AWS 기술 블로그
Amazon Aurora PostgreSQL과 RDS PostgreSQL 환경에서 TOAST OID 충돌로 인한 성능 저하 현상의 진단 및 해결 방안
이 글은 AWS Database Blog에 게시된 Identifying and resolving performance issues caused by TOAST OID contention in Amazon Aurora PostgreSQL Compatible Edition and Amazon RDS for PostgreSQL을 한국어 번역 및 편집하였습니다.
PostgreSQL에서 데이터 저장은 다양한 메커니즘을 통해 최적화하는 것 중 하나가 TOAST(The Oversized-Attribute Storage Technique)입니다. 이 메커니즘은 대용량 데이터 타입을 별도의 테이블로 이동시켜 효율적으로 저장하는 데 도움을 줍니다. TOAST는 데이터베이스 아키텍처의 필수적인 부분이지만, 때때로 예상치 못한 성능 문제를 일으킬 수 있으며, 특히 기본 객체 식별자(OID)가 최대 한계에 접근할 때 그렇습니다. OID 공간이 부족해지면 PostgreSQL은 새로운 행에 대해 새로운 OID를 할당하는데 어려움을 겪으며, INSERT(또는 UPDATE)와 같은 작업이 현저히 느려집니다.
이 게시물에서는 PostgreSQL의 OID 고갈 문제를 탐구하며, TOAST 테이블에 미치는 영향과 성능 문제를 야기하는 방식에 중점을 둡니다. 대기 이벤트, 세션 활동, 테이블 사용량을 검토하여 문제를 식별하는 방법을 다룰 것입니다. 또한 데이터 정리부터 파티셔닝과 같은 고급 전략까지 실용적인 해결책을 논의합니다.
OID란 무엇인가?
OID는 PostgreSQL이 테이블, 인덱스, 함수 등과 같은 데이터베이스 객체를 참조하기 위해 사용하는 시스템 전체 고유 식별자입니다. 이러한 식별자는 PostgreSQL의 내부 작업에서 중요한 역할을 하며, 데이터베이스가 객체를 효율적으로 찾고 관리할 수 있게 해줍니다.
PostgreSQL에서 TOAST 이해하기
TOAST는 표준 데이터베이스 페이지(일반적으로 8KB 크기)에 맞지 않는 TEXT, BYTEA, JSON과 같은 대용량 데이터 타입을 효율적으로 처리하는 PostgreSQL의 방법입니다. 대용량 값을 메인 테이블에 직접 저장하는 대신, PostgreSQL은 TOAST된 데이터를 위해 특별히 지정된 별도의 테이블에 저장합니다.
TOAST는 압축을 수행하고 대용량 필드 값을 라인 밖에 저장합니다. 2KB를 초과하는 필드 값(toast_tuple_target을 통해 조정 가능)은 크기를 줄이기 위해 구성 가능한 알고리즘(예: pglz)을 사용하여 압축됩니다. default_toast_compression 매개변수를 통해 압축 알고리즘을 구성할 수 있습니다. 압축만으로 충분하지 않은 경우, 값은 2KB 청크로 분할되어 TOAST 가능한 컬럼이 있는 테이블에 대해 자동으로 생성되는 별도의 TOAST 테이블에 저장됩니다. 메인 테이블에서 이러한 대용량 필드는 청크를 참조하는 작은 TOAST 포인터로 대체됩니다.
기본적으로 TOAST는 압축과 라인 밖 저장을 모두 가능하게 하는 EXTENDED 저장 전략을 사용합니다. pg_type의 typstorage 컬럼은 각 컬럼의 저장 방법을 결정합니다. MAIN, PLAIN, EXTERNAL과 같은 다른 전략을 선택하여 특정 컬럼에 대한 TOAST 동작을 수정할 수 있습니다. 예를 들어, PLAIN은 컬럼에 대해 TOAST를 완전히 비활성화하고, EXTERNAL은 압축 없이 데이터를 라인 밖에 저장합니다. 이 과정은 사용자에게 투명하며 기본적으로 활성화됩니다. TOAST 테이블은 TEXT, BYTEA, JSONB와 같은 데이터 타입의 컬럼을 포함하는 테이블에 대해 자동으로 생성됩니다.
