AWS 기술 블로그
클라우드 환경에서의 비디오 인텔리전스 구현 : TwelveLabs로 시작하는 AI 영상 분석 5부 – 비디오 임베딩을 위한 Vector DB 비교
배경
이 블로그 시리즈에서는 TwelveLabs의 비디오 인텔리전스 기술을 AWS 클라우드 환경에서 활용하는 방법을 단계별로 살펴봤습니다. 1편과 2편에서는 VoD 및 준실시간 환경에서의 비디오 분석 파이프라인을 구축했고, 3편에서는 Strands Agent를 활용한 Agentic video engine을 구현했습니다. 그리고 4편에서는 Amazon Bedrock에서 제공하는 TwelveLabs Marengo 3.0의 멀티모달 임베딩 전략과 검색 방법론(Fused Embeddings, Score-based Fusion, RRF, Intent-based Routing)을 깊이 있게 다뤘습니다.
시리즈의 마지막 편인 이번 블로그에서는, 4편에서 다룬 임베딩 전략을 실제 서비스에 적용할 때 반드시 답해야 하는 질문을 다룹니다:
“생성된 비디오 임베딩을 어디에 저장하고, 어떻게 효율적으로 검색할 것인가?”
비디오 임베딩은 일반적인 텍스트나 이미지 임베딩과는 다른 특성을 가집니다. Marengo 3.0은 하나의 비디오를 시간 단위의 세그먼트로 나누어 각각에 대해 512차원 벡터를 생성하므로, 짧은 클립이라도 수 개에서 수십 개의 벡터가 만들어지고, 장시간 영상은 수백~수천 개의 벡터를 생성합니다. 비디오 라이브러리의 규모가 커질수록 관리해야 할 벡터의 수는 빠르게 증가하며, 이를 효율적으로 저장하고 유사도 기반으로 빠르게 검색할 수 있는 인프라가 필요합니다.
이때 어떤 벡터 저장소를 선택하느냐에 따라 검색 레이턴시, 운영 비용, 확장성, 그리고 기존 인프라와의 통합 방식이 크게 달라집니다. 예를 들어, 비디오 메타데이터에 대한 키워드 검색과 임베딩 기반 시맨틱 검색을 동시에 수행해야 하는 경우와, 단순히 대규모 벡터를 저렴하게 저장하고 top-k 검색만 수행하면 되는 경우는 적합한 서비스가 다릅니다. 또한 이미 관계형 DB를 운영 중인 환경에서 벡터 검색을 추가하는 것과, 처음부터 벡터 전용 인프라를 구축하는 것도 서로 다른 접근이 필요합니다.
AWS에서는 벡터 데이터를 저장하고 유사도 검색을 수행할 수 있는 여러 서비스를 제공합니다. 이번 블로그에서는 그 중 서로 다른 설계 철학을 가진 두 가지 서비스에 실제 Marengo 3.0 비디오 임베딩을 저장하고 검색하는 과정을 단계별로 살펴봅니다:
- Amazon OpenSearch Serverless — 풀텍스트 검색과 벡터 검색을 동시에 지원하는 관리형 서비스입니다. 비디오 메타데이터에 대한 키워드 검색과 임베딩 기반 시맨틱 검색을 하나의 인프라에서 수행할 수 있어, 하이브리드 검색이 필요한 시나리오에 적합합니다.
- Amazon S3 Vectors — 2025년에 출시된 S3 네이티브 벡터 저장/검색 서비스입니다. S3의 확장성과 내구성을 기반으로 대규모 벡터를 저렴하게 저장하고 검색할 수 있으며, 별도의 클러스터 관리 없이 빠르게 시작할 수 있습니다.
각 서비스별로 설정부터 임베딩 저장, 검색까지의 과정을 코드와 함께 설명하고, 동일한 환경에서 측정한 성능 데이터도 함께 공유합니다.
