AWS 기술 블로그
AWS advanced JDBC wrapper 플러그인 이해하기
이 글은 AWS Database Blog에 게시된 Demystifying the AWS advanced JDBC wrapper plugins by Will Leach, Nirupam Datta, and Ryan Moore을 한국어 번역 및 편집하였습니다.
2023년에 AWS는 AWS advanced JDBC wrapper를 출시해하여 기존 JDBC 드라이버의 성능을 향상 시키고 추가 기능을 추가했습니다. 이 래퍼는 기존 사용자가 선택한 PostgreSQL, MySQL 또는 MariaDB JDBC 드라이버 위에 AWS와 Amazon Aurora 기능을 지원할 수 있게 해줍니다. 이 래퍼는 Aurora 연결 추적 플러그인, 무제한 연결 플러그인, 읽기-쓰기 분할 플러그인을 포함한 다양한 플러그인을 지원합니다. 이러한 플러그인을 사용하면 애플리케이션과 원활하게 통합되도록 AWS Advanced JDBC Wrapper를 사용자 정의할 수 있으며, 장애 조치 관리, 모니터링, 인증, 부하 분산 등의 향상된 기능을 제공합니다. AWS Advanced JDBC Wrapper가 지원하는 플러그인의 전체 목록은 공식 GitHub repository에서 확인할 수 있습니다.
이전 게시물에서 Aurora용 Advanced JDBC Wrapper Driver를 소개하고, Amazon RDS 다중 AZ DB 클러스터를 업그레이드시 Advanced JDBC Wrapper Driver를 사용하여 다운타임을 1초 이하로 줄이는 방법을 알아보고, Amazon Aurora를 위한 Advanced Python Wrapper Driver를 소개했습니다. AWS는 Python 외에도 Node.js, Go, PostgreSQL과 MySQL용 ODBC 드라이버 등 다른 인기 프로그래밍 언어와 프로토콜을 위한 유사한 래퍼 드라이버들도 개발했습니다.
이 포스트에서는 두 가지 인기 있는 AWS Advanced JDBC Wrapper Driver 플러그인인 Aurora 초기 연결 전략(Aurora Initial Connection Strategy)와 Failover v2 플러그인의 이점, 사용 사례 및 구현 세부 사항에 대해 설명합니다. AWS Advanced JDBC Wrapper GitHub repository에는 래퍼와 플러그인에 대한 방대한 양의 정보가 포함되어 있지만, 이 게시물에서는 개별 플러그인을 더 자세히 살펴며 이를 통해 해당 플러그인이 사용 사례에 도움이 될 수 있는지 판단하고 구현에 도움이 되는지 확인합니다.
오로라 초기 연결 전략(Aurora Initial Connection Strategy) 플러그인
Aurora 초기 연결 전략 플러그인(Aurora Initial Connection Strategy Plugin)은 애플리케이션이 Aurora 클러스터의 읽기 전용 엔드포인트에 처음 연결되는 방법을 제어합니다. readerInitialConnectionHostSelectorStrategy 파라미터를 사용하여 다양한 연결 전략을 선택 할 수 있습니다.
- Random — 임의의 Reader 인스턴스에 연결을 설정합니다.
- roundRobin — 라운드 로빈 방법으로 Reader 인스턴스에 연결을 설정합니다.
- leastConnections — 연결이 가장 적은 인스턴스에 연결을 설정합니다.
- FastTestResponse — 응답 시간이 가장 빠른 인스턴스에 연결을 설정합니다.
스마트 드라이버를 사용하는 동안에는 DNS가 캐시되지 않도록 주의해야 합니다. 캐싱은 Aurora 초기 연결 전략 플러그인에서 표시되는 결과에 영향을 미칠수 있습니다. 연결 처리 및 관리에 관한 모범 사례는 Amazon Aurora MySQL Database Administrator’s Handbook을 참조하십시오.
이 플러그인을 구성하려면 Java 코드 내에서 속성을 설정할 수 있습니다. 다음 예시에서는 데이터베이스의 사용자와 암호를 설정하고, 플러그인 (initialConnection) 을 지정하고, 초기 연결 전략 값을 random으로 설정합니다.
try { Properties props = new Properties(); PropertyDefinition.USER.set(props, USERNAME); PropertyDefinition.PASSWORD.set(props, PASSWORD); PropertyDefinition.PLUGINS.set(props, "initialConnection"); AuroraInitialConnectionStrategyPlugin.READER_HOST_SELECTOR_STRATEGY.set(props, “random”);}
세 개의 읽기 전용 복제본(Reader)이 있는 Amazon Aurora MySQL-Compatible Edition 클러스터를 사용하여 플러그인의 동작을 확인해 보겠습니다. 클러스터의 읽기 전용 엔드포인트를 사용하여 이 클러스터에 100개의 연결을 엽니다. 이 연결은 테스트 기간 동안 계속 SQL 쿼리를 수행하며, 전체 프로세스 동안 열린 상태를 유지합니다.
