AWS 기술 블로그
리멤버앤컴퍼니의 Amazon S3 Tables를 활용한 실시간 분석 워크로드 구축하기 2부: S3 Tables를 프로덕션 환경에서 운영하기
1부에서는 CDC를 활용해 Amazon S3 Tables 기반 데이터 레이크 구축 과정을 다뤘습니다.
이번 2부에서는 실제 운영 시 주의해야 할 사항과 함께, Compaction 전략, Snapshot 관리, 모니터링 전략, 그리고 분석 엔진 선택에 대해 정리해 보겠습니다.
Amazon S3 Tables Maintenance 개요
Amazon S3 Tables는 관리형 Iceberg 테이블로, 일반적인 Iceberg 테이블과 동일하게 성능과 스토리지 효율을 위해 일정한 관리가 필요합니다. 이를 위해 S3 Tables에서는 다음과 같은 Maintenance 기능을 제공합니다.
- Compaction
- Small 파일을 병합하여 성능 최적화
- Snapshot Management
- 오래된 스냅샷 정리 및 테이블 버전 관리
- Unreferenced File Removal
- 참조되지 않는 파일을 제거하여 스토리지 절약
이제 각 항목을 리멤버에서는 어떤 방식으로 운영했는지 살펴보겠습니다.
Compaction 전략
Iceberg는 데이터의 추가, 변경, 삭제가 발생할 때마다 새로운 Data File이 생성됩니다. CDC 환경에서는 업데이트가 잦기 때문에 Small File이 빠르게 누적되며, 이로 인해 다음과 같은 문제점이 발생합니다.
- S3 API 요청 수 증가
동일한 데이터를 작은 파일 여러 개로 저장하게 되면, 동일양의 데이터를 조회하더라도 액세스해야 하는 S3 상 파일 수가 늘어나게 됩니다. 이로 인해 GetObject 등 S3 관련 API 호출이 증가하게 됩니다. - 메타데이터 관리 비용 증가
Iceberg는 각 Data File에 대한 메타데이터를 관리합니다. 작은 파일이 많아지면 메타데이터의 수가 급격히 증가하고, 이를 관리하는 비용과 처리 시간이 늘어나게 됩니다. - 쿼리 성능 저하
쿼리 실행 시 많은 수의 작은 파일을 동시에 읽어야 하므로, I/O 비용과 스캔 시간이 증가하게 되어 전체 쿼리 성능이 떨어집니다.
따라서 작은 파일을 지속적으로 병합해 주는 Compaction 작업은 필수적입니다.
S3 Tables는 Iceberg 테이블 운영 시 자동 Compaction(Auto Compaction)을 기본으로 지원합니다.
또한 targetFileSizeMB 옵션을 통해 병합 대상 파일의 목표 크기를 설정할 수 있습니다.
(단, 해당 옵션은 AWS CLI를 통해서만 변경할 수 있습니다.)
targetFileSizeMB 값은 Iceberg 테이블의 성능에 크게 영향을 끼치는 중요한 항목입니다.
- 너무 작은 파일 → 파일 개수가 많아져 메타데이터 관리 비용과 S3 요청 수가 증가
- 너무 큰 파일 → 병렬 처리 효율이 떨어지고, 쿼리 시 불필요한 데이터 스캔이 발생
리멤버에서는 Iceberg 테이블의 targetFileSizeMB를 512MB로 지정하여 운영하고 있습니다. 기존에는 Parquet 파일을 HDFS 환경에서 512~1GB 범위로 설정하여 운영했으며, 실제 테스트에서도 이 범위에서 성능과 비용 효율이 균형을 이루는 것으로 확인되었습니다. Iceberg에서도 512MB로 설정했을 때 쿼리 성능과 S3 I/O 효율이 우수한 결과를 보여, 이를 표준 파일 크기로 채택했습니다. (참고 1, 참고 2)
- S3 I/O 효율 극대화
- 쿼리 엔진에서 병렬 처리 최적화
- Compaction 비용 최소화
다만, Iceberg에서 targetFileSizeMB를 512MB로 지정한다고 해서 반드시 각 파일이 정확히 512MB가 되는 것은 아닙니다. Iceberg는 내부적으로 min-file-size-bytes, max-file-size-bytes 값에 따라 rewrite 대상 파일을 결정하지만, S3 Tables에서는 현재 Maintenance 설정에서 targetFileSizeMB만 지정할 수 있기 때문에, 512MB에 근사한 파일 사이즈를 만들기 위해서는 경우에 따라 더 높은 값을 할당해야 할 수도 있습니다. 이 부분은 추후 시간이 될 때 추가 테스트를 통해 최적값을 확인할 예정입니다.
리멤버에서는 S3 Tables 도입 전에도 일부 워크로드에서 AWS Glue가 제공하는 Iceberg를 사용하고 있었습니다. 두 환경을 비교했을 때 느낀 S3 Tables의 장점은 크게 두 가지입니다.
