amazon Bedrock의 서버리스 추론 환경을 유기적으로 결합한 하이브리드 아키텍처를 최종 솔루션 아키텍처로 확정했습니다.
초기 접근과 기술적 난제
초기 아키텍처 설계
프로젝트 초기에는 음성 대화 데이터를 수집하고 AI로 분석하여 리포트를 생성하는 단순한 파이프라인을 구상했습니다. 수업이 종료되면 음성 파일을 텍스트로 변환(STT)하고, 생성형 AI가 전체 스크립트를 한 번에 분석하여 리포트를 작성하는 방식이었습니다.
직면한 기술적 난제
그러나 실제 구현 과정에서 다음과 같은 현실적인 문제에 직면했습니다.
1. AI 멀티태스킹의 한계
복잡한 작업을 일괄 처리 시, 응답 시간을 초과하거나, 일부 작업(예: 예문 생성)을 누락하거나, 사실이 아닌 내용을 생성하는 환각(Hallucination) 현상이 발생했습니다.
2. 비용 및 토큰 제한
긴 수업 스크립트 전체를 단일 요청으로 처리할 경우, AI의 추론과정이 길어지게 되면서 과도한 토큰 소모로 비용이 급증했습니다. 특히, 초기 도입 단계의 Amazon Bedrock 환경에서는 모델이 한 번에 처리할 수 있는 토큰의 크기에 물리적인 제한이 존재했습니다.
해결 전략 및 최종 아키텍처
문제 해결을 위한 아키텍처 전략
이러한 제약 사항을 극복하기 위해 기술과 파트너십이라는 두 가지 전략을 동시에 실행했습니다.
1. 아키텍처 설계: ‘단계 분리 원칙(Atomic Principle)’ 적용
초기 테스트 결과, AI 모델에 대규모 컨텍스트를 한 번에 요청할 경우 컨텍스트 오염(Context Contamination)이나 환각 현상(Hallucination)이 발생하는 것을 식별했습니다. 또한, 여러 개의 명령을 동시에 요청하면 일부 작업이 누락되는 안정성 문제도 있었습니다. 이를 근본적으로 해결하기 위해, 모든 작업을 AI가 가장 잘 처리할 수 있는 명확한 최소 단위로 분리하는 아키텍처를 채택했습니다.
2. 신뢰도 확보: ‘검증 프로세스’ 및 ‘데이터 정제’
‘단계 분리 원칙’을 적용한 후, 각 단계에서 반환되는 응답의 신뢰도를 극대화하는 것이 다음 과제였습니다. 이를 위해 저희는 핵심 분석 과정에서 동일한 요청을 3번 실행하여 2회 이상 일치하는 결과만 채택하는 ‘검증 프로세스(Verification Process)’를 도입했습니다. 또한, 프롬프트에는 최적화된 최소한의 데이터만 전달하는 ‘데이터 정제(Data Refinement)’ 로직을 적용하여 AI가 일관된 품질의 결과를 반환하도록 유도했습니다.
3. 플랫폼 제약 극복: AWS와의 파트너십
이러한 아키텍처적 개선 과정에서 사용하고자 하는 모델에 대한 Amazon Bedrock의 토큰 크기 제한이라는 제약이 존재했으나, AWS Support 및 Account 팀과의 긴밀한 협업을 통해 서비스 요건에 필요한 수준까지 토큰 리밋을 상향 조정하며 신속하게 해결할 수 있었습니다.
최종 아키텍처 개요
최종 구현된 아키텍처는 4개의 독립적인 단계로 구성된 비동기 파이프라인입니다.