Random 초기 연결 전략
다음 그래프는 ReaderInitialConnectionHostSelectorStrategy 파라미터에 Random 초기 연결 전략을 사용할 때 100개 연결 분배를 보여줍니다. Random 초기 연결 전략이 이 플러그인의 기본 선택 전략입니다.
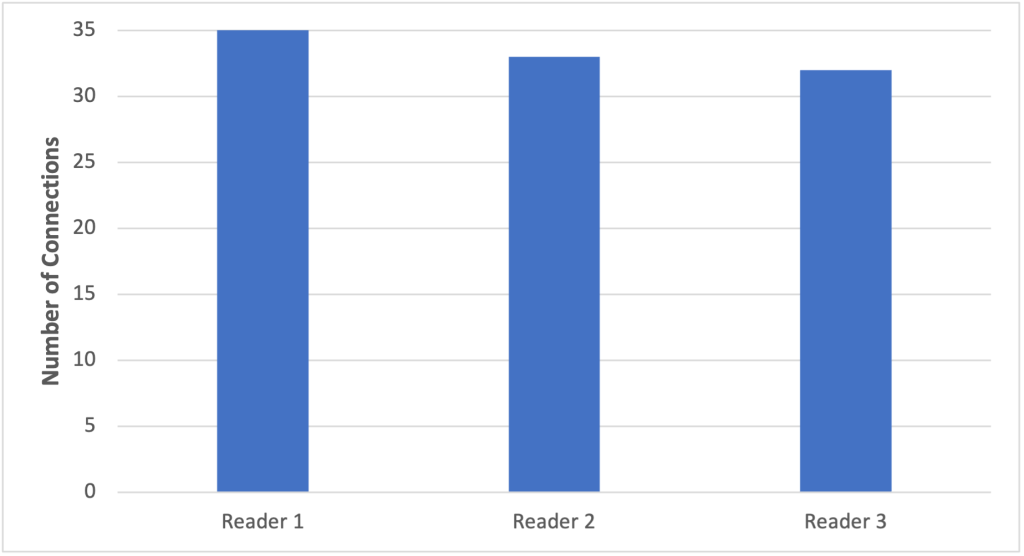 그림 1. “Random” 초기 연결 전략을 활용할 때 연결 분배를 표시하는 그래프
그림 1. “Random” 초기 연결 전략을 활용할 때 연결 분배를 표시하는 그래프
그림 1에서 볼 수 있듯이, 세 Reader 사이의 연결 분배는 공평합니다. 이 선택 전략을 사용하면 각 읽기 전용 복제본이 새로 열린 연결을 받을 동등한 기회를 얻습니다. 그래프에서 35% 의 연결이 Reader 1에 설정되었고, 33% 가 Reader 2에, 32% 의 연결이 Reader 3에 설정되었습니다.
Round robin 초기 연결 전략
다음 그래프는 roundRobin 초기 연결 호스트 선택 전략에 대한 테스트를 보여줍니다. 앞서 언급했듯이, 이 전략은 사용 가능한 DB 인스턴스를 한 주기로 번갈아 가며 Reader 인스턴스를 선택합니다. 하지만 roundRobinHostWeightPairs 파라미터를 사용하여 Reader 인스턴스에 가중치를 부여할 수 있습니다. 이는 하나의 연결 주기에서 특정 호스트에 대한 연결의 상대적 분배 비율를 설정할 수 있다는 의미입니다. 자세한 내용은 Reader 선택 전략을 참조하세요. 이 예에서는 각 호스트에 기본 가중치를 적용하여 거의 균일한 분배를 얻을 수 있습니다.

