이 블로그 포스트는 삼성전자의 최석원님과 함께 작성되었습니다.
개요
이 블로그는 삼성전자 로봇 설비 데이터 인사이트 혁신, Part 1: Amazon Quick Sight 대시보드 에 이어 삼성전자 로봇 설비 데이터 인사이트 혁신을 위해 Amazon Bedrock AgentCore와 MCP를 활용하여 AI 챗봇을 도입한 여정을 소개합니다. AI 챗봇 도입을 가속화하기 위하여 삼성전자는 AWS PACE팀과 협력하여 Prototyping 프로그램을 통해 구현한 프로토타이핑 결과물을 EBA (Explerience Based Acceleration) 프로그램 을 통해 빠르게 AWS 환경에 배포할 수 있었습니다.
AI 챗봇 도입 배경
삼성전자는 로봇과 대형 키친 설비들이 함께 동작시 발생하는 로그를분석하는 과정에서 여러 어려움에 직면했습니다. 특히 오류 상황이 발생했을 때, 그 원인을 파악하기 위해서는 설비와 로봇에서 발생하는 다양한 센서 데이터와 운영 로그를 교차 분석해야 했습니다. 오류는 로봇 자체의 문제일 수도 있고, 주방 환경의 온도나 습도 같은 외부 요인에 의해 발생할 수도 있었기 때문입니다.
설비 데이터 분석의 어려움
가장 큰 문제는 데이터 분석을 위해 SQL을 직접 작성해야 한다는 점이었습니다. 예를 들어 “이번주의 대면소분 설비의 평균 그릇배출 시간 알려줘”를 분석하려면 시계열 데이터를 조인하고 특정 시간대의 데이터를 필터링하는 복잡한 쿼리가 필요했습니다.
데이터 분석가들은 로봇 설비와 오류 패턴에 대한 도메인 지식은 풍부했지만, 모든 분석가가 복잡한 SQL 쿼리를 능숙하게 작성할 수 있는 것은 아니었습니다. 특히 여러 테이블을 조인하거나 시계열 데이터를 집계하는 쿼리를 작성할 때 많은 시간이 소요되었고, 때로는 IT 팀의 도움을 요청해야 하는 상황도 발생했습니다. 이는 오류 원인 분석의 속도를 늦추고, 신속한 대응을 어렵게 만들었습니다.
데이터 시각화의 필요성
데이터를 쿼리한 후에도 또 다른 어려움이 있었습니다. 숫자로 나열된 결과만으로는 오류 발생 전후의 데이터 변화 패턴이나 센서 간의 상관관계를 직관적으로 파악하기 어려웠습니다.
특히 이상 탐지를 위한 ML 모델 개발을 계획하고 있었기 때문에, 피처의 분포와 특성을 이해하고 피처 간의 상관관계를 파악하는 것이 중요했습니다. 또한 현장 엔지니어나 관리자 등 비전문가도 데이터를 쉽게 이해하여 신속하게 데이터 기반의 의사결정을 내릴 수 있도록 지원해야 했습니다.
이러한 문제들을 해결하기 위해 자연어로 질문하면 자동으로 SQL을 생성하고, 결과를 적절한 차트로 시각화해주는 AI 챗봇 시스템을 프로토타이핑으로 구현하게 되었습니다.
구현 과정의 챌린지
AI 챗봇 시스템을 구축하면서 몇 가지 핵심적인 기술적 과제에 직면했습니다.
1. 자연어에서 데이터베이스 쿼리로의 변환
첫 번째 과제는 다양한 패턴의 자연어 질문을 데이터베이스 쿼리로 변환하는 것이었습니다. 사용자들은 같은 의도라도 다양한 방식으로 질문할 수 있습니다. 예를 들어:
- “지난주 오류가 몇 번 발생했어?”
- “최근 7일간 에러 횟수 알려줘”
- “일주일 전부터 지금까지 오류 발생 건수는?”
이러한 다양한 표현을 모두 이해하고 정확한 SQL 쿼리로 변환할 수 있는 견고한 메커니즘이 필요했습니다.
2. 인터랙티브 차트 생성과 제공
두 번째 과제는 데이터 시각화 방식이었습니다. 챗봇을 통해 사용자가 쉽게 차트를 생성하고, 차트를 통해 데이터를 분석할 수 있어야 했습니다. 특히 정적인 이미지로 생성된 차트보다는 확대, 축소, 필터링 등이 가능한 인터랙티브 차트가 데이터 분석에 훨씬 효과적이었습니다.
