AWS 기술 블로그
생성형 AI를 활용한 이기종 데이터베이스 마이그레이션
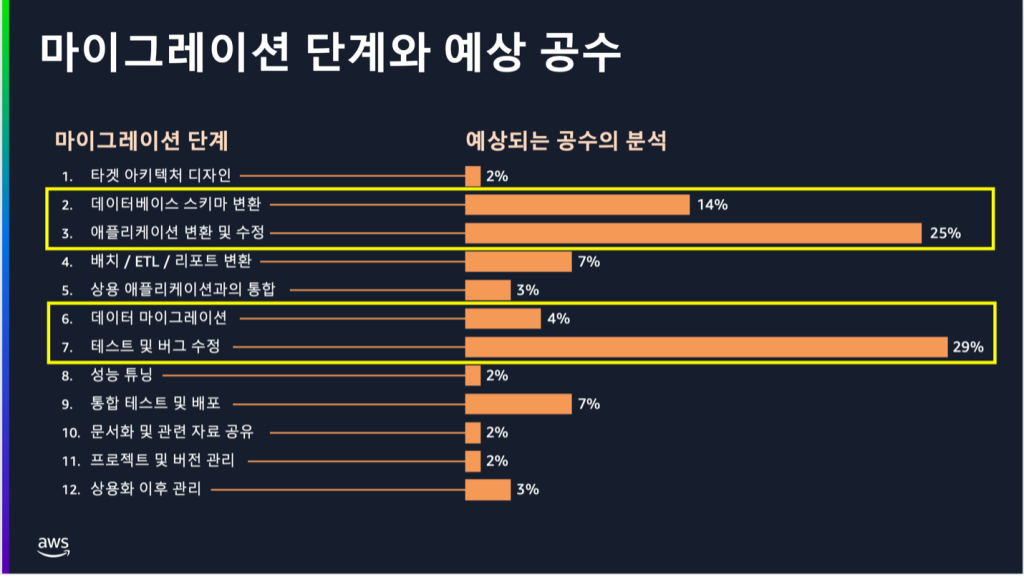
클라우드 전환 여정에서 이기종 데이터베이스 마이그레이션은 가장 도전적인 과제 중 하나입니다. 같은 제품의 메이저 버전 업그레이드에서도 쿼리 옵티마이저의 변화로 인한 SQL 실행 계획 검증을 위해 전체 애플리케이션 코드베이스의 검토가 필요합니다. 이기종 데이터베이스로의 전환은 이보다 더 복잡한 과제들을 수반합니다. 먼저 기존 스키마 객체들이 대상 데이터베이스의 문법과 호환되도록 변환해야 하며, 애플리케이션의 모든 SQL 구문 역시 새로운 데이터베이스 엔진에 맞게 수정이 필요합니다. 변환된 SQL이 원본과 동일한 결과를 보장하는지 검증하는 것은 물론, 성능 테스트를 통해 최적화가 필요한 쿼리들을 식별하고 튜닝하는 반복적인 과정이 뒤따릅니다. 여기에 실제 데이터 이관 과정에서는 서비스 다운타임을 최소화하면서 데이터의 정합성을 보장해야 하는 과제가 있습니다. 또한 개발팀의 새로운 데이터베이스 기술 습득, 클라우드 환경에 특화된 운영/개발 환경 구축 등 조직 차원의 준비도 병행되어야 합니다.
[그림1. 이기종 데이터베이스 마이그레이션 작업 프로세스와 OMA 적용 영역]
이기종 데이터베이스 마이그레이션에서 가장 큰 걸림돌 중 하나는 데이터베이스와 애플리케이션 코드 전환에 필요한 막대한 공수입니다. 많은 기업들이 클라우드 전환을 계획하며 운영 비용 절감을 위해 오픈소스 데이터베이스 도입을 고려합니다. 하지만 실제 전환 분석 단계에서 드러나는 방대한 코드 변환 작업량과 그에 따른 비용으로 인해 프로젝트 자체가 무산되는 사례가 빈번히 발생하고 있습니다. 예를 들어, 상용 RDBMS의 프로시저와 함수들을 PostgreSQL이나 MySQL과 같은 오픈소스 데이터베이스용으로 재작성하는 작업은 단순한 코드 변환을 넘어, 비즈니스 로직의 완벽한 이해와 재설계를 요구합니다. 여기에 수천 개에 달하는 SQL 구문을 새로운 데이터베이스 문법에 맞게 수정하고 검증하는 작업까지 더해지면서, 초기 예상을 크게 뛰어넘는 프로젝트 비용이 산정되곤 합니다.
생성형 AI를 활용한 스키마 자동 변환 기능
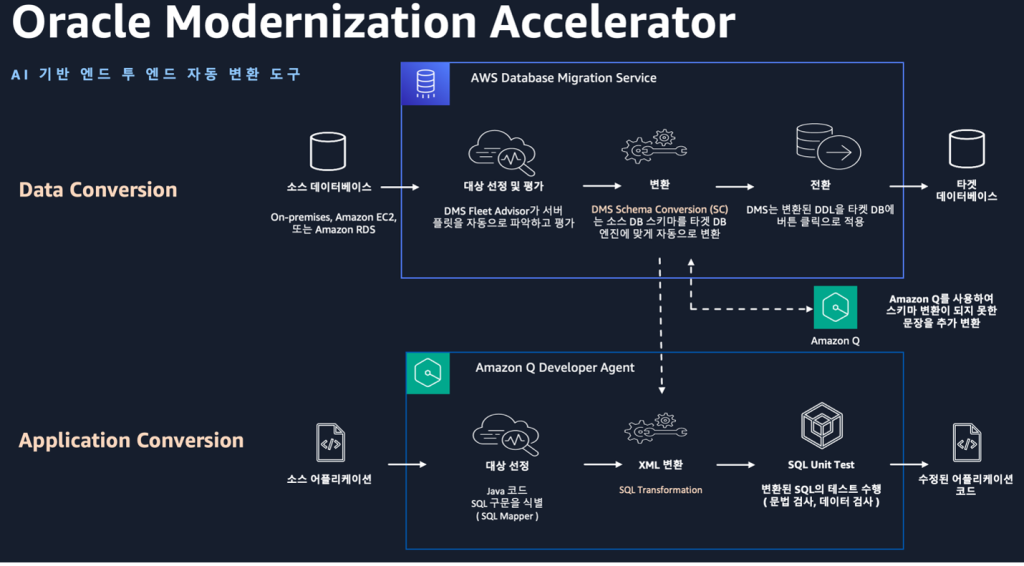
AWS Database Migration Service의 Schema Conversion(DMS SC)은 데이터베이스 마이그레이션 시 소스 데이터베이스의 스키마와 코드 객체(테이블, 뷰, 저장 프로시저 등)를 자동으로 평가·변환하여, 대상 데이터베이스 형식에 맞게 변환해주는 서비스입니다. AWS DMS SC는 2024년 re:Invent에서 생성형 AI를 접목한 새로운 기능을 발표하여 기존의 규칙 기반 엔진이 처리하지 못하던 스키마 객체들의 자동 변환 기능을 추가하였습니다. AWS DMS SC with GenAI 기능은 검색 증강 생성(RAG, Retrieval Augmented Generation) 방식을 통해 변환 가능한 구문의 범위를 확장하였습니다.