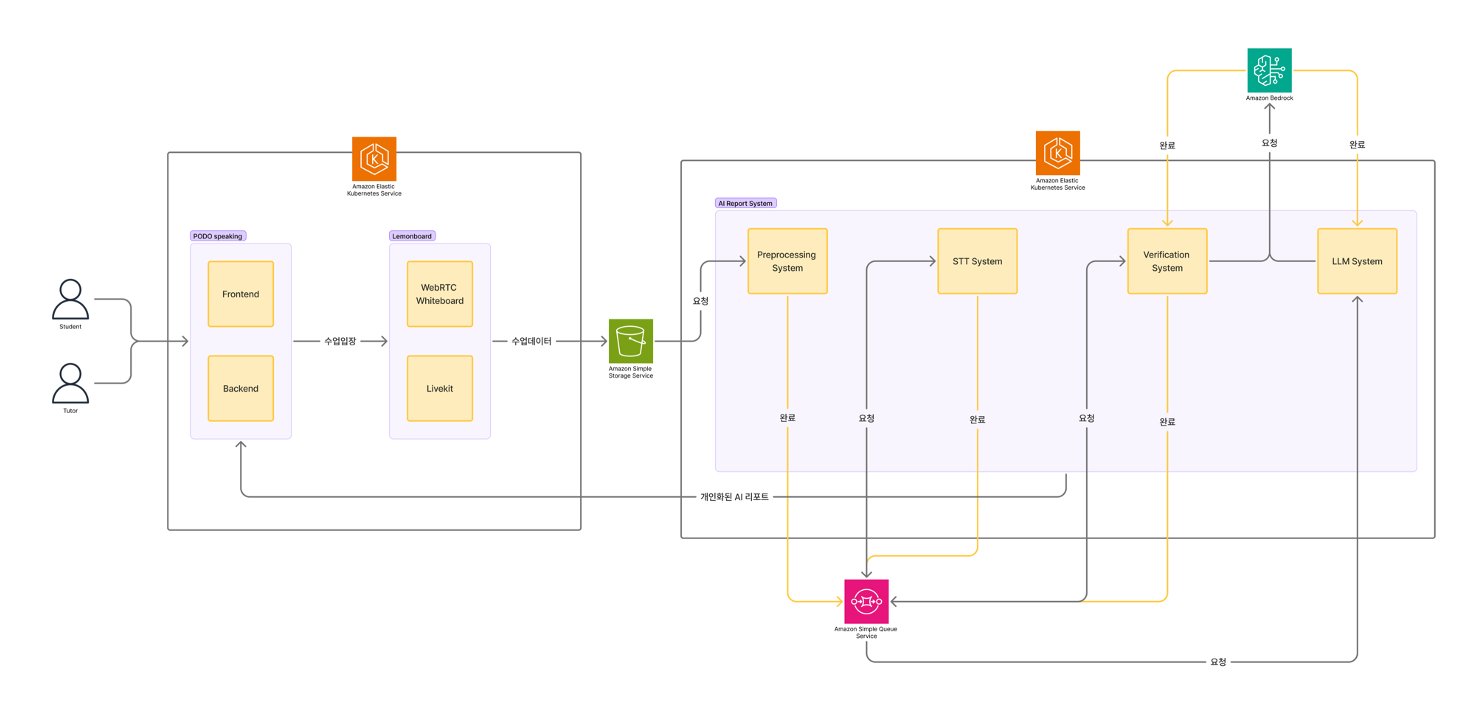
< Figure 1. PODO Speaking 전체 아키텍처 >
위 아키텍처는 다음과 같은 단계로 구성됩니다:
- 1단계: 전처리 (Pre-processing): 포도시스템을 통해 진행된 수업이 종료되면 Amazon S3에 저장된 원본 음성 파일에서 노이즈를 제거하고 파일을 합치는 등 전처리 작업을 진행합니다.
- 2단계: STT (Speech-to-Text): Amazon EKS 클러스터의 GPU Spot 인스턴스 위에서 호스팅되는 Whisper 모델이 음성을 텍스트로 변환합니다.
- 3단계: 데이터 분석 (Data Analysis): Amazon Bedrock이 텍스트 스크립트를 분석하여 문법 오류, 레벨 등 구조화된 데이터를 추출합니다.
- 4단계: 리포트 생성 (Report Generation): Amazon Bedrock이 3단계에서 추출된 데이터를 바탕으로 학생을 위한 최종 피드백 문장을 생성합니다.
수업 진행 및 데이터 수집
학생과 튜터는 포도시스템 내의 ’레몬보드’라는 화이트보드 시스템을 통해 수업을 진행합니다. 이는 커리큘럼을 바탕으로 필기와 음성으로 수업을 진행하는 수업 도구입니다.

