AWS 기술 블로그
HotelStory의 Amazon Q in QuickSight를 통한 생성형 AI 비즈니스 인텔리전스 환경 구축하기

호텔스토리는 호스피탈리티 테크 기업으로, 호텔 예약과 온라인 판매를 위한 통합 솔루션을 제공합니다. 호텔 파트너는 여러 OTA에 흩어진 객실 재고와 요금을 한 곳에서 추적 및 관리할 수 있어, 호텔스토리의 GSA(총판 사업) · CMS(채널 매니저) · 자사 예약엔진(부킹 엔진)을 도입해 객실가와 재고를 최적화하고 운영 효율을 극대화합니다.
영국 파이낸셜 타임즈(FT)로부터 3년 연속 ‘아시아 태평양 고성장 기업’으로 선정되는 등, 호텔스토리는 우수한 사업성을 대외적으로 인정받았으며, 현재 400곳 이상 호텔 파트너를 위해 일일 매출 데이터 수만 건을 처리하고 있습니다.
프로젝트 배경
호텔스토리는 객실 예약 · 판매 데이터에서 숙박 운영을 돕기 위한 BI 인사이트를 발굴하고 활용하고 싶었습니다. 예약일, 투숙일, 예약 확정 또는 취소, 요금정책, OTA 별 실적과 같은 데이터 속에서 상관성을 확인하고 세일즈 전략을 도출하려는 것이었죠. 간단한 예를 들어보겠습니다.
- 유효예약 건에 대한 객단가 및 수익성을 분석해 요금 정책을 수정
- 외국인 체류객 선호 숙소를 탐색하여 외국인을 위한 버티컬 마케팅 전략 수립
직면한 문제
하지만 호텔스토리는 별다른 데이터 분석 플랫폼을 갖추지 못한 채, 데이터 기반 세일즈 인사이트를 확보하느라 몇 가지 비효율을 마주해야 했습니다.
- 데이터 접근 제한: 데이터는 개발실 DB 자산으로서 비즈니스 담당자는 직접적인 접근과 쿼리가 제한됩니다. 그러므로 담당자는 개발실을 거쳐 필요 데이터를 제공받은 다음, 수작업 레포트로 가공해야 했습니다.
- 개발 리소스 소모: 대다수 데이터 수요는 임의로 발생하였으며, 이 요구를 처리하기 위해 개발실은 애드혹 SQL 쿼리를 작성해야 했습니다. 관련 티켓팅 프로세스는 적어도 수 시간에서 하루의 리소스를 소모했습니다.
- 전략적 활용 부재: 지속적인 데이터 활용 전략이 없어, 정기적으로 비즈니스 KPI 를 분석하거나 세밀한 판매 전략(실시간 요금 재조정 등)을 집행하는 데 어려움이 있었습니다.
개선 목표
문제를 해결하고자 호텔스토리 개발실은 비즈니스 담당자가 쓰기 쉬우면서도 즉각적인 분석이 가능한 도구를 구축하는 방안을 모색했습니다.
- 비즈니스 유저를 위한 셀프 서비스 BI: 데이터 전문 지식 없이도 누구나 쉽게 자연어로 매출 데이터를 탐색하고 분석할 수 있는 도구 제공하기
- 분석 시간 단축: 데이터 분석에 생성형 AI를 도입해 비즈니스 트렌드 파악과 레포트 작성에 드는 시간을 단축하기
- 정기적인 레포팅: 정기적인 KPI 분석과 판매 전략 수립에 참고할 데이터 플랫폼 만들기
이를 충족하는 셀프 서비스 BI 대시보드가 있다면, 데이터 전문성이 없더라도 시각적인 차트를 통해 데이터의 의미를 이해하고, 조직 전반에 인사이트를 제공하여 데이터 중심 의사결정 문화를 활성화할 수 있을 것입니다.
더욱이 생성형 AI를 통해 데이터 분석 지원을 받는다면, 모든 사용자가 자연어 프롬프트를 사용하여 귀중한 인사이트를 신속하게 얻는 모습을 기대할 수 있습니다.
Q in QuickSight 도입
이 상황에서 아마존이 제공하는 BI 대시보드 서비스인 Amazon QuickSight 와, 추가로 활성하는 생성형 AI 분석 도우미 Amazon Q in QuickSight 가 매력적으로 다가왔습니다. 대시보드에 내장된 생성형 AI 분석 어시스턴트는 자연어 질문을 통해 데이터를 탐색하고 인사이트를 도출하는 기능을 제공합니다.
사용자가 “지난 달 객실 유형별 평균 요금은?” 같은 일상 언어로 질문하면, AI 가 적절한 차트와 분석 결과를 생성해줍니다 (Build visuals). 또한 데이터 패턴을 자동으로 감지하여 예상치 못한 매출 트렌드나 이상치를 발견하고 (Forecasts), 데이터를 다각도로 AI 에이전트와 함께 드릴다운하여 호텔 비즈니스 맥락에 맞는 분석을 수행합니다. (Scenarios).
구축 과정
호텔스토리는 AWS Data Lab 프로그램에서 3주간 집중 스프린트를 진행하며 AWS 기술 지원을 받아 셀프 서비스 BI 대시보드에 대한 개념증명(PoC)을 구현했습니다. 객실 예약 데이터를 ETL 작업을 통해 QuickSight 서비스에 연결하고, 비즈니스 담당자 요구를 반영한 시각적 대시보드로 표현했습니다. 특히 Q in QuickSight를 활성화하여 데이터 전문 지식 없이도 복잡한 분석이 가능한 환경을 제공하였습니다.
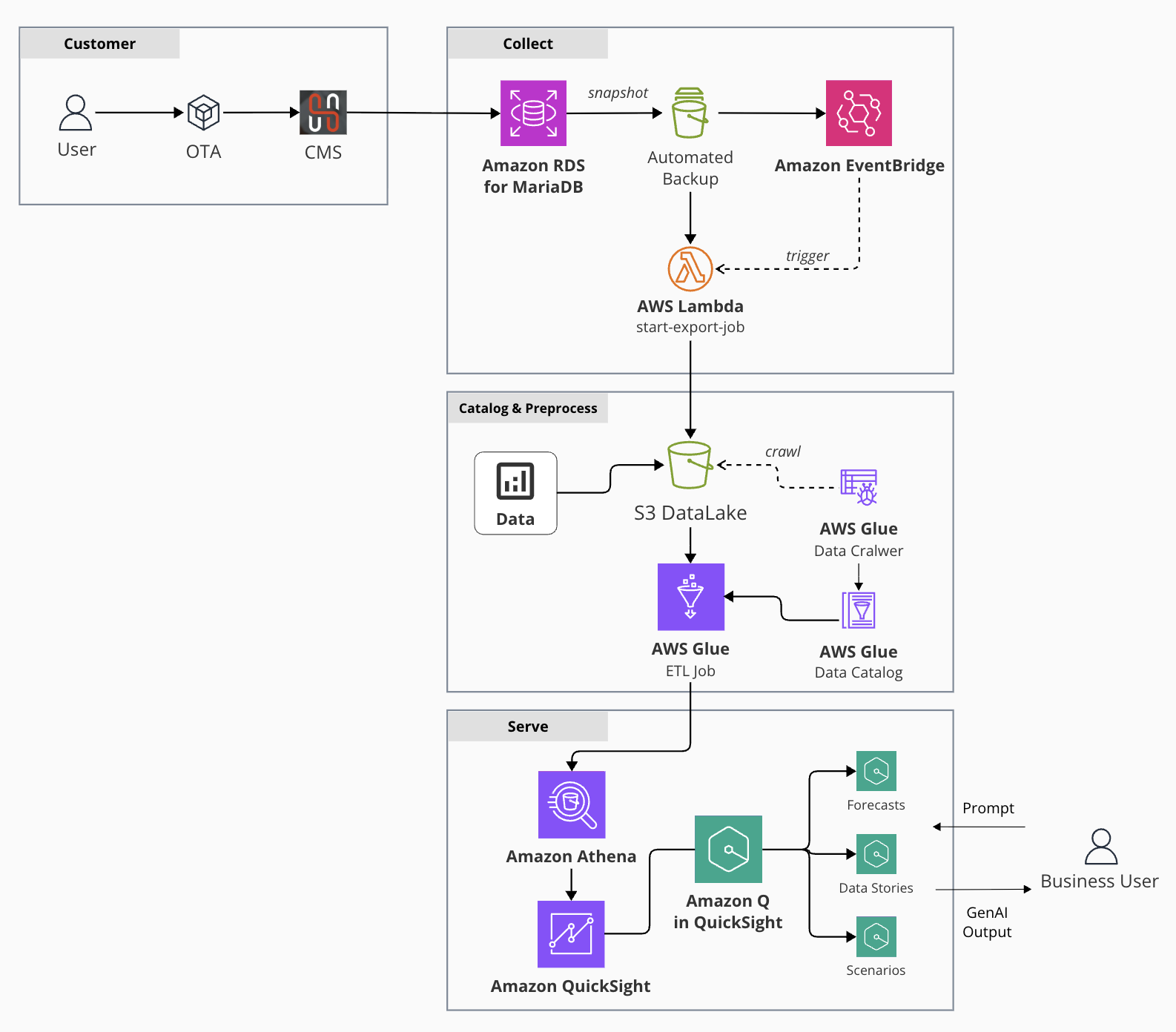
호텔스토리의 데이터 시각화 파이프라인은 데이터 수집> 카탈로깅> ETL> 서빙 단계로 구성되며 비용 효율성과 유연한 운영을 함께 고려하였습니다.