하지만 일반적인 챗봇 인터페이스에서 인터랙티브 차트를 직접 렌더링하는 것은 쉽지 않았습니다. 단순히 차트 이미지를 생성해서 보여주는 방식으로는 사용자가 데이터를 깊이 있게 탐색할 수 없었습니다.
3. 범용 챗봇 클라이언트와의 통합
세 번째로, 특정 커스텀 UI에 종속되지 않고 Claude Desktop과 같은 범용적인 챗봇 클라이언트와 쉽게 통합할 수 있는 방식을 고민했습니다. 표준화된 프로토콜을 활용한다면 향후 다양한 챗봇 클라이언트로 확장하거나, 새로운 기능을 추가할 때 유지보수 부담을 크게 줄일 수 있을 것이라 판단했습니다.
4. 쉬운 운영과 확장성
마지막으로 AWS 서비스에 익숙하지 않은 상황을 고려하여 복잡한 인프라 관리 없이도 쉽게 사용할 수 있고, 향후 데이터와 사용자가 증가하더라도 큰 어려움 없이 확장할 수 있는 솔루션이 필요했습니다. 인프라 운영 부담을 최소화하면서도 안정적인 서비스를 제공할 수 있어야 했습니다.
이러한 챌린지들을 해결하기 위해 우리는 Amazon Bedrock AgentCore와 MCP(Model Context Protocol)를 활용한 아키텍처를 설계하게 되었습니다.
아키텍처
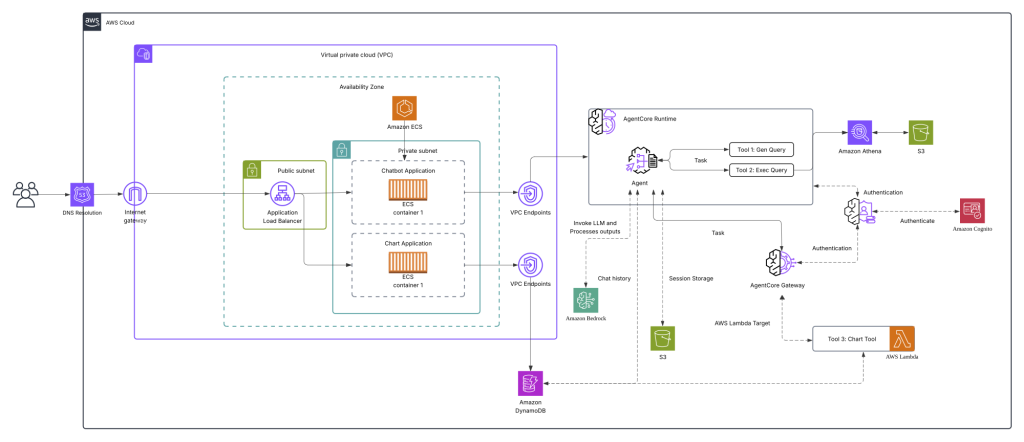
<아키텍처 설명>
AI 챗봇 시스템은 세 가지 핵심 컴포넌트로 구성됩니다.
1. AgentCore Agent
Amazon Bedrock AgentCore가 시스템의 두뇌 역할을 담당합니다. 사용자의 자연어 질문을 받아 적절한 Tool을 선택하고 실행합니다:
- Tool 1: Gen Query – 자연어를 SQL 쿼리로 변환 (Text-to-SQL)
- Tool 2: Exec Query – Amazon Athena를 통해 Amazon S3 데이터 조회
- Tool 3: Chart Tool – AWS Lambda 기반 차트 생성
AgentCore Gateway는 인증과 세션 관리를 처리하고, Amazon DynamoDB와 Amazon S3는 대화 이력을 저장하여 컨텍스트를 유지합니다.
2. Chatbot Application
Private Subnet의 Amazon ECS 컨테이너로 실행되는 메인 챗봇 인터페이스입니다. 사용자는 DNS Resolution과 Internet Gateway를 거쳐 접근하며, Application Load Balancer가 트래픽을 라우팅합니다. Amazon Cognito를 통해 인증이 처리되고, VPC Endpoints를 통해 AgentCore와 안전하게 통신합니다.