그림 2. 8분 동안 100개의 연결이 설정된 “roundRobin” 초기 연결 전략을 활용할 때 연결 분배를 표시하는 그래프
그림 2를 보면 세 Reader 사이의 연결 분배가 예상과 거의 일치하지만 완전히 일치하지는 않는 다는것을 알수 있습니다. Reader 간에 33/33/34로 나뉘는 대신 35/34/31을 나뉘었습니다. 왜 이런 일이 발생했는지 이해하려면 AWS Advanced JDBC wrapper 에서 기본적으로 활성화되는 Failover v2 플러그인이라는 또 다른 플러그인에 대해 살펴봐야 합니다.
기본적으로 Failover v2 플러그인을 사용할 때 clusterTopologyRefreshRateMs는 30,000밀리초 (30초) 입니다. 클러스터 토폴로지가 새로 고쳐지면 진행 중인 roundRobin 주기가 중단되고 새로 고친 토폴로지를 사용하여 다시 시작해야 합니다. 위 예시에서는 5초마다 연결이 1개씩 생성했는데, 이는 100개의 연결을 설정하는 데 8분 이상 걸렸다는 것을 의미합니다. 이 시간 동안 토폴로지 갱신이 최소 16번 발생했으며, 이는 현재 roundRobin 주기에 영향을 미쳤을 수 있습니다.
다음 그래프에서는 데이터베이스에 대한 100개의 연결을 1초 미만으로 생성하여, 클러스터 토폴로지 새로고침을 피하고 이전에 예상했던 거의 균등한 분배를 보여줍니다.
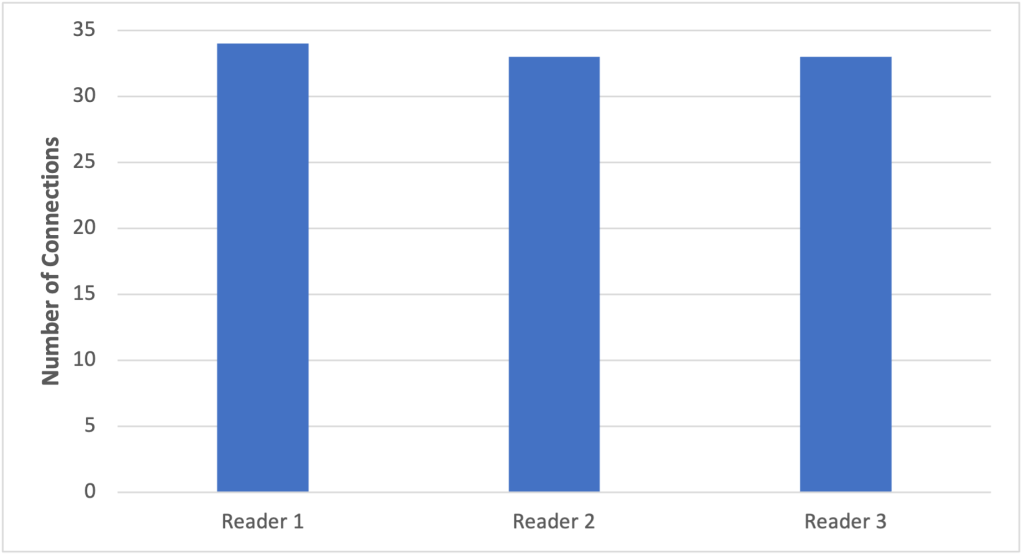 그림 3. 1초 동안 100개의 연결이 설정된 “roundRobin” 초기 연결 전략을 활용할 때 연결 분포를 표시하는 그래프
그림 3. 1초 동안 100개의 연결이 설정된 “roundRobin” 초기 연결 전략을 활용할 때 연결 분포를 표시하는 그래프
최소 연결(Least connections) 초기 연결 전략
다음으로, readerInitialConnectionHostSelectorStrategy 파라미터를 최소 연결로 구성해 보겠습니다. leastConnections 전략은 애플리케이션의 내부 연결 풀 (예: HikarICP 또는 C3P0) 내 활성 연결 수를 기반으로 연결할 Reader 인스턴스를 선택합니다. leastConnections 전략 사용 시 중요 고려 사항:
- 이 전략을 사용하려면 애플리케이션에 내부 연결 풀이 이미 구성되어 있어야 합니다.
- 플러그인은 자체 연결 풀 인스턴스의 연결만 추적합니다.
