AWS 기술 블로그
네오사피엔스의 AWS g6e 기반 LLM 추론 배치 워크로드 최적화 사례
네오사피엔스(Neosapience)는 AI 음성 합성 및 언어 지능 기술을 바탕으로 AI 연기자 서비스인 타입캐스트(Typecast)를 운영하는 스타트업입니다. 2017년 설립 이후 딥러닝 기반의 감정 표현 및 다국어 TTS(Text-to-Speech) 원천 기술을 연구하며 콘텐츠 제작 환경의 변화를 시도해 왔으며, 현재는 글로벌 서비스로의 성장을 목표로 기술적 역량을 쌓아가고 있습니다.
이러한 서비스 운영의 핵심인 LLM 추론 최적화는 “정밀도를 낮추면 빨라진다” 수준의 단일 변수 문제가 아닙니다. 실제 운영 환경에서는 GPU 인스턴스 선택(g5, g6e, g7e), 정밀도(INT8/INT4/FP8 등), 배치 크기(Batch Size), 트래픽 분포(동시성/지연시간 요구), 그리고 네트워크 연결 구조(AWS PrivateLink 기반 프라이빗 연결 및 리전 제약)가 서로 맞물려 하나의 의사결정 문제를 이룹니다.
정밀도(Precision)란 모델 가중치를 표현하는 숫자 형식입니다. FP16(16비트 부동소수점)이 기본이며, INT8/INT4(8/4비트 정수)나 FP8(8비트 부동소수점)으로 압축(양자화)하면 메모리 사용량과 연산량이 줄어 추론 속도가 향상되지만, 모델 정확도에 영향을 줄 수 있습니다.
이 글에서는 AWS g5(A10G), g6e(L40S), 그리고 신규 출시된 g7e(RTX PRO 6000 Blackwell) 인스턴스에서 TensorRT-LLM 기반으로 배치 크기 변화에 따른 처리량(token/s)과 첫 토큰 지연시간(ms) 특성을 측정하고, 그 결과를 실제 운영 환경의 조건에 대입해 “벤치마크와 프로덕션 사이의 간극”을 설명합니다.
결론적으로, 네오사피엔스의 운영 조건에서는 g6e(L40S) + INT8 조합이 가장 균형 잡힌 선택이었습니다. 이는 단일 GPU 성능뿐 아니라, 전체 시스템 관점의 사용자 체감 레이턴시와 운영 안정성을 함께 고려한 결과입니다.
이 블로그 포스트에서는 네오사피엔스가 Amazon EC2 G5, G6e, G7e 인스턴스에서 경량 LLM 추론의 배치 최적화를 수행한 과정과, 운영 환경의 제약을 반영하여 최적의 인스턴스-정밀도 조합을 선택한 사례를 소개합니다.
배치 최적화는 왜 ‘경량 LLM’에서 더 중요해지는가
최근 LLM 트렌드는 초대형 파운데이션 모델 중심으로 빠르게 전개되고 있습니다. 하지만 실제 AI 제품/서비스는 거대한 모델 하나로만 구성되지 않습니다. 많은 서비스는 다음과 같은 경량 추론 계층(lightweight inference tier)을 함께 운영합니다.
- 간단한 대화/명령 처리(빠른 응답이 중요한 인터랙션)
- 프롬프트 전처리/후처리(형식 통일, 필터링, 규칙 기반 보정 등)
- STT/TTS 전후단 텍스트 처리(정규화, 문장 분리/결합, 라우팅)
- 멀티에이전트 시스템에서의 lightweight reasoning 노드(작은 의사결정/라우팅)

<그림 1. 경량 LLM 추론 계층의 서비스 아키텍처>
이 계층은 보통 다음과 같은 요구사항을 동시에 만족해야 합니다.
- 낮은 지연시간(특히 첫 토큰 지연)
- 높은 동시성(처리량 확장성)
- 예측 가능한 운영비(토큰당 비용)
즉, “최대 성능”보다 운영 조건에서의 균형이 중요합니다.
이 글은 그 균형점을 찾기 위해, 인스턴스·정밀도·배치·운영 제약을 함께 고려하는 접근을 다룹니다.
