AWS 기술 블로그
Amazon SageMaker AI로 해보는 GPT-OSS 추론 성능 테스트와 용량 산정
SageMaker AI 와 LLM 추론 개요
Amazon SageMaker AI는 데이터 과학자와 개발자를 위한 완전 관리형 ML 플랫폼 서비스입니다. 실험부터 배포까지 전체 ML 개발 과정을 단일 환경에서 처리할 수 있습니다. 필수 AI 라이브러리가 미리 설치된 주피터 노트북 포함하여 다양한 IDE를 지원하기 때문에 선호도에 맞는 개발 환경을 선택할 수 있습니다. 개발자들은 복잡한 인프라 관리에 대한 부담 없이 모델 개발에 좀 더 집중할 수 있으며, 이를 통해 AI 프로젝트의 실험과 배포 과정을 단축시키고 효율화 할 수 있습니다. 본 블로그에서는 Amazon SageMaker AI 환경에서 최근 공개된 오픈 웨이트 모델인 GPT-OSS 120B를 활용한 추론 성능 테스트와 GPU 용량 산정 방법을 알아보고자 합니다. LLM 추론의 동작 단계를 이해하고, 추론 최적화 기법과 성능 지표를 살펴본 후, 대표적인 오픈소스 추론 프레임워크인 vLLM과 SGLang을 활용한 실제 워크로드 테스트를 수행하고 분석하겠습니다. 이를 통해 실제 서비스 환경에서 요구사항에 맞는 LLM 추론 인프라를 구축하는 데 필요한 인사이트를 제공하고자 합니다.
LLM 추론 동작 방식
LLM의 추론은 프리필(Prefill)과 디코드(Decode)라는 두가지 단계를 통해 작동하며, 각 단계는 서로 다른 특성과 계산 패턴을 가집니다. 프리필 단계는 사용자가 LLM에 프롬프트를 입력할 때 시작됩니다. 이 단계에서 모델은 모든 입력 토큰을 동시에 처리하며, 병렬로 행렬-행렬 연산을 수행합니다. 이러한 병렬 처리는 토큰 생성의 기초가 되는 키-값(KV) 쌍의 중간 상태 값을 계산할 때 GPU를 효율적으로 활용할 수 있게 합니다. 이는 마치 모델이 입력 컨텍스트를 한 번에 종합적으로 이해하려는 노력과 같습니다.
프리필 이후에는 디코드 단계가 시작되어 실제 토큰 생성이 이루어집니다. 이 단계는 자기회귀적(Autoregressive) 방식으로 작동하며, 각각의 새로운 토큰은 이전에 생성된 모든 토큰에 의존합니다. 프리필의 병렬 처리와는 달리, 디코드 단계에서는 한 번에 하나의 토큰을 생성하는 순차적인 행렬-벡터 연산을 수행합니다. 이러한 순차적 프로세스로 인해 프리필 단계에 비해 GPU 활용도가 낮아집니다.
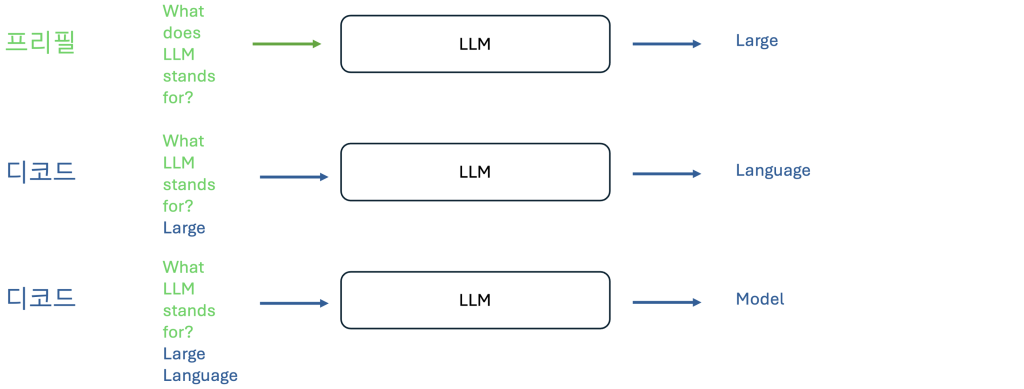
디코드 단계의 중요한 특징중의 하나로 메모리 대역폭 바운드(memory-bandwidth bound)를 들 수 있습니다. 성능 병목이 GPU 계산 속도가 아닌 메모리와 GPU 간의 데이터 전송에서 발생하기 때문입니다. 시스템은 가중치, 키-값 쌍, 활성화(Activation) 데이터를 메모리에서 GPU로 지속적으로 이동시켜야 하며, 실제 GPU에서 계산하는 시간보다 데이터 전송의 지연 시간이 더 많이 소요 되어서 성능 측면에서 더 중요한 관리 요소 입니다.

효과적인 키-값 캐시(KV Cache) 관리는 LLM 추론의 효율성을 향상시키는 핵심 메커니즘입니다. 프리필 단계에서는 입력 프롬프트의 모든 토큰을 병렬로 처리하여 생성된 키-값 쌍을 캐시에 저장합니다. 이후 디코드 단계에서는 새로운 토큰을 하나씩 생성할 때마다 이전에 저장된 키-값을 재사용함으로써 중복 계산을 제거하고 처리 효율성을 극대화합니다. 메모리 대역폭 바운드 특성을 갖는 디코드 단계에서, 키-값 캐시는 이미 계산된 결과를 메모리에 유지함으로써 불필요한 데이터 전송과 재계산을 최소화하며 메모리 효율성과 추론 속도를 동시에 개선합니다. 특히 GPT-OSS-120B 같은 대규모 모델에서는 메모리 대역폭 바운드 현상이 심화되기 때문에 이러한 최적화가 더욱 중요합니다.