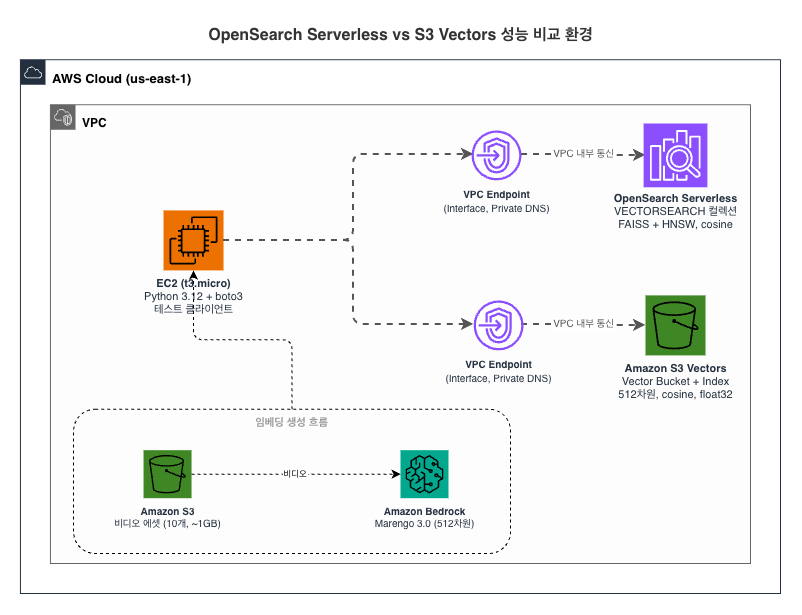
테스트 환경
비디오 에셋과 임베딩
테스트에는 다양한 규모의 비디오 10개(총 약 1GB)를 사용했습니다. 짧은 클립(5~20MB, 1분 이내)부터 장시간 스포츠 경기 영상(200~300MB, 수십 분)까지 포함하여, 비디오 길이와 크기에 따른 임베딩 특성 차이를 확인할 수 있도록 구성했습니다.
| 비디오 유형 | 개수 | 크기 범위 | 세그먼트 수 | 특성 |
|---|---|---|---|---|
| 짧은 클립 (일상/풍경) | 6개 | 5~20MB | 2~7개 | 짧은 영상 |
| 장시간 스포츠 경기 | 4개 | 100~321MB | 165~1,005개 | 축구 경기 영상 등 |
임베딩 모델: Amazon Bedrock의 twelvelabs.marengo-embed-3-0-v1:0 (비동기 API)을 사용했습니다.
- 임베딩 차원: 512 (Marengo 3.0의 기본 출력 차원)
- 모달리티: visual (기본값)
- 총 벡터 수: 2,285개 (asset-level + clip-level 포함)
Marengo 3.0은 비디오를 일정 간격의 세그먼트로 나누어 각각에 대해 512차원 벡터를 생성합니다. 짧은 클립은 2~7개의 세그먼트를, 장시간 영상은 수백~천 개 이상의 세그먼트를 생성합니다. 이 512차원이라는 수치는 벡터 DB 선택 시 차원 제한과 관련하여 중요한 고려사항이 됩니다.
테스트 인프라와 네트워크 경로
두 서비스의 성능을 정밀하게 측정하기 위해, 동일 리전의 동일한 Amazon EC2 인스턴스에서 모든 테스트를 수행했습니다. 네트워크 경로 차이로 인한 영향을 최소화하기 위해 AMAZON OpenSearch Serverless와 Amazon S3 Vectors에도 Interface VPC Endpoint(Private DNS 활성화)를 구성하였습니다. 테스트 클라이언트는 Python 3.12 + boto3 SDK를 사용했습니다.
| DB | 통신 경로 | 특성 |
|---|---|---|
| OpenSearch Serverless | EC2 → VPC Endpoint → OpenSearch Serverless | Interface VPC Endpoint (Private DNS 활성화) |
| S3 Vectors | EC2 → VPC Endpoint → S3 Vectors API | Interface VPC Endpoint (Private DNS 활성화) |
측정 방법론
인제스트와 검색 각각에 대해 다음과 같이 측정했습니다.
