AWS 기술 블로그
Amazon EFS 트러블슈팅, NFS I/O Hang 과 Security Group Outbound 규칙의 상관관계
소개
Amazon Elastic File System(Amazon EFS)은 내부적으로 인프라 유지보수를 수행합니다. 정상적인 환경에서는 이 과정이 투명하게 처리되지만, EFS mount target에 연결된 security group의 기본 Outbound 규칙(Allow All)을 제거한 환경에서는 유지보수 시 NFS I/O가 수분간 hang되는 문제가 발생할 수 있습니다.
이 글에서는 실제 운영 환경에서 발생한 EFS NFS I/O hang 사례를 바탕으로, AWS EFS 서비스팀과의 협력을 통해 확인된 근본 원인의 정확한 메커니즘, tcpdump를 활용한 진단 방법, 그리고 해결 방안을 공유합니다.
Prerequisites
- Amazon EFS 파일 시스템이 마운트된 Amazon EC2 인스턴스
- EC2 인스턴스에
tcpdump설치 (sudo yum install -y tcpdump또는sudo apt install -y tcpdump) - EFS Mount Target 및 EC2 인스턴스의 Security Group 수정 권한
문제 상황
한 고객 환경에서 EFS 유지보수 이후 특정 파일 시스템에 마운트된 EC2 인스턴스에서 NFS I/O hang이 발생했습니다.
주요 증상:
- 유지보수 전에는 정상 동작
- 유지보수 이후 하루 수십 회 NFS I/O hang이 반복 발생
- 매번 약 1~2분간 I/O가 멈춘 후 자동 복구 — 데이터 유실 없음
- 동일 EC2에서 다른 EFS 파일 시스템은 정상
커널 로그에서 다음과 같은 메시지가 확인되었습니다:
nfs: server 10.x.x.x not responding, still trying
nfs: server 10.x.x.x OK
배경: 왜 Security Group Outbound 규칙이 EFS에 영향을 주는가
이 문제를 이해하려면 세 가지를 알아야 합니다: TCP 연결의 기본 동작, Security Group의 stateful 특성, 그리고 EFS 유지보수 시 발생하는 특수한 상황.
TCP 연결과 RST
NFS는 TCP 위에서 동작합니다. TCP 연결은 3-Way Handshake(SYN → SYN,ACK → ACK)로 수립되며, 이후 모든 데이터 패킷에는 ACK 플래그가 포함됩니다 — “이전 패킷 잘 받았다”는 확인 신호입니다.
연결을 강제로 끊어야 할 때는 TCP RST(Reset) 패킷이 사용됩니다. RST는 “이 연결은 더 이상 유효하지 않다”는 즉시 종료 신호이며, ACK 플래그가 포함되지 않습니다.
Security Group의 stateful 동작
Security Group은 stateful입니다. Inbound로 허용된 연결의 응답 트래픽은 Outbound 규칙 없이도 자동으로 허용됩니다. 예를 들어 mount target의 security group에 “Inbound TCP 2049 허용” 규칙만 있어도, EFS에서 클라이언트로 돌아가는 NFS 응답([PSH, ACK])은 자동으로 통과합니다.
그런데 이 자동 허용에는 조건이 있습니다. EFS 서비스팀의 분석 결과, 기존 연결의 응답이 아닌 새로운 패킷 — 특히 ACK 없는 TCP RST — 은 이 자동 허용의 대상이 되지 않는 것으로 확인되었습니다.
EFS 유지보수 시 발생하는 특수한 상황
EFS 유지보수 시 백엔드 서버가 교체되면, 새로운 서버가 클라이언트에 RST를 보냅니다. 새 서버 입장에서 이 RST는 자신이 처리한 적 없는 연결에 대한 패킷이므로, 기존 연결의 “응답”이 아닌 새로운 패킷입니다.
이것이 핵심입니다:
| 패킷 | ACK 포함 | SG 자동 허용 | 결과 |
|---|---|---|---|
정상 NFS 응답 [PSH, ACK] |
예 | 예 | 통과 |
TCP Keep Alive RST [RST, ACK] |
예 | 예 | 통과 |
유지보수 시 새 서버의 RST [RST] |
아니오 | 아니오 | 차단 |
기본 Outbound 규칙(Allow All)이 있으면 이 RST도 통과합니다. 기본 규칙을 제거한 환경에서만 문제가 발생합니다.
