AWS 기술 블로그
GS리테일의 AIOps Agent 기반 운영 자동화 혁신
개요
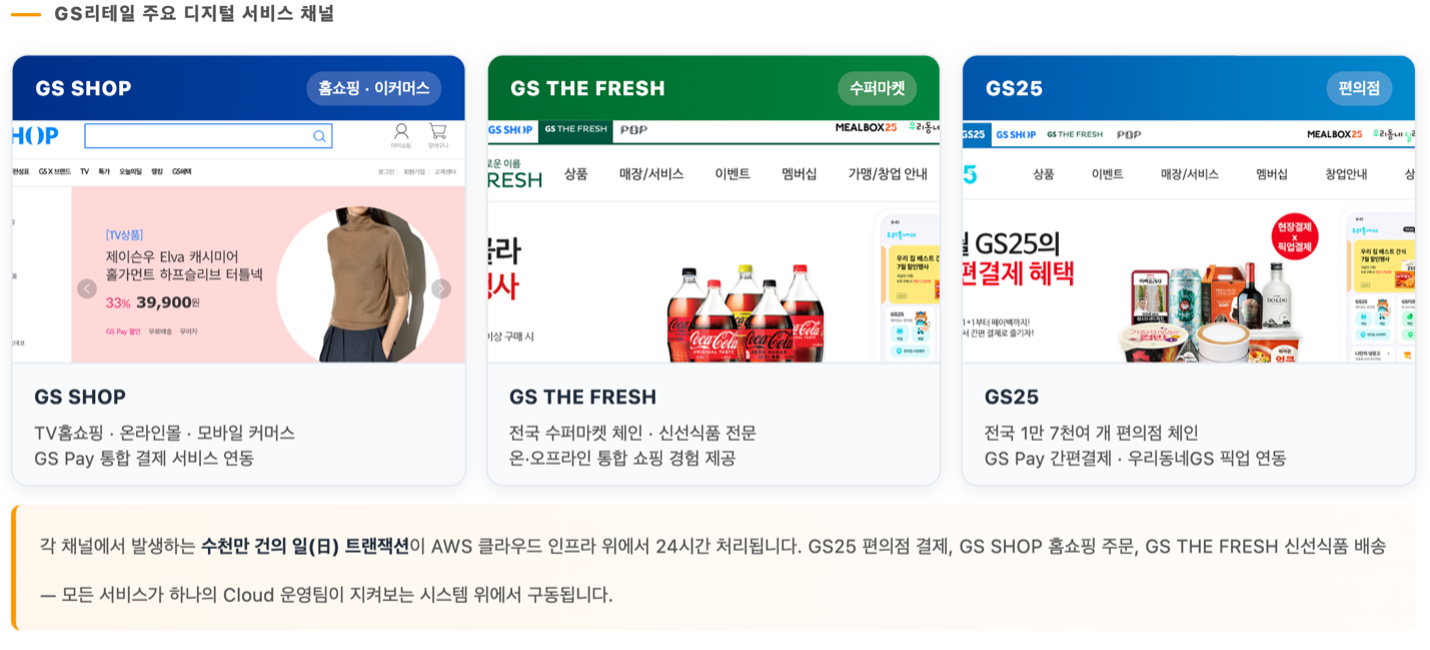
GS리테일은 전국 18,000여 개의 편의점 GS25와 슈퍼마켓 GS THE FRESH, O4O 플랫폼 우리동네GS, 홈쇼핑 GS SHOP 등 온·오프라인을 아우르는 대한민국 대표 유통기업입니다. 매일 수천만 명의 고객이 이용하는 이 서비스들이 끊김 없이 운영되는 데에는 GS리테일 클라우드인프라팀의 24/7 모니터링이 뒷받침되고 있습니다.
 GS리테일의 클라우드 인프라는 사업 부문별로 독립된 Datadog 환경과 다수의 모니터링 도구들을 통해 각각 모니터링되고 있습니다. 운영자들은 인시던트가 발생할 때마다 메트릭과 로그, Bitbucket 코드 변경 이력, Confluence 운영 문서, AWS 인프라 상태, Amazon EKS 클러스터 상태, DB 쿼리 확인까지 평균 5~6개의 도구를 직접 오가며 원인을 추적합니다.
GS리테일의 클라우드 인프라는 사업 부문별로 독립된 Datadog 환경과 다수의 모니터링 도구들을 통해 각각 모니터링되고 있습니다. 운영자들은 인시던트가 발생할 때마다 메트릭과 로그, Bitbucket 코드 변경 이력, Confluence 운영 문서, AWS 인프라 상태, Amazon EKS 클러스터 상태, DB 쿼리 확인까지 평균 5~6개의 도구를 직접 오가며 원인을 추적합니다.
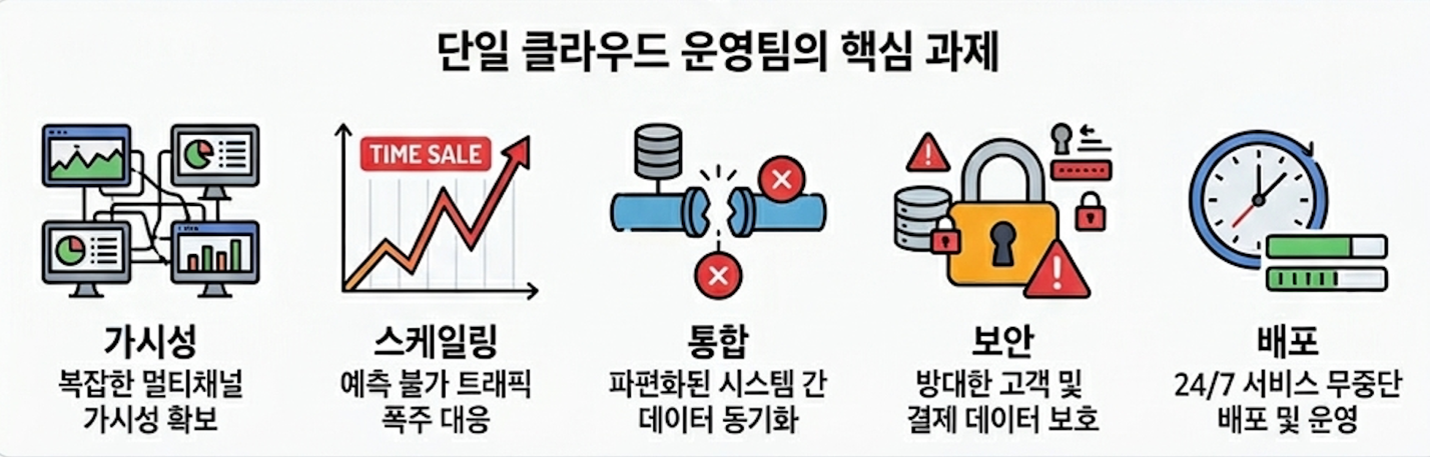
숙련된 운영자는 경험과 직관으로 도구 간 상관관계를 빠르게 파악하고, 때로는 과거 유사 장애의 기억을 바탕으로 근본 원인을 짚어낼 수 있지만 이 과정은 평균 30분 이상 소요되며, 야간이나 주말에는 초기 대응이 지연되어 장애가 확산되는 위험도 존재합니다. 무엇보다 숙련된 운영자의 분석 노하우가 체계적으로 축적되지 않아, 담당자에 따라 분석 품질에 편차가 발생하는 것이 현실적인 과제였습니다.
이러한 문제를 해결하기 위해, GS리테일 클라우드인프라팀은 숙련된 SRE 전문가의 사고방식 자체를 AI에 주입하여 인시던트를 자율적으로 분석하는 AIOps Agent 시스템을 구축하기로 했습니다.