3. Chart Application
데이터 시각화를 전담하는 별도의 Amazon ECS 컨테이너 애플리케이션입니다. AgentCore Agent의 Chart Tool(AWS Lambda)이 생성한 차트 정보를 받아 인터랙티브한 시각화를 렌더링합니다.
* 아키텍쳐 주요 특징
- 관리형 서비스 활용: Amazon ECS, AWS Lambda, Amazon Athena, Amazon Bedrock을 통해 운영 부담 최소화
- 보안: Private Subnet, VPC Endpoints, Amazon Cognito 인증으로 다층 보안 구현
- 확장성: 컨테이너와 서버리스 기반으로 트래픽 증가에 유연하게 대응
Amazon Bedrock AgentCore란?
Amazon Bedrock AgentCore는 AWS가 제공하는 관리형 AI 에이전트 오케스트레이션 서비스입니다. 개발자가 복잡한 인프라 관리 없이 AI 에이전트를 구축하고 실행할 수 있도록 지원하며, 이번 프로젝트에서는 AgentCore Runtime과 AgentCore Gateway라는 두 가지 기능을 사용했습니다.
AgentCore를 선택한 이유
- 관리형 서비스의 이점: 서버리스 아키텍처로 설계되어 인프라 프로비저닝, 스케일링, 패칭 등의 운영 부담이 없습니다. 복잡한 인프라 관리 없이 빠르게 AI 챗봇을 구축할 수 있다는 점이 큰 장점이었습니다.
- 빠른 개발과 배포: 에이전트 템플릿과 사전 구성된 통합 기능을 제공하여 개발 시간을 단축할 수 있습니다. 특히 AWS 서비스들과의 네이티브 통합이 용이하여, 별도의 복잡한 설정 없이도 빠르게 프로토타입을 만들 수 있었습니다.
- 자동 확장성: 사용량에 따라 자동으로 확장되므로, 초기에는 작은 규모로 시작해서 향후 사용자와 데이터가 증가해도 안정적으로 서비스할 수 있습니다.
배포 도구
AgentCore Runtime을 쉽게 배포하기 위해 AWS에서 제공하는 Bedrock AgentCore Starter Toolkit을 활용했습니다. 이 툴킷은 LangGraph나 Strands Agents 같은 인기 있는 Python 에이전트 프레임워크와 함께 사용할 수 있는 CLI 도구로, 에이전트 배포에 필요한 설정과 인프라를 자동으로 구성해줍니다.
# Starter Toolkit 설치
$ pip install bedrock-agentcore-starter-toolkit
# Agent 설정
$ agentcore configure -e my_agent.py
# Agent 배포
$ agentcore launch
# Agent 호출 테스트
$ agentcore invoke '{"prompt": "지난주 오류 발생 건수는?"}'
Agent 구성 및 도구(Tools)
Agent는 다음과 같은 요소로 구성됩니다.
Instructions (지침) 에이전트의 역할과 행동 방식을 정의합니다. 시스템 프롬프트를 통해 에이전트가 로봇 설비 데이터 분석을 돕는 어시스턴트로 동작하도록 설정했습니다. 특히 SQL 쿼리 생성 시 반드시 사용자에게 쿼리를 먼저 보여주고 실행하도록 명시했습니다.
Tools (도구) 에이전트가 사용할 수 있는 기능들을 정의합니다. 본 프로젝트에서는 다음과 같은 도구들을 구현했습니다:
- Text-to-SQL 도구: 자연어 질문을 SQL 쿼리로 변환하고 실행하는 핵심 기능입니다. 두 개의 도구로 분리하여 구현했습니다:
gen_query: 사용자의 자연어 질문을 Amazon Athena용 SQL 쿼리로 생성합니다. 데이터베이스 스키마 정보를 컨텍스트로 제공하여 정확한 쿼리를 생성할 수 있도록 했습니다.exec_query: 생성된 SQL을 S3 Tables에 대해 실행하고 결과를 반환합니다. PyAthena를 사용하여 Amazon Athena를 통해 Amazon S3 Tables 데이터를 쿼리합니다.
- 차트 생성 도구: 쿼리 결과를 다양한 형태의 차트로 시각화합니다. MCP 프로토콜을 통해 차트 생성 서비스와 통합됩니다. 이 도구는 다음 섹션에서 자세히 다룹니다.
Agent 구현
다음은 AgentCore Runtime에서 실행될 Agent 애플리케이션의 전체 구조입니다. Strands Agent 프레임워크를 사용하여 Text-to-SQL 도구와 차트 생성 도구를 통합했습니다.