< Figure 2. 학생과 튜터의 수업 화면 (레몬보드) >
WebRTC 기반의 화이트보드 시스템을 통해 필기 기능을 구현하였으며, Livekit을 통해 음성 연결 기능을 Amazon EKS에 구현하였습니다. 자체 제작된 커리큘럼 기반 위에 필기와 음성을 통해 수업을 진행하게 되면, 수업 내용이 Amazon S3에 저장됩니다.

< Figure 3. 수업 아키텍처 >
완료된 수업은 필기 데이터와 음성 데이터로 나뉘게 되며, 앞서 설명한 4단계를 통해 개인화된 리포트가 생성됩니다.
AI 분석 파이프라인
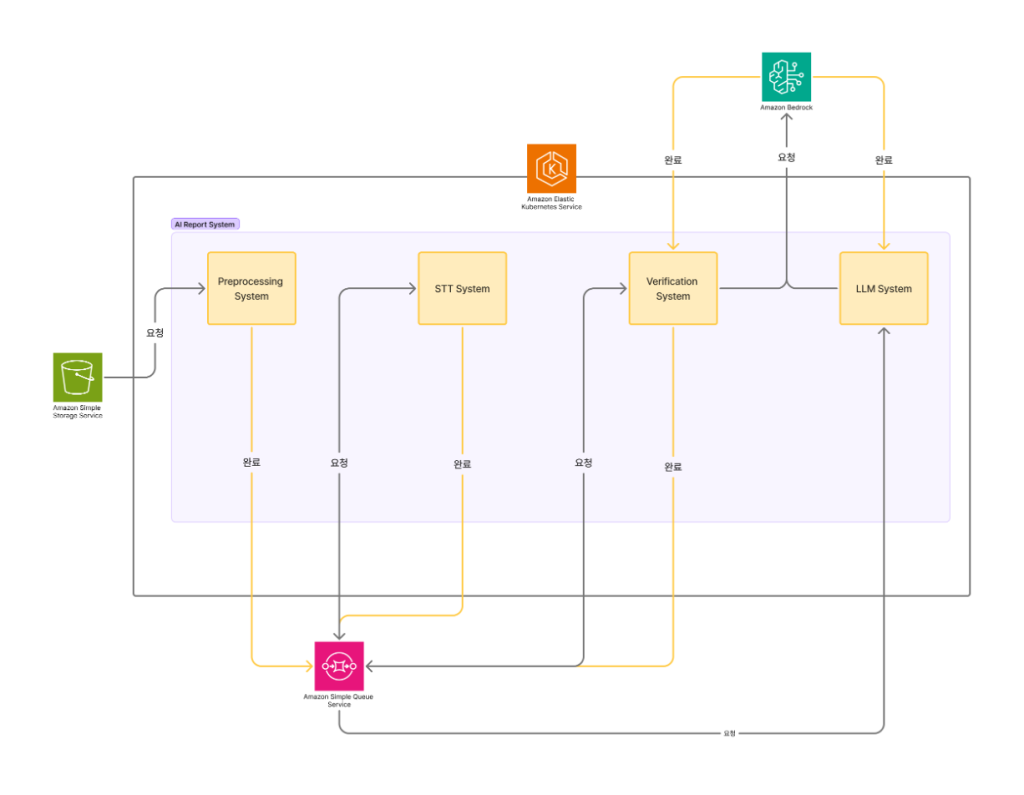
< Figure 4. AI 분석 파이프라인 >
AI 분석 파이프라인은 Amazon SQS(Simple Queue Service)를 통해 각 단계가 비동기적으로 연결되어 있어, 각 단계별로 waiting queue와 pod 의 상태를 체크하며 Horizontal Pod Autoscaling, Karpenter 를 통하여 독립적인 스케일링이 가능합니다. 이를 통해 트래픽 변동에 유연하게 대응하고, 비용 효율적인 운영이 가능합니다.
사용 AWS 서비스 및 핵심 기술 상세
본 파이프라인의 구현 및 안정적인 운영을 위해 다음과 같은 AWS 서비스와 핵심 기술이 적용되었습니다.