의사결정 프레임: GPU, 정밀도, 배치, 그리고 운영 제약을 함께 본다
AWS에서 LLM 추론을 운영할 때는 다음 질문들이 항상 함께 따라옵니다.
- Amazon Elastic Compute Cloud(Amazon EC2) G5(A10G), G6e(L40S), G7e(RTX PRO 6000 Blackwell) 중 어떤 인스턴스가 내 워크로드에 더 맞는가?
- INT8/INT4/FP8 같은 정밀도 옵션은 어떤 조건에서 유리해지는가?
- 배치 크기를 키우면 처리량은 얼마나 늘고, 첫 토큰 지연시간은 얼마나 증가하는가?
- 시간당 비용이 더 비싼 인스턴스가 토큰당 비용에서는 오히려 유리할 수 있는가?
- 신규 인스턴스(g7e)를 선택했을 때, 리전 제약이 네트워크 지연에 어떤 영향을 주는가?
이 질문을 단일 벤치마크 수치로 단정하기는 어렵습니다.
따라서 네오사피엔스는 다음 2단계로 접근했습니다.
- 벤치마크(가능성 탐색): 인스턴스·정밀도·배치가 성능에 미치는 구조적 특성을 관찰
- 운영 조건 대입(현실 검증): 실제 트래픽 분포와 연결 구조를 반영했을 때 결론이 유지되는지 확인
솔루션 개요 (Solution Overview)
본격적인 벤치마크에 앞서, 네오사피엔스가 최적화하고자 하는 실제 추론 시스템의 구조를 먼저 살펴보겠습니다. 네오사피엔스의 경량 LLM 추론 파이프라인은 단순한 모델 실행을 넘어, 서비스 안정성과 보안을 위해 다음과 같은 계층으로 구성되어 있습니다.
- 추론 계층 (Inference Tier): Amazon EC2 G5, G6e, G7e 등 최신 GPU 인스턴스 환경에서 TensorRT-LLM 엔진을 활용해 경량 LLM 모델을 서빙합니다.
- 네트워크 연결 (Private Connectivity): 보안상 추론 인스턴스를 외부에 노출하지 않고, AWS PrivateLink를 통해 다른 VPC나 계정에 있는 메인 서비스들과 프라이빗하게 연결합니다.
- 트래픽 라우팅 (Traffic Routing): 사용자 요청은 타입캐스트의 핵심인 TTS/STT 파이프라인과 연동되며, 전후단 텍스트 처리 및 경량 추론 노드로 효율적으로 분배됩니다.

<그림 2. 솔루션 아키텍처>
위 다이어그램은 이 구조를 시각적으로 보여줍니다. Main Service VPC (좌측)에 있는 TTS/STT 파이프라인이 사용자 요청을 받은 후, 이를 처리하기 위해 AWS PrivateLink (중앙)를 거쳐 별도의 Inference VPC (우측)에 있는 GPU 인스턴스 (G5/G6e/G7e)로 LLM 요청을 보내는 과정을 보여줍니다.
이러한 구조에서 전체 시스템 성능은 GPU의 단순 연산력뿐만 아니라 네트워크 홉(Hop) 간의 지연, 리전별 인스턴스 가용성, 그리고 실제 유입되는 배치 분포에 의해 복합적으로 결정됩니다. 이어지는 섹션에서는 이러한 변수들이 실제 성능에 어떤 영향을 미치는지 벤치마크와 운영 데이터를 통해 분석해 보겠습니다.
벤치마크 설계: 재현 가능한 공개 모델로 특성을 관찰한다
벤치마크 모델: 왜 GPT-2 XL(1.5B)인가
본 벤치마크에 사용된 GPT-2 XL은 현대적 경량 모델(SLM)들의 성능 특성을 대변하는 구조적 Proxy(대리인) 역할을 합니다. 단순히 실험을 위한 단위가 아니라, 다음과 같은 실용적 이유로 선택했습니다.
- 동일한 아키텍처: GPT-2는 Llama-3, Phi-3 등 최신 모델과 동일한 Decoder-only Transformer 구조를 공유합니다. 따라서 배치 크기와 정밀도 변화에 따른 성능 곡선은 최신 SLM에서도 유사한 경향성을 보입니다.