# my_agent.py
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from strands import Agent
from strands.models import BedrockModel
app = BedrockAgentCoreApp()
model = BedrockModel(model_id="global.anthropic.claude-sonnet-4-5-20250929-v1:0")
system_prompt = """
You are an intelligent assistant that helps users analyze kitchen robot facility data.
... (생략) ...
"""
@app.entrypoint
async def strands_agent_bedrock(payload):
user_input = payload.get("prompt")
# MCP 클라이언트 및 도구 초기화
chart_client = create_mcp_client()
chart_tools = get_full_tools_list(chart_client)
# Agent 생성
agent = Agent(
model=model,
tools=[
gen_query, # SQL 쿼리 생성
exec_query, # SQL 쿼리 실행
chart_tools # 차트 생성 도구
],
system_prompt=system_prompt
)
# 스트리밍 응답 반환
stream = agent.stream_async(user_input)
async for event in stream:
if "data" in event:
yield {"type": "text", "content": event['data']}
if __name__ == "__main__":
app.run()
SQL 쿼리 생성 도구
SQL 쿼리 생성 도구는 사용자의 자연어 질문을 Amazon Athena용 SQL로 변환합니다. 핵심은 별도의 Agent를 내부적으로 사용하여 스키마 정보와 최적화 규칙을 기반으로 정확한 쿼리를 생성하는 것입니다.
from strands import tool, Agent
from strands.models import BedrockModel
@tool
async def gen_query(input: str) -> str:
"""
Generate SQL Query for kitchen robot operational data from user input.
Returns the generated SQL query as a formatted string.
Args: input (str): User input to generate SQL for kitchen robot logs
"""
model = BedrockModel(model_id="global.anthropic.claude-sonnet-4-5-20250929-v1:0")
system_prompt = f"""
You are an AWS Athena SQL query generator for kitchen robot operational data.
Generate optimized Presto SQL queries for AWS Athena.
## Database Environment
- Engine: AWS Athena (Presto SQL)
- Data Format: Parquet files in S3
- Cost: Charged by data scanned, so optimization is critical
## Current Database Schema
Table Name: robot_logs.operational_data
Column Descriptions:
"timestamp" (TIMESTAMP): 데이터의 기준 시간
"id" (STRING): 설비 구분 ID
"menu_name" (STRING): 소분할 메뉴 이름
"facility_status" (INT): 설비 동작 상태
... (생략) ...
## Athena Query Optimization Rules
1. ALWAYS use column names instead of SELECT *
2. ALWAYS add LIMIT clause (default 100)
3. Use proper Presto SQL syntax with semicolon
4. Return only the SQL query, no explanations
## Performance Best Practices
- Minimize columns in SELECT to reduce scan costs
- Use DATE functions for timestamp comparisons
- Push down predicates early in WHERE clause
- Avoid SELECT * to minimize costs
Convert the user input to a SQL query:
"""
# 별도의 Agent를 사용하여 SQL 생성
agent = Agent(
model=model,
system_prompt=system_prompt,
)
res = await agent.invoke_async(input)
sql_query = res.message.content if hasattr(res.message, 'content') else str(res.message)
# 포맷팅하여 반환 - 사용자에게 명확하게 표시
return f"```sql\n{sql_query}\n```"
프롬프트 구성의 핵심 요소
효과적인 Text-to-SQL 프롬프트는 다음 세 가지 필수 요소를 포함해야 합니다:
데이터베이스 환경 정보
사용하는 데이터베이스 엔진과 특성을 명확히 알려줘야 합니다. Amazon Athena는 Presto SQL을 사용하며, 스캔한 데이터량에 따라 과금되는 특성이 있습니다. 이러한 정보를 포함시켜 Agent가 비용 효율적인 쿼리를 생성하도록 유도합니다.