추론 최적화 기법
LLM 추론 최적화는 모델의 성능을 유지하면서 계산 효율성, 메모리 사용량, 지연 시간과 처리량을 개선하는 과정이라고 할 수 있습니다. 이러한 최적화 과정을 수행하기 위한 기술들은, 크게 모델 경량화, 추론 과정 최적화, 하드웨어 가속으로 구분할 수 있습니다.
모델 경량화의 주요 기술로는 양자화(Quantization), 가지치기(Pruning), 지식 증류(Knowledge Distillation)등이 있습니다. 양자화는 가중치의 정밀도를 낮추고, 가지치기는 중요도가 낮은 연결을 제거하며, 지식 증류는 대형 모델의 지식을 소형 모델로 전달합니다. 경량화 기술은 모델의 크기와 연산 량을 줄이면서도 핵심 기능과 성능을 최대한 보존하는 것을 목표로 합니다.
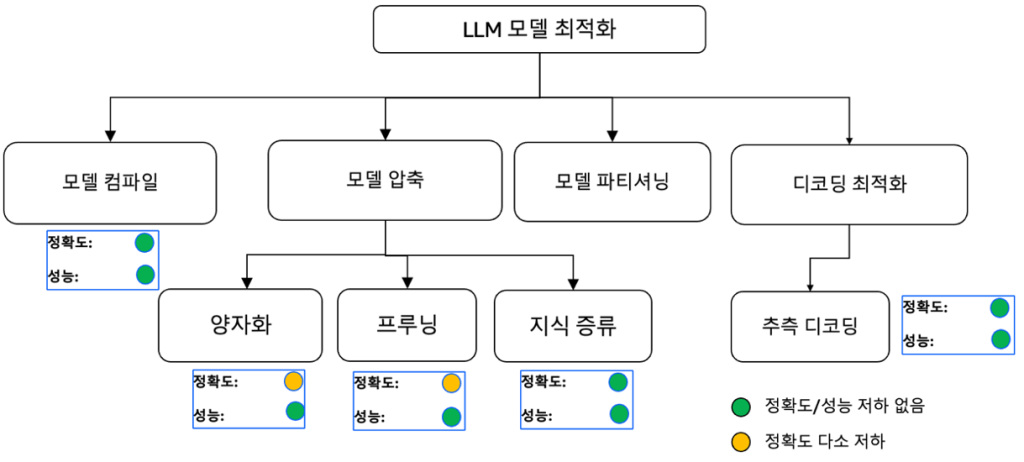
추론 과정을 최적화하는 기술로는 이전에 계산된 키-값 쌍을 저장하여 재 활용하는 키-값 캐싱이 있습니다. 이를 발전시킨 프리픽스 캐싱(Prefix Caching)은 자주 사용되는 프롬프트의 키-값 계산 결과를 미리 저장하여 재사용함으로써 계산 비용을 절감하는 기술입니다. 또한 텐서 병렬(Tensor Parallel), 파이프라인 병렬(Pipeline Parallel) 등의 다수의 GPU를 사용하여 병렬로 추론 작업을 실행하는 기술이 있습니다. 추론 처리량을 높이기 위하여 배치 처리를 효율화 하는 기술로 연속 배치 처리(Continous Batch)와 페이지드 어텐션(Paged Attention) 등이 있습니다. 플래시 어텐션(Flash Attention)은 메모리 접근 패턴을 최적화하여 GPU의 SRAM을 효율적으로 활용하고 메모리 대역폭 사용량을 줄이는 기술입니다.
연속 배치 처리와 페이지드 어텐션은 초창기에 LLM 추론 처리량을 획기적으로 개선하여 발자취를 남긴 기술이며 지금은 대부분의 LLM 추론 프레임워크에 기본 탑재 및 적용된 기법이 되었습니다.
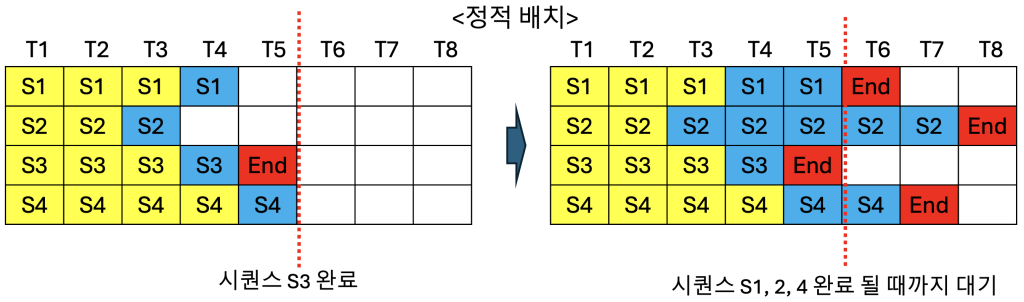
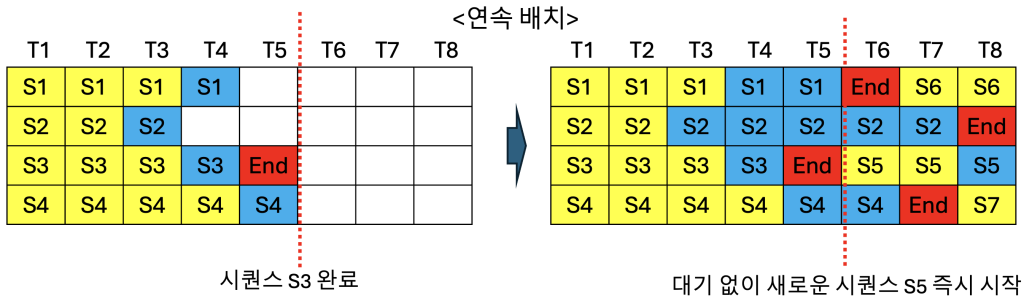
아래 그림을 통해서 정적 배치 처리와 연속 배치 처리의 차이점을 좀 더 설명드리겠습니다. GPU에서 한번에 동시 처리할 수 있는 시퀀스(프롬프트 요청)의 수가 배치 크기입니다. 여기에서는 배치 크기를 4로 가정하였습니다. 노란색은 프리필 단계의 토큰이고, 파란색은 디코드 단계의 토큰을 의미합니다. 위의 정적 배치 그림을 보면, 시간축 T1부터 T5까지 4개의 시퀀스(S1, S2, S3, S4)가 처리됩니다. T5 시점에서 시퀀스 S3은 End 토큰으로 완료되었지만, 배치 내의 다른 시퀀스 S1, S2, S4가 아직 완료되지 않았습니다. 정적 배치 방식에서는 배치 내 모든 시퀀스가 완료될 때까지 기다려야 하므로, S3이 완료된 후에도 S1, S2, S4가 모두 End에 도달하기까지 새로운 시퀀스를 받아들일 수 없습니다. 