- 동일한 Aurora 클러스터에 여러 애플리케이션이나 연결 풀이 연결되어 있는 경우, 각 풀은 자체 연결만 볼 수 있으므로,
leastConnections전략은 최적의 부하 분산을 제공하지 못할 수 있습니다. - 내부 연결 풀을 구성하지 않고 연결 속성을 leastConnections로 설정하면 다음과 유사한 예외가 발생합니다.
java.lang.UnsupportedOperationException: Unsupported host selection strategy 'leastConnections'.leastConnections 구성으로 테스트하는 동안 1초 걸쳐 100개의 연결이 생성되었습니다. 이로 인해 Reader 노드 사이에 연결이 거의 균등하게 분배되었으며, 분배의 33% 가 Reader 2와 3에게 가고 Reader 1이 34% 를 할당 받았습니다. 분배가 거의 균등한 이유는 테스트 기간 동안 트랜잭션을 실행하여 데이터베이스 연결을 활성 상태로 유지했기 때문입니다. 이는 AWS Advanced JDBC Wrapper의 초기 연결 전략 플러그인이 내부 연결 풀 내에서 활성 연결 수가 가장 적은 Reader 인스턴스를 적절하게 판단할 수 있었다는 것을 의미합니다. 이는 leastConnectionsHostSelector.getHost()함수를 통해 수행되며, 연결 풀에서 활성 연결이 가장 낮은 인스턴스로 새로 생성된 연결을 라우팅할 수 있습니다.
다음 다이어그램은 leastConnections 전략이 어떤 Reader 인스턴스와 연결을 형성할지 결정하는 방법을 보여줍니다.
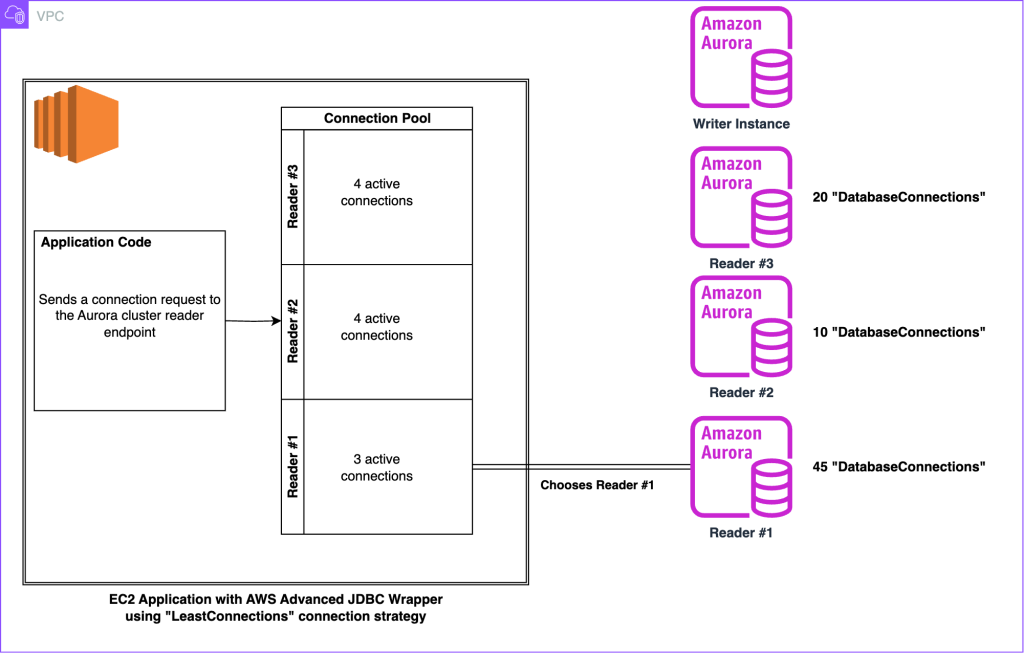 그림 4. “leastConnections” 초기 연결 전략을 활용할 때 연결이 어떻게 분산되는지 시각화하는 다이어그램
그림 4. “leastConnections” 초기 연결 전략을 활용할 때 연결이 어떻게 분산되는지 시각화하는 다이어그램
위 그림에서 Reader 2의 데이터베이스 연결은 총 10개로, 클러스터 내에서 가장 적습니다. 하지만 어플리케이션은 총 연결 수가 가장 많은 Reader #1 과의 연결을 생성하기로 결정합니다. 그 이유는 내부 연결 풀이 Aurora 클러스터와 형성한 연결만 추적하기 때문입니다. 내부 연결 풀에 대한 정보에 따르면, Reader 1은 실제로 연결이 3개로 가장 적은 열결 수를 가지고 있습니다. Aurora 클러스터에 연결된 애플리케이션이나 클라이언트가 여러 개 있을 때 이 동작을 염두에 두는 것이 중요 합니다.