- Compaction 최적화
- Glue Iceberg는 하루 단위로 Compaction이 실행되지만, S3 Tables는 더 짧은 주기로 Compaction이 수행되어 Small File 관리가 더 효율적
- 그 결과 Small File 수가 적은 상태로 유지되며, 쿼리 성능이 안정적으로 유지
- 비용 효율성
- Glue Iceberg의 Compaction은 DPU 시간 대비 압축된 파일 크기에 따라 비용 발생
- 반면 S3 Tables는 처리된 객체 수와 볼륨을 기준으로 비용이 산정, 상대적으로 더 효율적
Iceberg에서의 Small File 관리 수준이 곧 테이블 성능으로 이어지게 됩니다. 리멤버에서는 Glue Iceberg 대비 S3 Tables의 짧은 Compaction 주기와 비용 효율성 덕분에 운영 효율성을 크게 개선할 수 있었습니다.
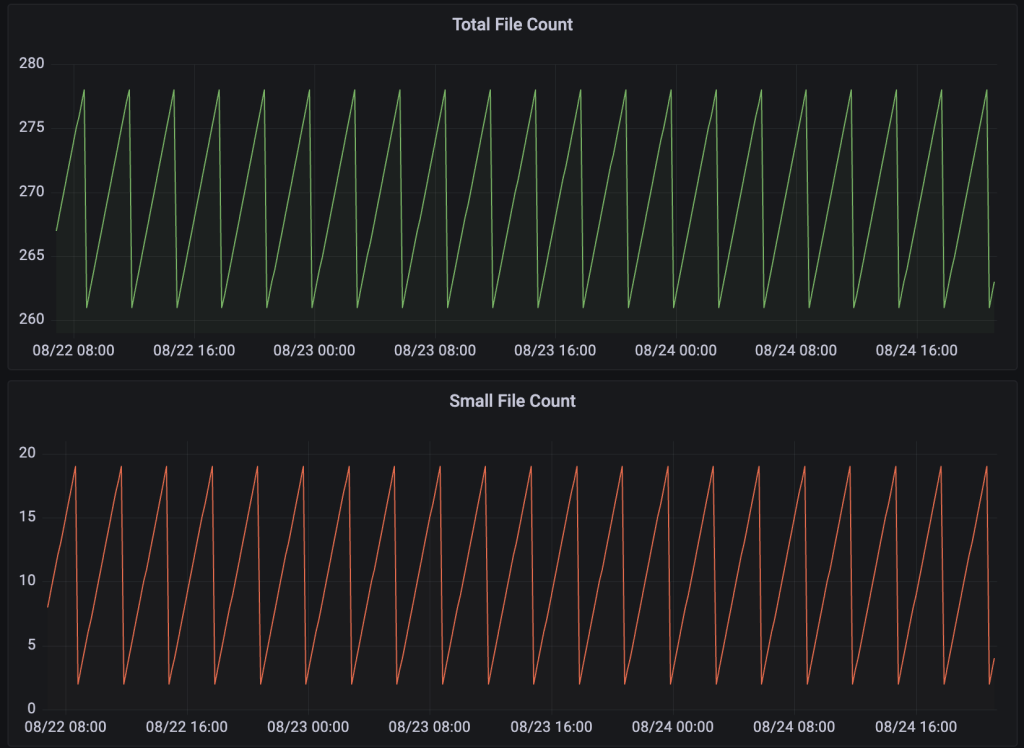
Snapshot Management
Iceberg는 모든 변경 사항을 스냅샷(Snapshot) 으로 기록합니다. 스냅샷은 테이블의 특정 시점(version)을 나타내며, 이를 통해 Time Travel을 가능하게 합니다.
S3 Tables는 두 가지 속성을 제공하며, 모두 CLI를 통해서만 설정할 수 있습니다.
- minSnapshotsToKeep: 최소 보관할 스냅샷 개수
- maxSnapshotAgeHours: 스냅샷 최대 보관 시간(시간 단위)
리멤버에서는 테이블의 성격에 따라 스냅샷 정책을 다르게 적용했습니다.
1. 시점 조회가 필요한 테이블
- minSnapshotsToKeep: 1
- maxSnapshotAgeHours: 720 (약 30일)
이렇게 설정할 경우 CDC 환경에서는 10분마다 Commit이 발생 → 한 달 기준 약 4,320개의 스냅샷이 생성되며 꾸준히 증가하게 됩니다.
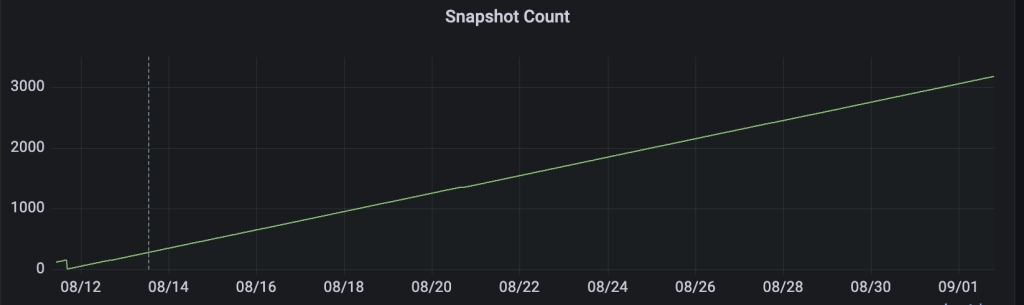
Iceberg는 쿼리 시 최신 스냅샷만 참조하기 때문에 읽기 성능에는 직접적인 영향 없습니다. 다만, 메타데이터 스토리지 증가 및 탐색 비용이 발생할 수 있어 균형점을 찾는 것이 중요합니다.