오른쪽 그림을 보면 T6, T7, T8 시점에 빈 슬롯이 발생하면서 GPU 자원이 낭비되는 것을 확인할 수 있습니다. 동일 배치 내의 시퀀스 4개의 길이, 즉 토큰 수가 모두 같으면 문제가 없겠지만 현실적으로는 다르기 때문에 정적 배치에서 GPU 자원 낭비는 필연적입니다. 반면 아래의 연속 배치 그림에서는 동일하게 T5 시점에서 S3 시퀀스가 End 토큰으로 완료되지만, 즉시 새로운 시퀀스 S5가 배치에 추가되어 T6부터 처리가 시작됩니다. T6 시점에서는 S1이 완료되어 새로운 시퀀스 S6이 추가되고, T7에서 S4가 완료되면서 S7이 즉시 투입됩니다. 이처럼 연속 배치 방식은 각 시퀀스가 완료되는 즉시 대기 중인 새로운 시퀀스로 해당 슬롯을 채울 수 있어, GPU 자원의 활용도를 높일 수 있습니다.
페이지드 어텐션은 운영체제의 가상 메모리 페이징 기법에서 착안하여 키-값 캐시 메모리 관리를 최적화하는 기술입니다. 기존 방식은 각 시퀀스의 최대 길이를 예측하여 연속된 메모리 공간을 미리 할당해야 했기 때문에, 실제 생성 토큰이 적을 경우 메모리 낭비가 발생하고, 크기가 다른 메모리 블록들로 인한 메모리 단편화 문제가 있었습니다. 아래 그림은 시퀀스 A의 프롬프트 “Alan Turing is a computer scientist”에 대해 “and mathematician renowned for”를 출력하는 상황입니다. 왼쪽 하단의 논리적(Logical) 키-값 캐시 블록은 각 토큰의 키-값 쌍을 순차적으로 저장하고, 중앙의 블록 테이블(Block table)은 논리적 블록과 물리적 블록을 매핑합니다. 논리 블록 0, 1, 2는 각각 물리 블록 7, 1, 3에 매핑되며, 오른쪽의 물리적(Physical) 키-값 캐시 블록에서 나머지 블록들(Block 0, 2, 4, 5, 6)은 비어있어 다른 시퀀스가 사용할 수 있습니다. 이러한 페이지드 어텐션은 키-값 캐시를 고정 크기의 블록 단위로 관리하여 메모리 단편화를 방지하고, 논리적 블록과 물리적 블록을 분리하여 토큰 생성량에 따라 동적으로 블록을 할당함으로써 메모리 낭비를 최소화합니다. 결과적으로 GPU 메모리를 효율적으로 활용하여 더 많은 시퀀스를 동시에 처리할 수 있어 추론 처리량이 향상됩니다.
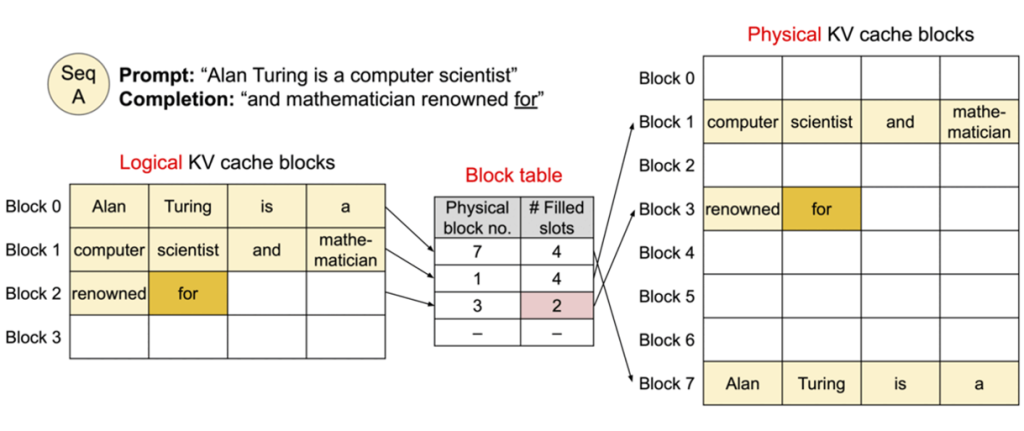
<출처: vLLM 블로그>
최근에 관심을 받고 있는 추론 성능 고도화 기술인 분산 비분리 프리필링(Disaggregated Prefilling)은 프리필과 디코드 단계를 물리적으로 분리하여 처리하는 최적화 방법입니다. 프리필과 디코드를 별도의 서버에서 처리하고 키-값 캐시를 비동기로 전송하는 방식으로 하여 처리량을 개선하며, 대규모 GPU 시스템 환경에서 더욱 효과적입니다.