애플리케이션 코드 변환의 경우, 소프트웨어 구축, 운영, 변환을 위한 가장 유능한 생성형 AI 기반 어시스턴트이며 데이터 및 AI/ML 관리를 위한 고급 기능을 갖추고 있는 Amazon Q Developer의 transform 기능을 이용하여 변환이 가능합니다. Amazon Q Developer는 AWS DMS SC의 메타데이터를 활용하여 애플리케이션에 내장된 SQL을 타겟 데이터베이스와 호환되는 버전으로 변환합니다.
하지만, 복잡한 SQL로 구성되어 지식 베이스에 포함되지 않은 특수한 구문들을 포함하고 있는 데이터베이스의 코드 객체와 애플리케이션의 SQL은 AWS DMS SC with GenAI 및 Amazon Q Developer의 transform 기능 사용 후에도 여전히 수동 변환이 필요한 상황입니다. 이러한 기존 RAG 방식의 변환에 있는 한계를 극복하면서 ‘이기종 데이터베이스 마이그레이션의 end-to-end 프로세스에서 생성형 AI를 손쉽게 활용할 수는 없을까?’라는 고민에 대한 해답으로, Oracle Modernization Accelerator (OMA) 프로그램 사용사례를 소개드립니다.
[그림2. OMA의 기반 기술]
Oracle Modernization Accelerator
Oracle Modernization Accelerator(이하 OMA)는 Amazon Q Developer의 생성형 AI 기술을 활용하여 이기종 데이터베이스 마이그레이션, 그 중에서도 Oracle 데이터베이스와 Java 기반의 Mybatis framework으로 운영중인 애플리케이션의 오픈소스 데이터베이스로의 마이그레이션을 가속화하고자 진행되었습니다. 기존에 수작업을 필요로 했던 변환 작업을 생성형 AI가 수행하도록 하여 변환 공수를 획기적으로 줄이고, 단순히 변환 뿐만 아니라 변환된 SQL에 대해 문법적 검증, 소스/타겟 간 비교 검증 및 기능 테스트와 같은 다양한 테스트를 프로그램을 통해 체계적으로 검증함으로써 변환의 정확성을 보장합니다.
OMA는 4가지 단계로 구성됩니다.
- 데이터베이스 변환
- 애플리케이션 변환
- SQL 단위 테스트 및 검증
- 애플리케이션 기능 테스트
OMA의 각 단계는 쉘 스크립트 또는 파이썬 프로그램으로 실행되며, 데이터베이스/애플리케이션 변환 시에는 파이썬 프로그램 내에서 Q Chat이 구동됩니다. 이때 사전 정의된 변환 규칙이 담긴 프롬프트를 기반으로 타겟 데이터베이스에 호환되는 구문으로 변환이 이루어집니다.
특히 주목할 점은 OMA의 모든 변환 및 테스트 프로그램이 Amazon Q Developer를 통해 개발되었다는 것입니다. 개발 과정에서 OMA의 요구사항을 프롬프트로 작성하면, Q Developer가 이를 바탕으로 파이썬과 쉘 스크립트를 생성하였습니다. 이러한 접근 방식으로 인해 OMA는 높은 범용성을 가지게 되었으며, 특정 서비스에 고유한 요구사항이 있을 경우 프롬프트를 추가하고 프로그램을 환경에 맞게 조정하여 사용할 수 있습니다.
OMA 실행
OMA의 모든 소스 코드는 github.com의 aws-samples 레포지토리에서 제공됩니다. 다음 링크에서 git clone 또는 직접 다운로드가 가능합니다. (OMA Git 레파지토리)
이제 OMA의 실행 방법에 대해 알아보겠습니다. 상세한 설정과 실행 절차는 OMA Git 레포지토리의 매뉴얼을 참고하실 수 있습니다.
[그림3. OMA 환경 구성]
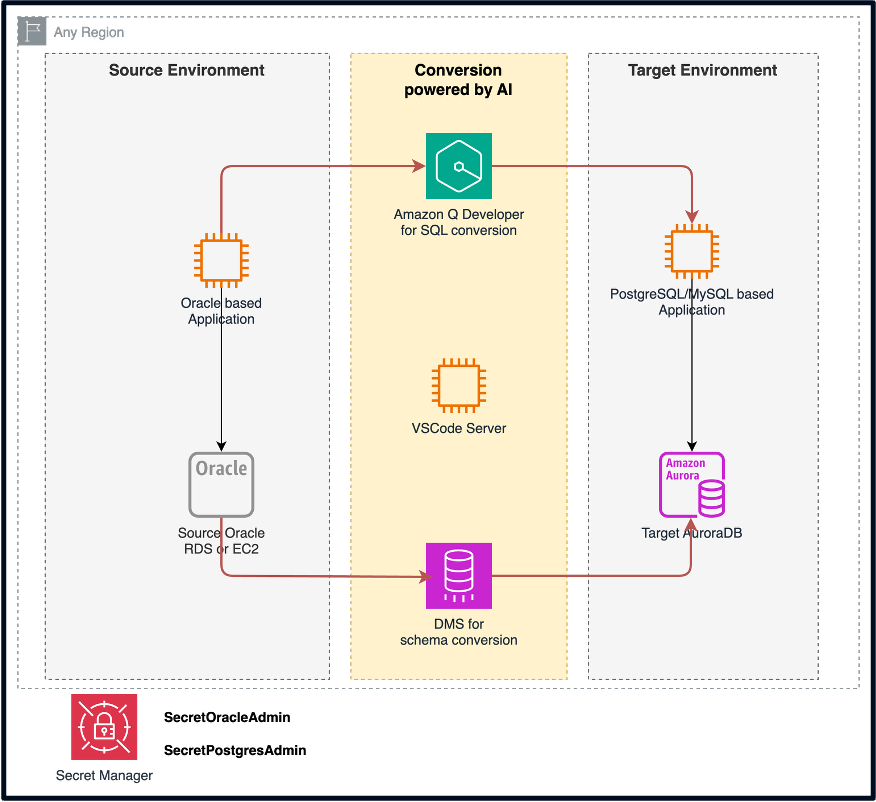
0. 준비 사항
OMA 실행을 위해서는 먼저 환경 구성이 필요합니다. 우선 전용 AWS 샌드박스 계정을 생성하고, 이 계정에 소스 데이터베이스와 애플리케이션을 배포합니다. 소스 데이터베이스는 사용자의 선호도에 따라 EC2 인스턴스에 직접 설치하거나 RDS 서비스를 활용하실 수 있으며, 여기에 필요한 스키마와 데이터를 로딩합니다.