- 데이터 수집: Amazon RDS 자동 백업 스냅샷을 Amazon S3 버킷으로 내보내는 자동 파이프라인을 구축합니다.
- 데이터 카탈로깅: AWS Glue Data Crawler를 주기적으로 실행하여 Parquet 파일을 AWS Glue Data Catalog에 등록합니다.
- 데이터 ETL: 데이터 처리 복잡도에 따라 두 가지 접근 방식을 적용합니다.
- 복잡한 전처리: AWS Glue ETL Job 을 활용한 대용량 데이터 변환
- 민첩한 스키마 조인: Amazon Athena 에 View를 만들어 쿼리 처리
- 데이터 서빙: QuickSight 에 Athena 데이터 세트를 연결합니다. Q in QuickSight의 AI 어시스턴트가 비즈니스 담당자의 분석 요구를 처리합니다.
1. 데이터 소스 표준화 및 S3 수집
RDS 스냅샷 내보내기를 통한 데이터 수집
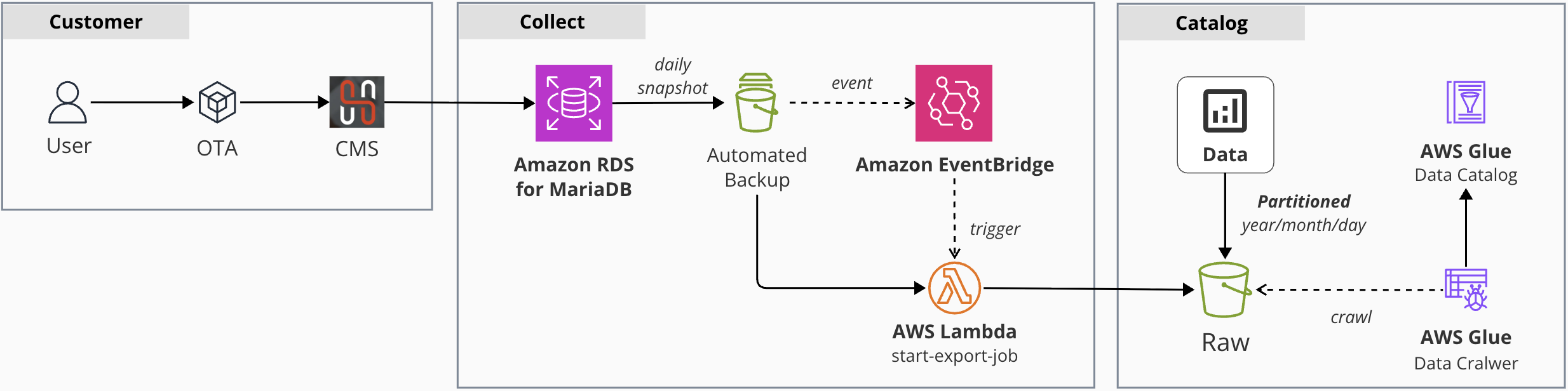
분석 워크로드가 운영 DB에 주는 부담을 완화하기 위해서, 일반적으로 DB 복제본을 생성해 분석용으로만 사용할 수 있습니다. 하지만 호텔스토리는 추가 인스턴스 없이 운영DB 영향성을 줄이고 싶었고, DB 스냅샷을 Amazon S3 버킷에 Export 하고서 데이터를 수집하는 파이프라인을 고안합니다.
- RDS 자동 백업이 매일 새벽 예약 DB 스냅샷을 생성합니다.
- 스냅샷 생성 이벤트가 Amazon EventBridge 에서 감지되고, AWS Lambda 함수를 트리거 합니다.
- Lambda 함수는 DB 스냅샷을 Amazon S3 버킷에 Apache Parquet 형식으로 저장합니다.
- 이후 AWS Glue 에 데이터를 카탈로깅 하면 후속 ETL 작업이나 Athena 쿼리로 테이블을 분석할 수 있습니다.
RDS 자동 백업 스냅샷 감지 이벤트
{
"source": ["aws.rds"],
"detail-type": ["RDS DB Snapshot Event"],
"detail": {
"EventCategories": ["creation"],
"SourceType": ["SNAPSHOT"],
"EventID": ["RDS-EVENT-0091"],
"SourceIdentifier": "my-db-instance"
}
}이 과정에서 특정 RDS 인스턴스의 스냅샷 생성을 감지할 수 있도록 EventBridge 이벤트 패턴을 정의했습니다. EventID: RDS-EVENT-0091 는 RDS 자동 백업으로 신규 스냅샷이 생성되었음을 포착합니다.
스냅샷을 S3 버킷에 내보내는 Lambda 함수
import boto3
from datetime import datetime
rds = boto3.client('rds')
def lambda_handler(event, context):
"""
RDS 스냅샷 생성 시 자동으로 S3로 Export하는 Lambda 함수
EventBridge를 통해 RDS 스냅샷 생성 이벤트를 수신
"""
try:
# EventBridge 이벤트에서 스냅샷 정보 추출
snapshot_arn = event["detail"]["SourceArn"]
snapshot_id = event["detail"]["SourceIdentifier"]
# S3 저장 경로 설정 (날짜별 폴더 구조)
export_date = datetime.utcnow().strftime('%Y%m%d')
s3_prefix = # S3 Prefix
# Export Task 실행
response = rds.start_export_task(
ExportTaskIdentifier=f"export-{export_date}-{snapshot_id}",
SourceArn=snapshot_arn,
S3BucketName=os.environ['EXPORT_BUCKET'],
S3Prefix=s3_prefix,
IamRoleArn=os.environ['EXPORT_ROLE_ARN'],
KmsKeyId=os.environ['KMS_KEY_ID']
)
print(f"Export task started: {response['ExportTaskIdentifier']}")
return {
'statusCode': 200,
'body': f"Successfully started export for snapshot: {snapshot_id}"
}
except Exception as e:
print(f"Export failed: {str(e)}")
return {
'statusCode': 500,
'body': f"Export failed: {str(e)}"
}이벤트가 포착되면 이어서 Lambda 함수가 트리거됩니다. 함수 event 인자의 detail.SourceArn 속성에 새 스냅샷 ARN이 담겨 있습니다. 함수는 RDS start-export-task 작업을 호출하며, 그 결과 스냅샷 사본이 Apache Parquet 형식으로 목적지 S3 버킷에 생성됩니다.