## Database Environment
- Engine: AWS Athena (Presto SQL)
- Data Format: Parquet files in S3
- Cost: Charged by data scanned, so optimization is critical
상세한 데이터베이스 스키마
가장 중요한 부분으로, 테이블 이름, 컬럼명, 데이터 타입, 그리고 각 컬럼의 의미를 상세히 기술해야 합니다. 특히 다음 정보들이 필수적입니다:
- 정확한 컬럼명: 쿼리에 사용할 정확한 컬럼명 표기
- 데이터 타입: TIMESTAMP, STRING, INT 등 정확한 타입 정보
- 컬럼의 의미: 각 컬럼이 나타내는 실제 의미와 비즈니스 맥락
- 도메인 용어 매핑: 사용자가 사용하는 용어와 실제 데이터 값의 매핑 정보
## Current Database Schema
Table Name: robot_logs.operational_data
Column Descriptions:
"timestamp" (TIMESTAMP): 데이터의 기준 시간
"id" (STRING): 설비 구분 ID
"menu_name" (STRING): 소분할 메뉴 이름
"facility_status" (INT): 설비 동작 상태
<이하 생략>
이러한 상세한 스키마 정보가 없으면 Agent는 정확한 쿼리를 생성할 수 없습니다. 실제 스키마 구조는 더 복잡했지만, 블로그에는 간소화된 버전을 제시했습니다.
쿼리 최적화 규칙과 제약사항
데이터베이스 엔진의 특성에 맞는 최적화 규칙을 명시해야 합니다. Amazon Athena의 경우:
SELECT * 사용 금지 (비용 증가)- 항상
LIMIT 절 포함
- 필요한 컬럼만 선택
- 적절한 필터링 조건 사용
## Athena Query Optimization Rules
1. ALWAYS use column names instead of SELECT *
2. ALWAYS add LIMIT clause (default 100)
3. Use proper Presto SQL syntax with semicolon
4. Return only the SQL query, no explanations
특히 “Return only the SQL query, no explanations”와 같은 출력 형식 지정도 중요합니다. Agent가 추가 설명 없이 순수한 SQL만 반환하도록 해야 후속 처리가 용이합니다.
선택적 요소: 예제 쿼리
복잡한 스키마나 특수한 쿼리 패턴이 있다면 예제를 포함하는 것이 효과적입니다:
## Example Queries
Input: "8월 3일에 제공된 마지막 메뉴는?"
Output: SELECT menu_name
FROM robot_logs.operational_data
WHERE timestamp >= CAST('2025-08-03 00:00:00' AS TIMESTAMP)
AND timestamp < CAST('2025-08-04 00:00:00' AS TIMESTAMP)
ORDER BY timestamp DESC
LIMIT 1;
SQL 실행 도구 (exec_query)
생성된 쿼리를 실제로 실행하는 도구로, 간단하지만 중요한 역할을 합니다.
from typing import List, Any
from pyathena import connect
from pyathena.cursor import DictCursor
from strands import tool
@tool
def exec_query(query: str) -> List[dict[str, Any]]:
"""
Execute SQL queries against AWS Athena.
Args:
query (str): Valid Presto SQL SELECT statement
"""
# PyAthena 연결 생성
conn = connect(
s3_staging_dir="s3://my-bucket/athena-results/",
region_name="us-east-1",
work_group="primary",
cursor_class=DictCursor # Returns results as dictionaries
)
cursor = conn.cursor()
try:
cursor.execute(query)
return cursor.fetchall()
except Exception as e:
print(f"Query execution error: {e}")
raise
Chart MCP Server 구현
Save Chart Lambda 함수
다음 코드는 Amazon DynamoDB에 Chart 데이터를 저장하는 예제입니다. Record<string, any>[] 타입의 데이터를 Amazon DynamoDB에 저장하며, PK(Partition Key)를 통해 사용자별 데이터 조회가 가능합니다. 여기서는 예시로 DEFAULT 사용자명을 사용합니다.
import { DynamoDBClient } from "@aws-sdk/client-dynamodb";
import { DynamoDBDocumentClient, PutCommand } from "@aws-sdk/lib-dynamodb";
import { Context, Handler } from "aws-lambda";
import { randomUUID } from "crypto";
interface SaveChartEvent {
readonly title: string;
readonly data: Record<string, any>[];
}
/*
MCP Tool Schema
[
{
"description": "차트 데이터를 데이터베이스에 저장하는 도구",
"inputSchema": {
"properties": {
"data": {
"description": "차트 데이터 배열 - 각 항목은 키-값 쌍의 객체",
"items": {
"type": "object"
},
"type": "array"
},
"title": {
"description": "저장할 차트의 제목",
"type": "string"
}
},
"required": [
"title",
"data"
],
"type": "object"
},
"name": "save_chart"
}
]
*/
export const handler: Handler = async (
event: SaveChartEvent,
context: Context,
) => {
console.log("event", event);
console.log("context", context);
const tableName = process.env.DYNAMODB_TABLE;
const client = new DynamoDBClient({});
const docClient = DynamoDBDocumentClient.from(client);
const uid = randomUUID();
await docClient.send(
new PutCommand({
TableName: tableName,
Item: {
PK: "DEFAULT",
SK: `CHART#${uid}`,
data: event.data,
title: event.title,
timestamp: Date.now(),
},
}),
);
return "The data is successfully saved.";
};
AgentCore Gateway 설정
bedrock-agentcore-control AWS SDK를 사용하여 다음과 같이 앞서 작성한 람다 함수를 AgentCore Gateway를 통한 MCP 서버로 설정할 수 있습니다.