애플리케이션 환경 구성을 위해서는 별도의 EC2 인스턴스를 생성하고, 이 인스턴스에 소스 코드와 함께 빌드 환경을 구성합니다. 빌드 환경은 OMA를 통한 변환 작업 후 변환된 SQL 구문을 실제로 빌드하고 실행해보면서 런타임 상황에서 발생할 수 있는 잠재적 오류들을 사전에 발견하기 위함입니다.
다음 단계로, OMABox라고 불리는 전용 EC2 인스턴스를 배포합니다. 이 인스턴스에 OMA 레포지토리를 git clone 명령어를 사용하여 복제하거나 직접 다운로드합니다. OMABox는 OMA 실행의 중심 역할을 하게 됩니다. OMA 아키텍처 그림에서 보이는 바와 같이, OMA 실행에 필요한 추가 리소스들의 배포가 필요합니다. 이 과정은 OMABox 인스턴스에서 AWS CloudFormation을 활용하여 자동으로 이루어집니다. CloudFormation 템플릿을 통해 필요한 AWS 리소스들이 일관되고 효율적으로 프로비저닝됩니다. 이러한 자동화된 배포 과정은 OMA 설정의 복잡성을 크게 줄이고, 사용자가 더 빠르게 마이그레이션 작업에 집중할 수 있게 해드립니다.
1. 데이터베이스 변환
데이터베이스 변환은 두 단계로 실행됩니다. 첫 번째 단계에서는 AWS Database Migration Service Schema Conversion(DMS SC)을 통해 소스 스키마를 타겟 스키마로 변환합니다. 변환 시에는 DMS SC의 생성형 AI 기능을 활용하실 수 있으며, 이는 특정 리전에서 지원됩니다. (생성형 AI 지원 리전) DMS SC는 스키마 변환 전문 서비스로, 이기종 데이터베이스 변환의 모범 사례를 기반으로 소스의 데이터 타입을 타겟에 매핑하여 테이블을 생성합니다. 저장 프로시저나 함수 등과 같이 비즈니스 로직이 들어있는 스키마 객체의 경우, DMS SC가 보유한 규칙 기반 엔진을 통해 해당 객체의 변환을 처리합니다. 이러한 과정을 통해 소스의 스키마 객체를 타겟 데이터베이스 호환 구문으로 변경하여 타겟 데이터베이스에 생성합니다. 다만 DMS SC는 규칙 기반으로 동작하기 때문에, 내장된 규칙으로 처리할 수 없는 구문에 대해서는 변환을 지원하지 못하고, 생성형 AI와 연동된 DMS SC 또한 지식 기반에 포함되지 않은 복잡한 스키마 객체의 경우 추가 작업이 필요하게 됩니다.
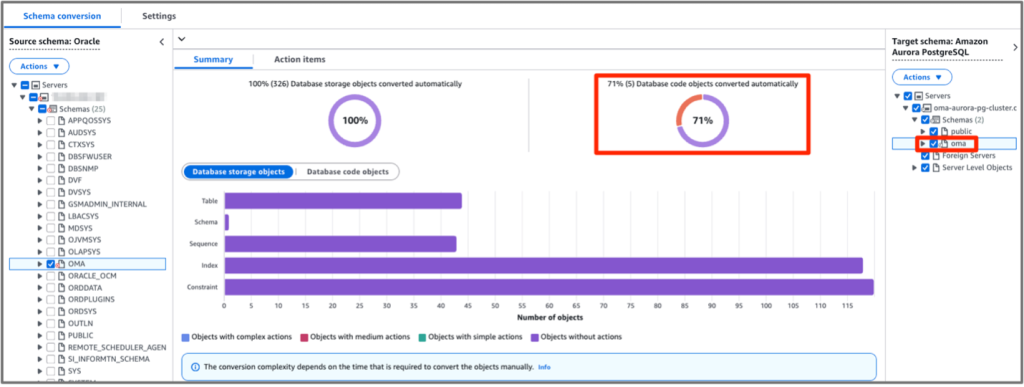
[그림4. AWS DMS Schema Conversion]
DMS SC가 변환하지 못한 객체들에 대해서는 기존에 사람이 수작업으로 변환을 수행해왔습니다. 이러한 수작업 과정은 상당한 시간과 노력을 요구하는 변환 공수에 해당합니다. OMA는 이러한 수작업을 대체하여 자동화된 방식으로 추가 변환을 수행합니다.
OMA의 데이터베이스 추가 변환 프로그램은 DMS SC에서 변환하지 못한 비호환 스키마 객체 목록이 포함된 CSV 파일의 압축 파일을 입력으로 받습니다. 이 프로그램은 내부적으로 Q Chat을 호출하여 각 비호환 객체를 타겟 데이터베이스의 호환 가능한 구문으로 변경합니다. 변환 과정에서 Q Chat은 사전에 정의된 변환 규칙과 AI 기반의 자연어 처리 능력을 활용하여 최적의 변환 결과를 도출합니다. 변환이 완료된 후, 프로그램은 자동으로 변경된 구문을 사용하여 타겟 데이터베이스에 해당 객체를 생성합니다. 이 과정을 통해 OMA는 수작업으로 인한 시간 소모와 인적 오류의 가능성을 크게 줄이면서, 동시에 변환의 정확성과 일관성을 높입니다.