TOAST에 적합한 데이터 세트가 있는 테이블의 경우, 연관된 TOAST 테이블에 저장된 각 초대형 데이터 청크를 고유하게 식별하기 위해 OID가 할당됩니다. 각 청크는 chunk_id와 연관되어 있으며, 이는 PostgreSQL이 TOAST 테이블 내에서 청크를 효율적으로 구성하고 찾는 데 도움을 줍니다.
OID 할당의 성능 문제
TOAST는 별도의 테이블에 저장된 대용량 라인 밖 데이터를 추적하기 위해 OID를 사용합니다. 그러나 PostgreSQL의 OID 시스템에는 근본적인 제한이 있습니다—최대 40억 개의 OID(2^32)만 처리할 수 있습니다. TOAST 테이블이 증가하고 더 많은 데이터가 저장되면서 사용 가능한 OID가 고갈되기 시작합니다. 이것이 발생한 후 PostgreSQL은 상당한 문제에 직면합니다:
- 해제된 OID 재사용 : PostgreSQL은 이전에 삭제되거나 업데이트된 데이터의 OID를 재사용하려고 시도합니다. 이론적으로는 작동할 수 있지만 항상 효율적이지는 않습니다.
- OID 검색 루프 : 해제된 OID가 충분한 간격을 제공하지 않거나 사용 중인 OID가 너무 많은 경우, PostgreSQL은 사용 가능한 OID를 찾으려고 시도하면서 검색 루프에 갇힐 수 있습니다. 이러한 철저한 검색은 PostgreSQL이 사용 가능한 OID를 찾는 데 점점 더 많은 시간을 소비하면서 TOAST 컬럼이 있는 테이블의 삽입 작업을 극도로 느리게 만들 수 있습니다.
이러한 사용 가능한 OID 검색은 특히 데이터를 TOAST해야 하는 삽입 중에 상당한 성능 병목 현상을 야기합니다. TOAST 테이블에 데이터가 많을수록 OID 고갈이 발생할 가능성이 높아지며, 삽입 작업에 지연이 발생합니다. 테이블이 상당히 크게 증가하거나 대용량 객체를 저장하는 대규모 프로덕션 시스템에서는 OID 고갈 문제가 더욱 두드러지며, 특히 TOAST 메커니즘이 해당 사용 사례에 최적화되지 않은 경우 그렇습니다. 이 문제로 인한 성능 병목 현상을 피하기 위해 사전 예방적 조치를 취하는 것이 중요합니다.
OID 고갈의 증상
PostgreSQL이 TOAST 테이블의 OID 고갈로 인해 성능 저하를 경험할 때, 증상은 일반적으로 새로운 행 삽입과 같은 겉보기에 간단한 작업을 통해 나타납니다. 일반적으로 빠른 작업이었던 것이 상당히 오래 걸립니다. OID 고갈이 데이터베이스에 영향을 미치기 시작할 때 관찰할 수 있는 것은 다음과 같습니다 :
- 간단한
INSERT가 이제 완료하는 데 훨씬 더 많은 시간이 걸립니다. - 각
INSERT에 소요되는 시간이 다양할 수 있으며, 때로는 빠르게 실행되고 때로는 훨씬 더 오래 걸립니다. - 지연은
INSERT가 TOAST된 데이터를 포함할 때만 발생합니다. TOAST 없는 일반적인 삽입은 예상대로 진행됩니다. - 다음 로그 항목이 이 문제 중에 나타날 수 있지만, 이러한 로그 항목이 없어도 성능 저하가 발생할 수 있습니다. 다른 증상이 문제 설명과 일치한다면 이러한 로그 항목의 존재와 관계없이 문제 식별을 진행하십시오.