이 글에서는 Amazon Bedrock과 Model Context Protocol(MCP)을 활용하여 7개 이상의 도구를 AI가 스스로 선택·조합하며 근본 원인을 추적하고, 인시던트 분석 시간을 평균 30분에서 약 2분으로 93% 단축한 사례를 소개합니다.
운영 복잡성과 과제
멀티 조직 모니터링의 어려움
GS리테일은 GS25, GS THE FRESH, 우리동네GS, GS SHOP 등 사업 부문별로 독립된 Datadog 환경을 운영하고 있습니다. 각 사업 부문은 서로 다른 인프라 환경과 서비스 특성을 갖고 있어, 모니터링 구성과 알림 체계 역시 독립적으로 관리됩니다. 클라우드인프라팀은 이처럼 서로 다른 컨텍스트를 가진 다수의 조직에서 발생하는 인시던트를 통합 관리하고, 조직마다 다른 메트릭 구조와 알림 기준을 이해한 상태에서 원인을 분석해야 했습니다.
수동 분석의 한계
- 도구 분산: Datadog 메트릭/로그/트레이스, Bitbucket 커밋 이력, Confluence 운영 문서, AWS 인프라 상태, EKS 클러스터 상태, DB 쿼리 분석 등을 각각 별도로 확인
- 컨텍스트 전환 비용: 평균 5~6개 도구를 오가며 분석, 도구 간 상관관계 파악에 추가 시간 소요
- 야간/주말 대응: 24/7 모니터링 인력 확보의 어려움, 초기 대응 지연으로 장애 확산 위험
- 지식 단절: 숙련된 운영자의 노하우가 체계적으로 축적되지 않아 신규 인력의 분석 품질 편차 발생
운영에 AIOps 도입의 필요성 (AIOps Agent)
결국 클라우드인프라팀이 직면한 핵심 과제는 명확했습니다. 1/흩어진 도구의 정보를 하나로 연결하고, 2/숙련된 운영자의 분석 패턴을 누구나 동일하게 재현할 수 있어야 하며, 3/사람이 자리를 비운 시간에도 즉각적인 초기 대응이 가능해야 한다는 것입니다. 이 세 가지 과제는 단순한 스크립트 자동화나 룰 기반 알림으로는 해결하기 어렵습니다. 인시던트마다 원인이 다르고, 확인해야 할 도구의 조합도 매번 달라지기 때문입니다.
따라서 클라우드인프라팀에게 필요한 것은 상황을 스스로 판단하고, 적절한 도구를 선택하며, 근본 원인을 끝까지 추적하는 AI Agent 즉, 숙련된 SRE의 사고방식을 재현할 수 있는 지능형 시스템이었습니다.
솔루션 설계기준
클라우드인프라팀은 이러한 과제를 해결하기 위해, AI가 운영자처럼 여러 도구를 자율적으로 탐색하고 근본 원인을 추적하는 에이전트 기반 시스템을 설계했습니다. 기술 선택의 핵심 기준은 세 가지였습니다.
첫째, AI 모델의 도구 활용 능력입니다. 인시던트 분석은 단순 텍스트 생성이 아니라, 상황에 맞는 도구를 선택하고 결과를 해석한 뒤 다음 행동을 판단하는 과정입니다. Amazon Bedrock의 Converse API는 모델이 외부 도구를 직접 호출하고 그 결과를 바탕으로 추론을 이어가는 에이전트 루프를 네이티브로 지원하여, 이 요구에 가장 적합했습니다.
둘째, 비용과 분석 품질의 균형입니다. 반복적인 도구 호출과 데이터 수집에는 빠르고 비용 효율적인 모델이, 최종 근본 원인 도출에는 추론 능력이 뛰어난 모델이 필요합니다.
셋째, 기존 운영 도구와의 원활한 연동입니다. 팀이 이미 사용하고 있는 Datadog, Bitbucket, Confluence, AWS, EKS, PostgreSQL, OpenSearch 등 7개 이상의 도구를 AI가 직접 활용할 수 있어야 했는데, Model Context Protocol(MCP)은 AI 모델과 외부 도구 간의 표준화된 연동 인터페이스를 제공하여, 각 도구를 개별 MCP 서버로 구성하고 AI 에이전트가 필요에 따라 자유롭게 호출할 수 있는 구조를 가능하게 했습니다.
시스템 처리 흐름
인시던트가 발생하면 다음과 같은 자동화된 파이프라인을 통해 분석이 진행됩니다.
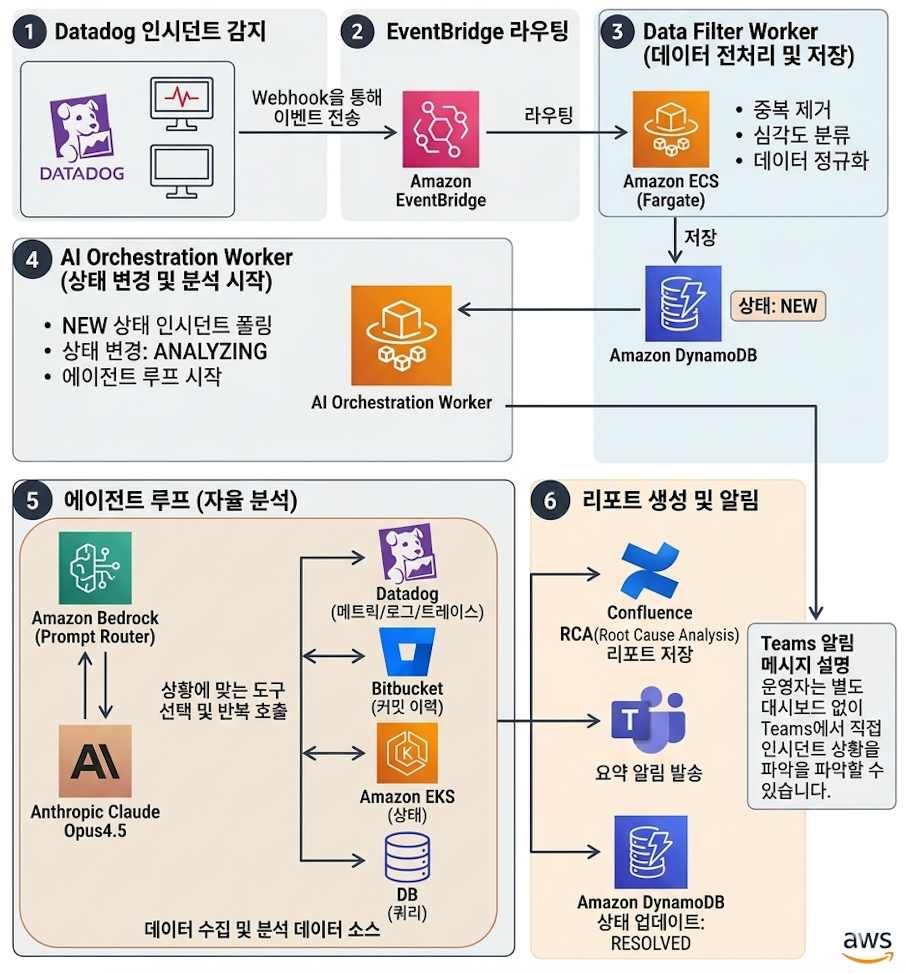
1단계: Datadog 인시던트 감지
16개 조직 중 하나에서 모니터 알림 발생 시, Datadog Webhook이 Amazon EventBridge로 이벤트를 전송합니다.
2단계: EventBridge 라우팅
이벤트 규칙에 따라 Amazon ECS Fargate의 Data Filter Worker로 라우팅이 이루어집니다.