현재 S3 Tables는 Branch/Tag 기반 보존 정책을 지원하지 않기 때문에 maxSnapshotAgeHours 설정을 이용하거나 배치 형태로 스냅샷 생성을 최소화하는 등 별도의 방법을 구성해야합니다. (공식 문서 참고)
2. 실시간 분석 목적 테이블
- minSnapshotsToKeep : 1
- maxSnapshotAgeHours : 1
이 경우 시점 조회가 불필요하기 때문에 최소한의 스냅샷을 유지하도록 설정하여 불필요한 메타데이터가 증가하는 것을 방지했습니다.
단, 실제로 Snapshot이 정리되는 주기를 확인해 보면 배치가 일 단위로 수행되는 것을 볼 수 있습니다. 따라서, maxSnapshotAgeHours 를 1시간으로 설정할 경우 매일 특정 시점에 배치가 동작하면서 해당 시점을 기준으로 1시간 내의 스냅샷만 남기게 됩니다.
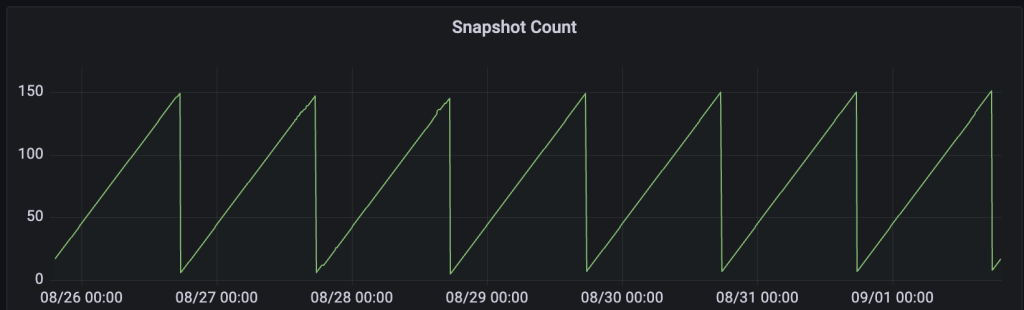
Iceberg의 스냅샷 기능은 시점별 데이터 복원과 변경 추적을 가능하게 하지만, 과도한 생성은 메타데이터 크기를 증가시켜 쿼리 성능과 관리 비용에 영향을 줄 수 있습니다. 이에 따라 S3 Tables에서는 테이블의 용도(예: 시점 조회 필요 여부)에 따라 스냅샷 보존 정책을 차등 적용하는 것이 안정적인 운영의 핵심입니다.
Unreferenced File Removal
스냅샷 만료와 함께 반드시 고려해야 할 부분이 고아 파일(Orphaned File) 관리입니다. Iceberg 테이블에서는 스냅샷에서 더 이상 참조되지 않는 데이터 파일이 쌓일 수 있는데, 이를 방치하면 스토리지 비용이 불필요하게 증가하게 됩니다.
S3 Tables에서는 테이블 스냅샷에서 더 이상 참조되지 않는 파일, 즉 Orphan Files를 자동으로 관리합니다. 이러한 파일은 테이블에서 직접 참조되지 않으며, AWS 내부적으로 unreferencedDays와 nonCurrentDays 설정에 따라 비현재(non-current)로 표시되고 일정 기간이 지나면 자동으로 삭제됩니다. 다만, 이 속성은 테이블 레벨이 아닌 테이블 버킷 레벨에서만 설정할 수 있습니다.
- unreferencedDays
- 지정된 일수 이후에도 어떤 스냅샷에서도 참조되지 않는 파일을 Unreferenced 상태로 표시
- 즉, 더 이상 필요 없는 파일로 간주
- nonCurrentDays
- 현재 활성 스냅샷이 아닌, 과거 스냅샷에서 참조하는 파일의 유지 기간
- 지정된 기간이 지나면 삭제 가능
속성 자체는 성능에 크게 영향을 미치지는 않았기에 기본 값인 unreferencedDays : 4, nonCurrentDays : 10 를 지정해서 사용하고 있습니다.