세번째로 하드웨어 가속 기반 최적화 기술은 CUDA 커널 최적화, 메모리 접근 패턴 개선, 연산 융합 등을 포함하며, 일반적으로 LLM 모델이 GPU나 CPU의 특수 하드웨어 기능을 활용하여 동작하도록 추가적인 모델 컴파일 과정이 필요합니다. AWS의 Inferentia 가 하드웨어 가속 기반 최적화 기술에 해당하며 일반적인 EC2 인스턴스 대비 저렴한 비용으로 훨씬 더 높은 처리량을 제공합니다.
이러한 최적화 기법들은 단독으로 사용되지 않고 상호 보완적으로 조합 적용 되어 최적의 효과를 발휘하며, 제한된 컴퓨팅 리소스 환경에서도 LLM을 효율적으로 배포하고 운영할 수 있도록 해줍니다.
추론 성능 지표
이번에는 추론의 성능을 판단할 몇 가지 지표들을 살펴보겠습니다. 성능 지표는 지연 시간(Latency)과 처리량(Throughput) 지표로 구분해볼 수 있는데요. 지연 시간 지표로 TTFT(Time To First Token), ITL(Inter Token Latency), TPOT(Time Per Output Token), E2E(End To End Latency)를 주로 사용하고 처리량 지표로는 TPS(Token Per Second)와 RPS(Request Per Second)를 주로 사용합니다.
- TTFT: 프리필 시작 후 첫 번째 토큰을 생성하는 데 소요 되는 시간
- ITL: 첫 번째 답변 토큰이 생성 되고, 이후의 토큰을 순차적으로 생성하는 데 소요되는 시간
- TPOT: 요청 단위로 출력 토큰을 생성하는 데 소요되는 시간
- E2E: 사용자 요청부터 전체 응답 생성이 완료될 때까지의 총 소요 시간
ITL과 TPOT은 모두 토큰 생성 속도를 측정하는 지표이지만, 측정 방식과 관점이 조금 다릅니다. ITL은 연속된 두 토큰 사이의 생성 시간을 개별적으로 측정하여 토큰 간의 실제 지연 시간을 보여주는 반면, TPOT은 전체 출력 토큰 수를 총 생성 시간으로 나눈 평균값으로, 요청 단위의 전반적인 생성 효율성을 나타냅니다. 처리량 측정 지표인 TPS와 초당 동시에 실행할 수 있는 요청 수인 RPS 도 중요하게 관찰 할 성능 지표들입니다.
네트워크 부하나 용량 부족 같은 이슈 상황에서, 서비스 수준 목표(SLO)를 충족하는지 측정하는 지표인 Goodput도 있습니다. 예를 들어, 시스템이 초당 10개의 요청을 처리하였지만 지연 시간 요구사항을 충족하는 것이 3개라면 Goodput은 3이 됩니다.
각 LLM은 서로 다른 토크나이저를 사용할 수 있습니다. 이로 인해 다른 LLM간의 토큰 생성 속도를 직접 비교 하면 오해의 소지가 생길 수 있습니다. 두 모델이 초당 동일한 수의 토큰을 생성하더라도, 토큰화 방식의 차이로 인해 실제 생성되는 텍스트의 양은 다를 수 있다는 점을 참고하시면 됩니다.
오픈 소스 추론 프레임워크
vLLM과 SGLang 은 업계에서 가장 많이 사용되는 대표적인 오픈소스 추론 프레임워크 프로젝트입니다. vLLM 프로젝트가 먼저 시작되어서 많은 저변 확대가 이루어졌으며, 현재는 커뮤니티 지원, 사례, 문서화 등 LLM 추론 분야에서 가장 활성화된 오픈소스 프로젝트가 되었습니다. SGLang은 상대적으로 최근에 시작되었지만, 시작하자마자 높은 추론 성능으로 주목을 받았습니다. 2024년 7월 SGLang 블로그에 게시한 vLLM과의 성능 테스트 비교 자료에 의하면 SGLang은 당시 vLLM 버전인 0.52 대비 최대 약 3배의 추론 성능 차이를 만들었습니다. 성능 차이에 기여한 기술 중의 하나로 SGLang의 라딕스 트리(Radix Tree) 기반의 프리픽스 캐싱 알고리즘을 들 수 있습니다. 이전에 사용한 프롬프트 토큰 중 일부만 매칭되더라도 재 사용할 수 있어서 캐시 히트율이 vLLM 캐싱 방식 대비 훨씬 높았습니다. SGLang 소스 코드를 다운로드 하면, 프로젝트내의 벤치마크 디렉토리에 당시 테스트에 사용한 코드들과 방법들이 있어서 직접 재현 테스트를 해볼 수 있습니다. SGLang 블로그의 성능 보고서는 vLLM 진영이 분발하도록 만든 좋은 자극제가 되었으며 vLLM은 불과 2개월만에 성능을 SGLang과 비슷한 수준으로 개선한 0.6 버전을 릴리즈 하였으며, 아래와 같은 성능 벤치마크 결과도 공개하였습니다.