인제스트 측정
각 서비스의 SDK를 사용하여 2,285개 벡터를 배치 단위로 저장하고, 전체 소요 시간을 측정했습니다. 배치 크기는 서비스별 API 제약에 맞춰 설정했습니다.
| 서비스 | 배치 크기 | 인제스트 방식 |
|---|---|---|
| OpenSearch Serverless | 200 | _bulk API (NDJSON) |
| S3 Vectors | 500 | put_vectors (boto3 SDK, API 최대 배치 크기) |
각 서비스의 API가 허용하는 최대 배치 크기를 활용하는 것이 인제스트 성능에 큰 영향을 미칩니다. S3 Vectors는 요청당 최대 500개까지 지원하며, 배치 크기를 50에서 500으로 변경하는 것만으로 인제스트 시간이 약 3배 개선되었습니다.
검색 레이턴시 측정
검색 레이턴시는 단일 쿼리의 왕복 시간(SDK 호출 시작 ~ 응답 수신)을 측정했습니다. 쿼리 벡터 5개 × 반복 20회 = 총 100회 측정하여 통계를 산출했습니다.
참고: 2,285개 벡터는 소규모 테스트입니다. 벡터 수가 수십만~수백만 개로 증가하면 각 서비스의 인덱싱 알고리즘, 메모리 관리, 샤딩 전략에 따라 성능 특성이 크게 달라질 수 있습니다. 또한 테스트 클라이언트의 스펙(t3.micro, 1GB RAM)도 프로덕션 환경(Lambda, ECS, EKS 등)과 다르므로, 이 블로그는 벡터DB 간 테스트를 참고만 하는 것으로 권장 드립니다.
Amazon OpenSearch Serverless
서비스 개요
Amazon OpenSearch Serverless는 OpenSearch의 관리형 서버리스 버전으로, 인프라 관리 없이 풀텍스트 검색과 벡터 검색을 모두 지원합니다. VECTORSEARCH 타입 컬렉션을 생성하면 k-NN(k-Nearest Neighbors) 검색을 위한 최적화된 환경이 자동으로 구성됩니다.
비디오 검색 시나리오에서 OpenSearch Serverless의 가장 큰 강점은 하이브리드 검색입니다. 벡터 유사도 검색(시맨틱)과 풀텍스트 검색(키워드)을 동시에 수행할 수 있어, “Q3 세일즈 발표 장면”처럼 시각 정보와 텍스트 정보가 혼합된 쿼리에 효과적입니다. HNSW, IVF 등 다양한 인덱스 알고리즘과 faiss, nmslib 등 엔진을 선택할 수 있고, 풍부한 메타데이터 필터링도 지원합니다.
설정 과정
1. 보안 정책 구성
OpenSearch Serverless는 일반적인 AWS 서비스와 달리, 세 가지 보안 정책을 별도로 구성해야 합니다:
- 암호화 정책: 데이터 암호화 설정 (AWS 관리형 키 또는 고객 관리형 키)
- 네트워크 정책: 퍼블릭/VPC 접근 제어
- 데이터 접근 정책: IAM 기반 인덱스/컬렉션 접근 권한
특히 데이터 접근 정책은 IAM 정책과 별개로 OpenSearch Serverless 자체에서 관리됩니다. EC2나 Lambda 등에서 접근하려면 해당 IAM 역할을 데이터 접근 정책의 Principal에 반드시 추가해야 합니다.
2. 인덱스 생성
컬렉션이 생성되면, 벡터 검색을 위한 인덱스를 생성합니다. 여기서 임베딩 차원, 검색 알고리즘 등을 설정합니다.
인덱스 설정에서 주목할 점:
- 엔진:
faiss(Facebook AI Similarity Search) – 대규모 벡터 검색에 최적화된 라이브러리 - 알고리즘:
hnsw(Hierarchical Navigable Small World) – 근사 최근접 이웃 검색으로, 정확도와 속도의 균형이 우수 - 거리 함수:
cosinesimil(코사인 유사도) – Marengo 3.0 임베딩에 적합
3. 벡터 인제스트
Marengo 3.0에서 생성된 임베딩을 OpenSearch에 벌크로 저장합니다. 배치 크기를 적절히 조절하여 효율적으로 인제스트할 수 있습니다.