OID 고갈 식별
느린 삽입과 불규칙한 지연 패턴을 발견했을 때, 근본 원인을 확인하고 싶을 것입니다. TOAST 테이블 OID 고갈은 진단하기 까다로울 수 있지만, 모니터링 도구를 사용하여 이것이 실제로 직면하고 있는 문제인지 확인할 수 있습니다.
1단계: 활성 세션 조사
모든 PostgreSQL 세션의 현재 활동을 보여주는 pg_stat_activity 뷰를 확인하는 것부터 시작하십시오. 느린 삽입을 경험하고 있다면, 다음 쿼리를 실행하여 LWLock:buffer_io 또는 LWLock:OidGenLock와 같은 이벤트를 대기하고 있는 활성 세션을 식별하십시오:
Sample output:
많은 세션이 LWLock:OidGenLock을 대기하고 있다면, 이는 PostgreSQL이 새로운 OID를 생성하는 데 어려움을 겪고 있다는 강력한 징후입니다.
2단계: Database Insights 확인
대기 이벤트 LWLock:buffer_io와 LWLock:OidGenLock은 새로운 OID 할당이 필요한 작업 중에 Performance Insights에 나타납니다. 이러한 이벤트에 대한 높은 평균 활성 세션(AAS)은 일반적으로 OID 할당과 관련 리소스 관리 중의 경합을 가리키며, 특히 높은 데이터 변동, 광범위한 대용량 객체 사용 또는 빈번한 객체 생성이 있는 환경에서 그렇습니다.
Database Insights의 몇 가지 예:
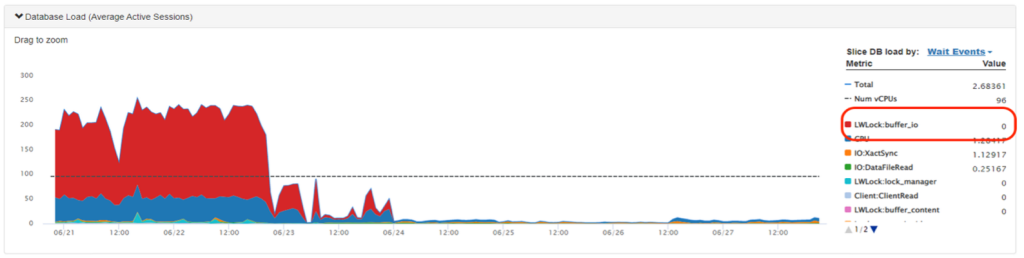
다음 그림은 공유 버퍼에서 I/O 작업을 대기함을 나타내는 LWLock:buffer_io를 보여줍니다. 높은 발생률은 디스크 병목 현상이나 과도한 I/O를 시사할 수 있으며, 이는 대용량 TOAST 인덱스와 OID 고유성 검사와 관련이 있을 수 있습니다.
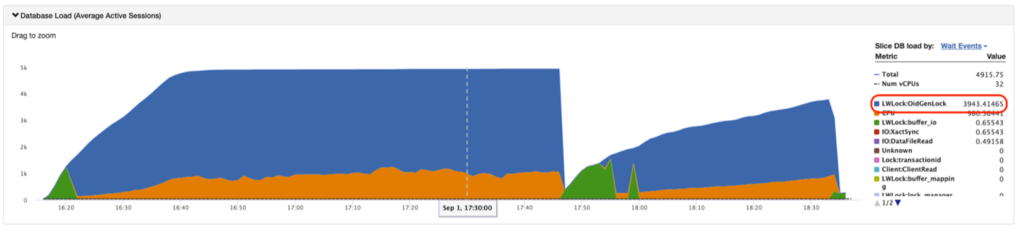
다음 그림은 새로운 OID 할당을 대기함을 보여주는 OidGenLock을 나타냅니다. 여기서의 높은 경합은 동시 TOAST 작업, 빈번한 객체 생성 또는 과도한 시스템 카탈로그 활동으로 인해 발생할 수 있습니다.