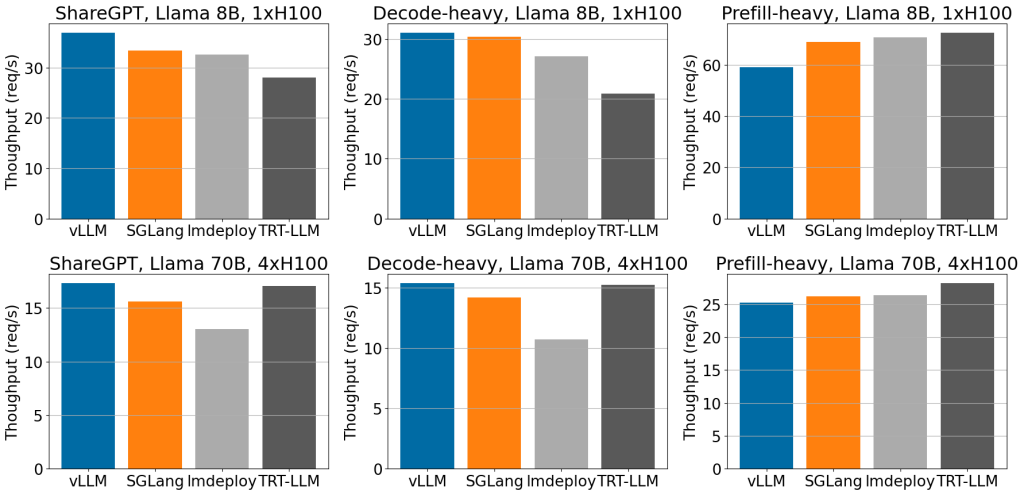
<출처: vLLM 블로그>
이후에도 vLLM과 SGLang은 선의의 경쟁을 하면서 지속적으로 성능을 개선하면서 발전해 왔습니다. vLLM은 성능 개선 작업을 진행함과 동시에 새로운 아키텍처인 V1 엔진 설계와 개발을 착수하였고, 25년 1월 V1 아키텍처 알파버전을 공개한 이후에는 V1상에서 성능 개선을 진행하고 있습니다. V1 아키텍처의 주요 개선점을 요약하면 다음과 같습니다.
- 중앙집중식 통합 스케줄러를 도입을 통한 전역 최적화
- v0의 약점으로 알려졌던 프리픽스 캐싱과 청크드 프리필(Chunked Prefill) 개선으로 메모리 효율성 향상
- 연속 배치와 다양한 추측 디코딩(Speculative Decoding) 지원을 통해 처리량 개선
- 전문가 혼합(Mixture-of-Experts) 모델 최적화와 향상된 멀티모달 지원
두 프로젝트에는 앞서 소개한 다양한 추론 최적화 기법들이 구현 되고 테스트 되었습니다. 본 블로그에서도 LLM 추론 성능 측정에 두 프로젝트의 프레임워크를 사용하려고 합니다.
GPU 메모리 용량 산정
성능 테스트를 하기 전에, 추론 서버에서 GPU 메모리가 어떻게 사용되는 지를 살펴보겠습니다. 추론 서버 구동 시, 아래와 같은 매개 변수들을 저장하기 위한 메모리 공간이 GPU에 할당 됩니다. 추론 단계에서는 GPU 메모리의 대부분을 차지하는 모델 파라미터, 키-값 캐시, 입력 데이터, 활성화 함수와 출력 데이터 처리를 위한 메모리 공간이 필요합니다. 목표 출력과 그레이디언트, 옵티마이저 등은 모델 학습 시에 필요한 GPU 메모리입니다.
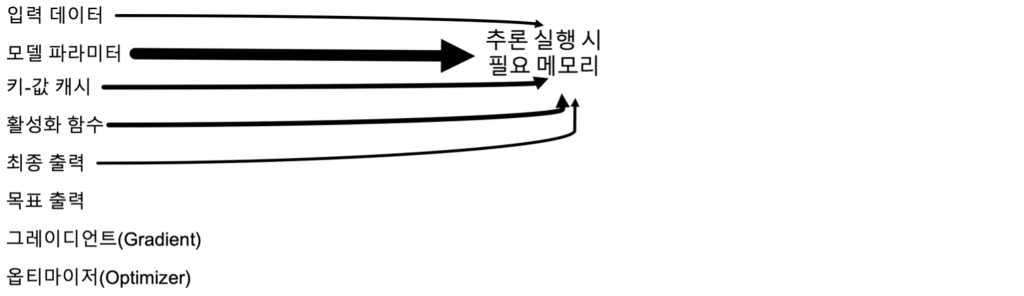
모델 추론 시에 필요한 메모리는 아래처럼 산출해 볼 수 있습니다. 일반적인 트랜스포머 모델을 가정하였기 때문에 모델 아키텍처나 최적화 기법 적용 여부에 따라 수식은 조금 달라질 수 있습니다. 배치 크기는 모델이 한 번에 처리하는 요청(프롬프트) 수입니다. 시퀀스 길이(sequence length)는 한번의 입력당 최대 토큰 수이며 모델 컨텍스트 크기에 근접합니다. 활성화(Activations)는 순전파 과정에서 발생하는 모델 레이어의 중간 출력 값이며 배치 크기, 시퀀스 길이, 은닉 차원의 크기, 모델 아키텍처의 특성에 영향을 받습니다. 추론 시에는 레이어를 순차적으로 처리하므로 한 번에 1개 레이어의 활성화 메모리만 필요하며, 메모리 공간을 재사용하는 것을 가정하였습니다. 또한 어텐션 메모리는 플래시 어텐션 같은 메모리 최적화 기법을 적용하는 것을 가정하였습니다.