이렇게 예약 DB 데이터를 S3 버킷으로 옮길 수 있었습니다. 이 방식의 장점은 분명합니다.
- 운영 안정성: 매일 새벽 생성되는 스냅샷에 접근하므로 보고서 생성이나 탐색적 분석이 업무간 운영 DB 성능에 영향을 주지 않습니다. 당일 업무 시작전, 데이터가 BI 대시보드에 반영되고, 운영 · 세일즈 팀은 하루 주기의 최신 지표에 기반해서 의사결정을 내릴 수 있습니다.
- 쿼리 비용 및 성능 개선: Parquet 포맷과 날짜 파티션 프루닝 덕분에 Athena 쿼리 스캔 용량을 절감하고, 스캔 비용 및 응답 속도가 모두 개선됩니다.
2. 데이터 카탈로깅 및 전처리
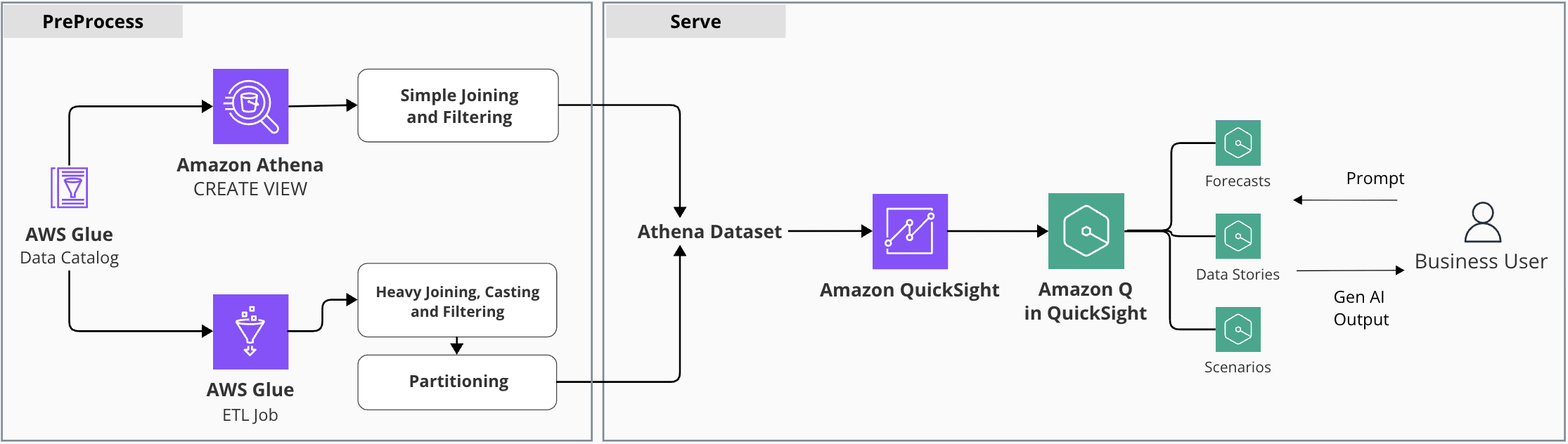
이제 데이터 카탈로그를 최신화하고 몇 가지 전처리를 수행하면 데이터를 활용할 수 있습니다. 호텔스토리는 데이터 카탈로깅 작업에 Glue Data Crawler 를 사용했습니다. 또, 무거운 전처리 작업은 Glue ETL Job 로 구현하고, 간단한 테이블 조인으로 민첩하게 처리 가능하다면 Athena View를 만드는 이원화 전략을 선택했습니다.
2.1. AWS Glue Data Crawler
매일 특정 시간에 Glue Data Crawler가 작동하여 S3 위치를 순회하며 DB 스냅샷을 조사하고 스키마 변경사항을 Glue Data Catalog에 갱신합니다.
2.2. AWS Glue ETL Job
스냅샷 데이터는 비압축 원본 기준 평균 50GB 상당입니다. 예약 · 상품 · 채널에 걸친 복수 테이블은 일괄적인 정제 및 상호 조인 작업이 필요합니다. 이러한 요구를 AWS Glue Studio의 시각적 ETL 작업에서 지원하는 인터페이스와 작업 노드로 처리하여 컬럼 선택, 타입 캐스팅, 정규화, 테이블 조인을 구현했습니다.
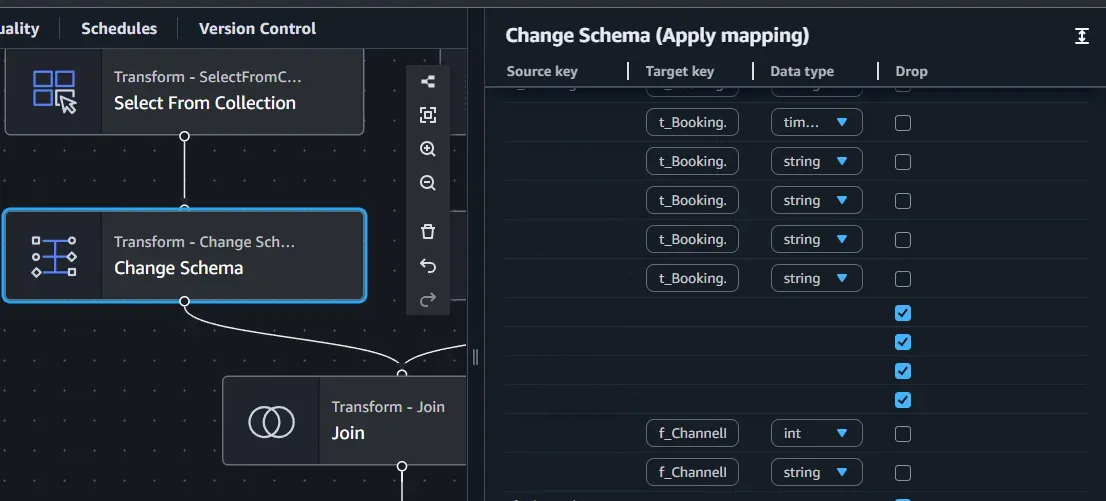
호텔 예약 분석에서 날짜 범위 필터가 자주 쓰이기 때문에, 예약일 기준 ‘연, 월, 일’ 로 파티션 키를 지정하여 year=YYYY/month=MM/day=DD 디렉토리 구조로 Parquet 파일이 분산 저장되도록 했습니다. 파티셔닝은 Athena 를 통한 S3 스캔 데이터량을 크게 줄여주어 쿼리 비용과 응답 속도를 개선합니다.