3단계: TOAST 테이블 크기 및 OID 사용량 확인
OID 고갈이 원인일 가능성을 확인한 후, TOAST 테이블을 직접 검사하십시오. 다음 쿼리를 사용하여 해당 테이블이 TOAST를 사용하는지 확인하고 테이블 크기의 개요를 얻으십시오:
샘플 출력:
테이블의 크기를 확인하십시오. 눈에 띄게 매우 클 것입니다. \dt+ test_table 샘플 출력:
이 경우 테이블이 12TB이며, 이는 TOAST 테이블이 상당한 양의 데이터를 저장하고 있을 수 있음을 시사합니다. 다음으로, TOAST 테이블 내의 현재 OID 사용량을 확인하십시오. OID 개수가 최대 한계(40억)에 가깝다면, 이는 잠재적인 OID 고갈의 명확한 징후입니다. TOAST 테이블의 레코드 수에 따라 이 쿼리는 시간이 걸릴 수 있으므로, 그에 따라 기대치를 설정하는 것이 중요합니다.
샘플 출력:
이 예시에서 OID 개수는 4,293,066,164로, 40억의 OID 한계에 매우 가깝습니다.
마지막으로, 다음 쿼리를 실행하여 TOAST 테이블에서 사용된 최대 OID를 확인하십시오:
샘플 출력:
최대 청크 ID가 40억에 가깝다면, 이는 OID 공간이 고갈되었거나 매우 가까워졌다는 강력한 징후입니다.
MAX(chunk_id)가 40억에 가까운 것을 보는 것이 문제의 징후이지만, 반드시 문제가 임박했다는 의미는 아닙니다. toast 레코드가 삭제될 때 OID가 해제될 수 있으므로, 시스템이 한계에 근접하고 있는지 확인하기 위해 고유한 청크 ID의 총 개수를 확인하는 것이 더 정확합니다.
TOAST 테이블의 OID 고갈 해결책
TOAST 테이블의 OID 고갈에 직면했을 때, 즉각적인 수정부터 장기적인 전략까지 문제를 완화하는 여러 가지 방법이 있습니다. 단기적인 해결책은 일시적인 완화를 제공할 수 있지만, 파티셔닝과 같은 장기적인 접근 방식이 가장 확장 가능한 옵션을 제공합니다. 다음 섹션에서는 PostgreSQL의 OID 고갈을 처리하기 위한 즉각적이고 장기적인 해결책을 모두 탐구합니다.
즉각적인 해결책
이 섹션은 식별된 문제를 해결하기 위해 즉시 구현할 수 있는 해결책을 개요하며, 신속한 배포를 위한 실행 가능한 단계를 제공하고 운영에 대한 최소한의 중단을 보장합니다.
1. 기존 데이터 정리
OID 고갈을 해결하는 즉각적인 방법 중 하나는 TOAST 테이블의 기존 데이터를 정리하는 것입니다. 오래되었거나 불필요한 행을 삭제함으로써 향후 사용을 위해 OID를 해제할 수 있습니다. 이는 OID 시스템의 압박을 줄이고 일시적으로 삽입 성능을 개선하는 데 도움이 될 수 있습니다.
고려사항:
- 이 접근 방식은 처음에는 잘 작동하지만, 테이블이 증가하면서 정리 기회가 줄어들 수 있습니다. 데이터 볼륨이 계속 증가한다면, 데이터 정리는 효과가 떨어질 수 있습니다.
- 테이블이 크고 빈번한 vacuuming이 필요한 경우, 각 삭제 작업 후에 데이터베이스가 공간을 효과적으로 회수해야 하므로
VACUUM을 사용한 정리도 문제를 야기할 수 있습니다.
단점:
- 시간이 지나면서 정리할 수 있는 공간이 줄어들어 지속적인 데이터 삭제로부터 상당한 개선이 없는 상황이 될 수 있습니다.
- 정기적인
VACUUM프로세스는 특히 정리 볼륨이 큰 경우 더욱 어려워질 수 있습니다.