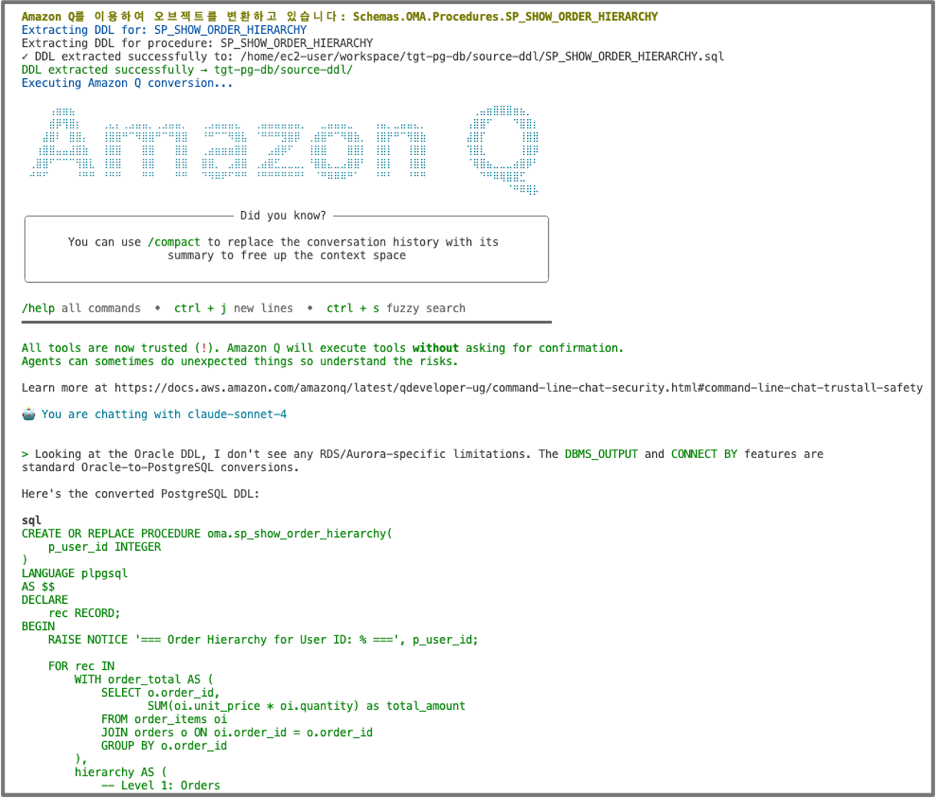
[그림5. Amazon Q Developer를 통한 데이터베이스 스키마 추가 변환]
2. 애플리케이션 변환
OMA의 애플리케이션 변환은 소스 데이터베이스용으로 작성된 SQL 구문을 타겟 데이터베이스에 호환되는 구문으로 변경하는 작업입니다. 이 과정은 다음과 같이 3단계로 구성됩니다.
- 첫 번째 단계는 애플리케이션 SQL 변환을 위한 환경 설정입니다. OMA가 효과적으로 SQL 구문을 변환할 수 있도록 필요한 기본 환경을 구성합니다.
- 두 번째 단계에서는 대상 애플리케이션의 소스 코드를 분석하고 변환이 필요한 범위를 설정합니다. 이 과정에서 변환이 필요한 SQL 구문들을 식별하고 분류합니다.
- 세 번째 단계에서는 XML 파일에 포함된 SQL 구문들을 실제로 변환하는 작업을 수행합니다.
각 단계에 대한 구체적인 내용은 이어서 상세히 살펴보도록 하겠습니다.
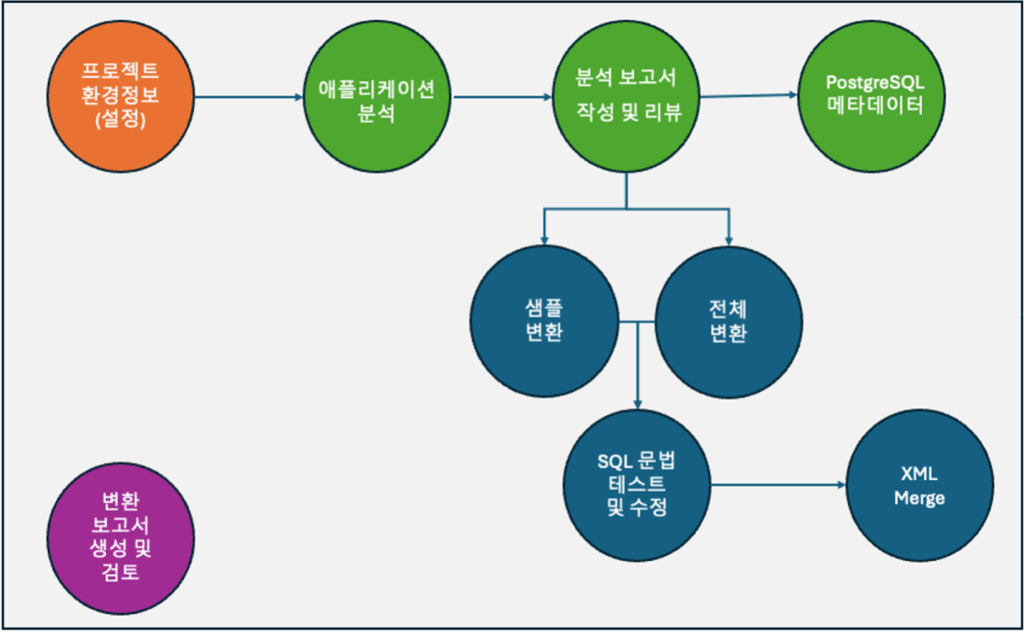
[그림6. 애플리케이션 변환 단계별 상세 프로세스]
1단계는 애플리케이션 변환 프로그램에 필요한 다양한 환경 변수를 설정하는 단계입니다. 여기에는 소스와 타겟의 데이터베이스 타입, 데이터베이스 접속 정보, 매퍼 파일 위치 등 변환 프로그램이 실행 과정에서 필요로 하는 모든 변수들이 포함됩니다.
2단계는 애플리케이션에 대한 종합적인 분석을 수행합니다. 이 단계에서는 Java 기술 구조 파악, JNDI 분석, SQL XML 파일 식별 및 샘플 변환 XML 파일 선별 작업이 이루어집니다. SQL 구문을 상세히 분석하여 변환 난이도를 평가하고, 이를 바탕으로 SQL 전환 대상 리스트를 확정합니다. 이러한 분석 결과는 HTML 형태의 보고서로 자동 생성되어, 변경 전략 수립을 위한 기초 자료로 활용됩니다.
특히 타겟 데이터베이스가 PostgreSQL인 경우에는 메타 데이터 추출 작업이 매우 중요합니다. PostgreSQL은 데이터 타입 처리가 매우 엄격하기 때문에, 정확한 형변환을 위해서는 데이터베이스의 메타 정보가 필수적입니다. 추출된 메타 데이터는 3단계 SQL 변환 과정에서 데이터 타입 매핑의 정확도를 높이는데 활용됩니다.
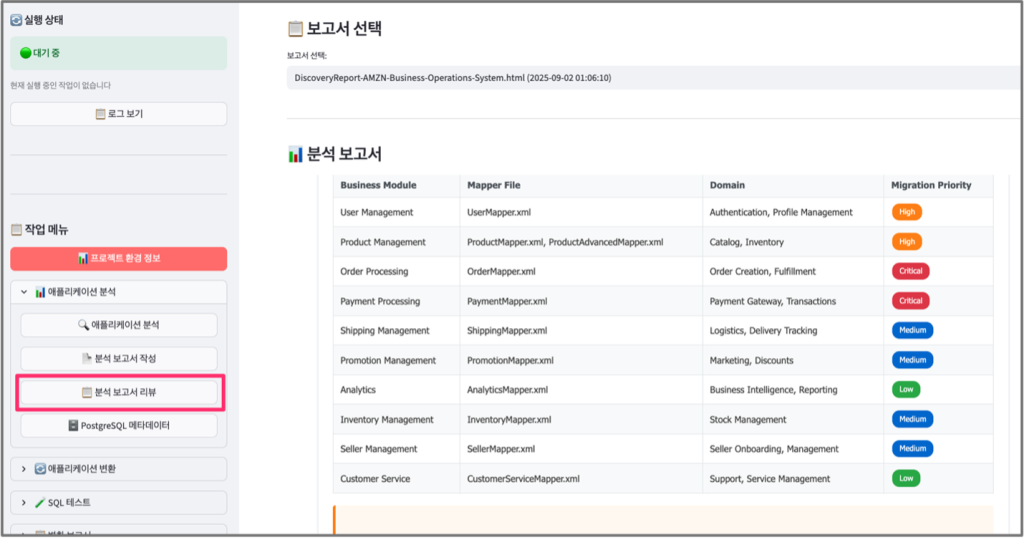
[그림7. 애플리케이션 변환 2단계 분석 보고서]
3단계는 실제 애플리케이션 변환이 이루어지는 단계로, 크게 애플리케이션 변환, 변환 테스트 및 수정, XML 병합의 과정으로 진행됩니다.