- 모델 파라미터 메모리 = 비트 정밀도 x 총 파라미터 수
- 키-값 캐시 메모리 = 배치 크기 x 비트 정밀도 x 레이어 개수 x 헤드 차원 수 x 키-값 헤드 개수 x 시퀀스 길이 x 2
- 활성화 메모리(레이어당) = 어텐션 메모리 + 피드포워드망(FFN) 메모리
- 어텐션 메모리 = 배치 크기 x 비트 정밀도 x 시퀀스 길이 x 은닉 차원 수 x 5
- 피드포워드망 메모리 = 배치 크기 x 비트 정밀도 x 시퀀스 길이 x (은닉 차원 수 x 2 + 피드포워드망 중간 은닉 차원 수 x 2)
- 입력 데이터 메모리 = 배치 크기 x 비트 정밀도 x 입력 토큰 수
- 출력 데이터 메모리 = 배치 크기 x 비트 정밀도 x 출력 토큰 수
아래와 같은 파라미터 구성을 갖는 라마 3.1 405B 모델을 대상으로 계산 해보겠습니다.

이제 GPT-OSS 120B 모델의 추론 테스트를 해볼 수 있도록 소프트웨어를 설치하고 모델 서버를 구동해 보겠습니다. GPT-OSS 모델을 원활하게 구동하고 테스트 하기 위해서 아래 사양의 ml.g6.48xlarge와 ml.p4de.24.xlarge를 테스트용 인스턴스로 선택하였습니다.
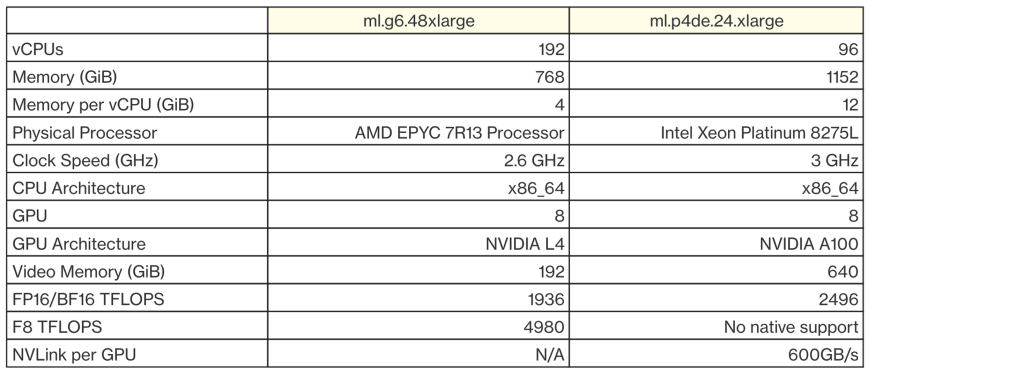
SageMaker AI의 노트북 생성 화면에서 OS로는 “Amazon Linux 2023, Jupyter Lab” 옵션을 선택하고, 디스크 용량은 500GB 로 설정한 후 인스턴스를 생성 합니다. 인스턴트 생성이 완료 되면 주피터랩의 Launcher를 통하여 터미널창을 실행합니다.

터미널에서 인스턴스에 사전 설치된 Conda를 이용해서 아래의 스크립트를 실행하여 가상 환경을 만들고 vllm 을 설치합니다.
비슷한 방식으로 아래의 스크립트를 실행하여 SGLang 프레임워크를 설치합니다.
선택적으로 터미널이 아닌 주피터 노트북 상에서 여러가지 실험을 하고 싶을 경우, 아래와 같이 활성화 설정을 하면 Conda로 조금 전에 생성한 vllm 가상환경이 보입니다.
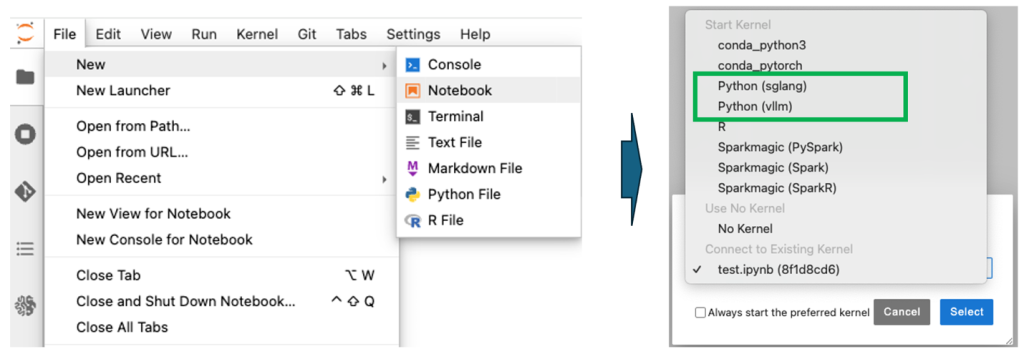
추가적으로 아래처럼 Conda가 아닌 uv 환경에서 설치하고 테스트 하는 것도 가능합니다.
본 블로그에서는 Conda 환경으로 테스트 하겠습니다.
블로그 작성 시점의 vLLM의 버전은 0.11.0이고 SGLang은 0.53입니다. 설치를 완료했으니 vLLM과 SGLang 추론 서버를 구동해보겠습니다. 앞서 살펴본 다양한 추론 최적화 옵션을 적용하여 OpenAI API 호환 모드로 구동 하려고 합니다. 먼저 vLLM 서버는 아래와 같은 옵션으로 구동할 수 있습니다. 가령 아래의 옵션은 tensor-parallel-size를 8로 설정하여 인스턴스에 탑재된 8장의 GPU를 모두 사용하도록 하였고요. max-model-len을 4096로 설정하여 하나의 프롬프트 요청 당 입력과 출력 토큰을 합해서 4096내에서 사용하도록 구성하였습니다. max-model-length를 크게 설정할 수록 더 긴 응답을 만들어내 낼 수 있지만 그 만큼 더 많은 키-값 캐시 공간도 필요하게 됩니다. gpu-memory-utilization은 0.8로 설정하여 GPU 카드 별 메모리의 80%를 사용하도록 설정하였습니다. p4de.24xlarge 인스턴스의 GPU 카드인 A100의 메모리 용량은 80GB입니다. 모델의 크기, 요청 당 최대 사용 토큰 수를 감안한 키-값 캐시 예상 크기를 바탕으로 사용 계획을 세워야 합니다.