Amazon EKS 기반 마이크로서비스 구축 및 운영
Amazon EKS는 AWS에서 Kubernetes를 손쉽게 실행할 수 있도록 하는 관리형 서비스입니다. 본 프로젝트에서는 모든 마이크로서비스(LiveKit, Golang Workers, STT Model Serving)를 운영하는 오케스트레이션 기반으로 활용했습니다. Amazon EKS를 통해 서비스별 독립적인 배포, 확장, 관리가 용이하며, Pod Anti-Affinity 등 Kubernetes의 고가용성 패턴을 적용하여 안정적인 서비스 환경을 구축했습니다.
STT on Amazon EKS GPU (with Spot Instances)
STT 비용 최적화와 핵심 기술 내재화를 위해, Whisper large-v3-turbo 모델을 Amazon EKS 클러스터에 직접 호스팅하는 방식을 선택했습니다. 이 아키텍처를 구축하는 과정에서 핵심 고려 사항은 비용 효율성과 탄력적인 확장성이었습니다.
비용 효율성 극대화
먼저, 비용 효율성을 극대화하기 위해 Amazon EC2 스팟 인스턴스(Spot Instances)를 기반으로 하는 Amazon EC2 G5(g5.xlarge) 인스턴스 노드 그룹을 구성했습니다. STT 워크로드는 GPU 리소스를 집중적으로 사용하므로, GPU 노드에는 Taints를 설정하여 전용으로 사용하도록 격리했으며, Whisper 파드(Pod)에는 해당 Toleration을 부여하여 GPU 리소스가 필요한 워크로드만 스케줄링되도록 구성했습니다.
managedNodeGroups:
- name: nodegroup-gpu
spot: true
taints:
- key: gpu
value: "true"
effect: NoSchedule< 스팟 인스턴스를 사용하는 관리형 노드 그룹의 Taint 설정 예시 >
tolerations:
- key: "gpu"
operator: "Equal"
value: "true"
effect: "NoSchedule"< 스팟 인스턴스를 사용하는 관리형 노드 그룹의 Toleration 설정 예시 >
Agent-based Smart Scaling
또한, 이 과정에서 스팟 인스턴스의 특성과 STT 트래픽의 변동성을 안정적으로 처리하는 것이 가장 큰 기술적 과제였습니다. 단순한 CPU/Memory 기반의 반응형 스케일링(Reactive Scaling)은 작업이 이미 대기열에 쌓인 후에야 동작하므로, 즉각적인 대응이 이뤄지지 않아 요구사항을 충족하지 못하였습니다. 이 문제를 해결하기 위해, ‘Agent-based Smart Scaler’라는 이름의 커스텀 에이전트를 Python으로 직접 개발하여 Amazon EKS Deployment로 배포했습니다.
- 워크로드 직접 감지: 스케일러는 CPU 사용률 대신, 저희 내부 에이전트 서비스의 API를 1분마다 직접 폴링하여 ‘실행 중인 작업’과 ‘대기 중인 작업’의 수를 정확히 파악합니다.
- 선제적 리소스 계산: 실제 작업 부하(Total Load)와 저녁 피크 타임(KST 22시~01시) 같은 시간대별 최적화 로직을 결합하여, 지금 당장 필요한 ‘최적 노드 수’를 선제적으로 계산합니다
- 인프라 및 워크로드 동시 제어: 마지막으로, 스케일러는 계산된 ‘최적 노드 수’를 바탕으로 AWS API(aws eks update-nodegroup-config)와 Kubernetes API(kubectl patch hpa)를 동시에 직접 호출합니다.
-
- AWS API 호출: Amazon EKS 노드 그룹의 desiredSize를 ‘최적 노드 수’로 즉시 업데이트하여 GPU 노드(인프라)를 준비시킵니다.
- Kubernetes API 호출: HPA의 minReplicas 설정을 ‘최적 노드 수’와 동일하게 강제로 업데이트합니다.