해당 속성을 활요하면 스냅샷 만료 동작과는 별개로 일정 기간 파일을 보존할 수 있습니다. 이로 인해 복구 가능성을 확보할 수 있고, 바로 삭제되지 않기 때문에 운영 안정성을 높힐 수 있습니다. Unreferenced로 지정된 파일은 직접 읽는 방법은 지원하지 않고 AWS에 문의를 통해서만 확인할 수 있습니다. (공식 문서 참고)
PyIceberg 를 사용해 S3 Tables 데이터 들여다보기
Apache Iceberg 테이블을 운영하다 보면, 특정 스냅샷이 참조하는 실제 Data File 목록을 확인해야 할 때가 있습니다.
예를 들어 다음과 같은 작업들이 있습니다.
- 파일 단위 관리 (Data File 추적)
- 최적화 작업 (Compaction, Data Skipping)
- 테이블 모니터링 (파일 수, 크기, 파티션 상태 등)
특히 AWS에서 제공하는 S3 Tables는 버킷을 직접 탐색할 수 없기 때문에 파일 자체를 콘솔에서 보기는 어렵습니다. 하지만 다행히도 S3 Tables REST Endpoint를 활용하면 모든 객체에 접근할 수 있고, 메타데이터 및 데이터 파일까지 확인할 수 있습니다.
S3 Tables Catalog 불러오기
이번에는 PyIceberg를 사용해 S3 Tables에 접근하고, 테이블 메타데이터와 실제 파일 정보를 확인하는 방법을 정리해 보겠습니다.
PyIceberg는 REST Catalog를 지원하며 S3 Tables REST Endpoint를 통해 파일에 직접 접근할 수 있습니다.
from pyiceberg.catalog import load_catalog
catalog = load_catalog(
"s3tablescatalog",
**{
"type": "rest",
"warehouse": "S3Tables Bucket ARN",
"uri": "https://s3tables.ap-northeast-2.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "s3tables",
"rest.signing-region": "ap-northeast-2",
}
)IAM 권한이 설정되어 있어야 정상적으로 Catalog에 접근할 수 있으며, CDC 환경에서 접근하는 방식과 동일합니다.
현재 스냅샷에서 Data File 가져오기
테이블에서 현재 스냅샷이 참조하는 Manifest List와 엔트리에 Data File을 불러올 수 있습니다.
from itertools import chain
from pyiceberg.table import _open_manifest
from pyiceberg.utils.concurrent import ExecutorFactory
from pyiceberg.manifest import DataFileContent
def only_data_files(data_file):
return data_file.content == DataFileContent.DATA
def no_filter(_):
return True
catalog.list_tables("namespace")
table = catalog.load_table(f"namespace.table")
# 현재 스냅샷 기준
scan = table.scan()
snapshot = scan.snapshot()
# Manifest list를 가져옴
io = table.io
manifests = snapshot.manifests(io)
executor = ExecutorFactory.get_or_create()
# Manifest 에서 참조하고 있는 Data File을 List에 담음
all_data_files = []
for manifest_entry in chain(
*executor.map(
lambda manifest: _open_manifest(io, manifest, only_data_files, no_filter),
manifests
)):
all_data_files.append(manifest_entry.data_file)
이렇게 하면 현재 스냅샷이 참조하고 있는 모든 Data File이 리스트에 담기게 됩니다.
만약 특정 스냅샷을 기준으로 확인하고 싶다면 scan(snapshot_id=…)을 지정하면 됩니다.
또한 content 값에 따라 POSITION_DELETES, EQUALITY_DELETES 같은 Delete File 정보도 함께 가져올 수 있습니다.
Data File 메타데이터 확인
불러온 Data File에는 다양한 메타 정보가 들어 있습니다.
for data_file in all_data_files:
print("content:", data_file.content)
print("file_path:", data_file.file_path)
print("file_format:", data_file.file_format)
print("partition:", data_file.partition)
print("record_count:", data_file.record_count)
print("file_size_in_bytes:", data_file.file_size_in_bytes)
print("column_sizes:", data_file.column_sizes)
print("value_counts:", data_file.value_counts)
print("null_value_counts:", data_file.null_value_counts)
print("nan_value_counts:", data_file.nan_value_counts)
print("key_metadata:", data_file.key_metadata)
print("split_offsets:", data_file.split_offsets)
print("equality_ids:", data_file.equality_ids)
print("sort_order_id:", data_file.sort_order_id)출력 예시는 아래와 같습니다.
content: DataFileContent.DATA
file_path: s3://test.parquet
file_format: FileFormat.PARQUET
partition: Record[]
record_count: 36587576
file_size_in_bytes: 394277708
column_sizes: <pyiceberg.utils.lazydict.LazyDict object at 0x11240f2b0>
value_counts: <pyiceberg.utils.lazydict.LazyDict object at 0x11240dd50>
null_value_counts: <pyiceberg.utils.lazydict.LazyDict object at 0x11240f970>
nan_value_counts: {}
key_metadata: None
split_offsets: [4, 135600871, 274300659]
equality_ids: None
sort_order_id: 0S3 Path, 파일의 records, file size 등 다양한 정보를 확인할 수 있습니다.