def MyTransform(glueContext, dfc) -> DynamicFrameCollection:
"""
예약 데이터에 날짜 파티션 컬럼 추가하는 Glue 변환 함수
f_BookingDate 컬럼에서 year, month, day 파티션 컬럼을 생성
"""
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import date_format
# DynamicFrame을 Spark DataFrame으로 변환
df = dfc.select(list(dfc.keys())[0]).toDF()
# 예약일(f_BookingDate)에서 파티션 컬럼 생성
df = df.withColumn('year', date_format('Date Column', 'yyyy')) \\
.withColumn('month', date_format('Date Column', 'MM')) \\
.withColumn('day', date_format('Date Column', 'dd'))
# DynamicFrame으로 변환 후 반환
result_frame = DynamicFrame.fromDF(df, glueContext, "partitioned_booking_data")
return DynamicFrameCollection({"CustomTransform": result_frame}, glueContext)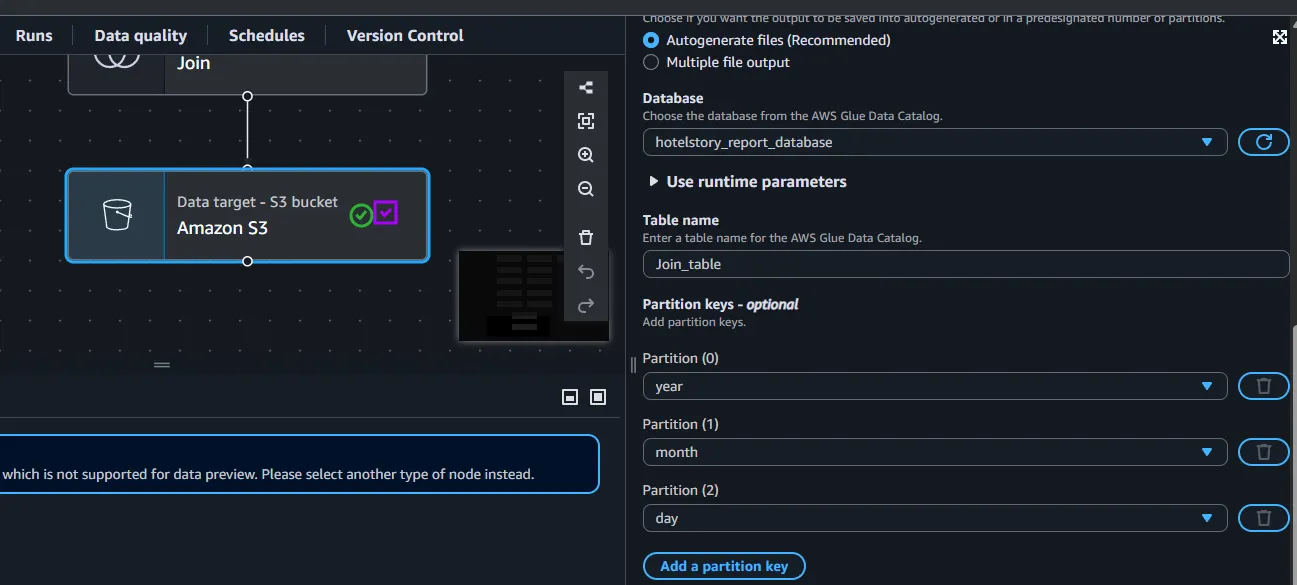
테스트 초기, 호텔스토리는 전처리 없는 작은 원본 데이터(170 MB)를 QuickSight 에 올려 검증하면서 SPICE 적재 용량이 50GB 가까이 불어나는 불편함을 겪었습니다. 이는 수 차례의 테이블 조인과, 이로인해 배가되는 컬럼 수가 야기한 것입니다.
Glue ETL 작업을 통해 컬럼 타입을 최적화하고 문자열 컬럼을 선별하여 현상을 해결할 수 있었습니다. 그리하여 SPICE 용량이 10~15GB 즉, 70~80% 수준으로 절감되었고 QuickSight 에서의 데이터 새로고침과 대시보드 로딩 속도 역시 개선되었습니다.
3. Amazon Q in QuickSight – 매출 데이터 스토리
HotelStory는 Q in QuickSight 를 중점으로 BI 도구를 제공하는 전략을 택했습니다. 세일즈 팀이 자연어로 구사한 광범위한 질문에, 생성형 어시스턴트가 필요한 지표를 집계하고 맥락 있는 서술형 인사이트(데이터 스토리)를 제공합니다. 덕분에 월간 매출이나 채널별 실적 같이 주기적인 확인이 필요한 지표를 개발실 개입 없이 신속하게 획득 가능합니다.
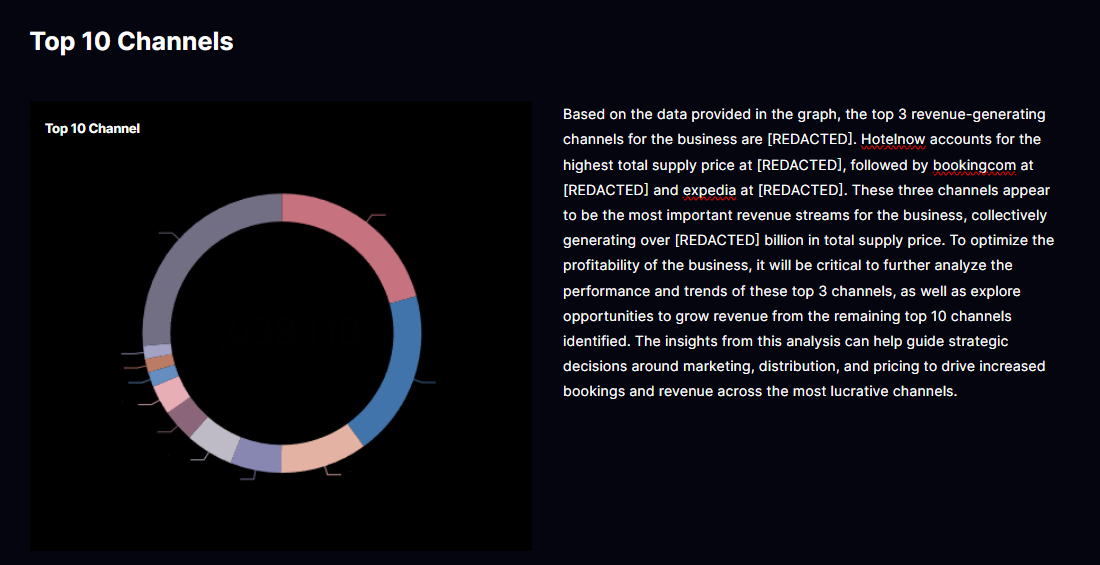
3.1. 채널별 매출 기여도: Top 10 Channels
이 데이터 스토리는 매출 누계에 따른 상위 채널을 한눈에 제시합니다. 최근 분석에서, 글로벌 상위 채널 세 곳이 전체 매출에 높은 비중을 차지함이 드러났습니다. 이러한 기여도 분석은 채널 마케팅/프로모션 배분, 채널 수수료, 채널별 가격 전략을 정하는 근거가 됩니다. 상위 채널의 성장 추세와, 하위 채널의 개선 여지를 함께 추적함으로써 채널 혼합 최적화가 가능합니다.
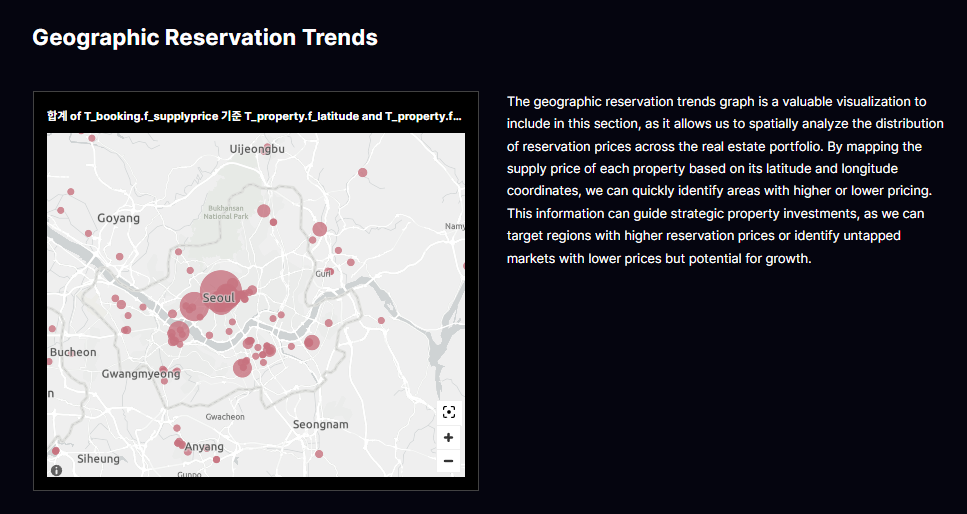
3.2. 지역별 예약 분포: Geographic Reservation Trends
숙소 위치(위 · 경도) 기반으로 예약 분포를 비교합니다. 특정 권역에서 가격이 높은데도 예약이 꾸준하다면, 지역 유형(도심 · 해변 · 관광지), 숙소 등급, 주요 편의시설과의 상관관계를 추가 분석해 가격 정책과 투자 우선순위를 고민할 수 있습니다. 이와 반대로, 가격은 낮지만 수요가 탄탄한 미개척 권역은 재고 확장이나 프로모션 테스트 후보가 됩니다.