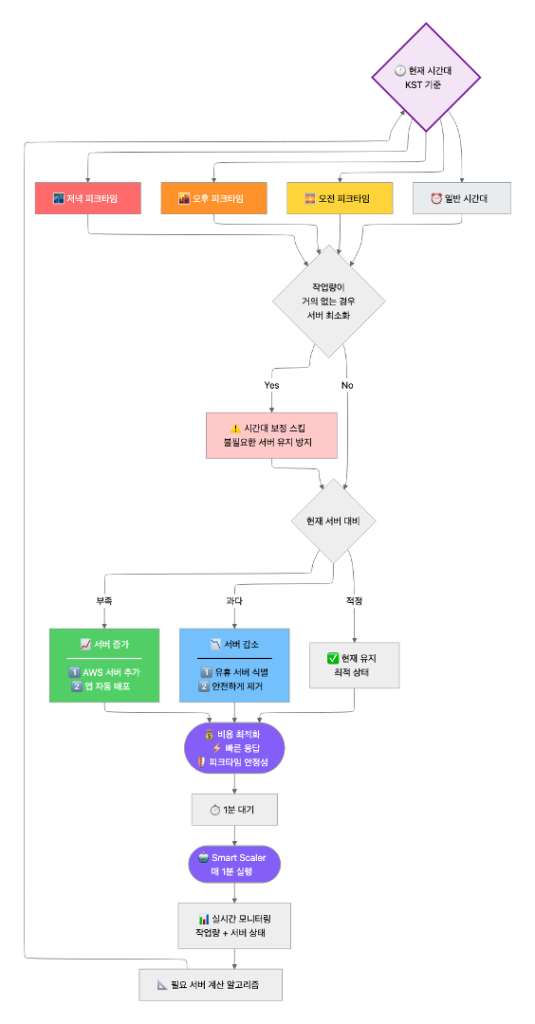
< Figure 5. Smart Scaler 플로우 차트 >
다음은 Smart Scaler의 핵심 로직입니다:
def get_agent_stt_status():
"""STT 대기열 조회"""
try:
response = requests.get(f"{STT 대기열 조회하는 API}", timeout=10)
if response.status_code == 200:
data = response.json()
running = data.get('running', 0)
waiting = data.get('waiting', 0)
total_load = running + waiting
logger.info(f"Agent STT Status - Running: {running}, Waiting: {waiting}, Total: {total_load}")
return total_load, running, waiting
else:
logger.error(f"Failed to get agent STT status: {response.status_code}")
return None, None, None
except Exception as e:
logger.error(f"Error getting agent STT status: {e}")
return None, None, None< Smart Scaler의 STT 대기열 조회 로직 예시 >
def calculate_optimal_nodes(total_load, pod_status=None):
"""실증 공식 기반 최적 노드 수 계산"""
# 파드 안정성 최우선 체크 - Running 파드가 없으면 즉시 최소값 보장
if pod_status and pod_status['running'] < ABSOLUTE_MIN_RUNNING_PODS:
emergency_minimum = MIN_NODES
return emergency_minimum
# 실증 공식을 모든 경우에 일관되게 적용
if total_load == 0:
base_optimal = MIN_NODES
else:
# 실증 공식
base_optimal = NEED_NODE_COUNT_BY_ALGORITHM
# 추가 안정성 체크 - Running 파드가 적으면 보수적으로
if pod_status and pod_status['running'] <= 1:
stability_minimum = MIN_NODES
base_optimal = max(base_optimal, stability_minimum)
# 실제 작업량이 적을 때는 시간대별 제한을 완화
if total_load <= 1:
# 작업량이 매우 적으면 시간대별 제한을 적용하지 않음
elif current_hour == NIGHT_PEEK_TIME
optimal = max(optimal, base_optimal
elif current_hour == AFTERNOON_PEEK_TIME
optimal = max(optimal, base_optimal)
elif current_hour == MORNING_PEEK_TIME
optimal = max(optimal, base_optimal)
return optimal< Smart Scaler의 최적 노드 수 계산 로직 예시 >
이 아키텍처를 통해 외부 API 대비 4배 이상의 비용 절감 효과를 달성했을 뿐만 아니라, 예측 불가능한 트래픽 변화에도 유연하게 대응하고 안정적인 STT 서비스를 제공할 수 있는 강력한 인프라를 내재화하게 되었습니다.