Data File 실제 데이터 읽기
메타데이터뿐 아니라 실제 Data File 내용도 직접 조회할 수 있습니다. file_path에 있는 Parquet 파일을 PyArrow와 S3FS를 활용해 열어보면 됩니다.
import pyarrow.parquet as pq
import s3fs
fs = s3fs.S3FileSystem()
scan = table.scan()
file_path = "s3://test.parquet"
pq_table = pq.read_table(file_path, filesystem=fs)
print(pq_table.to_pandas().head())이렇게 하면 Data File 내부 데이터를 Pandas DataFrame 형태로 바로 확인할 수 있습니다.

정리하자면 S3 Tables는 AWS 콘솔에서 직접 객체를 탐색할 수 없지만, REST Endpoint와 PyIceberg를 활용하면 메타데이터 및 파일 목록에 접근할 수 있습니다. 운영 환경에서 Iceberg 테이블을 효율적으로 관리하려면 파일 단위까지 들여다보는 것이 매우 중요합니다.
Iceberg 모니터링 전략
Apache Iceberg 테이블을 운영하다 보면 Small File 문제가 성능에 큰 영향을 미친다는 점을 반드시 고려해야 합니다. 특히 쿼리 성능 저하, 스캔 비용 증가, Compaction 효율 저하 등으로 이어질 수 있기 때문에, 지속적인 모니터링 체계를 구축하는 것이 필수적입니다.
AWS에서 제공하는 S3 Tables는 별도의 모니터링 서비스나 관리 지표를 제공하지 않기 때문에 리멤버에서는 PyIceberg를 활용해 직접 Iceberg 메타 정보를 수집하고, 이를 기반으로 모니터링 시스템을 구성했습니다.
모니터링 지표
Iceberg 성능에 영향을 주는 핵심 요소로, 다음 3가지 지표를 정의했습니다.
- Total File Count
- 테이블의 전체 데이터 파일 개수
- Small File Count
- Target File Size(512MB)의 75% 미만인 파일 개수
- Compaction이 정상적으로 동작하고 있는지 확인하는 핵심 지표
- Average File Size
- 평균 파일 크기
- Target File Size(512MB)에 얼마나 근접하게 병합되고 있는지 확인 가능
수집 주기는 10분 단위로 설정하여 최종적으로는 위 지표들을 모니터링 대시보드에 시각화하여 운영자가 직관적으로 확인할 수 있도록 했습니다.
- Compaction 주기 및 패턴 확인
- Snapshot 관리 상태 확인
- 특정 시점 Small File 급증 추적
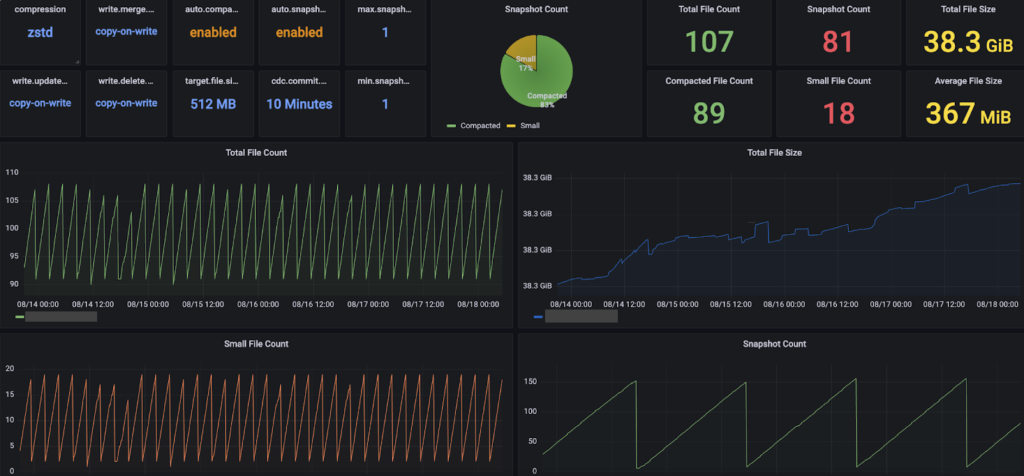
S3 Tables의 경우, Maintenance 주기나 횟수를 AWS에서 공식적으로 제공하지 않고 있습니다. 따라서 자체 모니터링을 통해 Compaction과 Snapshot 관리가 정상적으로 동작하는지 확인하는 것이 매우 중요합니다.
지표 외에도 S3 Tables Maintenance 로그를 지속적으로 수집했습니다. 이 두 가지를 결합하면, AWS가 제공하지 않는 운영 가시성을 확보할 수 있고 Iceberg 기반 데이터 레이크 성능을 안정적으로 유지할 수 있습니다.