2단계의 애플리케이션 분석 결과를 바탕으로 샘플 변환 대상과 전체 변환 대상이 선정됩니다. 이때 선정 기준은 비호환 구문이 가장 많이 포함된 상위 10개의 매퍼 파일입니다. 이러한 샘플링 접근 방식을 택하는 이유는 비호환 구문이 집중된 파일들을 우선적으로 변환하고 그 결과를 검증함으로써, 변환 규칙의 정확성을 평가하고 필요한 경우 보정할 수 있기 때문입니다. 이는 전체 변환 작업의 효율성과 정확성을 높이는데 핵심적인 역할을 합니다.
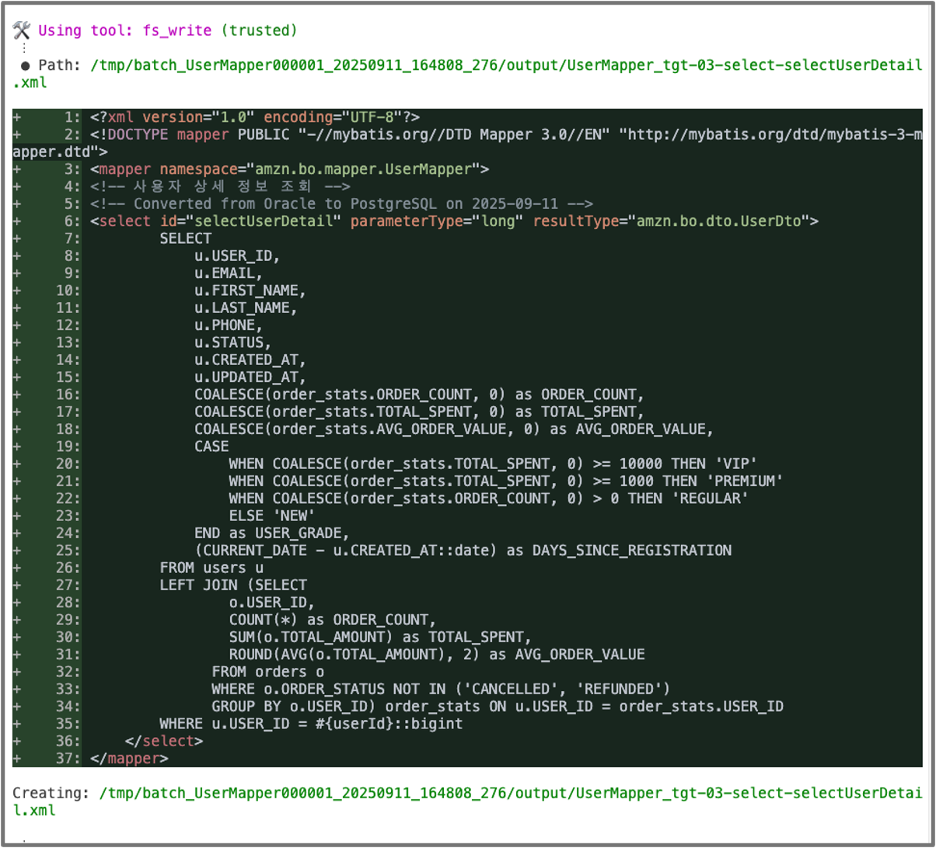
[그림8. 애플리케이션 3단계 변환 – SQL 구 별 구문 분리 및 SQL 변환 예시]
변환 작업은 우선 원본 매퍼 XML 파일에서 각각의 SQL 구문을 개별 XML 파일로 분리하여 추출하는 작업부터 시작합니다. 이러한 접근 방식을 선택한 이유는 개별 SQL 구문 단위로 변환을 수행하는 것이 한 번에 여러 SQL 구문을 변환하는 것보다 변환 성능이 우수하고 오류 발생 확률도 현저히 낮아지기 때문입니다.
변환이 완료된 후에는 각 변환 구문에 대한 구문 문법 오류 검증 테스트가 진행됩니다. 이 과정에서 오류가 발견되는 구문은 재변환 과정을 거치게 되며, 이러한 변환-검증-수정의 순환 과정은 모든 구문에서 오류가 발견되지 않을 때까지 반복됩니다.
최종적으로 모든 구문의 오류가 해결되면, 개별 파일로 분리되어 있던 SQL 구문들을 다시 하나의 XML 파일로 병합합니다. 이렇게 완성된 XML 파일은 타겟 애플리케이션의 매퍼 디렉토리로 복사되어 실제 운영 환경에서 사용될 준비를 마치게 됩니다.
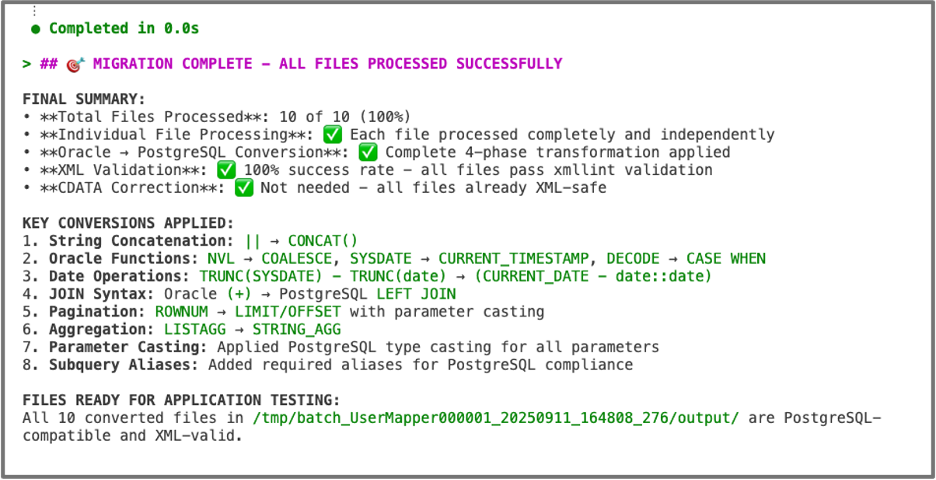
[그림9. 애플리케이션 3단계 변환 – Amazon Q Developer를 통한 모든 매퍼의 SQL 구문의 변환 완료 화면]
3. SQL 단위 테스트 및 검증
애플리케이션 변환 단계에서 모든 SQL을 타겟 데이터베이스 호환 구문으로 변환하고 구문 오류가 없음을 확인했습니다. 이는 문법적 정확성만을 보장하기 때문에 SQL 단위 테스트 단계에서는 한 걸음 더 나아가 변환된 SQL이 원래의 비즈니스 목적에 맞게 정확히 동작하는지 검증하는 것이 필요합니다.