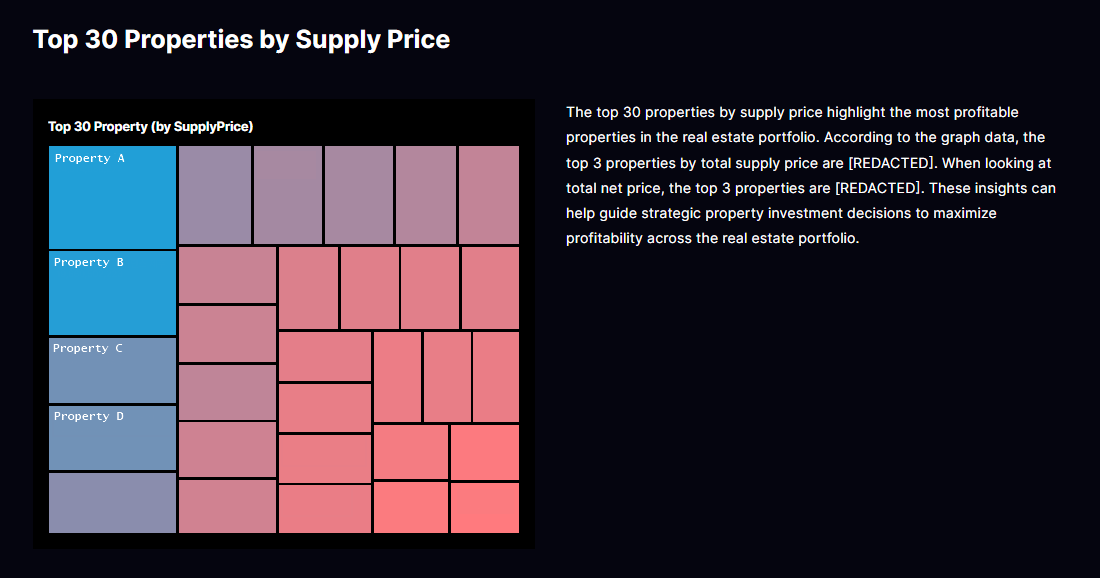
3.3. 숙소 매출 상위: Top Properties
순매출 상위 숙소를 비교합니다. 숙소별 객단가(ADR), 점유율, 마진율을 교차분석하면, 높은 점유율을 유지하면서도 가격 인상 여력이 있는 지점을 식별할 수 있습니다. 이와 반대로 점유율은 높지만 수익성이 낮은 숙소는 고객 이탈 리스크를 최소화하면서 수익을 개선하기 위해 패키지 구성을 절감하는 리디자인을 고려할 수 있습니다.
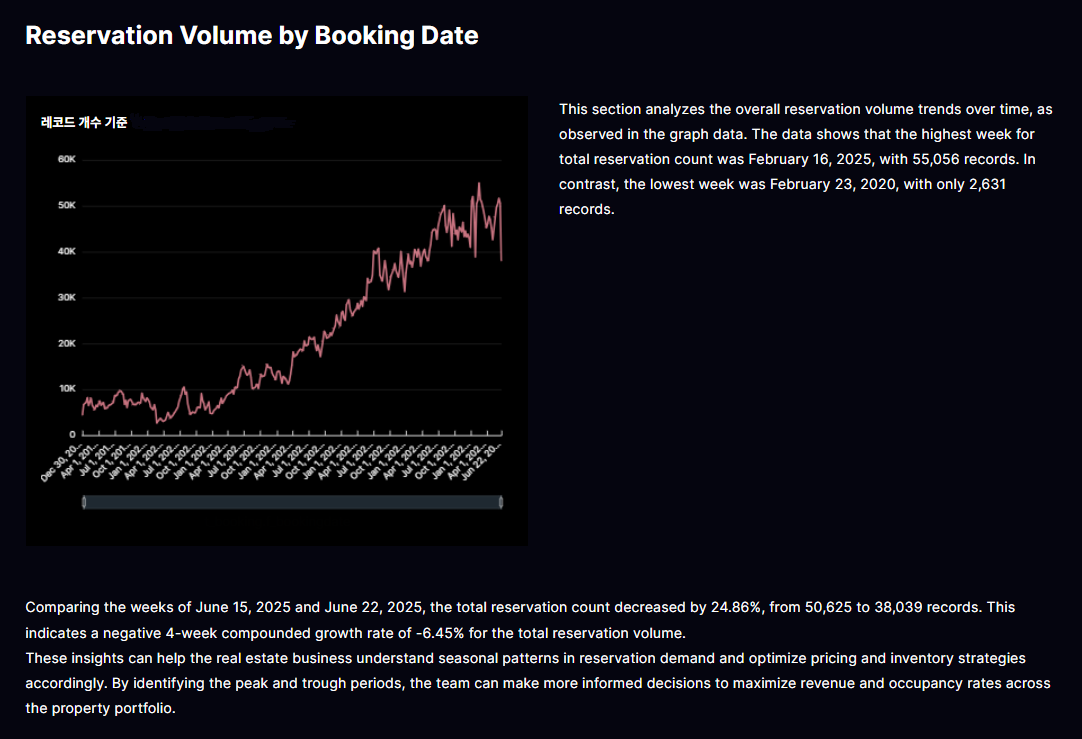
3.4. 예약 트렌드 (주차/월차) : Reservation Volume by Booking Date
정기적인 예약 추세를 살펴봅니다. 예약 건이 많고 적은 주(week)가 나타나며, 성수기 · 비수기 패턴과 단기 변동을 체크할 수 있습니다. 프로모션 시점, 리드타임 기반의 탄력적 요금 조정, 인력 및 재고 배치와 관련한 운영 의사결정을 지원합니다.
4. Amazon Q in QuickSight – 객실가 시나리오 분석
호텔스토리는 AI 에이전트와 대화 방식으로 광범위한 데이터를 드릴다운하여, 세일즈 팀 요구에 맞는 인사이트와 보조 차트를 제공하는 시나리오 분석도 도입하였습니다. 아래는 특정 객실 유형에 관해 심층적인 분석을 진행한 실제 시나리오 흐름입니다.
4.1. 객단가 추세 확인 – “현상 파악”
첫 질문은 특정 객실의 기간별 ADR(객단가) 추세를 빠르게 훑어보는 것입니다.
- 질문: 2025년 7월 1일부터 7월 15일까지
객실 유형 208399의 ADR 을 보여주세요. - 결과: 지정기간 해당 객실 ADR은
₩144,511 ~ ₩257,763범위입니다. 최고 ADR은 7월 4일₩257,763, 최다 객실 판매는 7월 5일,19박입니다. 일부 날짜의 ADR이null로 표시되지만 이는 예약 없음으로 처리하며 평균 계산에서 제외했습니다.