3단계: Data Filter Worker
중복 이벤트 제거, 심각도 분류, 인시던트 데이터 정규화를 수행한 후 Amazon DynamoDB에 저장합니다.(상태: NEW)
4단계: AI Orchestration Worker
Amazon DynamoDB 폴링으로 NEW 상태 인시던트를 감지 후, 상태를 ANALYZING으로 변경하고 에이전트 루프를 시작합니다.
5단계: 에이전트 루프 (자율 분석)
Amazon Bedrock Prompt Router / Anthropic Claude Opus 4.5 기반으로 상황에 맞는 도구를 선택하여 반복 호출 작업을 수행합니다. Datadog 메트릭/로그/트레이스, Bitbucket 커밋 이력, EKS 상태, DB 쿼리 등을 수집하고 분석합니다.
6단계: 리포트 생성 및 알림
분석 결과를 Confluence에 RCA(Root Cause Analysis) 리포트로 저장하고 MS Teams 채널에 요약 알림을 발송합니다. Amazon DynamoDB 상태를 RESOLVED로 업데이트합니다.
Teams 알림 메시지
분석이 완료되면 AI Orchestration Worker가 Microsoft Teams 채널에 구조화된 요약 알림을 자동 발송합니다. 운영자는 별도 대시보드 접속 없이 Teams에서 바로 인시던트 상황을 파악할 수 있게 됩니다.
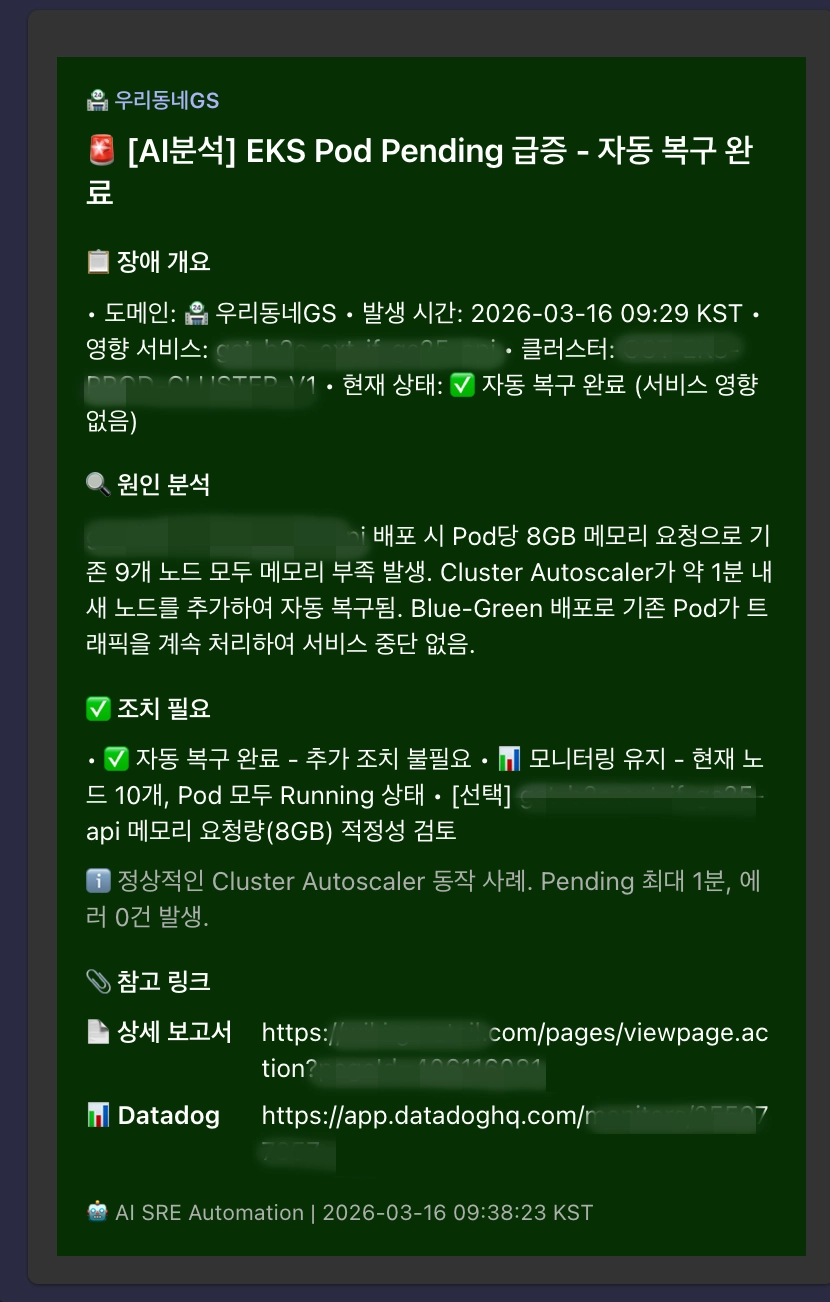
<그림 1. MS Teams 자동 알림 메시지>
<AI 분석 후 인시던트 요약, 근본 원인, 권장 조치를 채널에 메시지로 발송>
솔루션 아키텍처
이러한 설계 기준을 바탕으로 구축된 시스템의 전체 아키텍처는 다음과 같습니다.
시스템은 Amazon ECS Fargate 위에서 동작하는 컨테이너 기반 아키텍처로 설계되었습니다. AI 모델은 Amazon Bedrock Prompt Router(Anthropic Claude Sonnet 계열 자동 라우팅)와 Anthropic Claude Opus 4.5를 병행 사용하여, 작업 복잡도에 따라 최적의 모델을 활용합니다.
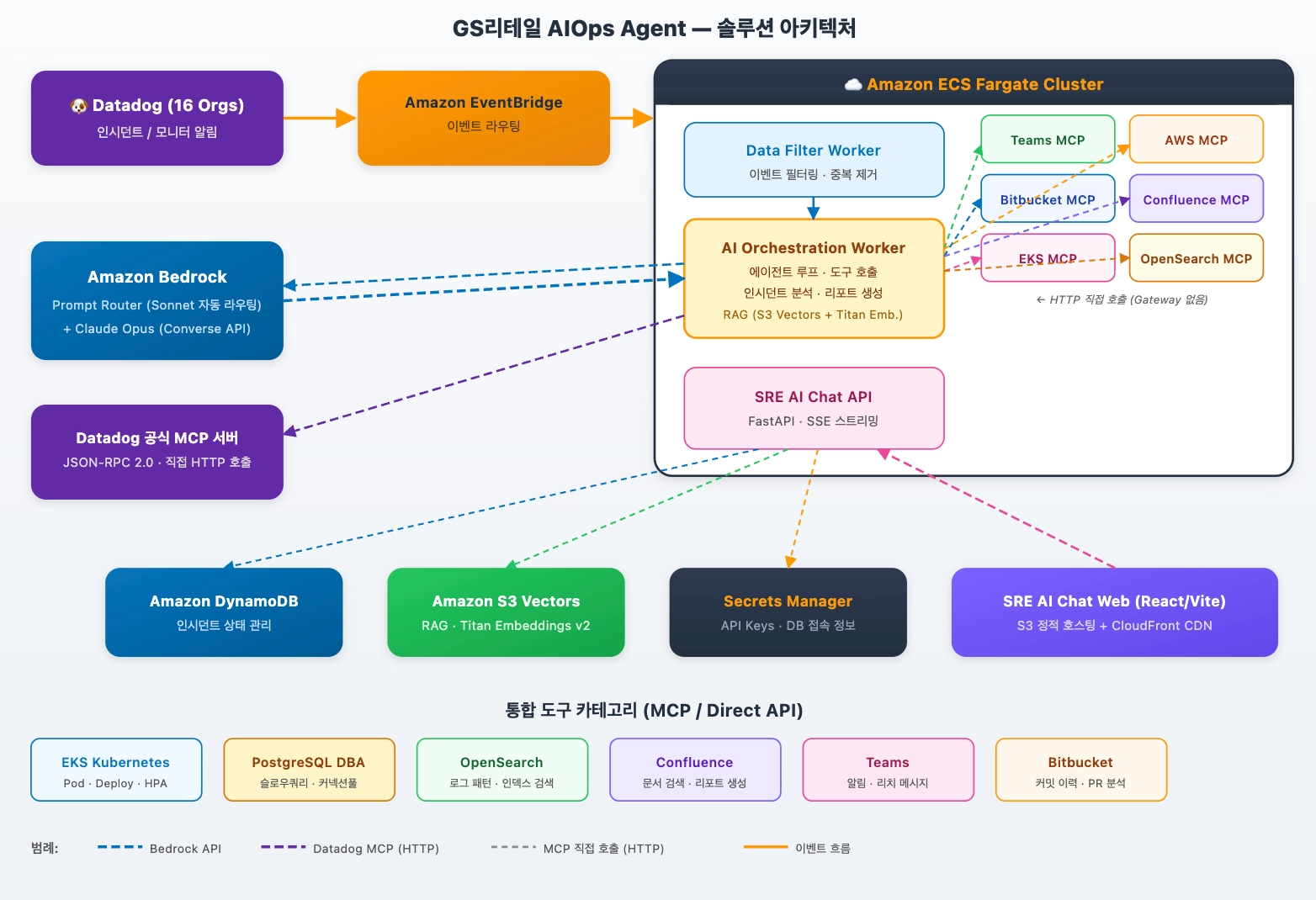
<그림 2. GS리테일 AIOps Agent 솔루션 아키텍처>
핵심 설계 결정
Bedrock Prompt Router + Anthropic Claude Opus 4.5 병행: Prompt Router는 Anthropic Claude 3.7 Sonnet과 Claude 3.5 Sonnet v2 사이에서 자동 라우팅하여 비용을 최적화합니다. 복잡한 분석이 필요한 경우 Anthropic Claude Opus 4.5를 Converse API로 직접 호출합니다. 개발 시점에서 Prompt Router에 아직 Opus 4.5가 지원되지 않아 별도 인터프리터 방식으로 호출하는 구조를 활용했습니다.