import boto3
gateway_client = boto3.client(
'bedrock-agentcore-control',
region_name='your aws region'
)
auth_config = {
"customJWTAuthorizer": {
"allowedClients": ['your cognito m2m client'],
"discoveryUrl": 'your cognito discovery url'
}
}
gateway_response = gateway_client.create_gateway(
name="mcp-chart",
description="Mcp Chart API Gateway",
roleArn='your agentcore role arn',
protocolType='MCP',
authorizerType='CUSTOM_JWT',
authorizerConfiguration=auth_config,
)
lambda_target_config = {
"mcp": {
"lambda": {
"lambdaArn": 'your save chart lambda function arn',
"toolSchema": {
"inlinePayload": [
{
"name": "save_chart",
"description": "tool for saving chart data to database",
"inputSchema": {
"type": "object",
"properties": {
"data": {
"type": "array",
"description": "Array of char data - each item is an object with key-value pairs",
"items": {
"type": "object"
}
},
"title": {
"type": "string",
"description": "Title of the chart to save"
}
},
"required": ["title", "data"]
}
}
]
}
}
}
}
credential_config = [
{
"credentialProviderType" : "GATEWAY_IAM_ROLE"
}
]
targetname='ChartLambdaFunctions'
target_response = gateway_client.create_gateway_target(
gatewayIdentifier=gateway_response['gatewayId'],
name=targetname,
description='Chart Lambda Target',
targetConfiguration=lambda_target_config,
credentialProviderConfigurations=credential_config)
Chart Tool
다음은 Strands Agents를 활용한 MCP Client 설정 예제입니다. AgentCore Gateway 엔드포인트에 Amazon Cognito 인증으로 연결하여 Text-to-SQL과 Chart 도구를 통합합니다.
이 구성을 통해 “지난주 오류가 몇 번 발생했는지 검색하고 차트로 저장해줘”와 같은 자연어 요청을 처리할 수 있습니다. 시스템은 자동으로 DB 쿼리를 생성하고, 결과 데이터를 차트 형태로 변환하여 저장합니다.
MCP를 통해 차트 기능을 외부 도구로 구현하면 Claude Desktop 등 다양한 LLM 도구와의 통합이 용이해집니다.
from typing import List
import requests
from mcp.client.streamable_http import streamablehttp_client