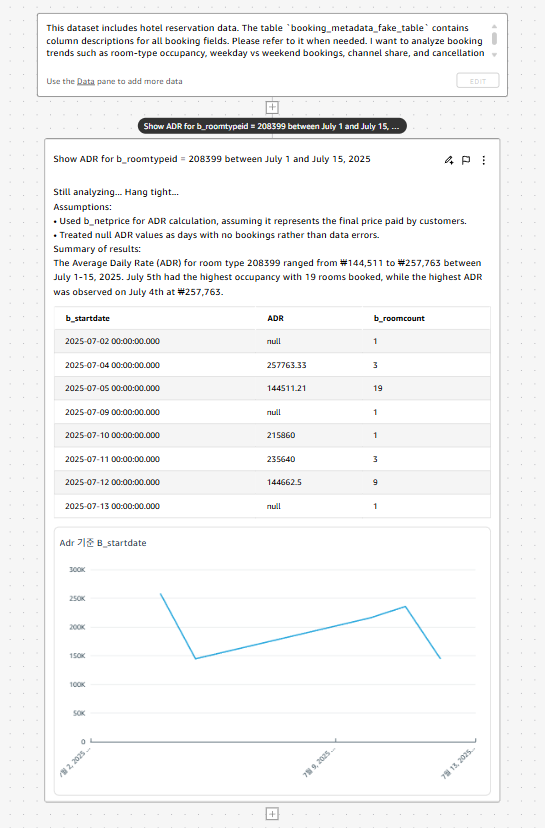
이 단계는 객단가 추세를 빠르게 파악하고 추가로 파고들 지점을 가늠하는 출발선입니다. Q in QuickSight 는 곧바로 시각 근거와 인사이트 요약을 제공하므로 탐색 속도가 비약적으로 빨라집니다.
4.2. 유효 예약 기반 재산출 – “왜곡 제거”
- 질문: 2025년 7월 1일부터 7월 15일까지
객실 유형 208399의 평균 ADR을 보여주세요.순 가격 = 0또는객실 수= 0인 예약은 제외합니다. - 결과: 지정기간 해당 객실의 평균 ADR은
₩169,259.9, 총 판매 객실은24박입니다. 일자별 ADR은₩144,511.2 ~ ₩257,763.3범위로 관측됩니다.
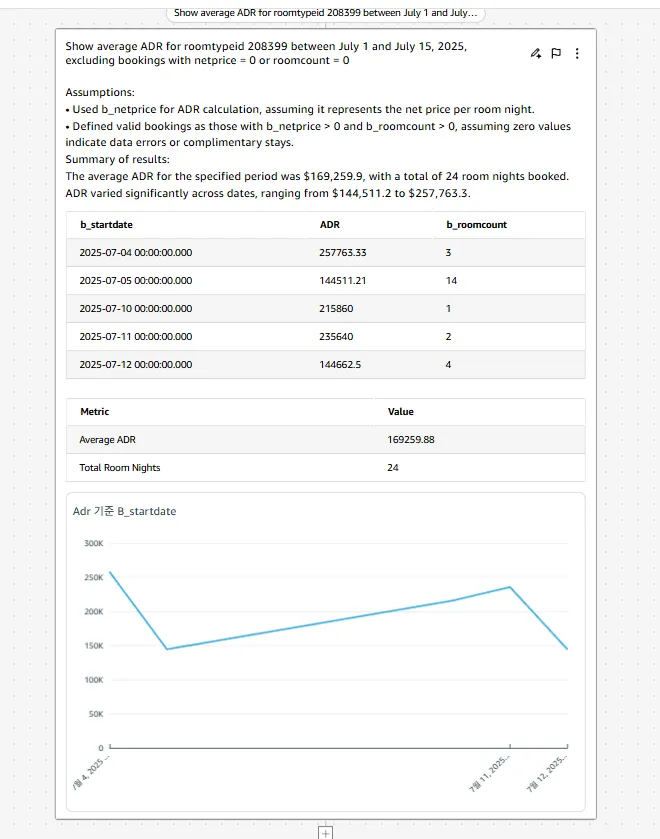
이 단계에서 이상치와 무의미한 예약을 제거해 의사결정에 적합한 실제 단가 신호를 얻을 수 있습니다. 필터를 한 줄 추가하는 것만으로 평균과 분포가 현상을 더 정확히 반영하며, 이후 가격 바닥 · 천장 재설정, 프로모션 효과 판독, 채널별 단가 비교와 같은 후속 분석이 신뢰성 있게 이어집니다.
4.3. 전체 기간 분석 – “정책 프레임”
마지막으로 질문의 범위를 전체 가용 기간으로 확장해 계절성과 가격 밴드를 확인했습니다.
- 질문: 모든 날짜에 대해
객실 유형 208399의 평균 ADR을 보여주세요.순 가격 = 0또는객실 수 = 0인 예약은 제외합니다. - 결과: 2025년 1월-7월 구간 109개 관측 일자가 존재합니다. ADR은
₩48,840 ~ ₩456,705로 나타나고, 전체 평균은₩179,979입니다. 주/월 단위로 가격 편차와 시즌성이 뚜렷하게 확인됩니다.
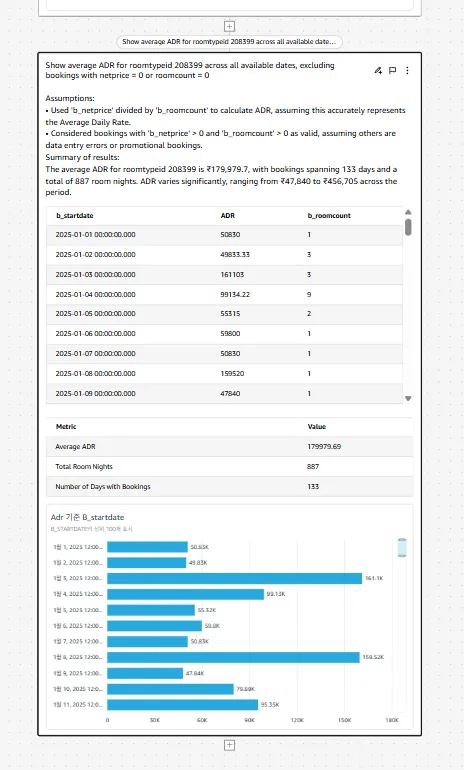
이 단계에서 우리는 해당 객실의 “가격 바닥과 천장”을 설정하고, “성수기 및 어깨 구간에서 얼마나 공격적인 가격 책정이 가능한지” 정책 프레임을 잡을 수 있습니다. 한 번 만든 시나리오는 객실유형과 기간만 바꿔 다른 객실에 재사용할 수 있습니다.
5. Amazon Q in QuickSight – 외국인 선호 시나리오 분석
Q in Quicksight 는 자연어 질의의 연속성과 세분화된 통계 비교를 한 흐름으로 이어 주는 것이 강점입니다. 이번 시나리오는 “외국인 고객이 국내 고객보다 체류가 더 긴가?”라는 질문에서 시작해, 체류일(LOS) 계산 → 국적별 비교 → 후속 KPI 탐색으로 확장하는 과정을 보여줍니다
5.1. 전체 예약의 체류일(LOS) 계산 – 공통 기준선 만들기
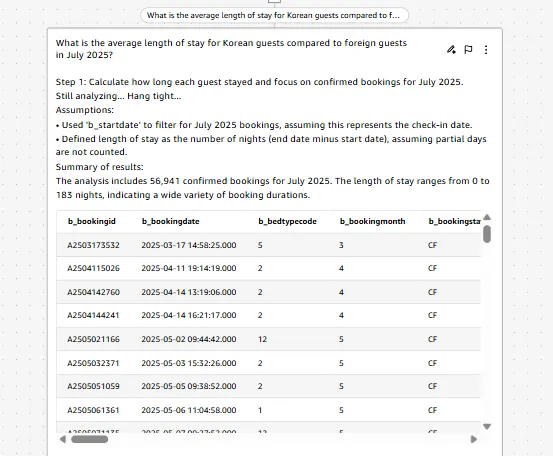
- 질문: 모든 예약의 체류일을 보여주세요.
- 결과: 체크인/체크아웃을 기준으로 LOS가 계산되어 분포와 요약 통계가 생성됨
이 단계는 이후 있을 모든 분석의 기준선을 세우는 과정입니다. 운영 측면에서 LOS 값은 프런트 인력 배치, 객실 회전, 장기 숙박 상품 설계시 근거가 됩니다. LOS를 고정해 국적 · 채널 · 숙소별 후속 분석을 진행하면 동일한 잣대로 의미를 해석할 수 있습니다.