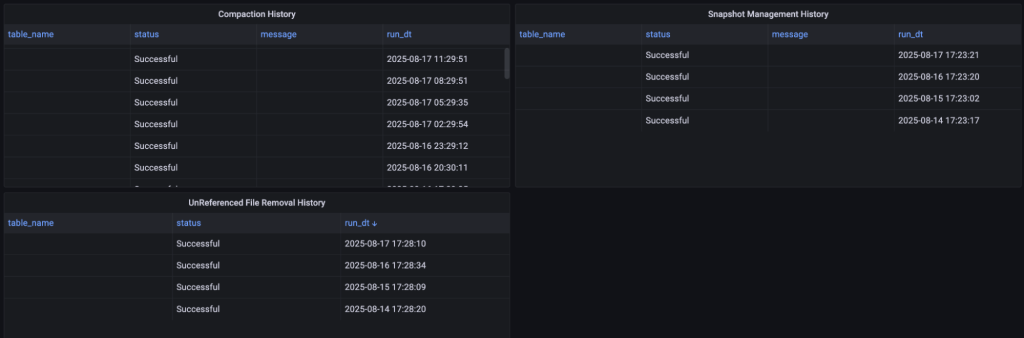
StarRocks On EKS 도입
리멤버는 S3 Tables의 성능을 극대화하고 실시간 분석 효율성을 높이기 위해 StarRocks를 도입했습니다.
기존 분석 환경은 Presto On Amazon EMR / Amazon Athena 두 가지를 사용했습니다. S3에 Parquet 형태로 파일이 적재되고, Analysts 분들에게는 Presto, Batch 목적의 무거운 워크로드에선 Athena가 사용되고 있었습니다.
성능 자체에는 크게 문제가 없었지만, 운영상 비효율적인 부분들이 몇 가지 존재했습니다.
1. Presto on Amazon EMR
- 실시간 변경사항을 조회하기 위한 MySQL Federation 필요 → 쿼리 부하 발생
- c7g.4xlarge 인스턴스를 여러 대 운용 → 성능 대비 높은 운영 비용
- S3 Tables 연계 사례가 부족 -> 안정적인 운영이 어려움
2. Amazon Athena
- 비싼 데이터 스캔 비용
- Warming 과정으로 인해 실시간 스트리밍 분석 용도에 적합하지 않음
또한 내부 시스템이 개선되면서 기존에 Amazon Opensearch Service로 제공하던 검색 엔진을 대체할 정도의 성능 요구 사항이 생겼으나, Presto와 Athena 환경에서는 SLA 1초 이내의 응답 속도를 충족 시키기 어려웠습니다.
이러한 이유로 새로운 엔진 도입을 검토하게 되었고 다양한 테스트 과정을 거쳐 아래의 이유로 StarRocks를 차세대 분석 환경으로 선정하게 되었습니다.
- Iceberg(S3Tables) 지원 기능을 충분히 제공
- 실시간 분석과 저지연 쿼리 지원
StarRocks란?
StarRocks는 실시간 분석(Real-Time Analytics, OLAP) 을 위해 설계된 MPP(Massively Parallel Processing) 분산 데이터베이스로 단순한 쿼리 엔진을 넘어, 데이터 저장과 쿼리 처리, 고성능 분석을 통합 제공합니다.
몇 가지 주요 기능들에 대해 설명드리겠습니다.
- 자체 스토리지와 다양한 외부 카탈로그 사용 가능
- 분산 OLAP 데이터베이스로 실시간 분석과 Low-latency 쿼리 지원
- in-place CRUD 방식을 사용한 predicate pushdown
- SIMD 명령을 사용한 벡터화된 쿼리 엔진 사용
- Materialized View, Bitmap 인덱스, Query Rewrite 등 분석 성능 극대화를 위한 다양한 기능 제공
이렇게 분석을 위한 다양한 기술들을 제공합니다. 이 StarRocks를 운영하면서 Presto On EMR 대비 장점으로 느낀 점은 크게 4가지가 있습니다.
- K8S 기반 컨테이너 오케스트레이션으로 필요할 때 Pod 단위로 확장 가능
- Shuffle에 대한 제약이 적어, 필요할 때만 Pod를 확장할 수 있어 EMR 장기 클러스터 유지 비용 절감
- Low-latency 지원으로 인한 빠른 쿼리 실행 속도
- MySQL 프로토콜을 지원
StarRocks는 Operator를 활용해 클러스터를 자동으로 배포·확장할 수 있어 Pod 관리가 간편했습니다. 필요할 때만 Pod를 확장할 수 있기 때문에 Presto 대비 비용도 저렴했습니다. Materialized View, Bitmap 인덱스를 이용하면 특정 구간에선 Opensearch를 능가하는 성능을 보여주었습니다.
무엇보다도 MySQL 프로토콜을 지원하기 때문에 기존 Aurora MySQL을 사용할 경우 Host 정보만 바꾸는 것으로 기존 워크로드를 수정할 수 있었습니다.
StarRocks 아키텍쳐
StarRocks는 고성능 MPP(Massively Parallel Processing) 아키텍처를 기반으로 하며, 세 가지 주요 컴포넌트로 구성됩니다.
- FE (Frontend)
Frontend는 클러스터의 메타데이터 관리와 쿼리 계획(Query Planning) 을 담당합니다.