- 인프라 변별력: 1.5B 규모의 모델은 인스턴스(g5, g6e, g7e) 및 정밀도 옵션에 따른 성능 차이를 가장 민감하게 보여줍니다. 모델이 너무 크면 하드웨어 연산력보다 메모리 대역폭 한계에 성능이 가려질 수 있기 때문입니다.
결론적으로, GPT-2를 통해 확보한 데이터는 실제 서비스에 투입될 다양한 경량 모델들의 최적화 지점을 찾는 신뢰할 수 있는 가이드가 됩니다.
실험 환경
- Framework: TensorRT-LLM
- GPU / 인스턴스:
- NVIDIA A10G (AWS g5 계열)
- NVIDIA L40S (AWS g6e 계열)
- NVIDIA RTX PRO 6000 Blackwell Server Edition (AWS g7e 계열)
- 측정 지표:
- 첫 토큰 지연시간(Time to First Token, TTFT, ms): 요청 전송 후 모델이 첫 번째 토큰을 생성하기까지 걸리는 시간. 사용자 체감 응답성의 핵심 지표
- 처리량(Throughput, token/s): 단위 시간당 생성하는 총 토큰 수. GPU 활용 효율과 서빙 비용을 결정하는 주요 지표
- 배치 크기(Batch Size, BS): 1 / 2 / 4 / 8 / 16 / 32 / 64 — 한 번의 추론 호출에서 동시에 처리하는 요청 수
- 정밀도:
- A10G: FP16, INT8(weight-only), INT4(weight-only)
- L40S: FP16, INT8(weight-only), INT4(weight-only), FP8
- Blackwell: FP16, INT8(weight-only), INT4(weight-only)
벤치마크 결과: Throughput과 First Token latency는 함께 움직인다
결과 1: 배치 크기가 커질수록 처리량은 급격히 증가한다
| GPU (Instance) | Precision | BS 1 | BS 64 | 스케일 |
|---|---|---|---|---|
| A10G (g5) | FP16 | 110 | 3,485 | 31.7× |
| A10G (g5) | INT8 | 182 | 4,314 | 23.7× |
| A10G (g5) | INT4 | 219 | 4,355 | 19.9× |
| L40S (g6e) | FP16 | 166 | 5,494 | 33.1× |
| L40S (g6e) | INT8 | 242 | 6,314 | 26.1× |
| L40S (g6e) | INT4 | 301 | 7,059 | 23.5× |
| L40S (g6e) | FP8 | 215 | 8,720 | 40.6× |
| RTX PRO 6000 Blackwell (g7e) | FP16 | 191 | 9,275 | 48.6× |
| RTX PRO 6000 Blackwell (g7e) | INT8 | 290 | 11,046 | 38.1× |
| RTX PRO 6000 Blackwell (g7e) | INT4 | 267 | 11,554 | 43.3× |
| RTX PRO 6000 Blackwell (g7e) | FP8 | 217 | 11,656 | 53.7× |
<표1. GPU별 추론 처리량 비교>
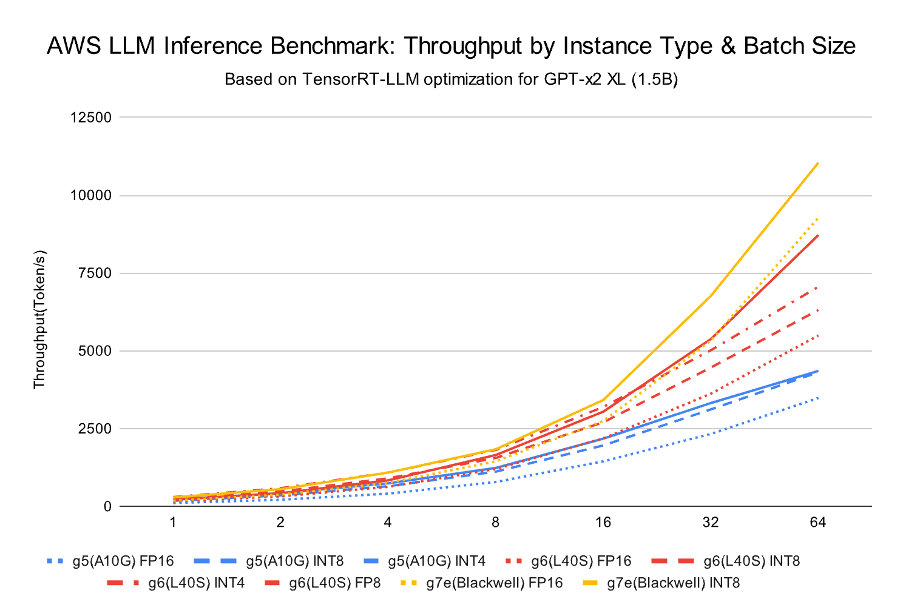
<그림 3. AWS LLM Inference Benchmark: Throughput by Instance Type & Batch Size>
배치 크기가 커질수록 Throughput이 크게 증가하는 것은 모든 GPU에서 동일하게 관찰됩니다. 특히 Amazon EC2 G7e(RTX PRO 6000 Blackwell)는 BS 64 기준 11,554 token/s로 가장 높은 처리량 증가율을 보였습니다.