> 주의: OpenSearch Serverless는 인덱스 생성 직후 내부적으로 샤드 할당과 최적화를 수행합니다. 인덱스 생성 후 충분한 대기 시간(10초 이상)을 두고 인제스트를 시작하는 것이 권장됩니다.
4. 벡터 검색
저장된 임베딩에서 유사한 비디오 세그먼트를 검색합니다.
하이브리드 검색이 필요한 경우, OpenSearch 2.10+에서 권장하는 방식은 search pipeline과 hybrid 쿼리를 사용하는 것입니다. 이 방식은 벡터 검색과 키워드 검색의 스코어를 정규화한 뒤 결합하여, 더 정확한 랭킹을 제공합니다.
먼저 search pipeline을 생성합니다:
그런 다음 hybrid 쿼리로 검색합니다:
bool > must로 knn과 match를 결합하는 방식도 동작하지만, 서로 다른 스코어 체계를 정규화 없이 결합하므로 랭킹이 부정확할 수 있습니다. hybrid 쿼리 + normalization-processor search pipeline이 권장하는 하이브리드 검색 방식입니다.
테스트 시 축구 비디오의 임베딩 벡터와 “Manchester United goal football” 키워드를 결합하여 하이브리드 검색을 테스트한 결과, 벡터 유사도(가중치 0.7)와 텍스트 매칭(가중치 0.3)이 결합된 스코어가 정상적으로 반환되었습니다. 기본 k-NN 검색에서는 벡터 유사도가 높은 5건만 반환되었지만, 하이브리드 검색에서는 텍스트 매칭을 통해 더 넓은 범위의 관련 결과가 포함되면서도, 상위 결과는 벡터 유사도가 높은 축구 비디오가 차지하는 것을 확인할 수 있었습니다.
성능 결과
2,285개 벡터를 _bulk API로 인제스트하는 데 약 16.80초가 소요되었습니다. 이번 테스트에서는 배치 크기를 200으로 설정했는데, OpenSearch의 bulk API는 문서 수가 아닌 요청 크기(기본 100MB) 기반으로 제한되므로 배치 크기를 더 키울 수 있습니다. OpenSearch 공식 블로그에서는 100개부터 시작해서 성능이 더 이상 개선되지 않을 때까지 올려보는 것을 권장합니다. 다만 Serverless 환경에서는 OCU 용량에 따라 너무 큰 배치가 throttling을 유발할 수 있으므로, 워크로드에 맞는 적절한 크기를 찾는 것이 중요합니다.
검색 레이턴시는 k=5 기준 p50 약 25ms, p95 약 37ms로 측정되었으며, k 값을 10이나 20으로 늘려도 레이턴시는 비슷한 수준을 유지했습니다.
Amazon S3 Vectors
서비스 개요
Amazon S3 Vectors는 2025년에 출시된 S3 네이티브 벡터 저장/검색 서비스입니다. S3의 확장성과 내구성을 기반으로, 대규모 벡터 데이터를 저렴하게 저장하고 유사도 검색을 수행할 수 있습니다. 기존 S3 인프라와 자연스럽게 통합되며, 별도의 클러스터 관리가 필요 없습니다.
S3 Vectors의 가장 큰 강점은 설정의 간편함과 비용 효율성입니다. Vector Bucket과 Index만 생성하면 바로 사용할 수 있고, 별도의 보안 정책이나 VPC 구성 없이 기존 IAM 정책으로 접근 제어가 가능합니다. 요청 수 + 저장 용량 기반 과금으로 소규모 워크로드에서 매우 저렴하며, 벡터 키(key)를 직접 지정할 수 있어 같은 키로 다시 저장하면 자동으로 업데이트(upsert)되는 패턴도 지원합니다.