EFS mount helper와 noresvport
AWS는 EFS 마운트 시 noresvport 옵션을 강력히 권장합니다. 이 옵션은 재연결 시 새로운 TCP 소스 포트를 사용하게 하여, 재연결 실패를 방지합니다. EFS mount helper를 사용하면 noresvport가 기본 적용되며, TLS 암호화도 함께 활성화할 수 있습니다:
# EFS mount helper (권장) — noresvport 기본 적용 + TLS
sudo mount -t efs -o tls fs-xxxxxxxx:/ /mnt/efs
# 수동 마운트 시 noresvport 명시 필수
sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport mount-target-ip:/ /mnt/efs
그러나 noresvport만으로는 이 문제를 해결할 수 없습니다. noresvport는 RST를 수신한 후의 재연결을 개선하는 것이지, RST 자체가 차단되는 문제는 해결하지 못합니다. RST가 클라이언트에 도달해야 재연결이 시작됩니다.
근본 원인
EFS 유지보수 시 발생하는 일
EFS는 유지보수 시 백엔드 서버 간 연결 리밸런싱을 수행합니다. 새로운 서버가 클라이언트에 TCP RST를 전송하여 재연결을 유도합니다. 정상적인 경우 클라이언트는 RST를 수신하고 즉시 새 연결을 맺어 NFS 통신을 재개합니다.
RST가 차단되면
다음 다이어그램은 정상 환경과 문제 환경의 차이를 보여줍니다:
정상 환경 (Outbound Allow All) — RST 수신 후 즉시 재연결:
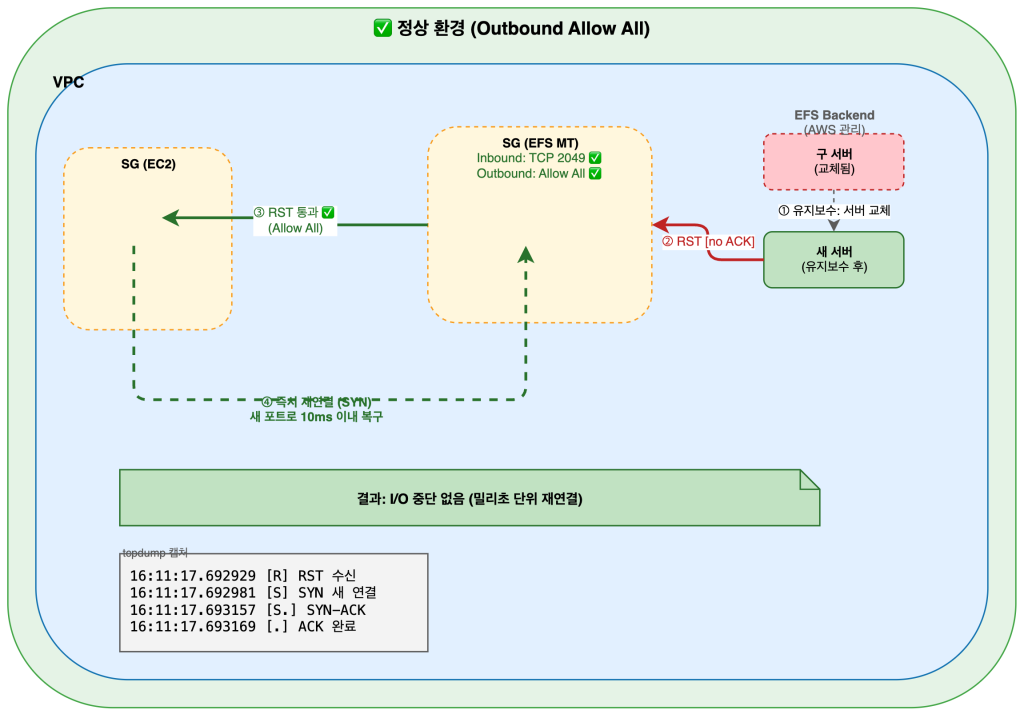
그림1. 정상 환경: Outbound Allow All 설정 시, 새 서버의 RST가 클라이언트에 도달하여 즉시 재연결
문제 환경 (Outbound 규칙 없음) — RST 차단으로 1~2분 hang:
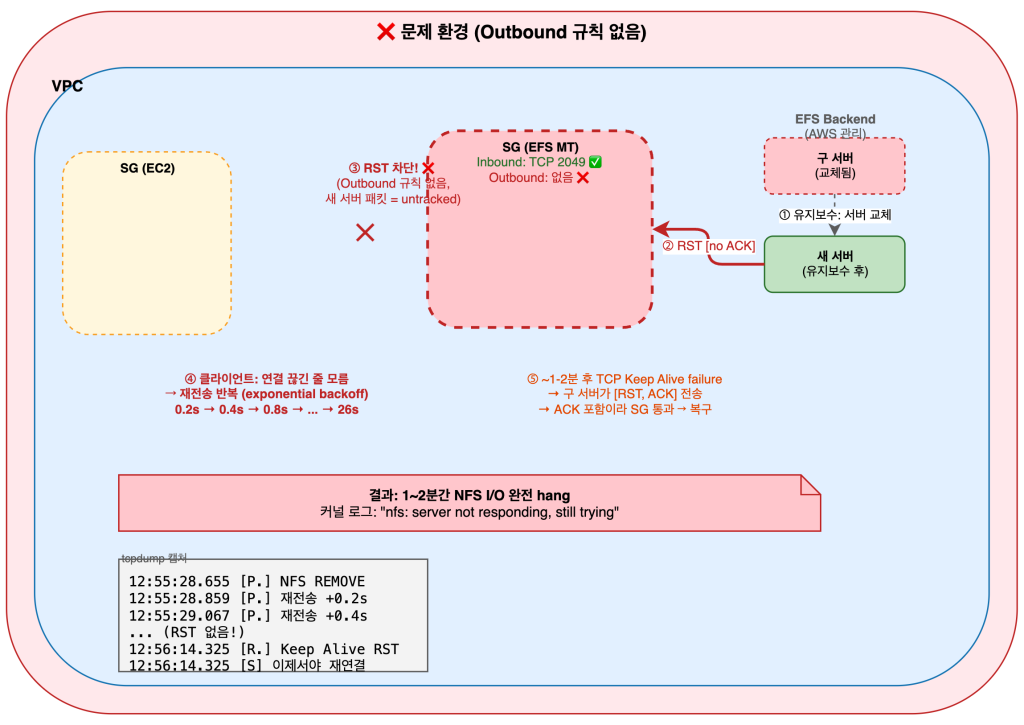
그림2. 문제 환경: Outbound 규칙 부재 시, RST가 Security Group에서 차단되어 1~2분간 NFS I/O hang 발생
EFS mount target에 연결된 security group에 기본 Outbound 규칙(Allow All)이 없고, 명시적 Outbound 규칙도 없으면:
- 새 서버가