from strands.tools.mcp.mcp_client import MCPClient, MCPAgentTool
# Edit Variable for you environments
CLIENT_ID = 'your cognito client id'
CLIENT_SECRET = 'your cognito client secret'
COGNITO_DOMAIN = 'your cognito domain'
MCP_ENDPOINT = 'your agentcore gateway endpoint'
def get_token_url() -> str:
return f"{COGNITO_DOMAIN}/oauth2/token"
def fetch_access_token(client_id: str, client_secret: str, token_url: str) -> str:
response = requests.post(
token_url,
data="grant_type=client_credentials&client_id={client_id}&client_secret={client_secret}".format(
client_id=client_id,
client_secret=client_secret,
),
headers={'Content-Type': 'application/x-www-form-urlencoded'}
)
return response.json()['access_token']
def create_mcp_client() -> MCPClient:
access_token = fetch_access_token(CLIENT_ID, CLIENT_SECRET, get_token_url())
mcp_client = MCPClient(
lambda: streamablehttp_client(MCP_ENDPOINT, headers={"Authorization": f"Bearer {access_token}"}))
return mcp_client
def get_full_tools_list(client: MCPClient) -> List[MCPAgentTool]:
"""
List tools w/ support for pagination
"""
more_tools = True
tools = []
pagination_token = None
while more_tools:
tmp_tools = client.list_tools_sync(pagination_token=pagination_token)
tools.extend(tmp_tools)
if tmp_tools.pagination_token is None:
more_tools = False
else:
more_tools = True
pagination_token = tmp_tools.pagination_token
return tools
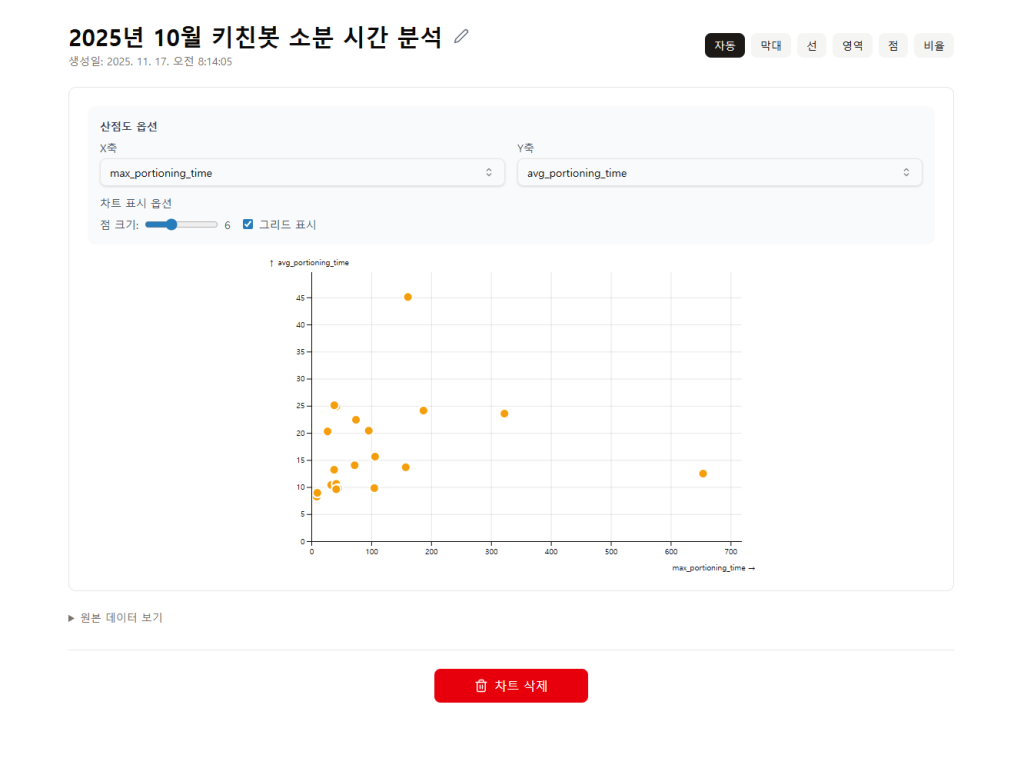
<Pic – Amazon DynamoDB에 저장된 Chart 데이터 뷰어 예제>
Chatbot App
다음의 코드는 bedrock-agentcore AWS SDK를 사용하여, 배포된 AgentCore Runtime을 Invoke하는 예제입니다.
import {BedrockAgentCoreClient, InvokeAgentRuntimeCommand} from "@aws-sdk/client-bedrock-agentcore";
export interface ChatMessageInput {
sessionId: string;
message: string;
agentRuntimeArn: string;