5.2. 국적 기준 체류일(LOS) 비교 – 외국인 선호도 파악
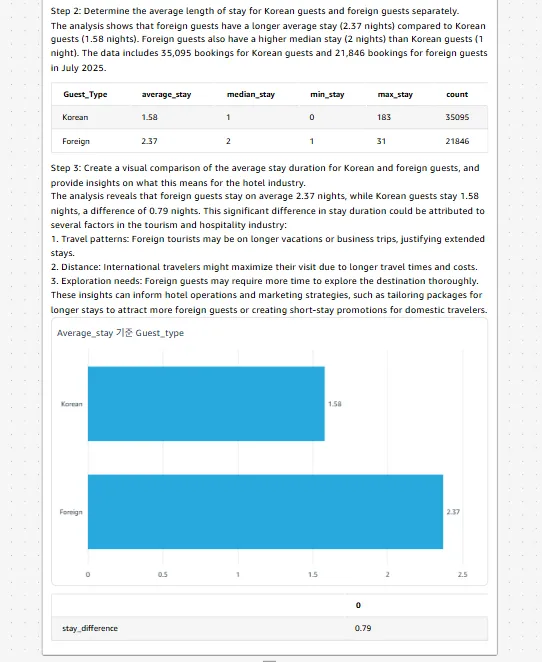
- 질문: 2025년 국적별 체류일 평균과 중위값을 보여주세요.
netprice > 0 AND roomcount > 0조건을 적용해 유효 예약만 판단합니다. - 결과: 외국인 투숙객의 체류일이 국내 고객보다 길게 나타남
외국인 고객은 객실 박수를 더 많이 소비하므로, 예약 건수 비해 Room Nights 수에 높이 기여합니다. 따라서 LOS 가 높이 나타나는 것으로 추정 가능합니다. 마케팅 측면에서는 외국인 대상 3, 5, 7박 번들, 공항 이동&투어 번들, 다국어 캠페인 같은 장기 체류 중심 전략이 적합합니다.
반면 국내 고객군에게는 주말·단기 특가, 업셀 패키지가 효과적입니다. 가격 전략은 LOS 구간별 ADR/할인율 정책을 마련해 탄력적으로 운영하는 것이 바람직합니다.
6. 시나리오 분석에서 발견한 효과
시나리오 분석은 동일한 맥락안에서 질문만 바꿔가며 빠른 인사이트 탐색을 가능하게 해주었습니다. 매번 새로운 시각 차트나 필터 구성을 추가할 필요 없이, 한 화면에서 원하는 데이터를 자연어로 요청해 곧장 비교가 가능합니다. 예를 들어, 이상치 제거 전과 후를 연속으로 대조하면서 향상되는 데이터 품질을 확인할 수 있었습니다. 이제는 세일즈 팀 스스로 데이터를 질의 · 검증 · 공유하는 프로세스가 자리잡았고, 개발실 의존이 크게 낮아지게 되었습니다.
최종 결과
수요 모니터링/예측 대시보드
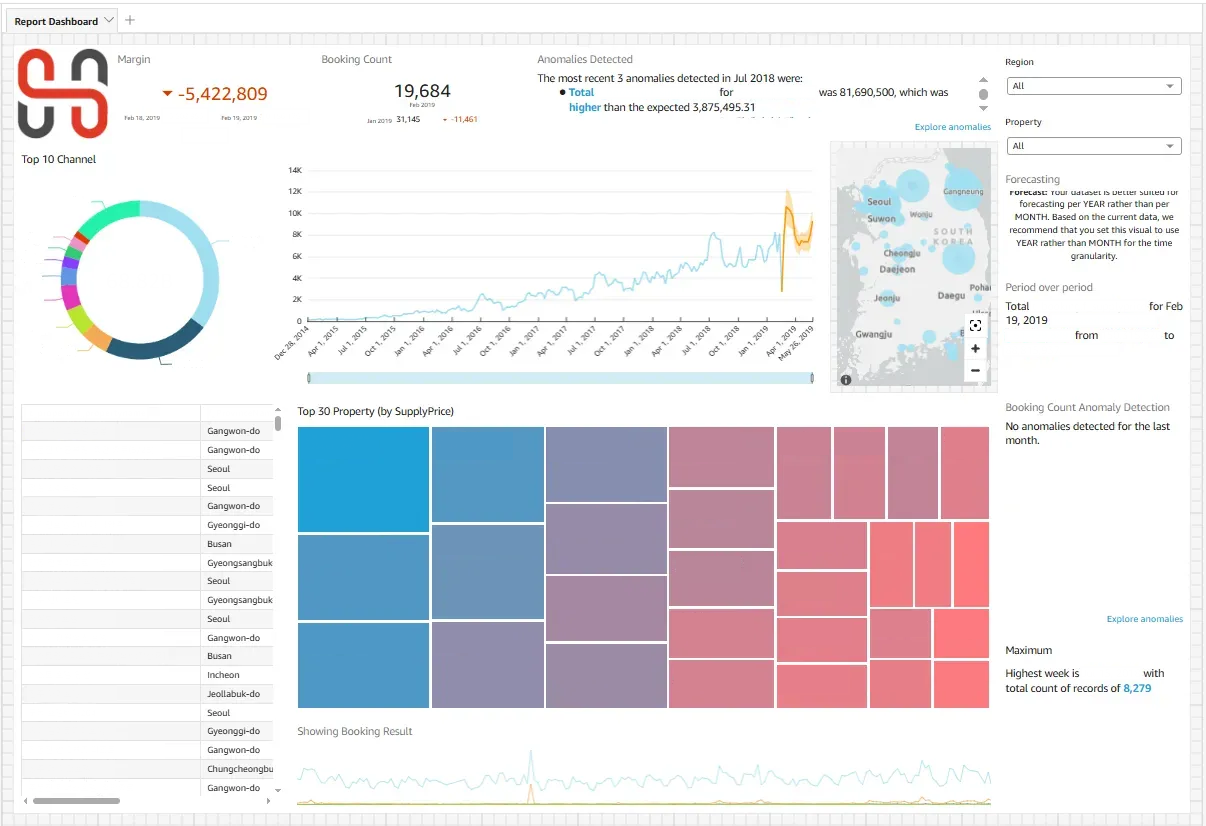
호텔스토리의 수요 모니터링/예측 대시보드는 세일즈, 마케팅, 운영 리더들이 일일 헬스체크와 주간 리뷰에 활용하는 핵심 운영 도구입니다. 상단 KPI 카드(누적 마진, 예약 수, 이상값 감지 요약)부터 채널별 매출 기여도 도넛차트, 시계열 예약 추이와 예측 오버레이, 지역별 수요 분포 지도, 숙소 성과 트리맵까지 포괄적인 비즈니스 인사이트를 한 화면에 제공합니다.
이 대시보드를 통해 운영팀은 전일 대비 이상 징후를 즉시 파악하고 원인을 채널, 숙소, 지역별로 드릴다운하여 분석할 수 있습니다. 채널별 기여도와 상위 숙소 성과를 근거로 프로모션 예산과 재고 우선순위를 조정하며, 예측 데이터와 시즌성 분석을 바탕으로 요금 정책과 캠페인 타이밍을 최적화합니다.
더 심층적인 질문이 필요한 경우 Q in QuickSight의 자연어 질의 기능으로 즉석에서 추가 분석을 수행할 수 있어, 데이터 기반 의사결정의 속도와 정확성을 크게 향상시켰습니다.