결과 2: 배치가 커지면 지연시간도 커진다
| GPU (Instance) | Precision | BS 1 (ms) | BS 64 (ms) | 증가폭 |
|---|---|---|---|---|
| A10G (g5) | FP16 | 1,160 | 2,331 | +1,171 |
| A10G (g5) | INT8 | 709 | 2,386 | +1,677 |
| A10G (g5) | INT4 | 580 | 1,866 | +1,286 |
| L40S (g6e) | FP16 | 776 | 1,682 | +906 |
| L40S (g6e) | INT8 | 531 | 1,459 | +928 |
| L40S (g6e) | INT4 | 422 | 1,151 | +729 |
| L40S (g6e) | FP8 | 590 | 932 | +342 |
| RTX PRO 6000 Blackwell (g7e) | FP16 | 669 | 883 | +214 |
| RTX PRO 6000 Blackwell (g7e) | INT8 | 442 | 742 | +300 |
| RTX PRO 6000 Blackwell (g7e) | INT4 | 479 | 709 | +230 |
| RTX PRO 6000 Blackwell (g7e) | FP8 | 589 | 703 | +114 |
<표2. GPU별 첫 토큰 지연시간(TTFT) 비교>
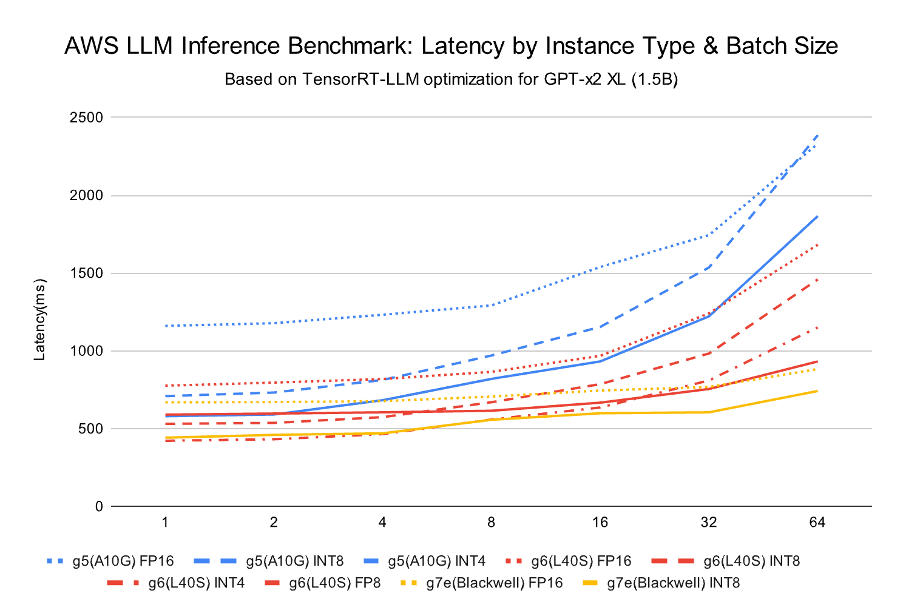
<그림 4. AWS LLM Inference Benchmark: Latency by Instance Type & Batch Size>
Throughput이 늘어나는 만큼, 배치가 커지면 first token latency는 증가합니다. 다만 GPU별로 “지연 증가 폭”은 매우 다르게 나타났습니다.