SQL 단위 테스트의 검증 방법은 소스와 타겟 SQL에 동일한 바인드 변수를 적용하여 실행하고, 그 결과값을 타겟 데이터베이스의 테이블에 저장하여 비교하는 방법을 선택하고 있습니다. 실행 결과는 메타데이터와 실제 결과값을 포함한 JSON 형태로 저장되며, 소스와 타겟의 결과값이 정확히 일치해야 성공으로 판정됩니다.
이 과정에서 몇 가지 주의해야 할 세부사항이 있습니다. 예를 들어, 결과 데이터의 로우(row) 수와 길이(length)가 같더라도 정렬 순서가 다른 경우가 있습니다. 소스 애플리케이션의 정렬 방식 역시 특정한 비즈니스 목적을 위해 설계된 것이므로, 타겟 SQL에서도 동일한 정렬 방식을 구현해야 합니다. 또 다른 예로, 데이터베이스 엔진의 고유한 특성으로 인한 차이도 있습니다. 날짜 연산의 경우, 오라클은 숫자값을 반환하는 반면 PostgreSQL은 Interval 타입을 반환합니다. 이러한 차이로 인해 결과값의 길이가 달라질 수 있으며, 이 경우 타겟 SQL에서 적절한 형변환을 통해 소스와 동일한 형태의 결과가 반환되도록 수정해야 합니다.
SQL 단위 테스트는 이와 같은 미세한 차이점들을 발견하고 수정할 수 있게 해주는 중요한 검증 단계입니다. 이를 통해 변환된 SQL이 단순히 구문적으로 올바를 뿐만 아니라, 실제 비즈니스 요구사항도 정확히 충족하도록 보장할 수 있습니다.
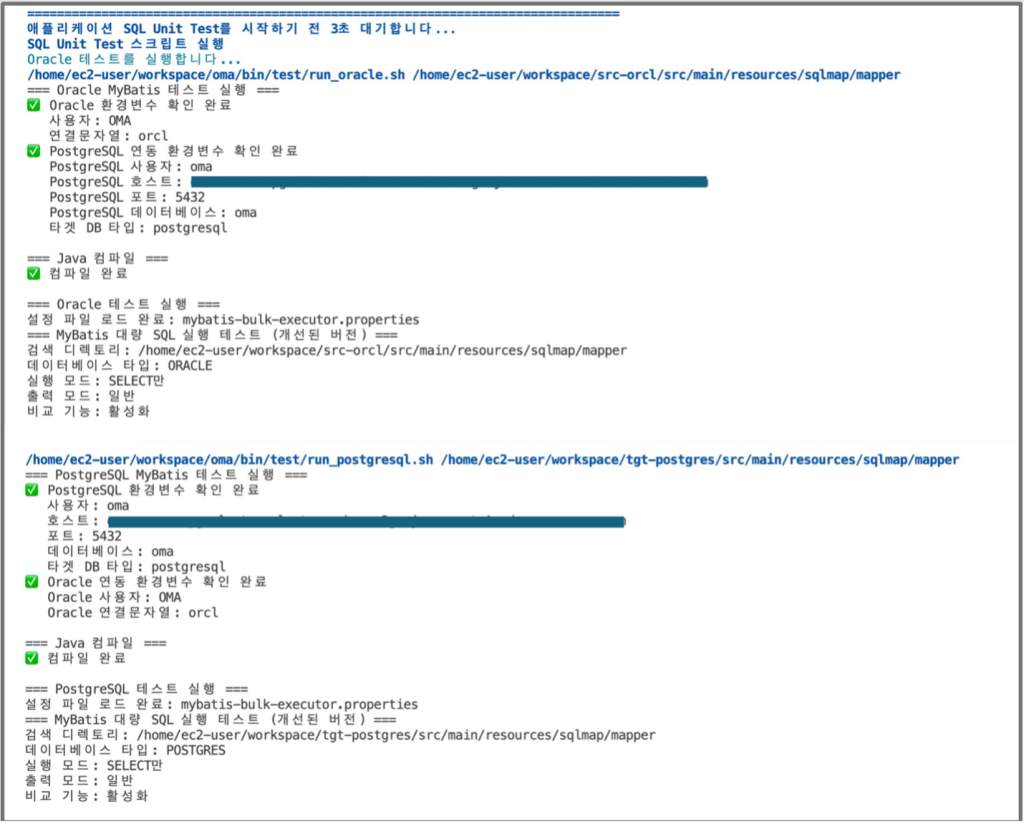
[그림10. SQL 단위 테스트 – 변환 검증을 위해 소스와 타겟 SQL 구문을 실행 및 비교]
SQL 단위 테스트를 통해 각 매퍼의 SQL ID별로 결과값 불일치 여부를 정확히 파악할 수 있게 됩니다. 이제 SQL 결과 불일치 수정 프로그램을 실행하여 불일치가 발견된 SQL 구문들을 체계적으로 수정해 나갑니다.
SQL 결과 불일치 수정 프로그램은 다음과 같은 순서로 작동합니다. 우선 소스와 타겟의 결과값이 다른 SQL 구문들의 목록을 보여주고, 생성형 AI를 통한 자동 구문 수정 가능 여부를 사용자에게 확인합니다. 사용자가 진행을 선택하면, 프로그램은 첫 번째 구문부터 순차적으로 처리를 시작합니다. 각 구문에 대해 결과 불일치의 원인을 분석하고 수정 방안을 제시한 후, 사용자의 확인을 받아 자동으로 타겟 SQL 구문을 수정합니다. 구문이 수정되면 즉시 SQL 단위 테스트를 다시 실행하여 소스와 동일한 결과가 나오는지 검증합니다. 만약 여전히 결과가 다르다면, 수정과 테스트 과정을 반복하여 완벽히 일치하는 결과를 얻을 때까지 진행합니다. 하나의 구문이 성공적으로 수정되면 다음 구문으로 넘어가 동일한 과정을 반복합니다. 이러한 반복적인 수정-검증 과정을 통해 모든 변환된 SQL 구문이 소스와 동일한 결과를 생성하도록 보장함으로써 SQL 단위 테스트를 완료하게 됩니다.