객실 공급가 모니터링 대시보드
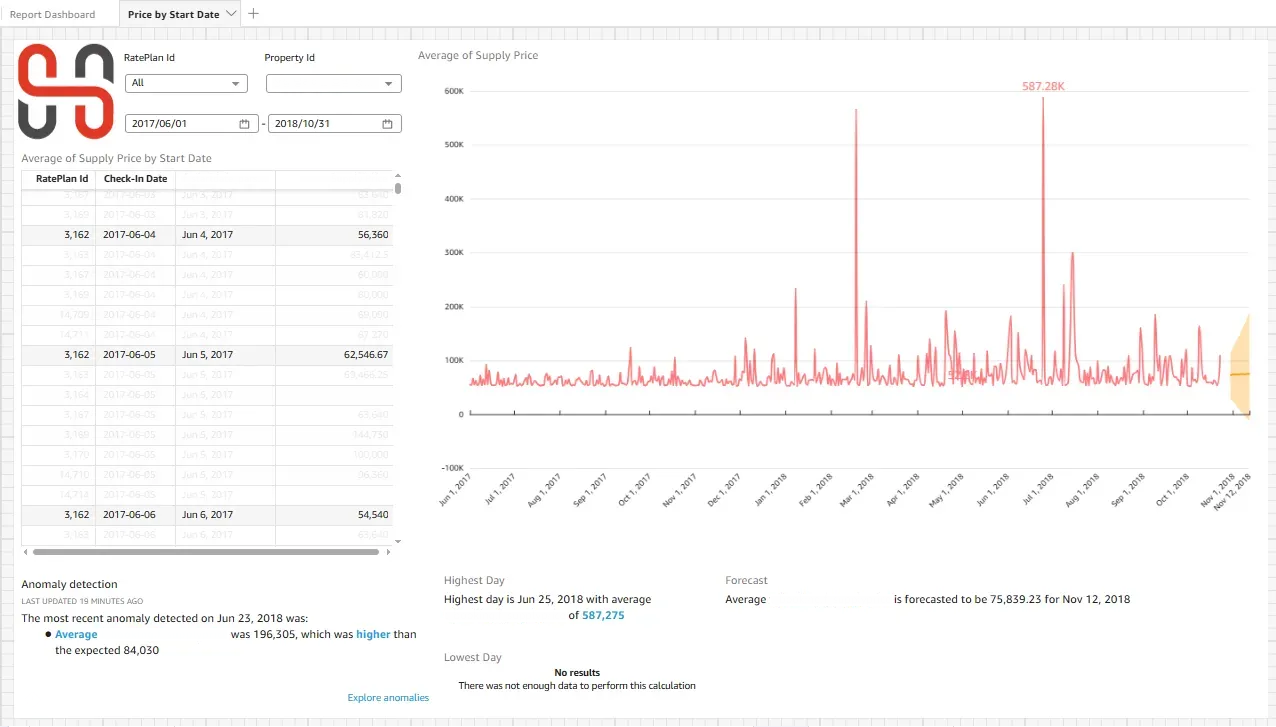
호텔스토리의 객실 공급가 모니터링 대시보드는 세일즈 담당자가 일 · 주 단위 헬스체크와 가격 조정 및 판매 촉진을 위해 활용하는 도구입니다. 상단 시계열 라인차트를 통해 일자별 평균 공급가 흐름을 추적하고, 음영 구간의 예측 범위로 가까운 미래의 예상 가격대를 확인할 수 있습니다. 이상치 자동 감지 기능은 예상치 대비 급등/급락을 요약하여 “왜 가격이 튀었는가?”에 대한 즉각적인 인사이트를 제공하며, 최고/최저가 일자 요약과 상품별 세부 테이블을 통해 피크/저점 원인을 심층 분석할 수 있습니다.
이 대시보드의 핵심 가치는 적정 가격대(Price Band) 산정을 위한 데이터 기반 근거 제공에 있습니다. 세일즈팀은 최근 N주/N개월의 평균 가격 트렌드와 변동 폭을 통해 현재 베이스라인을 설정하고, 이상치 감지로 표시된 급등/급락 구간의 원인을 분석하여 정책 외 이벤트(프로모션, 단체행사, 데이터 보정)를 식별합니다.
이를 통해 의사결정 시간을 단축하고, 이상 대응 속도를 향상시키며, 운영 우선순위를 명확화하여 리소스를 효율적으로 배분할 수 있게 되었습니다.
Amazon QuickSight 도입 효과
호텔스토리는 예측형 수요 모니터링과 공급가 모니터링 대시보드 도입을 통해 데이터 기반 운영의 혁신적 변화를 경험했습니다. 기존 수작업 리포트 작성에 소요되던 며칠의 분석 시간이 몇 분으로 단축되었으며, 이상 탐지와 데이터 스토리 기능이 “언제/어디서/무엇이 달랐는지”를 자동으로 문장화하여 이상 징후에 대한 즉시 액션이 가능해졌습니다.
더욱 중요한 것은 하나의 통합 화면에서 핵심 KPI부터 채널별 기여도, 숙소별 성과, 지역별 분포까지 동시에 점검할 수 있게 되어 운영 우선순위가 명확해졌다는 점입니다. 트리맵과 도넛차트를 통해 상위 성과군을 빠르게 식별하고 리소스(예산/인력/재고)를 집중할 수 있게 되었으며, Q in QuickSight 시나리오 분석으로 즉각적인 심층 분석을 요청하여 데이터 전문 지식 없이도 복잡한 비즈니스 인사이트를 도출할 수 있게 되었습니다.
요약
호텔스토리는 AWS Data Lab 프로그램을 통해 3주간의 집중 스프린트로 생성형 BI 셀프 서비스 환경을 성공적으로 구축했습니다. 기존 개발실에 의존하던 데이터 분석 프로세스를 Amazon Q in QuickSight 기반의 자연어 질의 환경으로 전환하여, 비즈니스 팀이 직접 데이터를 탐색하고 인사이트를 도출할 수 있는 혁신적인 변화를 달성했습니다.
핵심 아키텍처는 RDS 스냅샷 → S3 Export → Glue ETL → Athena → QuickSight 파이프라인으로 구성되며, 운영 DB 부하 최소화와 비용 효율성을 동시에 고려했습니다. 특히 데이터 전처리시 날짜 기반 파티셔닝과 Parquet 최적화를 통해 SPICE 용량을 70-80% 절감하고 쿼리 성능을 대폭 개선했습니다.
주요 성과
이번 프로젝트를 통해 달성한 구체적인 성과는 다음과 같습니다.
- 운영 DB 부하를 최소화하는 스냅샷 기반 분석 아키텍처
- 비즈니스 용어를 표준화한 Q 시나리오 분석을 통해 “질문 → 지표”를 빠르게 연결
그 결과, 다음과 같은 개선을 달성했습니다.
- 분석 응답 시간 단축: 반복적인 애드혹 요청이 줄고 요청-응답 리드타임이 일 단위에서 분 단위로 단축되었습니다.
- 운영 효율성 향상: Glue 전처리와 파티션 전략 덕분에 SPICE 용량을 70-80% 절감하고 쿼리 성능을 대폭 개선했습니다.
- 실시간 의사결정 지원: Q의 데이터 스토리, 시나리오 분석 및 예측 기능으로 가격 및 재고 정책 실험과 예약 이상 탐지를 더 기민하게 수행할 수 있었습니다.
- 셀프 서비스 BI 실현: 비즈니스 팀이 개발실 의존 없이 자연어로 데이터 분석을 수행할 수 있게 되었습니다.
결론
HotelStory는 AWS 기반 데이터 파이프라인과 생성형 BI를 결합하여 데이터 기반 의사결정 환경을 성공적으로 구축했습니다. 특히 Amazon Q in QuickSight를 활용한 자연어 기반 분석 환경은 비즈니스 팀의 데이터 접근성을 획기적으로 개선했습니다.
HotelStory는 앞으로도 생성형 AI를 적극적으로 활용해, 누구나 데이터로 빠르게 결정하는 경험을 확장해 나가겠습니다. 이번 사례가 호스피탈리티 업계뿐만 아니라 데이터 기반 의사결정 환경 구축을 고민하고 있는 다른 조직들에게 실질적인 도움이 되기를 바랍니다.