}
export async function createChatStream(input: ChatMessageInput) {
const client = new BedrockAgentCoreClient();
const cmd = new InvokeAgentRuntimeCommand({
agentRuntimeArn: input.agentRuntimeArn,
contentType: 'application/json',
accept: 'application/json',
payload: JSON.stringify({
session_id: input.sessionId,
prompt: input.message,
})
});
const output = await client.send(cmd);
const sourceStream = output.response?.transformToWebStream();
if (!sourceStream) {
throw new Error('No response stream available');
}
return new ReadableStream({
async start(controller) {
try {
const reader = sourceStream.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) {
controller.close();
break;
}
controller.enqueue(value);
}
} catch (error) {
const serializableError = new Error(
error instanceof Error ? error.message : 'Failed to invoke agent runtime'
);
if (error instanceof Error) {
serializableError.name = error.name;
serializableError.stack = error.stack;
}
controller.error(serializableError);
}
}
});
}]
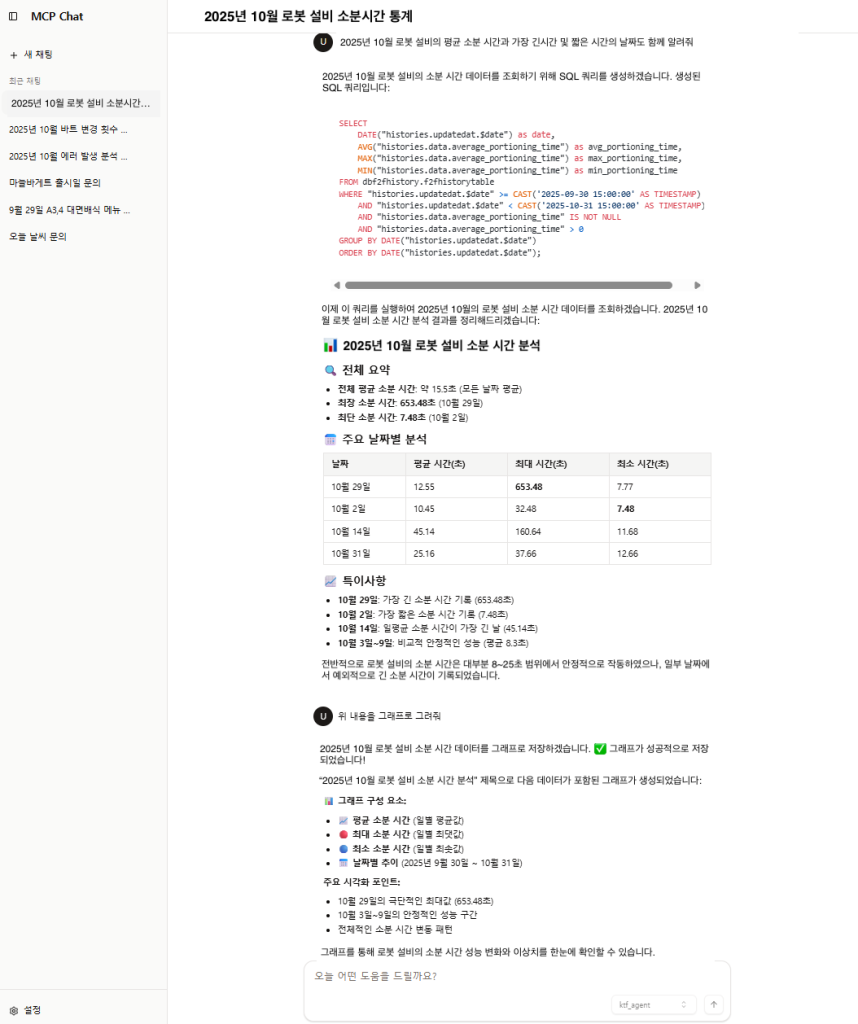
< Pic – Chatbot App 예제 >
결론
삼성전자는 AWS Prototype과 EBA 프로그램을 통하여 개발 생산성 향상을 도모할 수 있었습니다. AWS Prototyping 프로그램을 통하여 Amazon Bedrock과 AI 챗봇 개발 경험이 전혀 없었음에도 불구하고 2명의 개발자가 개발 3주, 배포 1주, 파인튜닝 2주로 총 6주 만에 실사용 가능한 수준으로 AI 챗봇을 구현을 할 수 있었습니다. 또한, AWS EBA 프로그램을 통해 Amazon Bedrock, Amazon Athena, Amazon S3, AWS CloudFormation 등 다수의 AWS 서비스가 연계된 복잡한 아키텍쳐를 단 1일만에 배포할 수 있었습니다.
데이터 분석 프로세스도 혁신적으로 개선되었습니다. AI 챗봇 도입 이후에는 daily 화면을 일일이 확인하며 특이사항을 찾던 방식에서 벗어나, 특정 상황에 대해 질문하고 즉시 해당 날짜의 상세 데이터를 분석할 수 있게 되었습니다. 또한, 그래프로는 확인하기 어려웠던 인사이트도 자연어 질의응답을 통해 발견할 수 있게 되었으며, 2개 이상의 데이터베이스에 걸친 복합 질문도 가능해졌습니다.
이번 프로젝트는 적절한 도구 선택과 AI 기술 활용이 얼마나 큰 생산성 향상을 가져올 수 있는지 증명했습니다. 현재 추가 데이터베이스 연동과 파인튜닝을 진행 중이며, 앞으로도 지속적인 개선을 통해 더 나은 데이터 기반 의사결정 환경을 만들어갈 계획입니다.