SQL 파서를 통해 쿼리를 분석하고 실행 계획을 생성하며, 사용자의 인증 및 권한 관리도 수행합니다. - BE (Backend)
Backend는 실제 데이터 저장 및 쿼리 실행(Execution) 을 담당하는 노드입니다.
FE가 만든 실행 계획을 받아 병렬로 데이터를 스캔하고 집계합니다. - CN (Compute Node)
Compute Node는 StarRocks 3.x 버전부터 도입된 구성 요소로, 스토리지와 컴퓨팅을 분리(Decoupled Architecture) 하기 위한 노드입니다.
BE와 달리 데이터를 직접 저장하지 않고, 외부 스토리지(S3, HDFS 등)에 저장된 데이터를 읽어 서버리스 형태로 쿼리 실행만 수행합니다.
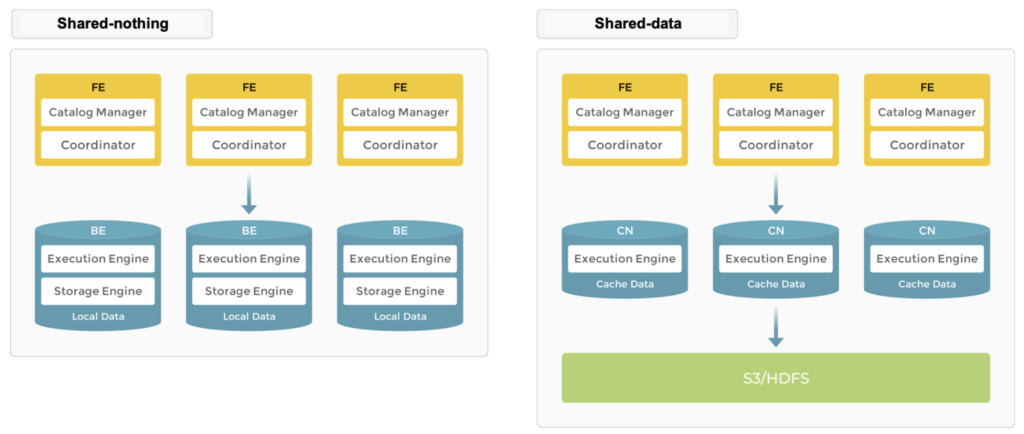
Starrocks의 아키텍쳐는 스토리지 관리 방식에 따라 Shared-nothing 과 Shared-data 로 구분할 수 있습니다. 그리고 선택한 방식에 따라 BE와 CN 중 어떤 노드를 사용할지 결정됩니다.
Shared-nothing 방식에서 BE 노드에는 로컬 스토리지에 데이터를 분산 저장합니다. 데이터에 직접 액세스 하기 때문에 초고속 쿼리 및 분석 성능을 제공합니다. 또한 다중 복제본 데이터 저장을 지원하여 동시성을 향상시키고 데이터 안전성을 보장하기 때문에 최적의 쿼리 성능을 추구하는 시나리오에 적합합니다.
Shared-data 방식은 공유 스토리지를 사용합니다. 스토리지와 컴퓨팅이 분리되어 있으므로 데이터 리밸런싱 없이 CN 노드를 추가하거나 제거할 수 있습니다. S3 같은 저렴하고 안정적인 원격 스토리지를 사용하기 때문에 비용 효율적이며 CN 노드는 컴퓨팅 작업과 핫 데이터 캐싱 담당하여 캐시가 적중되면 쿼리 성능은 Shared-nothing 방식과 유사합니다.
리멤버에서는 StarRocks Operator를 사용해 EKS 위에 Shared-data 방식으로 구축했습니다. 이 결정의 배경은 크게 두 가지 이유가 있었습니다.
- S3 Tables를 외부 카탈로그로 사용
- Pod 단위로 CN 노드 수평 확장 가능
첫 번째로 리멤버는 CDC를 이용한 데이터 레이크 저장소로 S3 Tables를 사용하고 있었기 때문에 로컬 스토리지를 사용할 필요가 없었습니다. 쿼리 결과를 실제 물리적인 테이블 형태로 저장하는 Materialized View 나 메모리 부하를 최소화하기 위해 중간 결과를 스토리지에 저장하는 Disk Spill 기능을 위해 사용하고 있습니다.
아래는 StarRocks에서 S3 Tables를 외부 카탈로그로 등록하는 방법입니다.
하나 유용한 팁을 공유드리자면, JDBC Client를 이용해 접속하시게 되면 default_catalog로 연결되기 때문에 S3 Tables 카탈로그가 보이지 않습니다. 이때 sessionVariables로 catalog를 S3 Tables로 매핑해주시면 MySQL DB처럼 S3 Tables를 사용하실 수 있습니다.
두 번째로 리멤버에서는 기존 인프라에 EKS를 사용하고 있었습니다. Operator를 사용하면 Pod 단위로 노드를 추가하거나 리소스를 간편하게 증설할 수 있습니다. 추가된 노드는 기존 데이터 파일을 재배치하지 않고 바로 쿼리 처리에 참여할 수 있어 리밸런싱 없이 클러스터 용량을 늘릴 수 있으며 Presto와는 달리 노드를 추가하면서 발생하는 Shuffle 과정이 없어 초 단위 확장이 가능했습니다.