비용 절감 효과:
- 25분짜리 수업에 대한 STT 처리 비용 비교
- 외부 API 사용 시: $0.06
- 자체 STT 사용 시: $0.015
- 절감률: 75% (4배 절감)
Amazon Bedrock (Claude Sonnet 4)
Amazon Bedrock은 다양한 Foundation Model을 API를 통해 사용할 수 있는 완전 관리형 서비스입니다. 본 프로젝트에서는 AI 파이프라인의 핵심 추론 엔진(두뇌) 역할을 수행합니다. Amazon Bedrock을 채택한 이유는 다음과 같습니다.
1. 최적의 모델을 유연하게 선택 가능 (Model Flexibility) : Amazon Bedrock이 제공하는 다양한 Foundation Model을 유연하게 선택하여 테스트가 가능했습니다.
2. 인프라 관리 부담 없는 서버리스 추론 (Serverless Inference) : 복잡한 LLM 서빙 인프라 구축 및 운영 부담 없이, 대규모 추론 요청을 안정적으로 처리했습니다. 덕분에 개발팀은 인프라 관리가 아닌, 프롬프트 엔지니어링 및 핵심 비즈니스 로직 개발에만 집중할 수 있었습니다.
두 가지 모드로 나눈 AI 활용
본 프로젝트에서는 Amazon Bedrock 서비스에서 제공하는 Foundation Model 중 강력한 Claude Sonnet 4 모델을 사용하였으며, 두 가지 모드로 나누어 활용했습니다.
분석 모드 (3단계)
모델의 창의성을 제어하고, 엄격한 JSON 스키마로만 응답하도록 강제합니다. 이를 통해 ‘문법 오류’, ‘핵심 어휘’ 등 객관적인 데이터만을 정밀하게 추출합니다.
< 분석 모드를 위한 시스템 프롬프트 예시 >
생성 모드 (4단계)
’분석 모드’에서 추출된 JSON 데이터 조각들을 입력값으로 받아, 모델의 정교한 작문 능력과 공감 능력을 활용해 학생의 눈높이에 맞는 ’자연스럽고 격려가 담긴 피드백’으로 재창조합니다.
< 생성 모드를 위한 시스템 프롬프트 예시 >
< Figure 6. Amazon Bedrock 분석 모드 결과물 예시 | Figure 7. Amazon Bedrock 생성 모드 결과물 예시 >
이러한 이중 모드 접근 방식을 통해 생성형 AI의 환각 현상(Hallucination)을 최소화하고, 일관된 품질의 피드백을 제공할 수 있었습니다.
결과 및 성과
본 시스템 구축을 통해 기술, 교육, 그리고 비즈니스 측면에서 다음과 같은 가시적인 성과를 달성했습니다.
기술적 성과 (Technical Achievements)
- 비용 절감 : 자체 STT 엔진 구축 및 Amazon EC2 스팟 인스턴스 활용으로 STT 비용 4배 절감을 달성했습니다.
- 안정성 및 확장성 확보 : Amazon EKS와 Amazon SQS 기반의 비동기 파이프라인 설계를 통해 대규모 트래픽에도 유연하게 대응 가능한 확장형 아키텍처를 구축했습니다.
- AI 신뢰도 향상 : ‘단계 분리 원칙’과 ’프롬프트 단일 책임 원칙’ 적용으로 AI의 환각 및 작업 누락률을 획기적으로 감소시켰습니다.
유저 및 비즈니스 성과 (User & Business Impact)
유저 피드백은 매우 긍정적이었습니다. 실제 유저 설문조사 결과, 79.3%의 유저가 AI 리포트의 피드백이 학습에 도움이 되었다고 응답했습니다.
가장 고무적인 성과는, 89.7%의 유저가 “AI 리포트가 있다면 포도스피킹 수업을 더 오래 유지할 가능성이 높아진다”고 응답한 점입니다. 이는 기술적 노력이 단순히 새로운 기능을 추가하는 것을 넘어, 고객 만족도와 서비스 리텐션(Retention)이라는 핵심 비즈니스 지표에 직접적으로 기여하고 있음을 증명합니다.