Datadog 공식 MCP 서버 직접 호출: 자체 MCP 서버 대신 Datadog이 제공하는 공식 MCP 서버를 JSON-RPC 2.0으로 직접 호출합니다. 16개 조직의 API Key/App Key는 AWS Secrets Manager에서 관리하며, 새 조직 추가 시 키만 등록하면 즉시 사용 가능합니다.
MCP 직접 호출 구조: AI Orchestration Worker가 Teams, AWS, Bitbucket, Confluence 등 각 MCP 서비스를 HTTP로 직접 호출합니다. 중간 Gateway 없이 직접 통신하여 레이턴시를 최소화하고 아키텍처를 단순화했습니다.
RAG 기반 지식 검색: Amazon S3 Vectors와 Amazon Titan Embeddings v2를 활용하여 과거 인시던트 분석 결과를 벡터화하고, 새 인시던트 발생 시 유사 패턴을 검색하여 분석 품질을 높입니다.
에이전트 루프 : 자율적 SRE의 사고 엔진 구현
AI Orchestration Worker의 핵심은 에이전트 루프(Agent Loop)입니다. 단순히 명령을 수행하는 것이 아니라, Amazon Bedrock API를 활용해 스스로 도구를 선택하고 결과를 분석하며 정답을 찾을 때까지 추론을 반복하는 ‘자율적인 분석 사이클’을 구축했습니다.
컨텍스트 기반 동적 도구 로딩 (Dynamic Tooling)
모든 도구를 한꺼번에 주입하면 모델의 혼란도가 높아지고 토큰 비용이 상승하므로 인시던트의 유형(DB, K8s, Network 등)에 따라 필요한 도구 세트만 동적으로 구성하여 정확도를 높였습니다.
- DB 장애라면? PostgreSQL 분석 도구와 Slow Query 로그 조회 권한 부여
- K8s 이슈라면? EKS Pod 상태 확인 및 이벤트 로그 수집 도구 활성화
- 코드 이슈라면? Bitbucket 소스코드 열람 도구 자동 로딩
async def _build_tool_config(self, incident: dict) -> list:
"""인시던트 성격에 따라 최적의 도구 세트 구성"""
tools = []
tools.extend(self._get_datadog_tools()) # 기본 모니터링
if self._is_k8s_related(incident): tools.extend(self._get_eks_tools())
if self._is_db_related(incident): tools.extend(self._get_postgres_tools())
....
if self._has_service_mapping(incident): tools.extend(self._get_bitbucket_tools())
return toolsAmazon Bedrock Converse API 기반 에이전트 루프
일반적인 분석은 Prompt Router를 통해 비교적 비용 효율적인 Anthropic Claude Sonnet 계열로 처리하고, 고도의 판단이 필요한 최종 단계에서는 Anthropic Claude Opus 4.5를 호출하는 하이브리드 전략을 사용합니다.
async def _run_agent_loop(self, incident: dict, tools: list) -> dict:
"""Sonnet으로 조사하고, Opus 4.5 로 확정하는 하이브리드 루프"""
messages = [self._build_system_prompt(incident)]
for i in range(15):
# 1. [Sonnet] 기민한 현장 조사 (Prompt Router 활용)
# 반복적인 도구 호출과 데이터 수집은 비용 효율과 속도가 중요합니다.
response = await self.bedrock.converse(
modelId=self.prompt_router_arn,
messages=messages,
toolConfig={"tools": tools}
)
if response["stop_reason"] == "tool_use":
# AI가 도구를 사용해 실시간 데이터를 가져오는 과정
results = await self._execute_tools(response)
messages.append(response["output"]["message"])
messages.append({"role": "user", "content": results})
continue
# 2. [검증] "직접 코드를 봤는가?" (Source Code Enforcement)
# 보고서에 코드 얘기가 있는데 Bitbucket을 안 봤다면 다시 돌려보냅니다.
final_draft = self._extract_text(response)
if self._needs_more_investigation(final_draft):
messages.append({"role": "user", "content": "추측 대신 Bitbucket 코드를 직접 분석하세요."})
continue
# 3. [Opus 4.5] 최종 심층 분석 (Escalation)
# 단순 조사를 넘어 '근본 원인'의 인과관계를 엮어낼 때는 최고 성능의 모델을 호출합니다.
if self._is_complex_case(final_draft):
return await self._interpret_with_opus(final_draft)
return final_draft4단계 적응형 조사 전략
에이전트는 인시던트 유형에 따라 조사 전략을 자동으로 조정합니다.
- 초기 컨텍스트 수집: Datadog 인시던트 상세 정보, 관련 모니터, 최근 이벤트 조회
- 메트릭/로그 심층 분석: 에러율, 레이턴시, 리소스 사용량 등 핵심 메트릭과 에러 로그 패턴 분석
- 상관관계 분석: Bitbucket 최근 배포 이력, EKS Pod 상태, DB Slow Query 등 교차 분석
- 근본 원인 도출: 수집된 데이터를 종합하여 근본 원인 식별 및 해결 방안 제시
핵심 AI 로직: 시스템 프롬프트와 자율 사고
에이전트 루프의 진짜 핵심은 AI에게 “어떻게 생각할 지” 가르치는 시스템 프롬프트와, 매 단계마다 AI가 스스로 다음 행동을 결정하는 Thinking 로직입니다.
시스템 프롬프트 – 핵심 행동 원칙
AI Orchestration Worker가 Amazon Bedrock에 전달하는 시스템 프롬프트의 핵심입니다. 단순한 “분석해줘”가 아니라, SRE 전문가의 사고방식 자체를 주입합니다.