[RST]전송 → SG에서 차단 → 클라이언트에 도달 못함 - 클라이언트는 연결이 끊긴 줄 모르고 기존 연결로 계속 요청
- 응답이 없으므로 exponential backoff로 재전송 반복 (0.2s → 0.4s → … → 26s)
- 결국 TCP Keep Alive failure로 old 서버가
[RST, ACK]를 보내서 복구 (약 1~2분 후)
이 시간 동안 NFS I/O가 완전히 hang됩니다. 데이터 유실은 없지만, Amazon EFS에 의존하는 애플리케이션이 응답 불가 상태가 됩니다.
참고: NFS 2049 포트만 Outbound에 추가하는 것으로는 부족합니다. Outbound 규칙의 포트는 목적지(remote) 포트를 의미합니다. 클라이언트가 NFS 통신에 사용하는 포트는 2049가 아닌 임의의 포트입니다. 따라서 Outbound에 NFS 포트(2049)만 허용하는 것으로는 해결되지 않으며, EFS 서비스팀의 테스트 결과 All TCP(0-65535) 범위가 필요합니다. 단, Destination을 EC2 Client Security Group으로 제한하면 해당 인스턴스로의 트래픽만 허용되므로, 인터넷이나 다른 리소스로의 접근은 열리지 않습니다.
SG Outbound 설정별 동작
| Outbound 설정 | 유지보수 시 RST 전달 | 결과 |
|---|---|---|
| 규칙 없음 | 차단 | 1~2분 I/O hang |
| NFS 2049 → EC2 인스턴스의 security group | 차단 (클라이언트 포트는 2049가 아님) | 1~2분 I/O hang |
| All TCP → EC2 인스턴스의 security group (권장) | 통과 | 즉시 재연결 (밀리초 단위) |
| Allow All (기본) | 통과 | 즉시 재연결 (밀리초 단위) |
공식 문서와의 관계
AWS 공식 문서(Using VPC security groups)에서는 다음과 같이 안내하고 있습니다:
“You don’t need to add an outbound rule because the default outbound rule allows all outbound traffic.”
“Inbound rules other than the one for NFS port 2049, and any outbound rules, aren’t used by network interfaces for file system mount targets.”