향후 계획
데이원컴퍼니는 현재의 성과에 머무르지 않고, AI 기술을 활용하여 교육 경험을 한 단계 더 발전시키고자 합니다. 다음 목표는 AI 리포트를 통해 축적된 데이터를 바탕으로, 학생별 관심사와 수준에 맞는 ‘AI 기반 개인화 커리큘럼’을 자동 생성하는 것입니다.
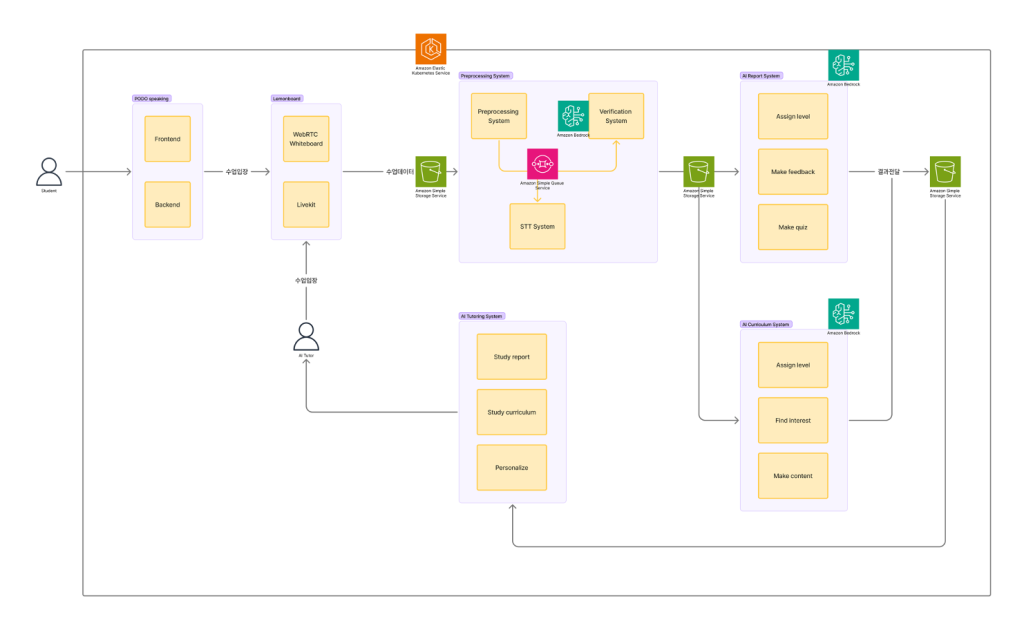
< Figure 8. 목표 아키텍처 – 생성형 AI 기반 개인형 맞춤 수업 생태계 >
궁극적인 목표는 이러한 AI 기반 서비스들을 유기적으로 연결하여, 학습의 준비-학습-분석-개선의 전 과정을 AI가 지원하는 통합 AI 교육 생태계를 구축하는 것입니다.
마무리
본 글에서는 데이원컴퍼니가 Amazon EKS와 Amazon Bedrock을 활용하여 1:1 음성 대화 AI 분석 시스템을 구축하고, 교육 리포트를 개인화한 사례를 소개했습니다.
핵심 성과는 다음과 같습니다:
- 비용 효율성: Amazon EC2 스팟 인스턴스 활용으로 STT 비용 75% 절감
- 운영 효율성: 튜터의 리포트 작성 시간 완전 제거
- 사용자 만족도: 79.3%의 유저가 AI 리포트가 학습에 도움이 된다고 응답
- 비즈니스 성과: 89.7%의 유저가 AI 리포트로 인해 서비스 유지 가능성이 높아진다고 응답
이러한 성과는 AWS 클라우드 기술과 생성형 AI를 결합한 혁신적인 접근, 그리고 AWS Support 및 Account 팀과의 긴밀한 협력을 통해 달성할 수 있었습니다.
교육산업에서 직면하는 데이터 휘발성, 피드백 불일치, 운영 비효율 문제는 많은 기업들이 공통적으로 겪고 있는 과제입니다. 본 사례가 유사한 문제를 해결하고자 하는 다른 교육 기업들에게 실질적인 인사이트를 제공하기를 바랍니다.
AWS 위에서 펼쳐질 데이원컴퍼니의 다음 기술적 도전에 많은 관심 부탁드립니다.