# 역할
당신은 장애의 근본 원인(Root Cause)을 추적하는 SRE 전문가입니다.
증상을 나열하는 것이 아니라, "왜 이 문제가 발생했는가"를 끝까지 파고
들어야 합니다.
# 핵심 행동 원칙
## 1. 자율적 탐색
- 모든 도구를 자유롭게 사용하세요. 순서 제한 없습니다.
- 한 영역에서 원인을 못 찾으면 다른 영역으로 확장하세요.
- 인프라 <-> 애플리케이션 <-> 외부연동 <-> 데이터베이스, 어디든 이동 합니다.
## 2. 직접 확인 우선
- 의심되는 것은 반드시 도구로 직접 확인하세요.
- "~를 확인해 보세요"라고 쓰려면, 먼저 직접 확인을 시도하세요.
- 보고서에는 확인한 결과만 기술하세요.
- 소스코드도 직접 확인하세요! "코드 점검 필요"가 아니라,
Bitbucket에서 실제 코드를 찾아 분석 결과를 보고서에 포함하세요.
## 3. 증거 기반 분석
- 모든 판단에는 증거(로그, 메트릭, 트레이스, 코드)를 첨부하세요.
- 추측과 사실을 명확히 구분하세요. 추정 시 "[추정]" 표기.
## 4. 근본 원인까지 추적 (5 Whys)
- 증상 수집에서 멈추지 마세요. "왜?"를 반복하세요.
- 가설 수립 -> 도구로 검증 -> 결과 기록 -> 다음 가설
(원인을 찾을 때까지 반복)설계 의도: “자율적 탐색”과 “직접 확인 우선” 원칙이 핵심입니다. 정해진 순서대로 도구를 호출하는 것이 아니라, AI가 매 순간 상황을 판단하여 가장 효과적인 도구를 선택합니다. “코드 점검 필요”라고 사람에게 넘기는 대신, Bitbucket에서 직접 소스코드를 읽고 분석하도록 지시합니다.
Thinking 로직 – AI의 자율적 판단
매 조사 단계마다 AI는 _think() 메서드를 통해 “방금 본 결과를 바탕으로 다음에 뭘 봐야 할까?”를 스스로 결정합니다. 정해진 순서가 아니라, 실시간 데이터를 보고 판단하는 구조입니다.
async def _think(self, observation: Dict, context: Dict) -> Dict:
"""AI가 다음 액션 결정 - 매 순간 상황을 보고 스스로 판단"""
# 마지막 조사 결과를 상세하게 전달
last = context['investigation_history'][-1]
full_result_str = json.dumps(last['full_result'], indent=2)
prompt = f"""
# 방금 조사한 내용 (자세히 읽어보세요!)
**액션**: {last['action']}
** 상세 결과**: {full_result_str}
# 조사 철학
당신은 순서를 따르는 로봇이 아닙니다.
매 순간 상황을 보고 스스로 판단하는 SRE입니다.
1. "다음에 뭘 봐야 할까?"를 스스로 결정하세요
2. Datadog에서 문제를 발견하면 -> Bitbucket에서 코드를 찾아 분석
3. 데이터가 본질과 관련없다면 즉시 다른 방법을 시도
4. 한 가지 방법에 2번 이상 집착하지 마세요
"""
response = await self._call_bedrock(prompt)
decision = self._parse_json_response(response)
# AI의 사고 과정 로깅
logger.info(f"[Think] {decision['thinking']}")
logger.info(f"[Think] Decision: {decision['action']}")
return decisionAI는 다음과 같은 JSON 형식으로 사고 과정을 출력합니다. thinking 필드에 자연어로 추론 과정을 기술하고, 그에 따라 다음 도구를 선택합니다.
// 실제 AI 사고 과정 예시 (우리동네GS EKS Pod Pending 인시던트)
{
"thinking": "Pod Pending 알람이네. EKS 클러스터 상태를 먼저 봐야겠어.
노드 메모리가 부족한 건 아닌지, 스케줄링 실패 이벤트가 있는지 확인하자.",
"action": "eks_get_events",
"reasoning": "Pending 상태는 스케줄링 실패를 의미. 이벤트를 보면 원인을 알 수 있어.",
"parameters": {
"cluster_name": "EKS-PROD-CLUSTER-V1",
"namespace": "xxxx"
}
}
// -> 결과: "Insufficient memory" 이벤트 발견
// -> 다음 사고: "메모리 부족이네. 최근 배포가 있었나? Bitbucket 확인하자."
{
"thinking": "노드 메모리 부족으로 스케줄링 실패. 최근에 메모리를 많이 쓰는
배포가 있었을 수 있어. Bitbucket에서 최근 커밋을 확인해보자.",
"action": "bitbucket_list_commits",
"reasoning": "xxxx-api 배포가 메모리 부족을 유발했을 가능성.",
"parameters": { "service_name": "xxxx-api" }
}MCP 도구 상세
시스템은 7개 이상의 도구 카테고리를 통합하여 다양한 관점에서 인시던트를 분석합니다.
| 카테고리 | 주요 도구 | 설명 |
|---|---|---|
| Datadog | search_logs, get_metric, search_spans, get_trace | 16개 조직의 메트릭, 로그, APM 트레이스를 공식 MCP 서버로 직접 조회 |
| Bitbucket | list_commits, get_pr_diff, search_code | 서비스별 최근 커밋 이력, PR 변경사항, 코드 검색으로 배포 관련 원인 파악 |
| Confluence | search, get_page, create_page | 운영 문서 검색, 과거 장애 대응 이력 참조, 분석 리포트 자동 생성 |
| AWS | describe_instances, get_metric_data | EC2, RDS, ELB 등 인프라 리소스 상태 및 Amazon CloudWatch 메트릭 조회 |
| EKS Kubernetes | get_pods, describe_pod, get_events, get_hpa | Pod 상태, 이벤트, HPA 스케일링 상태, 리소스 사용량 분석 |
| PostgreSQL DBA | slow_queries, connection_pool, table_stats |
슬로우쿼리 분석, 커넥션 풀 상태, 테이블 통계 및 락 정보 조회 * 자체적으로 개발한 DBA Agent로, PostgreSQL 및 Oracle MCP 를 활용해 DB 딕셔너리 테이블 또는 테이블 컬럼 구조 등을 조회하여 데이터베이스를 관리합니다. RDS, EDB on EC2, IDC 내의 PostgreSQL까지 모두 관리하고 있습니다. |
| OpenSearch | search_index, log_pattern_analysis, data_distribution | 로그 패턴 분석, 데이터 분포 변화 감지, 이상 탐지 |
SRE AI Chat Web
자동 분석 시스템과 별도로, 운영자가 직접 AI와 대화하며 인시던트를 분석할 수 있는 SRE AI Chat Web을 구축했습니다. 운영자가 자연어로 질문하면 AI가 실시간으로 Datadog, AWS, Bitbucket 등의 도구를 호출하여 답변합니다.