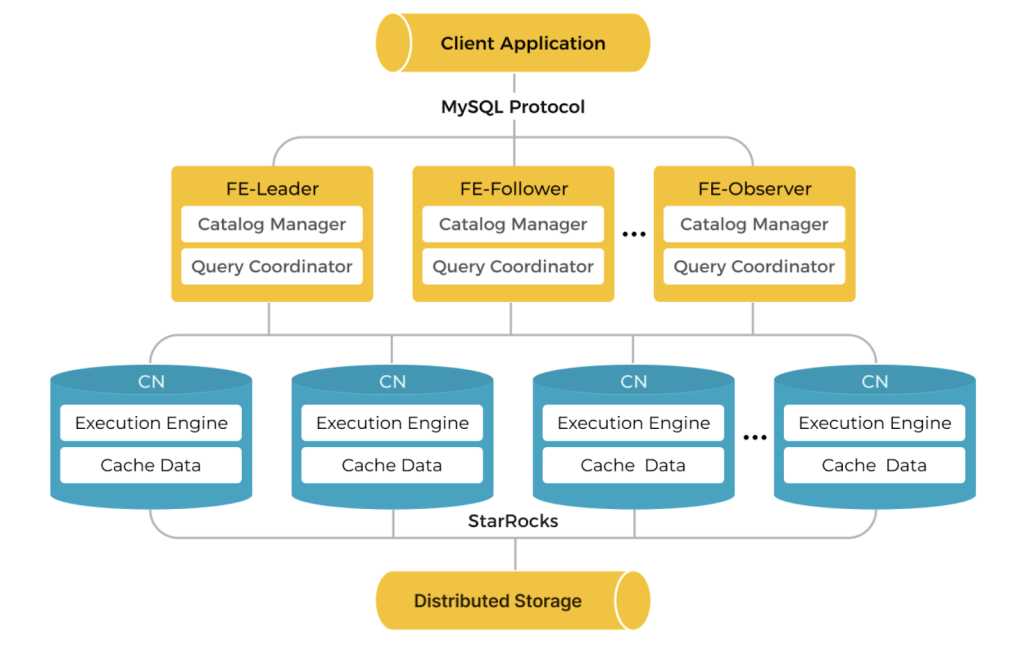
StarRocks에서는 성능 최적화를 위해 Iceberg Table의 메타데이터 캐시를 지원하고 있습니다. Cache TTL을 매 쿼리 실행 시마다 S3 Tables에서 메타데이터 파일을 다시 읽는 비용을 절감하여 성능을 극대화할 수 있습니다.
- enable_iceberg_metadata_cache : Iceberg 메타데이터 캐시 기능 활성화 여부
- iceberg_table_cache_ttl_sec : 테이블의 스키마 & 프로퍼티 정보를 캐싱하는 TTL
- iceberg_meta_cache_ttl_sec : 메타데이터 파일(metadata.json) 캐싱 TTL
- iceberg_manifest_cache_max_num : Manifest 파일 캐시의 최대 개수
여기서 주의해야할 점은 TTL 설정 시 CDC Commit 주기보다 길게 설정할 경우 Commit 반영 후에도 캐시가 갱신되지 않아 변경되지 않은 데이터를 읽게 된다는 점입니다. 따라서 Commit 주기보다 짧게 설정하시는 것을 권장드려며, 비즈니스 목적에 맞는 올바른 균형점을 찾으시면 됩니다.
마무리
2부에서는 이전 1부에서 소개한 MySQL에서 S3Tables로의 마이그레이션 이후, 이를 효율적으로 관리하기 위한 실제 운영 전략 그리고 StarRocks라는 분석 엔진을 구축하는 방법에 대해 다뤘습니다.
리멤버에서는 S3 Tables 기반 Iceberg 포맷을 도입하면서 데이터 파이프라인의 효율성과 성능이 크게 개선되었습니다. Full Refresh 대신 변경 데이터(CDC)만 반영하는 구조를 통해 수 분 단위의 실시간 분석이 가능해졌고 Aurora MySQL에서 수십 분 이상 걸리던 대용량 분석 쿼리도 StarRocks를 통해 초 단위로 처리할 수 있게 되었으며, 분석 부하를 Reader 인스턴스에서 StarRocks로 이전하면서 운영 DB의 안정성도 함께 향상되었습니다.
향후 계획
현재 리멤버는 EMR과 Sqoop을 이용한 Full Refresh 파이프라인과 S3 Tables 기반 Incremental 파이프라인을 병행 운영하고 있습니다. 향후에는 모든 분석 작업을 S3 Tables와 StarRocks로 전환할 계획입니다.
이 사례가 실시간 대용량 분석으로 인해 어려움을 겪는 기업에게 재현할 수 있는 벤치마크가 되길 기대합니다.