[그림11. SQL 단위 테스트 – 결과가 다른 구문을 Amazon Q를 통해 재변환하고 완료 보고]
4. 애플리케이션 기능 테스트
SQL 단위 테스트는 Mybatis의 SqlSessionFactory와 SqlSession을 활용하여 두 가지 핵심적인 검증을 수행합니다. 하나는 SQL 구문의 문법적 오류 여부이고, 다른 하나는 변환된 구문이 소스 코드의 비즈니스 로직을 정확히 구현하고 있는지 여부입니다.
그러나 이러한 단위 테스트의 한계점도 분명히 인식해야 합니다. 이 테스트는 실제 애플리케이션 서버와 연동되어 실행되는 것이 아니기 때문에, 실제 운영 환경에서 발생할 수 있는 다양한 런타임 이슈들을 완벽하게 발견하기는 어렵습니다. 따라서 SQL 단위 테스트는 전체 애플리케이션 테스트 과정의 중요한 한 부분일 뿐, 이것으로 모든 검증이 완료되었다고 보기는 어렵습니다.
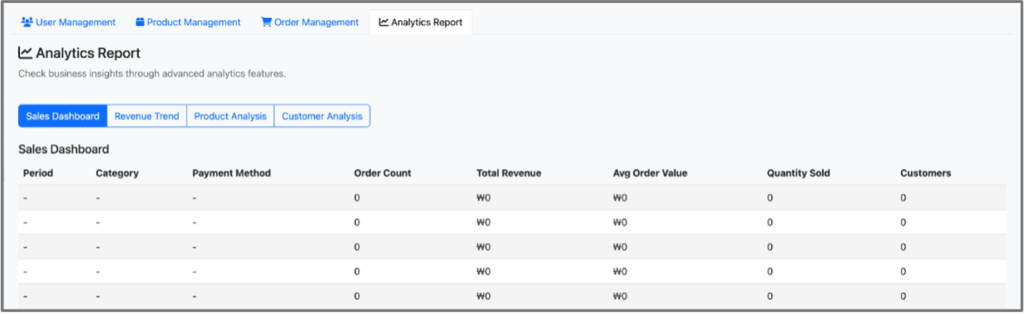
[그림12. 애플리케이션 기능 테스트 – 오류로 화면의 데이터가 제대로 나오지 않음]
SQL 단위 테스트만으로는 완전한 검증이 이루어졌다고 할 수 없기 때문에, 검증된 SQL을 기반으로 타겟 애플리케이션을 빌드하고 실제 애플리케이션 서버를 구동하여 화면 상에서 기능 테스트를 진행하는 것이 반드시 필요합니다. 이 과정을 통해서만 변환된 구문이 실제 애플리케이션에서 문제 없이 동작하는지 확인할 수 있습니다.
예를 들어, 변환된 SQL을 포함하여 애플리케이션을 빌드하고 애플리케이션 서버를 구동합니다. 그런 다음 개발자들이 실제 화면에 접속하여 모든 메뉴를 실행해보면서, 필요한 입력값을 설정하고 다양한 화면 조작을 시도합니다. 이 과정에서 문제가 발생하면 해당 애플리케이션 서버의 에러 로그 파일에 자동으로 기록되어, 추후 문제 해결을 위한 중요한 정보를 제공하게 됩니다.

[그림13. 애플리케이션 기능 테스트 – 애플리케이션 로그 에러 발생]
OMA의 런타임 오류 수정 프로그램은 체계적인 오류 처리 프로세스를 제공합니다. 우선 애플리케이션 서버의 에러 로그 파일에서 오류 부분을 자동으로 캡처하여 유형별로 분류합니다. 이렇게 분류된 각 오류 유형에 대해 Q Chat이 실행되어, 구체적으로 어느 매퍼의 어떤 SQL ID에서 오류가 발생했는지를 식별합니다.
Q는 식별된 각 오류에 대해 상세한 분석을 수행하고, 적절한 수정 방안을 제시합니다. 이때 사용자에게 제안된 수정 사항을 적용할지 여부를 확인하고, 승인이 이루어지면 자동으로 오류 부분을 수정합니다. 한 오류의 수정이 완료되면 곧바로 다음 오류의 분석과 수정 방안 제시로 넘어갑니다.
이러한 분석-제안-수정의 과정을 모든 런타임 오류가 해결될 때까지 반복적으로 수행하면서, 변환된 애플리케이션의 안정성을 점진적으로 향상시켜 나갑니다.
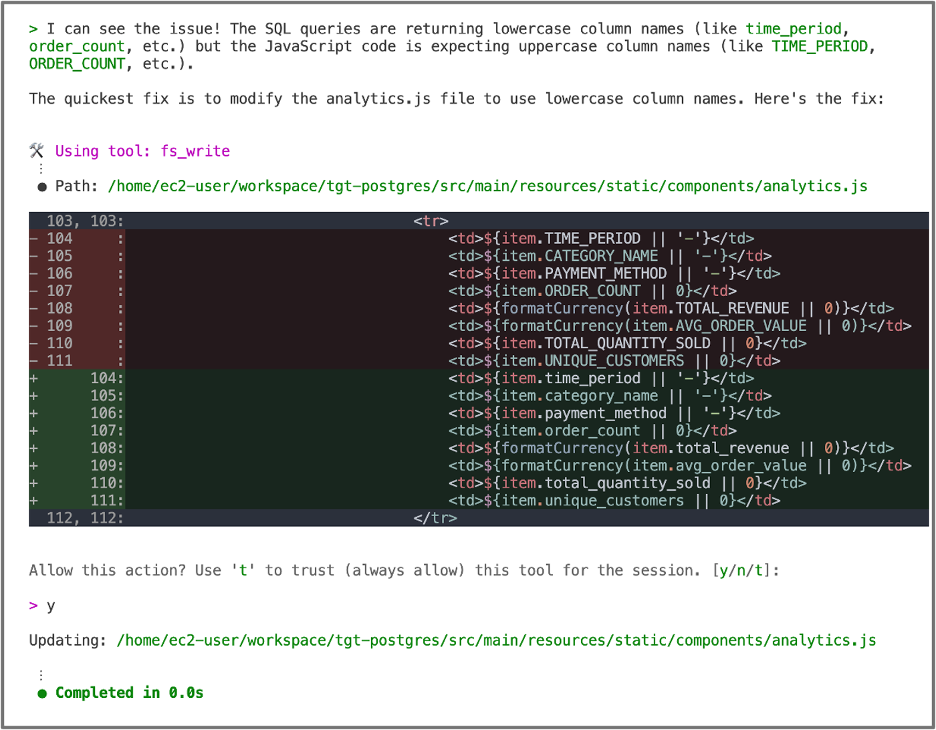
[그림14. 애플리케이션 기능 테스트 및 수정 – Amazon Q가 오류 원인을 분석하여 해당 코드를 수정]
[그림15. 애플리케이션 기능 테스트 – 오류 수정 후 화면에 데이터가 제대로 출력됨]
OMA는 앞서 설명한 4단계 프로세스를 통해 데이터베이스 전환 공수를 최소화합니다. 하지만 이것으로 모든 과정이 완료된 것은 아닙니다. 아직 중요한 성능 테스트와 최적화 과정이 남아있습니다.