- 백엔드: FastAPI 기반 SSE(Server-Sent Events) 스트리밍 API, Amazon ECS Fargate에서 운영
- 프론트엔드: React/Vite SPA, Amazon S3 정적 호스팅 + Amazon CloudFront CDN
- 대화 이력: Amazon DynamoDB에 대화 세션 및 메시지 저장
- 실시간 도구 호출: AI가 분석 중 호출하는 도구와 결과를 실시간으로 스트리밍하여 투명한 분석 과정 제공
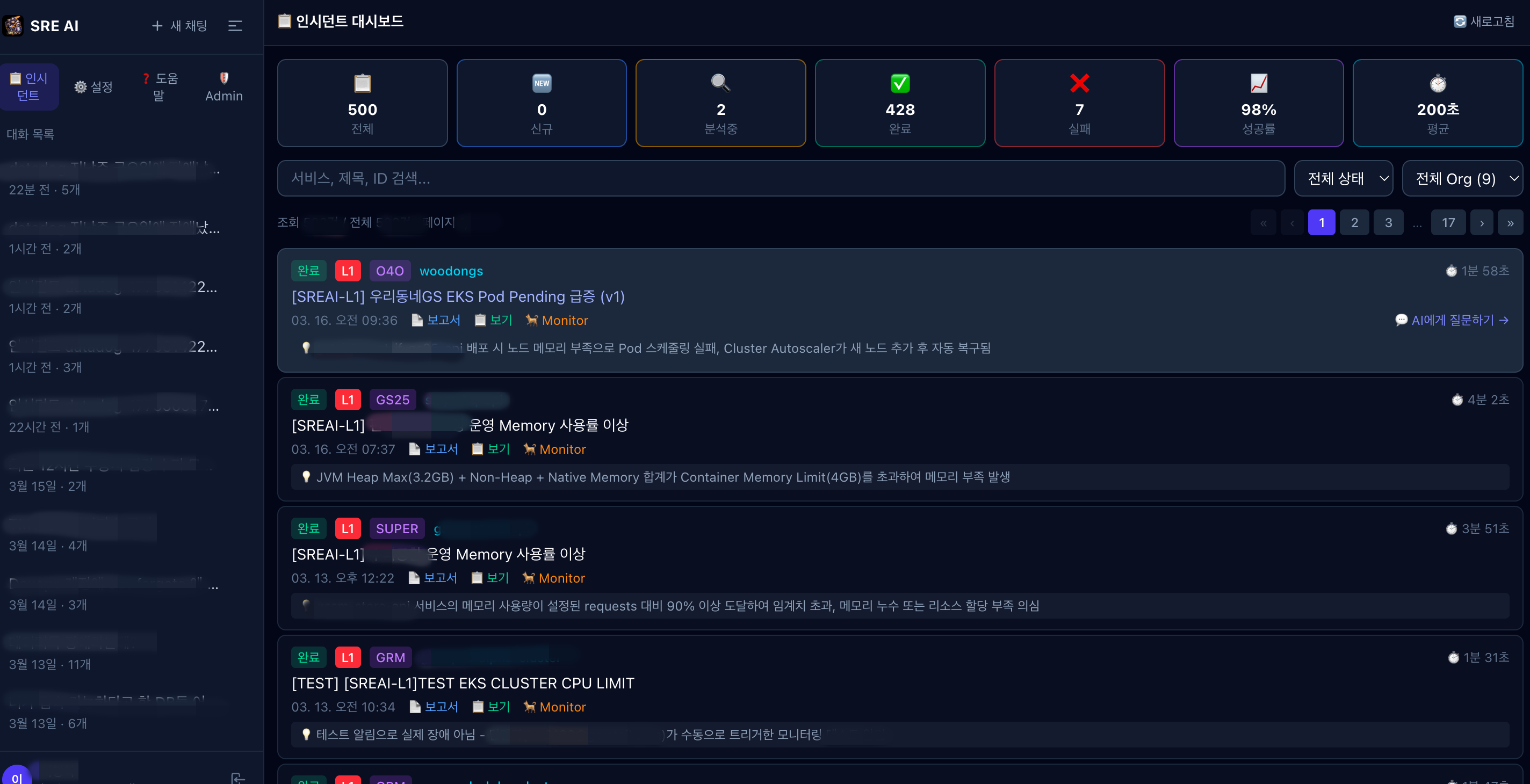
<그림 3. SRE AI Chat 인시던트 대시보드>
<인시던트 상세 분석 결과와 근본 원인, 타임라인, 권장 조치를 포함한 구조화된 리포트>
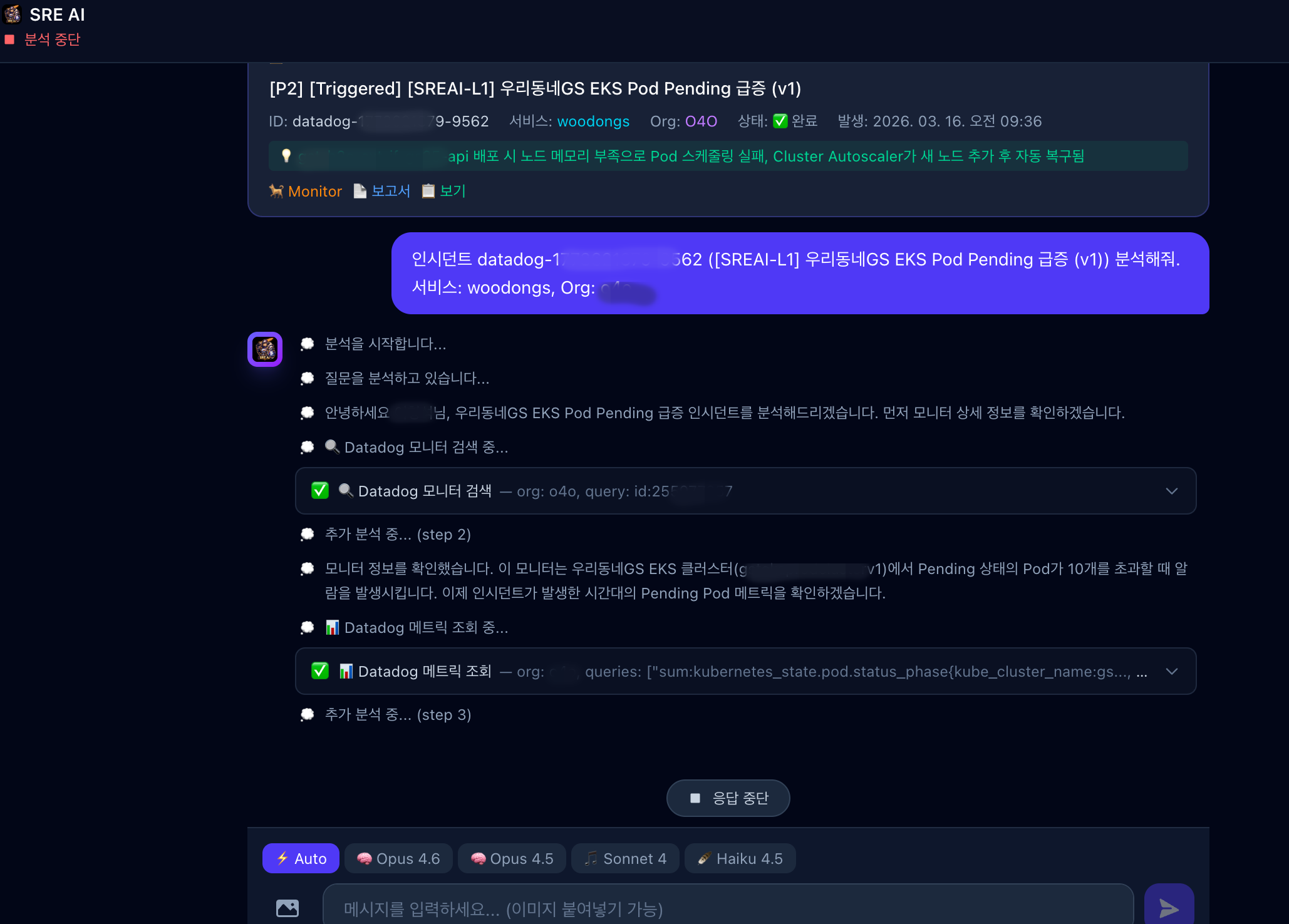
<그림 4. SRE AI Chat 대화형 분석>
<운영자의 질문에 AI가 실시간으로 Datadog, Bitbucket 등 도구 호출하며 분석 과정을 투명하게 스트리밍>
실제 인시던트 시나리오
다음은 우리동네GS 서비스의 EKS Pod Pending 급증 인시던트를 시스템이 자동으로 분석한 실제 사례입니다. Datadog 모니터 알림이 발생한 시점부터 AI가 근본 원인을 도출하고 Confluence에 RCA 보고서를 생성하기까지의 전체 과정을 보여줍니다.