2. 새 테이블로 데이터 아카이빙
또 다른 단기적인 해결책은 데이터를 새 테이블로 아카이빙하는 것으로, 본질적으로 오래되었거나 덜 자주 액세스되는 데이터를 라이브 테이블에서 이동시키는 것입니다. 이는 TOAST 테이블의 레코드 수를 줄이는 데 도움이 되어 PostgreSQL이 OID를 더 효율적으로 관리할 수 있게 합니다.
접근 방식:
- 새 테이블을 생성하고, 데이터를 새 테이블로 이동한 다음, 라이브 테이블을 정리합니다.
- 이는 원본 테이블의 크기를 줄이고 한동안 OID 고갈 문제를 완화할 수 있습니다.
단점:
- 아카이빙과 정리는 여전히 라이브 테이블에서
VACUUM의 일상적인 사용에 문제를 야기할 수 있습니다. 테이블이 시간이 지나면서 상당히 증가하는 경우 OID 고갈의 근본적인 문제를 완전히 해결하지 못할 수 있기 때문입니다. - 데이터 정리와 마찬가지로, 아카이빙은 일시적인 완화를 제공할 수 있지만 장기적인 해결책은 아닙니다.
3. 새 테이블에 쓰기
더 적극적인 해결책은 새 테이블에 데이터를 쓰는 것입니다. 접근 방법은 다음과 같습니다:
- 기존 테이블을
mytable_old로 이름을 변경합니다(예: tasks를tasks_old로 이름 변경). - 동일한 구조를 가진 새로운 빈 테이블
mytable을 생성합니다. - 모든 새로운 쓰기를
mytable테이블로 지시합니다. UNION ALL을 사용하여 이전 테이블과 새 테이블을 결합하는 뷰를 생성합니다. 이렇게 하면 두 테이블이 하나의 논리적 테이블로 나타나며, 애플리케이션은 동일한 쿼리 구조를 계속 사용할 수 있습니다.
이 접근 방식을 통해 이전 테이블의 OID 고갈 문제를 우회하면서 데이터 삽입을 계속할 수 있습니다.
단점:
- 이전 테이블에
UPDATE작업이 있다면, OID 고갈 문제가 다시 발생할 수 있습니다. 해결 방법은 새 테이블에서UPDATE를 사용하도록 지시하는 로직을 애플리케이션 레이어에 구현하는 것입니다. - 예를 들어, 업데이트가 필요할 때 애플리케이션은 다음을 수행할 수 있습니다:
- 이전 테이블에서 레코드를 가져옵니다.
- 업데이트된 값으로 새 레코드를 생성합니다.
- 업데이트된 레코드를 새 테이블에 삽입합니다.
이 접근 방식은 작동하지만, 필요한 추가 로직으로 인해 응답 시간이 증가하고 지연이 발생할 수 있습니다.
- 또한 시간이 지나면서 이전 테이블의 모든 레코드가 결국 업데이트될 수 있으며, 이는 새 테이블에서도 OID 고갈이 다시 나타날 수 있습니다.
권장사항:
- 이 접근 방식은 단기적으로는 실행 가능하지만 시간이 지나면서 확장 가능하지 않습니다. 새 테이블이 증가하고 더 많은 업데이트가 발생하면서 OID 고갈 문제가 재발할 수 있습니다.
장기적이고 확장 가능한 해결책: 테이블 파티셔닝
OID 고갈에 대한 최고의 장기적인 해결책은 테이블 파티셔닝입니다. 파티셔닝은 큰 테이블을 파티션이라고 알려진 더 작고 관리 가능한 조각으로 나눕니다. 각 파티션은 자체 TOAST 테이블과 OID 공간을 가질 수 있어, 여러 파티션에 걸쳐 OID 사용을 효과적으로 분산시키고 단일 파티션이 OID 한계에 도달하는 것을 방지합니다.
장점:
- 단일 파티션에서 OID 고갈의 위험을 줄입니다.