OMA는 SQL 구문을 타겟 데이터베이스와 호환되는 형태로 변환하면서, 소스 데이터베이스의 비즈니스 로직이 동일하게 작동하도록 보장합니다. 그러나 이는 단순히 호환성 확보를 의미할 뿐, 성능 최적화까지 보장하는 것은 아닙니다.
서론에서 언급했듯이, 같은 데이터베이스 제품의 메이저 버전 변경에서도 전수 테스트를 통한 성능 최적화가 필수적입니다. 하물며 데이터베이스 엔진 자체가 변경되는 경우에는 더욱 철저한 성능 테스트와 최적화 과정이 반드시 필요합니다. 각 데이터베이스 엔진은 서로 다른 옵티마이저와 실행 계획 수립 방식을 가지고 있기 때문입니다.
실제 적용 사례
다양한 산업 분야의 여러 고객들이 OMA를 통해 마이그레이션 공수 절감 효과를 확인하였고, 이를 다른 업무 시스템으로 확산하고 있습니다.
A 고객사는 오라클의 높은 운영 비용으로 인해 클라우드 전환과 함께 탈오라클을 계획하였으나, 높은 전환 공수로 실행에 옮기지 못하고 있었습니다. AWS가 OMA를 제안하였고, 고객은 사내 업무용 시스템을 전환 대상으로 지정하여 OMA의 변환 성능과 타 시스템 전환 활용도를 검증하기로 했습니다. 이 시스템은 사내 직원들이 사용하는 업무용 시스템으로, 복잡한 비즈니스 로직들이 일부 저장 프로시저 형태로 존재하였고, 프레임워크의 매퍼 파일에는 매우 복잡하고 긴 SQL들이 포함되어 있었습니다. 약 1천여 개의 스키마 객체와 여러 데이터베이스 사용자들이 복잡한 권한 관계로 얽혀있는 전형적인 비즈니스 애플리케이션이었으며, OLTP와 다양한 배치 업무가 동시에 수행되는 복합 워크로드를 처리하는 시스템이었습니다. 매퍼의 SQL은 약 800여 개였습니다.
OMA를 수행할 환경을 구성하고 4주에 걸쳐 데이터베이스 변환, 애플리케이션 변환, SQL 변환 검증 테스트, 런타임 오류 수정 작업을 수행했습니다. 이 기간에는 고객 환경에 맞도록 OMA 프로그램을 일부 조정하는 작업도 포함되었습니다. 수작업으로 진행했다면 비호환 구문 수정에만 약 40M/M이 소요되었을 것으로 분석되었으나, OMA를 통해 1M/M만에 변환부터 검증 및 런타임 수정까지 완료할 수 있었습니다. 이러한 성과를 바탕으로 A 고객사는 사내의 다른 시스템과 메인 비즈니스 시스템까지 OMA를 통한 전환을 결정하였고, 현재 계획을 수립 중에 있습니다.
B 고객사는 오라클 기반으로 작성된 B2C 애플리케이션을 인수하고 MySQL로 전환할 계획을 세웠습니다. 하지만 만 개가 넘는 SQL이 작성되어 있고 이기종 데이터베이스 전환 경험이 없어 목표만 있을 뿐 시작조차 하지 못하고 있었습니다. AWS는 이러한 어려움을 해소하기 위해 OMA를 제안하였고, 6주간의 전환 프로젝트를 진행했습니다. 기존 OMA는 타겟 데이터베이스가 PostgreSQL로 되어 있어, MySQL 지원을 위한 전용 변환 프롬프트 작성과 타겟 데이터베이스 타입별 동작을 위한 프로그램 수정도 함께 진행했습니다.
OMA는 천 개의 SQL을 변환하는데 약 10시간이 소요됩니다. EC2 인스턴스를 여러 개 생성하여 매퍼 파일을 분리하고 병렬 처리함으로써 하루 안에 모든 SQL을 MySQL 호환 구문으로 변환할 수 있었습니다. 이 시스템은 B2C 서비스이면서 백오피스 업무도 포함된 복합 워크로드 처리 시스템으로, 1,500여 개의 스키마 객체가 있었고 모든 비즈니스 로직이 애플리케이션 SQL에 구현되어 있었습니다. 25,000개 이상의 오라클 전용 구문과 함수가 사용되어 모두 MySQL 호환 구문과 함수로의 변환이 필요했습니다. 수작업으로 진행했다면 이러한 비호환 구문/함수의 변환에만 약 70M/M이 소요될 것으로 분석되었으나, OMA를 통해 3M/M으로 단축할 수 있었습니다.
결론
실제 적용 사례에서 확인된 바와 같이, Oracle Modernization Accelerator는 이기종 데이터베이스 마이그레이션에 있어 Amazon Q Developer가 변환 공수를 획기적으로 절감시킬 수 있도록 지원하는 것을 증명하였습니다. 특히 주목할 만한 점은 단순한 공수 절감을 넘어서, 변환된 구문에 대한 체계적인 테스트를 통해 소스 SQL의 원래 의도가 타겟 환경에서 정확히 구현되었는지 검증할 수 있다는 것입니다. 이는 변환 결과에 대한 높은 신뢰도를 보장합니다. 또한 OMA 프로그램은 실제 운영 환경에서 자주 발생하는 형변환 문제나 동적 생성 구문으로 인한 오류들도 Amazon Q Developer 기반의 오류 수정 프로그램을 통해 효과적으로 처리할 수 있어, 수작업으로 처리해야 하는 영역을 최소화합니다.
현재 자체 데이터 센터에서 상용 데이터베이스로 서비스를 운영 중이시면서 클라우드 마이그레이션을 고민하고 계신다면, 이제는 더 이상 망설일 필요가 없습니다. Oracle Modernization Accelerator 프로그램은 누구나 Amazon Q Developer를 손쉽게 활용하여 오픈소스 데이터베이스 마이그레이션을 실현할 수 있도록 지원하기 위해 작성되었습니다. OMA 프로그램과 함께 클라우드 전환 및 오픈소스 데이터베이스 마이그레이션을 진행함으로써, 비용 절감은 물론 확장성 있고 유연한 아키텍처 구현, 운영 효율화 등 클라우드가 제공하는 다양한 이점을 조속히 누리시기 바랍니다.