설정 과정
1. Vector Bucket 및 Index 생성
S3 Vectors는 일반 S3 버킷과 별도로 Vector Bucket을 사용합니다. Vector Bucket 내에 하나 이상의 Index를 생성하여 벡터를 저장합니다.
별도의 보안 정책을 구성할 필요 없이, 기존 IAM 정책으로 접근 제어가 가능합니다.
2. 벡터 인제스트 (boto3 SDK)
Marengo 3.0에서 생성된 임베딩을 S3 Vectors에 저장합니다. boto3 SDK의 s3vectors 클라이언트를 사용합니다.
import boto3
client = boto3.client("s3vectors", region_name="us-east-1")
# 배치 인제스트 (500개씩 - API 최대 배치 크기)
batch_size = 500
for b in range(0, len(vectors), batch_size):
batch = vectors[b:b + batch_size]
items = []
for i, v in enumerate(batch):
items.append({
"key": f"{v['video_id']}_{v['scope']}_{v['start_sec']}_{b+i}",
"data": {"float32": v["embedding"]}, # 512차원 벡터
"metadata": {
"videoId": v["video_id"],
"startSec": str(v["start_sec"]),
"endSec": str(v["end_sec"]),
"scope": v["scope"]
},
})
client.put_vectors(
vectorBucketName="my-video-vectors",
indexName="video-embeddings",
vectors=items
)S3 Vectors의 put_vectors API는 요청당 최대 500개 벡터를 지원합니다. 비용 최적화를 위해 최대 배치 크기를 사용하도록 권장합니다. 배치 크기 50과 500의 인제스트 시간 차이는 약 3배(13.46s → 4.12s)에 달했습니다.
S3 Vectors의 특징적인 점은 벡터 키(key)를 직접 지정할 수 있다는 것입니다. 같은 키로 다시 저장하면 자동으로 업데이트(upsert)되므로, 임베딩을 재생성했을 때 별도의 삭제/재생성 과정 없이 바로 갱신할 수 있습니다.
3. 벡터 검색
저장된 임베딩에서 유사한 비디오 세그먼트를 검색합니다.
2,285개 벡터를 배치 500개씩 put_vectors로 인제스트하는 데 약 4.12초가 소요되었습니다. 검색 레이턴시는 k=5 기준 p50 약 65ms, p95 약 181ms로 측정되었습니다. k 값을 늘려도 레이턴시는 비슷한 수준(k=10 p50 약 62ms, k=20 p50 약 63ms)을 유지했습니다.
테스트 결과와 각 서비스의 특성
지금까지 두 가지 서비스에 Marengo 3.0 비디오 임베딩을 저장하고 검색하는 과정을 살펴봤습니다. 동일한 환경(us-east-1, VPC 내 EC2, VPC Endpoint 구성)에서 측정한 성능 데이터를 정리하고, 테스트 과정에서 관찰된 각 서비스의 특성을 공유합니다.
검색 레이턴시

| 서비스 | k=5 p50 | k=5 p95 | k=10 p50 | k=20 p50 |
|---|---|---|---|---|
| OpenSearch Serverless | 25.18ms | 36.77ms | 23.99ms | 23.81ms |
| S3 Vectors | 65.32ms | 180.99ms | 61.53ms | 62.50ms |
Lessons Learned
배치 크기와 인제스트 방식이 성능에 주는 영향: S3 Vectors의 경우 배치 크기를 50에서 500(API 최대값)으로 변경하는 것만으로 인제스트 시간이 약 3배 개선되었습니다. 각 서비스의 API가 허용하는 최대 배치 크기를 활용하는 것이 중요합니다.
소규모 데이터셋의 한계: 2,285개 벡터는 소규모 테스트입니다. 대규모(수십만~수백만 벡터)에서는 각 서비스의 인덱싱 알고리즘, 메모리 관리, 스케일링 특성에 따라 결과가 달라질 수 있으므로, 실제 프로덕션 도입 전에는 자신의 워크로드 데이터와 쿼리 패턴으로 PoC를 수행하는 것을 권장합니다.