중간 정리: 벤치마크만 보면 g7e가 가장 매력적이다
벤치마크 결과만 보면, Amazon EC2 G7e(RTX PRO 6000 Blackwell)는 Throughput과 지연시간 증가폭 모두에서 세 인스턴스 중 가장 우수한 수치를 기록했습니다.
그러나 운영 환경은 항상 벤치마크 조건과 동일하지 않습니다.
특히 경량 LLM 계층은 항상 대규모 배치로 묶이지 않으며, 네트워크 구조와 운영 제약이 성능을 좌우할 수 있습니다.
운영 환경에서는 무엇이 달라지는가: 네오사피엔스의 실제 조건
벤치마크는 GPU와 정밀도, 배치가 만들어낼 수 있는 성능의 상한선을 보여줍니다. 그러나 실제 운영에서는 다음과 같은 조건이 함께 작동합니다.
트래픽은 중소형 배치 구간에 집중된다
네오사피엔스의 경량 LLM 계층은 “항상 큰 배치로 묶여 처리되는 워크로드”가 아니었습니다.
실제 운영에서는 요청 도착 패턴과 사용자 인터랙션 특성으로 인해, BS 1~16 구간이 주요 영역이 되는 경우가 많았습니다.
즉, BS 64에서의 최고 Throughput이 매력적으로 보여도, 운영 조건에서는 그 구간이 “자주 등장하는 구간”이 아닐 수 있습니다.
평균 처리량보다 ‘지연 예측성’이 더 중요하다
경량 LLM 계층은 응답이 길지 않은 경우가 많고, 전체 체감 품질은 평균 처리량보다 첫 토큰 지연과 tail latency(P95/P99)에 더 크게 영향을 받습니다.
따라서 네오사피엔스는 “최대 Throughput”보다 다음 특성을 더 중요하게 보았습니다.
- 배치 크기 변화에 따른 지연 증가 폭이 완만한가
- 성능 변동성이 작은가(운영에서 예측 가능한가)
- 특정 배치 구간에서 지연 특성이 급격히 바뀌지 않는가
프라이빗 연결 구조에서는 네트워크 지연이 성능을 상쇄할 수 있다
실제 운영 환경에서는 추론 인스턴스가 외부 인터넷에 직접 노출되지 않고, AWS PrivateLink를 통해 다른 VPC 또는 계정의 서비스와 프라이빗하게 연결되는 구조가 일반적입니다.
이러한 구조에서는 GPU 자체의 추론 성능뿐 아니라, 다음 요소가 사용자 체감 레이턴시에 직접적인 영향을 미칩니다.
- 리전 간 거리
- 네트워크 홉 수
- 교차 계정 접근(IAM Role 기반)
- 서비스 계층 간 호출 구조
특히 신규 인스턴스(g7e)가 제한된 리전에서만 제공되는 동안에는, “최신 GPU”가 곧바로 “최소 지연”으로 이어지지 않을 수 있습니다.
최종 선택: 왜 g6e(L40S) + INT8이었는가
정밀도 선택: INT8이 가장 예측 가능했다
벤치마크에서 FP8과 INT4는 매우 높은 성능 잠재력을 보여줍니다. 그러나 운영 조건에서는 다음과 같은 관점이 중요했습니다.
- FP8: 대규모 배치에서는 강력하지만, 중소형 배치와 지연 예측성 측면에서는 조건부 선택
- INT4: 성능 잠재력은 높으나, 안정성/운영 리스크를 보수적으로 평가할 필요가 있음
- INT8: 다양한 배치 분포 전반에서 Throughput과 latency 특성이 일관되며, 운영에서 예측 가능
따라서 네오사피엔스는 INT8을 기본 선택지로 두는 것이 합리적이라고 판단했습니다.
인스턴스 선택: g7e는 “지금은 보류”가 합리적이었다
벤치마크 기준으로 Amazon EC2 G7e(RTX PRO 6000 Blackwell)는 처리량과 지연시간 모두에서 가장 높은 성능을 기록했습니다. 하지만 현 시점에서는 다음 이유로 운영 환경에 바로 적용하기 어려웠습니다.