09:36 – Datadog 알림 수신
[P2] [SREAI-L1] 우리동네GS EKS Pod Pending 급증 (V1) 모니터 알림발생.
클러스터: EKS-PROD-CLUSTER-V1, 서비스: XXXX (Monitor ID: 12345678)09:36 – 자동 분석 시작
Data Filter Worker가 EventBridge 이벤트를 수신하고 DynamoDB에 저장 (상태: NEW).
AI Orchestration Worker가 폴링으로 감지하여 즉시 분석 시작 (상태: ANALYZING)09:36 ~30s – Datadog 메트릭/모니터 분석
AI가 get_datadog_metric, search_datadog_monitors 도구를 호출하여
kubernetes.pods.status.pending 메트릭 급증 확인.
클러스터내 Pending 상태 Pod 수가 임계값을 초과한 시점과 패턴 분석09:37 – EKS 클러스터 상태 조사 + 로그 분석
AI가 get_pods, describe_pod, get_events 도구로 EKS-PROD-CLUSTER-V1 클러스터 상태 확인.
동시에 search_datadog_logs로 XXXX 서비스 에러 로그 분석.
Pod 스케줄링 실패 원인과 노드 메모리 부족 패턴 파악09:37 ~30s – 배포 이력 확인 + 근본 원인 도출
AI가 Bitbucket 배포 이력을 확인하고, 수집된 메트릭/로그/클러스터 상태를 종합하여
근본 원인 도출: XXXX 서비스 배포 시 노드 메모리 부족으로 Pod 스케줄링 실패09:38 – RCA 보고서 생성 및 알림
Confluence에 RCA 보고서 자동 생성, Teams 채널에 인시던트 요약 알림 발송,
DynamoDB 상태를 RESOLVED로 업데이트. 전체 처리 완료분석 소요 시간: 1분 58초 – Datadog 알림 수신부터 RCA 보고서 생성까지 평균 처리 시간 198초, 최소 76초. 기존 수동 분석(30분 이상) 대비 약 93% 단축된 수치입니다. 운영자는 AI가 생성한 리포트를 확인하고 조치 여부만 판단하면 됩니다.
RCA 보고서 (Confluence 자동 생성)
AI Orchestration Worker는 분석이 완료되면 Confluence에 구조화된 RCA(Root Cause Analysis) 보고서를 자동으로 생성합니다. 아래는 실제 우리동네GS EKS Pod Pending 인시던트에 대해 AI가 자동 생성한 보고서입니다. 알람 정보, 메트릭 분석 결과, 근본 원인, 권장 조치가 포함됩니다.
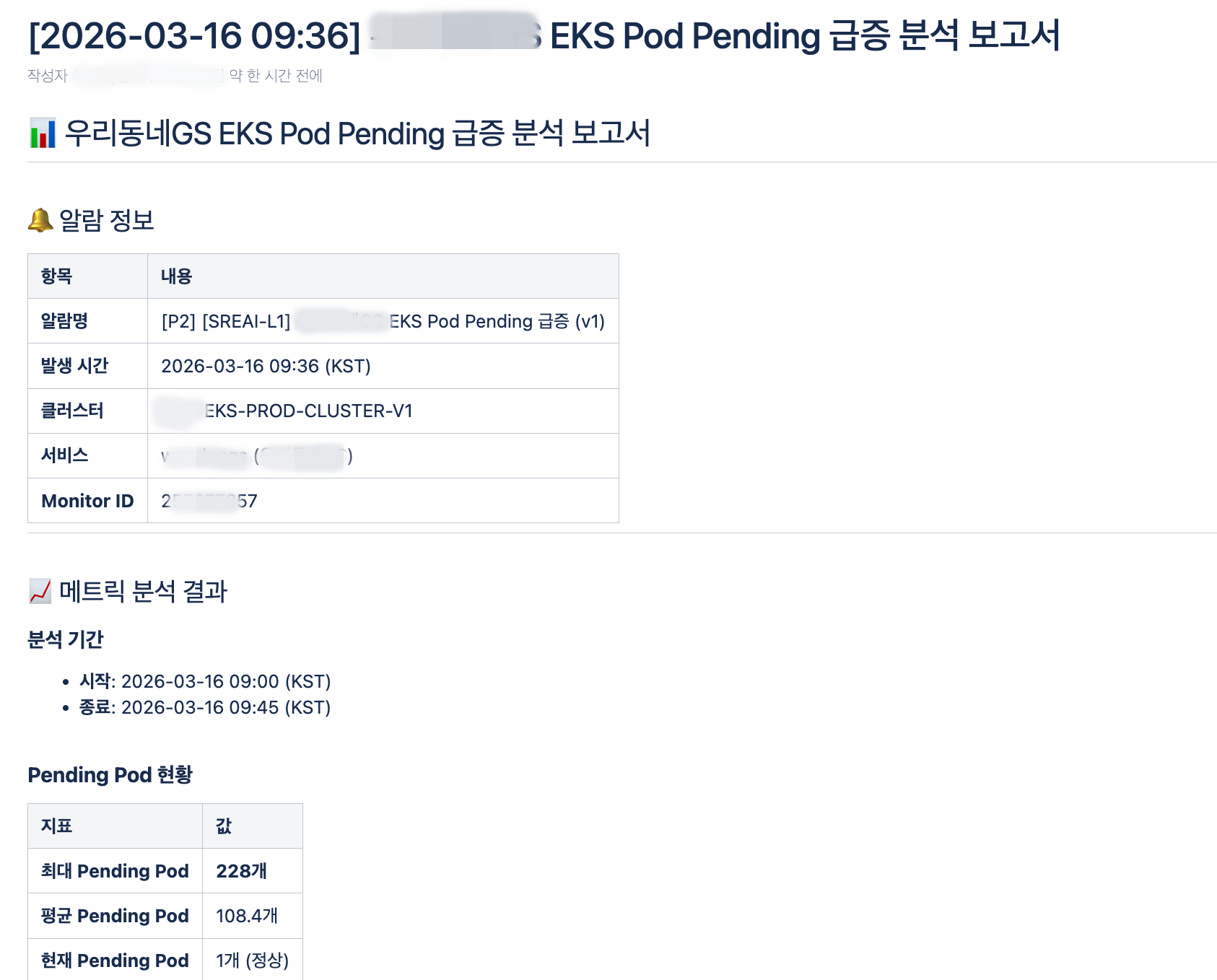
<그림 5. RCA 보고서 (1)>
<알람 정보 (모니터명, 심각도, 클러스터, 서비스) 및 메트릭 분석 결과. kubernetes.pods.status.pending 메트릭 추이와 임계값 초과 시점 분석>

<그림 6. RCA 보고서 (2)>
<AI가 수행한 조사 과정 상세. EKS 클러스터 상태, Pod 스케줄링 이벤트, Datadog 로그/트레이스 분석 결과 및 상관관계 도출>
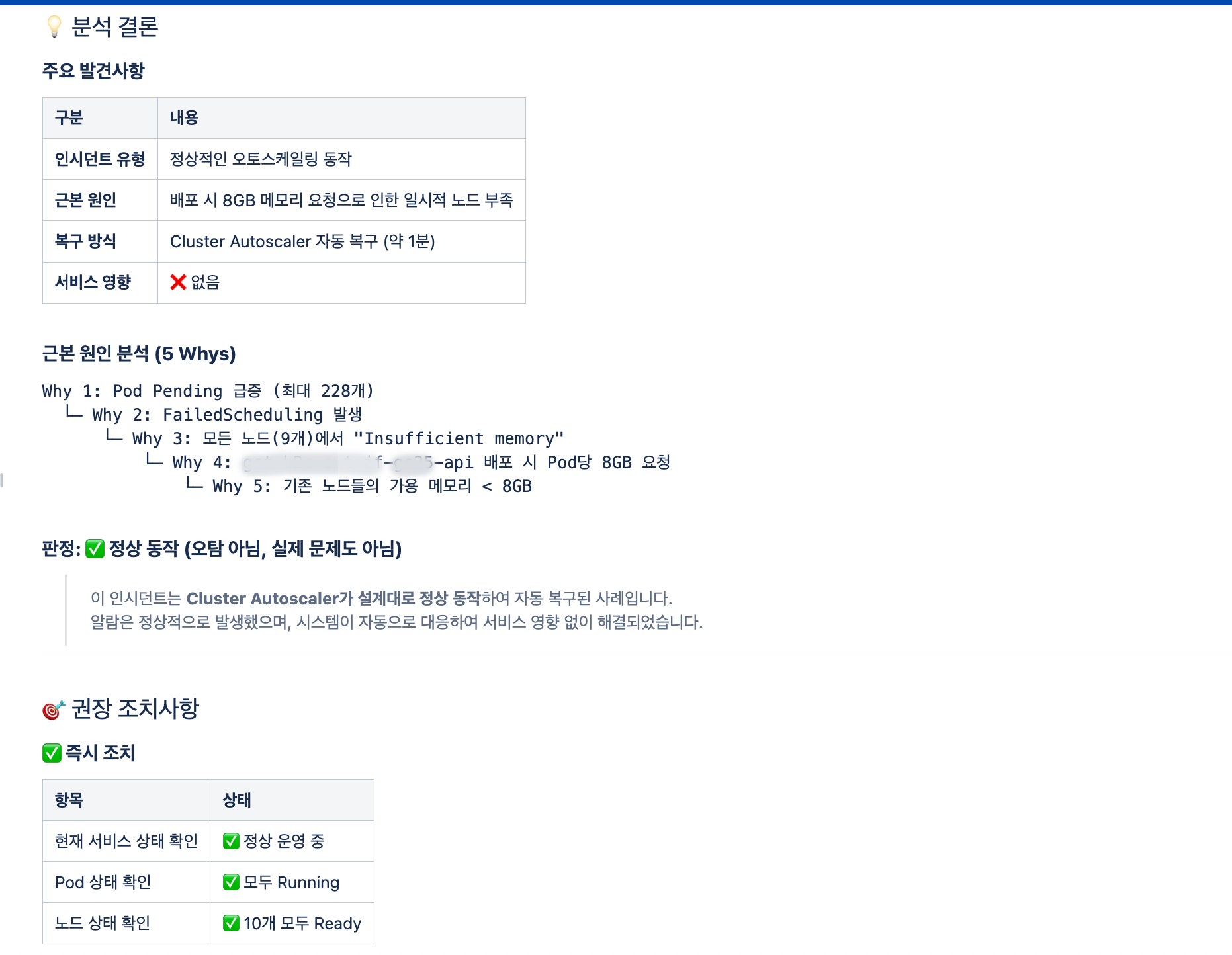
<그림 7. RCA 보고서 (3)>
<근본 원인 분석 결과 (5 Whys), 권장 조치 사항, 재발 방지 대책 및 후속 작업 목록>
도입 성과
정량적 성과
| 지표 | Before (수동 분석) | After (AIOps Agent) |
|---|---|---|
| 평균 분석 시간 | 30분 이상 | 약 2분 (평균 198초, 최소 76초) |