이 문장들은 기본 Outbound 규칙(Allow All)이 유지되어 있다는 전제 하에 작성된 것입니다. 보안 강화를 위해 기본 규칙을 제거한 환경에서는 해당되지 않습니다.
참고: 이 사례를 EFS 서비스팀에 공유하였습니다.
유지보수 전에는 왜 문제가 없었나?
EFS는 내부 유지보수를 사전 알림 없이 수행합니다. AWS Health Dashboard에도 표시되지 않습니다. 정상 환경에서는 유지보수가 투명하게 처리되어 고객이 인지하지 못하는 것이 기대 동작입니다.
평상시에는 EFS가 TCP RST를 보낼 이유가 없으므로 Outbound 규칙 부재가 문제를 일으키지 않습니다. 유지보수 시점에서야 비로소 드러나는 것이 이 문제를 사전에 발견하기 어려운 이유입니다.
진단 방법: tcpdump
이 문제는 Amazon VPC Flow Logs로는 진단할 수 없습니다. 실제 사례에서 Flow Logs를 분석했으나 REJECT 레코드가 전혀 없었습니다. 확정 진단에는 EC2 클라이언트에서의 tcpdump가 필수입니다.
tcpdump 캡처 명령
EFS mount helper + TLS 환경에서는 NFS 트래픽이 stunnel을 통해 127.0.0.1로 전달되므로, 로컬 트래픽도 함께 캡처해야 합니다:
# EFS mount helper + TLS 환경 (권장)
sudo tcpdump -W 30 -C 1000 -s 2000 \
-w nfs_pcap_$(date +%FT%T).pcap \
-i any -z gzip -Z root \
'port 2049 or (src 127.0.0.1 and dst 127.0.0.1)'
TLS를 사용하지 않는 환경에서는 mount target IP로 직접 필터링합니다:
# 비-TLS 환경
sudo tcpdump -i any host <mount_target_ip> and port 2049 -nn -v \
-w /tmp/efs_capture.pcap
RST 패킷만 실시간으로 확인하려면:
sudo tcpdump -i any port 2049 and 'tcp[tcpflags] & (tcp-rst) != 0' -nn
캡처 결과 분석 — 실제 운영 환경 데이터
다음은 실제 운영 환경에서 캡처한 pcap 데이터입니다 (IP 주소 마스킹).
정상 환경 (Outbound Allow All) — 즉시 재연결:
# 유지보수로 서버 교체 → 새 서버가 RST 전송 → 클라이언트 즉시 재연결
16:11:17.692731 IP 10.x.x.12.55870 > 10.x.x.126.2049: Flags [P.], length 312: NFS V4 Call REMOVE
16:11:17.692929 IP 10.x.x.126.2049 > 10.x.x.12.55870: Flags [R], seq 998293 ← RST 수신!
16:11:17.692981 IP 10.x.x.12.51474 > 10.x.x.126.2049: Flags [S], seq 0 ← 즉시 새 연결 (SYN)
16:11:17.693157 IP 10.x.x.126.2049 > 10.x.x.12.51474: Flags [S.], seq 0 ← SYN-ACK
16:11:17.693169 IP 10.x.x.12.51474 > 10.x.x.126.2049: Flags [.], ack 1 ← ACK (연결 완료)
16:11:17.708470 IP 10.x.x.126.2049 > 10.x.x.12.51474: Flags [P.], length 120: NFS V4 Reply REMOVE
→ RST 수신 후 10ms 이내 새 포트(51474)로 재연결 완료. I/O 중단 없음.
문제 환경 (Outbound 규칙 없음) — 46초 Hang:
# 유지보수로 서버 교체 → RST가 SG에서 차단 → 클라이언트는 모름
12:55:28.655124 IP 10.x.x.12.52532 > 10.x.x.126.2049: Flags [P.], length 312: NFS V4 Call REMOVE
12:55:28.859702 IP 10.x.x.12.52532 > 10.x.x.126.2049: Flags [P.], length 312 ← 재전송 (+0.2s)
12:55:29.067702 IP 10.x.x.12.52532 > 10.x.x.126.2049: Flags [P.], length 312 ← 재전송 (+0.4s)
12:55:29.483706 IP 10.x.x.12.52532 > 10.x.x.126.2049: Flags [P.], length 312 ← 재전송 (+0.8s)
12:55:30.315714 IP 10.x.x.12.52532 > 10.x.x.126.2049: Flags [P.], length 312 ← 재전송 (+1.7s)
12:55:35.275708 IP 10.x.x.12.52532 > 10.x.x.126.2049: Flags [P.], length 312 ← 재전송 (+6.6s)
12:55:55.243710 IP 10.x.x.12.52532 > 10.x.x.126.2049: Flags [P.], length 312 ← 재전송 (+26.6s)
... (RST 패킷이 보이지 않음)
12:56:14.325465 IP 10.x.x.126.2049 > 10.x.x.12.52532: Flags [R.], ack ... ← TCP Keep Alive failure (약 46초 후)
12:56:14.325550 IP 10.x.x.12.41064 > 10.x.x.126.2049: Flags [S], seq 0 ← 이제서야 재연결
→ Flags [R] (RST)이 보이지 않고 재전송만 반복. 약 46초 후 복구.