SGLang도 구동 스크립트 문법은 조금 다르지만, 유사한 방식으로 아래처럼 구동할 수 있습니다. ml.g6.48xlarge와 ml.p4de.24xlarge 인스턴스 각각 8장의 GPU 카드가 구성되어 있어서, 텐서 병렬 크기(tp)를 8로 설정한 것 외에는 대부분 기본 설정을 사용하였습니다.
vLLM 서버는 별도로 지정하지 않으면 포트 번호로 8000을 사용하며 SGLang은 30000을 사용합니다. 서버가 구동이 되면 curl 명령을 이용해서 아래와 같이 간단하게 동작 여부를 테스트 해볼 수 있습니다.
본 블로그에서는 특정 최신 버전(vllm 0.11.0, sglang 0.53)을 사용하기 위해서 노트북 인스턴스에서 직접 소프트웨어를 설치 하였지만, SageMaker에서는 이러한 설치 과정 없이 엔드포인트(Endpoint)를 통한 실시간 서빙이 가능합니다. AWS에 관리하는 LMI(Large Model Container) v16을 사용하여 vLLM 0.10.2 버전 기반의 모델 서버를 몇 줄의 코드로 구동할 수 있습니다. 서빙 외에도 오토 스케일링과 무 중단 A/B 테스트 등 서비스에 필수적인 기능들을 제공하여 운영 관리 비용과 복잡도를 줄일 수 있습니다. 테스트를 마친 후 운영 환경에서는 엔드포인트 활용하는 것을 권고합니다.
import boto3
import sagemaker
smr_client = boto3.client("sagemaker-runtime")
role = sagemaker.get_execution_role()
sess = sagemaker.session.Session()
region = sess._region_name
model_name = "<YOUR MODEL NAME>"
image_uri = f"763104351884.dkr.ecr.{region}.amazonaws.com/djl-inference:0.34.0-lmi16.0.0-cu128"
vllm_config = {
"OPTION_MODEL_ID": <YOUR MODEL ID>,
"OPTION_ROLLING_BATCH": "vllm",
"OPTION_TENSOR_PARALLEL_DEGREE": "max",
"OPTION_MAX_ROLLING_BATCH_SIZE": "32",
"OPTION_MAX_INPUT_LEN": "1024",
"OPTION_MAX_OUTPUT_LEN": "2048",
"OPTION_MAX_MODEL_LEN": "2048",
"OPTION_DTYPE": "fp16"
}
create_model_response = sm_client.create_model(
ModelName = model_name,
ExecutionRoleArn = role,
PrimaryContainer = {
"Image": image_uri,
"Environment": vllm_config,
}
)작업 부하 정의 및 벤치마크테스트
추론 서버의 설치와 구동까지 완료하였으며, 이제는 실제 업무와 서비스 환경을 시뮬레이션 할 수 있도록 유사한 워크로드를 잘 정의하는 것이 필요합니다. 목표로 하는 서비스 환경이 동시 사용자가 많은 지, 요청 트래픽은 24시간 균등한지 아니면 집중적으로 몰리는 피크 시간대가 있는지 등을 정의할 수 있고요. 워크로드 부하에 맞는 입력과 출력 프롬프트 토큰 수도 산정해야 합니다. 요구 사항이 명확하지 않을 때에는 공개된 벤치마크 데이터셋을 이용하여 시작하는 방법도 있습니다. 본 블로그에서는 다양한 오픈 데이터셋을 사용할 수 있고 서비스 환경에 맞게 워크로드 부하를 쉽게 정의하고 테스트할 수 있는 vLLM의 벤치마크 도구를 사용하려고 합니다.
아래는 vLLM을 이용한 벤치마크 테스트 예제입니다. GPT-OSS 120B 모델을 로딩한 SGLang 추론 서버를 대상으로, 10명의 동시 사용자 수(max-concurrency), 사용자당 20개씩 총 200개의 프롬프트(num-prompts) 워크로드를 발생 시키는 스크립트입니다. 하나의 프롬프트는 2,048개의 입력 토큰(random-input-len)과 300개의 출력 토큰(random-output-len)을 생성합니다. 프리필 부하를 발생시키는 워크로드라고 할 수 있으며 서비스 환경에 맞도록 모든 수치들을 조절할 수 있습니다.
합성 데이터셋이 아닌 오픈 데이터셋을 사용할 수도 있습니다. vLLM 벤치마크 도구에서는 sharegpt, burstgpt, sonnet, hf 등의 텍스트와 이미지 오픈 데이터셋을 제공하며 위의 dataset-name 옵션의 “random”으로 되어 있는 값을 오픈 데이터셋 이름으로 변경해서 테스트 할 수 있습니다. 위의 스크립트를 실행하면 아래와 같은 결과가 출력됩니다. 총 200개(Successful requests)의 프롬프트가 성공적으로 실행되었으며, 총 처리한 입력 토큰(Total input tokens)은 409,318개, 출력 TPS는 259.92, 프롬프트의 평균 TTFT는 925.48이며 99%의 프롬프트가 TTFT 5223.02 초 내에서 처리가 되었습니다.
워크로드를 좀더 세분화 해서 벤치마크 테스트를 진행 해보겠습니다. 아래와 같이 워크로드를 프리필, 디코드, 일반 대화 3개 유형의 워크로드로 세분화 하여 구성 하였고, 동시 사용자 수를 50, 100, 200명으로 증가 시키면서 성능 추이를 살펴보려고 합니다. 금번에는 추론 서버를 기본 옵션으로 구동하였지만, 긴 입력을 더 작은 청크로 나누어서 메모리 효율성을 향상 시키는 기법인 청크드 프리필 크기(chunked_prefill_size)와 배치 크기(max-num-batched-tokens)를 조절하여 추가적인 성능 개선을 이룰 수 있습니다.