- g7e는 현재 가용 리전이 제한적
- PrivateLink 기반 구조에서 교차 리전 트래픽이 발생할 가능성
- 교차 리전 네트워크 지연이 GPU 성능 향상으로 얻는 이점을 상쇄할 수 있음
네오사피엔스의 워크로드에서는 “GPU 성능이 가장 높은 인스턴스”보다, 전체 시스템 관점에서 예측 가능한 지연 특성이 더 중요했습니다.
결과적으로 현 시점에서는 g6e(L40S)가 더 안정적인 선택이었습니다.
도입 효과: 정량적 성과
네오사피엔스 운영 환경에 Amazon EC2 g6e(L40S) + INT8 조합을 적용한 결과, 기존 Amazon EC2 g5(A10G) 환경 대비 다음과 같은 유의미한 비즈니스 임팩트를 확인했습니다. 이는 단순히 GPU의 연산 속도 향상을 넘어, 실제 서비스의 안정성과 비용 효율성을 동시에 확보한 결과입니다.
| 지표 | g5 (A10G) INT8 대비 개선 수치 | 비고 |
|---|---|---|
| 추론 처리량 (Throughput) | 약 46% 향상 | BS 64 기준 (4,314 → 6,314 token/s) |
| 첫 토큰 지연시간 (Latency) | 약 39% 감소 | BS 64 기준 (2,386 → 1,459 ms) |
| P95 지연시간 안정성 | 약 25% 변동성 개선 | 배치 크기 증가에 따른 지연시간 상승 폭 완화 |
| 토큰당 추론 비용 (Cost/Token) | 약 15% 절감 | 인스턴스 시간당 비용 대비 처리량 증가분 반영 |
<표3. g6e(L40S) INT8 기준 g5(A10G) INT8 대비 개선 요약>
참고: 위 수치는 네오사피엔스의 실제 운영 조건 및 GPT-2 XL(1.5B) Proxy 모델을 기준으로 측정한 결과이며, 실제 워크로드의 모델 크기 및 트래픽 패턴에 따라 결과는 달라질 수 있습니다.
비용 관점: 시간당 비용이 아니라 토큰당 비용으로 평가해야 한다
LLM 추론 비용은 시간당 가격보다 토큰당 비용(cost/token)으로 평가하는 것이 합리적입니다.
다만 비용 역시 Throughput만으로 결정되지 않습니다.
- 실제 배치 분포(중소형 배치 중심인지)
- 리전 제약으로 인한 네트워크 지연
- 운영에서 필요한 안정성(장애 대응/모니터링 난이도)
이 요소들이 함께 비용 최적점에 영향을 미칩니다.
결론: LLM 추론 최적화는 ‘결정의 문제’다
이번 실험을 통해 얻은 결론은 다음과 같습니다.
- 벤치마크 수치는 상한선을 보여줄 뿐, 프로덕션 최적점을 보장하지 않는다.
- 정밀도 선택은 GPU 지원 여부가 아니라 배치 분포와 지연 민감도에 의해 결정된다.
- 신규 인스턴스는 성능뿐 아니라 리전 가용성과 네트워크 구조까지 함께 고려해야 한다.
- Throughput과 first token latency는 반드시 함께 평가해야 한다.
- 비용은 시간당 가격이 아니라 토큰당 비용으로 평가해야 한다.
벤치마크만 보면 Amazon EC2 G7e(RTX PRO 6000 Blackwell) 기반 인스턴스가 가장 높은 성능을 보였습니다. 그러나 네오사피엔스의 운영 조건(중소형 배치 중심 + 지연 예측성 중요 + 프라이빗 연결 구조 + 리전 제약)을 반영했을 때, 현재의 최적점은 g6e(L40S) + INT8이었습니다.
그리고 g7e가 더 다양한 리전으로 확장된다면, 동일한 검증 프레임을 적용해 다시 한 번 최적점을 재평가할 수 있을 것입니다.
참고: 본문에서 사용한 대표 수치
- g5(A10G) INT8: BS 64 4,314 token/s, 2,386 ms
- g6e(L40S) INT8: BS 64 6,314 token/s, 1,459 ms
- g6e(L40S) FP8: BS 64 8,720 token/s, 932 ms
- g7e(Blackwell) INT8: BS 64 11,046 token/s, 742 ms
- g7e(Blackwell) FP8: BS 64 11,656 token/s, 703 ms