가장 빠른 응답(Fastest response) 초기 연결 전략
fastestResponse 연결 전략은 가장 빠르게 응답하는 호스트에 연결합니다. 클러스터 내 Reader 인스턴스 중에서 가장 빠른 응답을 식별 한후, 이를 캐시에 저장하여 추후 사용합니다. 이 플러그인을 사용하려면 다음 Java 코드와 같이 fastestResponseStrategy 플러그인을 로드해야 합니다.
props.setProperty(PropertyDefinition.PLUGINS.name, "initialConnection,fastestResponseStrategy");연결 분배는 Reader 인스턴스의 가용 영역, 리소스 경합, 가용성 등을 포함하되 이에 국한되지 않는 여러 요인에 따라 달라집니다. 애플리케이션에서 지연 시간이 주요 관심사라면, 연결 생성 시 잠재적 지연 시간을 최소화 하기위해 fastestResponse 연결 전략을 사용하는 것이 좋습니다. 또한 연결 풀을 구현하면 기존 연결을 재사용할 수 있어 새 연결 설정과 관련된 지연 시간을 줄일 수 있습니다.
Failover v2 플러그인
Failover v2 플러그인은 기존 Failover 플러그인의 향상된 버전으로, 여러 가지 개선 사항을 제공합니다. 이 플러그인은 Aurora 클러스터 토폴로지에 대한 래퍼의 정보를 활용하여 기본 DB 인스턴스를 사용할 수 없게 되는 장애 조치 이벤트 동안 다운타임을 최소화합니다. 기존 데이터베이스 연결의 재연결 시간을 줄여서 이를 달성합니다. 다음을 포함한 다양한 설정을 구성할 수 있습니다.
- 장애 발생 시 래퍼가 재연결을 시도하는 특정 DB 인스턴스의 우선 순위
- 타임 아웃 값
failoverReaderHostSelectorStrategy파라미터는 위의 오로라 초기 연결 전략 섹션에서 설명한 것과 동일한 Reader 선택 전략 을 사용합니다.
기존 Failover 플러그인의 정보와 제안 사항 대부분은 Failover v2 플러그인에 적용되만, 세 가지 중요한 차이점이 있습니다.
각 연결은 자체 조치 프로세스를 수행합니다
각 연결은 동일한 스레드에서 RdsHostListProvider 모니터링 구성 요소를 호출하여 토폴로지를 가져옵니다.
Reader 노드가 토폴로지를 가져올 때, 장애 조치 후 짧은 시간 동안 오래된(stale) 상태일 수 있습니다.
DB 인스턴스 장애 발생시 Aurora는 클러스터에서 장애 조치를 시작하여 복구를 위해 새로운 기본 DB 인스턴스를 승격합니다. 이 과정에서 JDBC 드라이버는 관련 통신 예외를 감지하고 각 연결에 대해 자체 장애조치 프로세스를 수행합니다. 기존 버전의 플러그인에서는 각 장애 조치 프로세스가 독립적으로 처리되었습니다. 이 방법은 다른 연결 상태에 의존하지 않는 장점이 있지만, 동시에 많은 양의 장애조치 프로세스가 발생하는 경우 클라이언트 측에 상당한 부하를 일으킬 수 있습니다. 이 방법은 그림 5에 시각화되어 있습니다.
 그림 5. 각 연결이 새로운 Writer를 감지하기 위해 자체 독립적인 장애 조치 프로세스를 트리거하는 방식을 시각화하는 다이어그램
그림 5. 각 연결이 새로운 Writer를 감지하기 위해 자체 독립적인 장애 조치 프로세스를 트리거하는 방식을 시각화하는 다이어그램
Failover v2 플러그인은 최적화된 방법을 구현합니다. 이 방식에서는 Aurora 클러스터 토폴로지를 감지하고 확인하는 프로세스가 별도의 스레드에서 실행되는 중앙 토폴로지 모니터링 구성요소인 MonitorRdsHostListProvider에 의해 처리됩니다. 토폴로지를 확인하고 새 Writer가 확인되면 토폴로지에서 대기 중인 각 연결이 재개되어 필요한 DB 인스턴스에 다시 연결할 수 있습니다. 이 접근 방법은 필요한 자원을 최소화하고 연결 수가 많을 때 기존 Failover 플러그인보다 훨씬 더 잘 확장됩니다. 또한 MonitorRdsHostListProvider 구성 요소는 Writer DB 인스턴스에서 최신 토폴로지를 가져오는 반면, 기존 Failover 플러그인은 오래된 Reader DB 인스턴스에서 토폴로지를 가져올 수 있습니다. 그림 6은 이 과정을 보여줍니다.