| 분석 시간 단축률 | – | 약 93% |
| 도구 전환 | 5~6개 도구 수동 전환 | 7개 이상 도구 자동 통합 분석 |
| 야간/주말 초기 대응 | 당직 인력 의존 | AI 자동 분석 즉시 시작 |
| 분석 결과 문서화 | 수동 작성 | Confluence RCA 보고서 자동 생성 |
정성적 성과
- 야간/주말 대응 강화: AI가 24/7 자동 분석하여 초기 대응 시간 단축, 운영자는 리포트 확인 후 의사결정에 집중
- 지식 축적: 모든 분석 결과가 Confluence에 자동 저장되어 조직 지식으로 축적, RAG를 통해 유사 인시던트 분석 시 참조
- 분석 품질 균일화: 숙련도에 관계없이 일관된 분석 품질 제공, 신규 인력의 학습 곡선 단축
- 투명한 분석 과정: SRE AI Chat Web을 통해 AI의 도구 호출과 분석 과정을 실시간으로 확인 가능
결론
이 글에서는 GS리테일 클라우드인프라팀이 Amazon Bedrock과 MCP를 활용하여 AIOps Agent 시스템을 구축한 사례를 소개했습니다. 이 시스템은 Datadog 인시던트 발생 시 AI가 자율적으로 7개 이상의 도구를 활용하여 근본 원인을 분석하고, Confluence에 RCA 보고서를 자동 생성하며, Microsoft Teams로 결과를 알립니다. 핵심은 단순한 자동화가 아니라, SRE 전문가의 사고방식을 AI에 주입한 에이전트 루프 구조입니다. Amazon Bedrock Prompt Router를 통한 비용 최적화, Anthropic Claude Opus 4.5를 활용한 심층 분석, 그리고 동적 도구 로딩과 Thinking 로직을 통한 자율적 판단이 결합되어, 기존 30분 이상 소요되던 인시던트 분석을 평균 약 2분으로 단축했습니다.
GS리테일은 여기서 멈추지 않고, 더 고도화된 자율 운영을 향한 로드맵을 추진하고 있습니다.
- 자동 조치(Auto-Remediation) 확장 현재의 ‘원인 분석 및 보고’ 단계를 넘어, 분석 결과의 신뢰도가 높은 특정 장애 패턴(예: 특정 서비스의 Pod Restart, 리소스 임계치 조정 등)에 대해서는 에이전트가 직접 인프라를 복구하는 Self-healing 기능을 강화할 예정입니다.
- FinOps Agent 연동을 통한 비용 기반 대응 새롭게 구축될 FinOps Agent와 연동하여, 장애 복구 시나리오 선택에 ‘비용’이라는 변수를 추가합니다. 예를 들어, 트래픽 폭증 시 무조건적인 스케일 아웃 대신, 현재 예산 상황과 리소스 단가를 고려하여 가장 비용 효율적인 인스턴스 타입을 선택하거나 비핵심 리소스를 일시 중단하는 등의 비용 최적화된 장애 대응을 실현할 계획입니다.
- 멀티 에이전트 협업 체계(Multi-Agent Orchestration) DB 전용 분석 에이전트, 보안 특화 에이전트, FinOps 에이전트가 서로 MCP를 통해 컨텍스트를 공유하며 협업하는 구조로 발전시켜, 더욱 복잡하고 거대한 규모의 인프라를 지능적으로 관리하고자 합니다.
- Graph DB 기반 정확도 향상 회사 전체 시스템의 온톨로지를 Amazon Neptune 기반 GraphRAG로 구성하여, 장애 발생 시 Upstream/Downstream 영향도를 즉시 파악하고 근본 원인(Root Cause)까지 정확히 도출할 수 있도록 분석 정확도를 끌어올리고 있습니다.
<그림 8. Graph RAG 구성을 통한 정확도 향상>
이제 GS리테일의 SRE는 새벽 3시 장애 알람에 깨어 막막한 분석을 시작하는 대신, AI가 자율적으로 작성한 정밀 보고서를 검토하며 즉각적인 의사결정에 집중하고 있습니다.