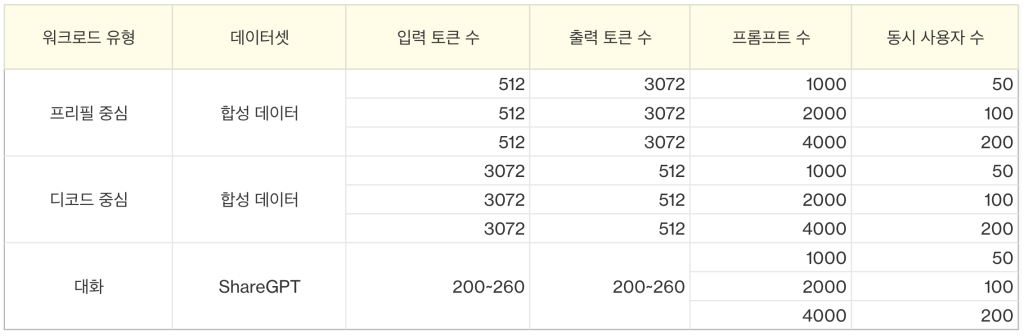
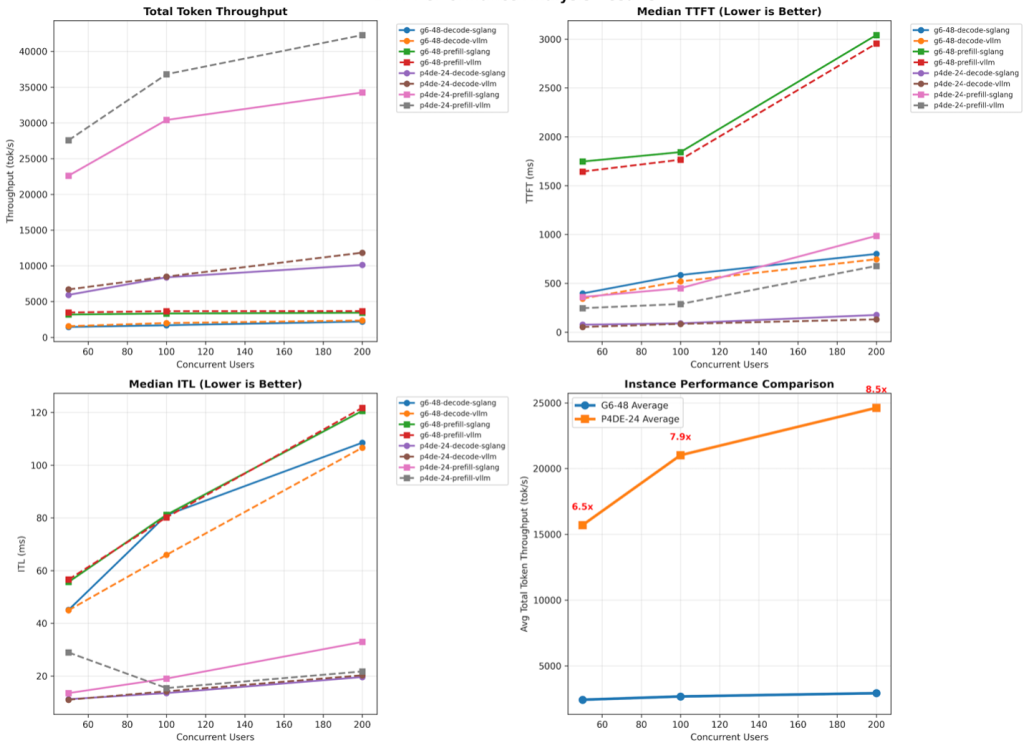
BMT 실행 결과에 대해서 일부 주요 지표들만 정리하면 아래와 같습니다. 프레임워크 간의 비교는 vLLM이 SGLang 대비 전반적으로 좀 더 높은 성능을 보였으며, 인스턴스 간의 성능 비교는 p4de가 g6.48xlarge 대비 처리량, TTFT, ITL 모두 최소 3배에서 10배 정도의 높은 성능 우위를 보였습니다. GPT-OSS-120B 모델에 대해 p4de 인스턴스에서 처리할 수 있는 초당 토큰 처리량은 vLLM 기준 42,283로 나왔으며, 설정과 튜닝을 통해서 더 많은 토큰 처리가 가능할 것으로 보입니다. 전반적으로는 p4de 인스턴스에서 vLLM을 사용한 추론이 성능 지표에서 우위를 보였으며, 특히 디코드 중심 부하 작업에서의 실시간 응답성과 프리필 부하 작업에서 대용량 처리 능력이 높게 나왔습니다.
마무리 하면서
Amazon SageMaker AI 환경에서 GPT-OSS 120B 오픈 웨이트 모델에 대한 추론 성능 테스트와 GPU 용량 산정 방법을 알아보았습니다vLLM과 SGLang이라는 오픈소스 추론 프레임워크를 SageMaker 인스턴스에서 다양한 워크로드 시나리오로 테스트를 수행하였습니다. 이번 성능 테스트 결과 자체보다는 실제 서비스 환경에서 요구사항과 워크로드 특성에 따라 적합한 추론 프레임워크와 하드웨어 인프라를 선택하는 데 참고 자료로 사용하면 될 것 같고요. 앞으로도 LLM 추론 최적화 기술은 계속 발전할 것이기에 효율적인 추론 성능을 위한 다양한 접근법을 지속적으로 탐색해 나가는 것이 중요할 것입니다.