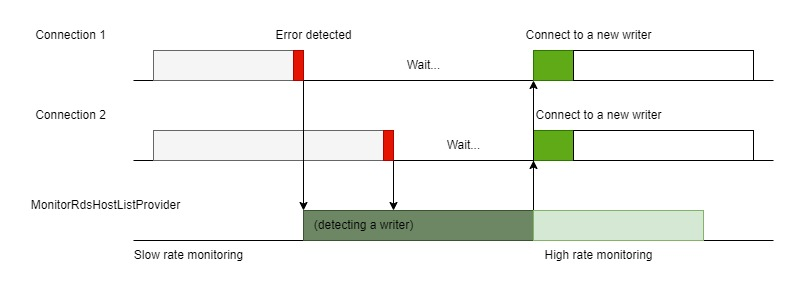 그림 6. MonitorRDSHostListProvider가 장애 조치를 간소화하는 방식을 시각화하는 다이어그램
그림 6. MonitorRDSHostListProvider가 장애 조치를 간소화하는 방식을 시각화하는 다이어그램
DB 인스턴스 장애 발생 시 이 플러그인이 기존 연결의 다운타임을 최소화하는 방법을 보여주기 위해 세 개의 Reader가 있는 Aurora MySQL 클러스터에 대한 테스트를 수행합니다. sysbench 툴을 사용하여 클러스터의 Writer 엔드포인트에 대한 쓰기 및 읽기 워크로드를 동시에 시뮬레이션합니다. 이 워크로드는 새 테이블이 생성하고 100,000개의 새 행을 반복해서 삽입합니다. 부하가 발생하는 동안, 여러 UPDATE 쿼리가 포함된 쓰기 트랜잭션과 연결된 호스트로부터 데이터를 읽어오는 SELECT 쿼리를 반복적으로 실행합니다. 이 워크로드가 실행 중일 때, Writer 인스턴스 클래스의 스케일업을 수행합니다. 이는 Aurora 클러스터 내에서 장애 조치를 시작하고 AWS Advanced JDBC Wrapper가 재연결하도록 강제합니다. 다음 그래프는 같은 워크로드에 대한 여러 테스트의 재접속 시간을 보여줍니다. 한 테스트는 Failover v2 플러그인이 활성화된 상태로 AWS Advanced JDBC Wrapper를 활용하고, 다른 테스트에서는 AWS Advanced JDBC Wrapper를 계속 사용하면서 플러그인을 비활성화합니다.

그림 7. Failover v2 플러그인 사용 여부에 따른 재연결 소요 시간(초)을 10회 테스트한 결과를 시각화한 그래프
Failover v2 플러그인을 활성화한 상태에서 클라이언트는 전체 테스트에서 평균 재연결 시간이 7.8초인 반면, Failover v2 플러그인을 사용하지 않은 테스트는 평균 15초가 소요되었습니다. 결과는 Failover v2 플러그인이 AWS Advanced JDBC Wrapper만 단독으로 사용할 때보다 일관되게 더 빠른 재연결 시간을 달성함을 보여줍니다. 또한 클러스터 토폴로지를 능동적으로 쿼리하는 메커니즘 덕분에 더 일관된 성능을 제공합니다. Failover v2 플러그인은 Aurora 클러스터 장애조치 중 다운타임을 최소화고 연결에 대해 특정 DB 인스턴스의 우선 순위를 지정하는 옵션을 제공합니다. failoverMode, failoverReaderHostSelectorStrategy 및 기타 타임아웃 관련 파라미터들의 값은 애플리케이션 요구 사항과 Aurora 클러스터 아키텍처에 따라 결정됩니다.
결론
이 게시물에서는 Aurora Initial Connection 플러그인과 Failover v2 플러그인이 AWS Advanced JDBC Wrapper에서 어떻게 작동하는지 자세히 살펴보았습니다. 이 플러그인들은 Aurora 장애조치 및 연결 설정을 위한 고급 관리 기능을 제공합니다. 이러한 플러그인의 내부 작동 방식을 이해하면 Aurora 환경을 더욱 효과적으로 구성할 수 있습니다.