핵심 차이: 정상 환경에서는 Flags [R] 후 즉시 Flags [S]가 따라옵니다. 문제 환경에서는 RST가 없고 exponential backoff 재전송만 반복됩니다.
해결 방법
Option 1 (권장): All TCP Outbound 규칙 추가
EFS mount target의 security group에 EC2 인스턴스의 security group으로의 All TCP Outbound 규칙을 추가합니다.
Type: All TCP
Protocol: TCP
Port range: 0 - 65535
Destination: sg-xxxxxxxx (EC2 인스턴스의 security group)
AWS CLI:
aws ec2 authorize-security-group-egress \
--group-id sg-efs-mount-target \
--protocol tcp \
--port 0-65535 \
--source-group sg-ec2-client
이 규칙은 EC2 클라이언트로의 트래픽만 허용하며, 인터넷이나 다른 리소스로의 접근은 허용하지 않습니다.
Option 2: 기본 Outbound 규칙 유지
기본 Outbound 규칙(Allow All)을 유지하는 것이 가장 간단합니다. AWS 공식 문서에서도 이 구성을 전제로 안내하고 있습니다.
적용 후 검증
# 커널 로그에서 NFS 관련 메시지 모니터링
sudo dmesg -w | grep -i nfs
실제 사례에서는 Outbound 규칙 적용 후 NFS I/O hang이 즉시 해소되었으며, 이후 유지보수에서도 재발하지 않았습니다.
Cleanup
이 글의 진단 절차를 테스트 환경에서 수행한 경우, 다음 리소스를 정리하여 불필요한 과금을 방지하세요:
- tcpdump 캡처 파일 삭제:
sudo rm /tmp/efs_capture.pcap - 테스트용으로 변경한 security group Outbound 규칙이 의도한 상태인지 확인
- 테스트용 Amazon EFS 파일 시스템을 생성한 경우, mount 해제 후 파일 시스템을 삭제
비즈니스 임팩트
| 지표 | Before (Outbound 없음) | After (Outbound 추가) |
|---|---|---|
| 유지보수 시 NFS I/O | 수분간 hang | 즉시 재연결 (밀리초 단위) |
| 애플리케이션 영향 | I/O wait로 서비스 일시 중단 | 영향 없음 |
| 데이터 유실 | 없음 | 없음 |
| 원인 파악 소요 시간 | 수일 (서비스팀 에스컬레이션) | 수분 (tcpdump로 RST 미수신 확인) |
요약
| 항목 | 내용 |
|---|---|
| 근본 원인 | EFS 유지보수 시 새 서버의 TCP RST(ACK 없음)가 SG Outbound에서 차단 |
| 왜 놓치기 쉬운가 | 평상시에는 RST가 발생하지 않아 Outbound 부재가 드러나지 않음 |
| 진단 도구 | tcpdump (Amazon VPC Flow Logs에는 REJECT가 기록되지 않음) |
| 해결 방법 | mount target의 security group에 All TCP → EC2 인스턴스 SG Outbound 규칙 추가 |
| 주의 | NFS 2049만으로는 부족 — All TCP 범위 필요 |
Conclusion
EFS mount target에 연결된 security group의 Outbound 규칙 부재는 평상시에는 드러나지 않다가, 유지보수 시점에 NFS I/O hang으로 나타나는 숨겨진 함정입니다.
지금 바로 확인하세요:
- mount target의 security group Outbound 규칙을 확인하세요. 기본 Allow All이 제거되어 있다면, EC2 인스턴스의 security group으로의 All TCP Outbound 규칙을 추가하세요.
- EFS mount helper + TLS를 사용하세요.
noresvport가 기본 적용되어 재연결 안정성이 향상됩니다. - NFS 2049 포트만으로는 부족합니다. All TCP 범위가 필요합니다.
더 자세한 내용은 다음 리소스를 참고하세요:
질문이나 피드백이 있으시면 댓글로 남겨주세요.