- 쿼리와 삽입 중에 PostgreSQL이 스캔해야 하는 데이터 양을 줄여 성능을 개선합니다.
고려사항:
- 파티셔닝은 파티션 간에 데이터가 고르게 분산되도록 신중한 설계가 필요합니다. 예를 들어, 파티셔닝을 위한 올바른 컬럼 선택(예: 날짜 또는 지역)은 성능에 상당한 차이를 만들 수 있습니다.
- 쿼리 패턴과 인덱싱 전략에 대한 신중한 고려가 중요합니다. 부적절한 파티셔닝 구현은 데이터베이스 성능에 심각한 영향을 미칠 수 있기 때문입니다.
OID 및 TOAST 테이블 사용량 모니터링
OID 고갈을 방지하고 최적의 성능을 유지하려면 TOAST 테이블의 OID 사용량을 모니터링하는 것이 중요합니다. 이 섹션은 OID 소비를 추적하고 잠재적인 문제를 식별하기 위한 몇 가지 쿼리를 개요합니다.
UPDATE 동작과 OID 관리
PostgreSQL에서 UPDATE 작업은 행의 원래 OID를 보존하지 않습니다. 대신 업데이트된 행에 대해 새로운 OID가 생성되며, 이는 특히 TOAST된 컬럼에서 업데이트가 자주 발생할 때 더 빠른 OID 소비를 초래할 수 있습니다.
예를 들어, 다음을 고려하십시오:
업데이트 전 :
chunk_id
11684324
11684325
11684326
(3 rows)
UPDATE 작업 수행 후:
업데이트 후:
업데이트된 행에 새로운 OID가 할당되어 추가적인 OID 소비에 기여하고 TOAST 테이블의 OID 고갈을 악화시킵니다.
OID 사용량 모니터링을 위한 유용한 쿼리
다음은 TOAST 테이블의 OID 사용량을 모니터링하고 관리하기 위한 유용한 쿼리들입니다:
쿼리 1: 비어있지 않은 TOAST 관계와 최대 OID 사용량을 가진 테이블 가져오기
이 쿼리는 활성 TOAST 관계를 가진 테이블을 식별하고 각 테이블에서 사용된 최대 OID를 보고하며, OID 한계에 근접한 TOAST된 관계를 찾아내는 데 도움이 됩니다.
샘플 출력:
쿼리 2: TOAST 관계당 사용된 OID 수 계산
특정 TOAST 관계 내의 OID 사용량을 추적하려면, 다음 쿼리를 실행하여 고유한 청크 ID의 수를 계산하십시오. 이는 각 TOAST 관계에서 사용되고 있는 OID 수를 이해하는 데 도움이 되어 잠재적인 OID 고갈에 대한 통찰력을 제공합니다.
샘플 출력:
결론
TOAST 테이블의 OID 고갈은 PostgreSQL 데이터베이스에 상당한 결과를 가져올 수 있는 미묘하지만 중요한 성능 문제이며, 특히 데이터 볼륨이 증가할 때 그렇습니다. 이 문제의 근본 원인을 이해하고 Database Insights와 같은 모니터링 도구를 사용함으로써 OID 소비 패턴을 식별하고 교정 조치를 취할 수 있습니다. 데이터 정리나 아카이빙과 같은 즉각적인 해결책과 파티셔닝이나 새 테이블로의 마이그레이션과 같은 더 확장 가능한 전략이 성능을 복원하는 데 도움이 될 수 있습니다.
그러나 OID 고갈을 해결하는 것은 일회성 수정이 아닙니다. 문제가 다시 나타나는 것을 방지하기 위해서는 OID 사용량과 TOAST 테이블 크기의 지속적인 모니터링이 필수적입니다. 모범 사례를 채택하고 대용량 데이터 타입 관리에 적극적으로 임함으로써 PostgreSQL 데이터베이스가 OID 한계에 도달하지 않으면서 효율적이고 확장 가능하며 증가하는 워크로드를 처리할 수 있도록 보장할 수 있습니다.