각 서비스의 특성
두 서비스는 각각 다른 초점을 가지고 있으며, 이는 테스트 결과에서도 잘 드러납니다.
OpenSearch Serverless는 검색 엔진으로서의 풍부한 기능이 강점입니다. 벡터 유사도 검색뿐 아니라 키워드 기반 풀텍스트 검색을 동시에 지원하므로, 비디오 메타데이터(제목, 설명, 태그 등)에 대한 키워드 검색과 임베딩 기반 시맨틱 검색을 하나의 인프라에서 수행할 수 있습니다. hybrid 쿼리와 search pipeline을 활용한 하이브리드 검색은 OpenSearch만의 차별화된 기능입니다. 다만 서버리스 환경의 최소 OCU 비용(dev/test 시 ~$175/월, 프로덕션 시 ~$350/월)이 있어, 소규모 워크로드에서는 비용 부담이 될 수 있습니다.
S3 Vectors는 설정의 간편함과 비용 효율성이 강점입니다. Vector Bucket과 Index만 생성하면 바로 사용할 수 있고, 별도의 보안 정책이나 VPC 구성이 불필요합니다. 요청 수 + 저장 용량 기반 과금으로 소규모 워크로드에서 매우 저렴하며, S3의 확장성과 내구성을 그대로 활용할 수 있으며, 관리 편의성이 높습니다.
서비스별 특성 정리
| 항목 | OpenSearch Serverless | S3 Vectors |
|---|---|---|
| 주요 강점 | 하이브리드 검색 (키워드 + 벡터) | 설정 간편함, 비용 효율성 |
| 벡터 검색 | k-NN (HNSW, IVF) | top-k 유사도 검색 |
| 풀텍스트 검색 | 지원 (하이브리드 검색 가능) | 미지원 |
| 메타데이터 필터링 | Full-text 포함 지원 | 지원 |
| 인덱스 튜닝 | 엔진/알고리즘 선택 가능 | 관리형 |
| 최대 벡터 차원 | 16,000 | 4,096 |
| 문서/벡터 ID 지정 | 불가 (Serverless vectorsearch) | 가능 (key 기반, upsert 지원) |
| 관리 오버헤드 | 낮음 (서버리스) | 매우 낮음 |
| 과금 방식 | OCU 기반 (최소 비용 존재) | 요청 수 + 저장 용량 |
결론
이번 블로그에서는 TwelveLabs Marengo 3.0으로 생성한 비디오 임베딩을 AWS의 두 가지 서비스에 저장하고 검색하는 과정을 단계별로 살펴봤습니다. 두 서비스는 서로 다른 설계 철학을 가지고 있어, 워크로드의 특성에 따라 적합한 선택이 달라집니다. OpenSearch Serverless는 키워드와 벡터를 결합한 하이브리드 검색이 필요할 때, S3 Vectors는 간편한 설정과 비용 효율성이 중요할 때 각각의 강점을 발휘합니다.
1편부터 5편까지, 이 시리즈에서는 TwelveLabs의 비디오 인텔리전스 기술을 AWS 클라우드 환경에서 활용하는 전체 여정을 다뤘습니다. 비디오 분석 파이프라인 구축(1~2편)에서 시작하여, Agentic video engine 구현(3편), 멀티모달 임베딩 전략과 검색 방법론(4편), 그리고 임베딩 저장과 검색 인프라(5편)까지 — 비디오 인텔리전스 서비스를 구축하는 데 필요한 핵심 구성 요소들을 단계별로 살펴봤습니다.
클라우드 환경에서의 TwelveLabs 기반 비디오 인텔리전스 구현 블로그는 총 5개의 시리즈로 구성이 되어 있습니다. 아래에서 관심 있는 주제를 추가로 살펴보시기 바랍니다.
TwelveLabs로 시작하는 AI 영상 분석 1부 – VoD환경에서의 비디오 분석 파이프라인 구축하기
TwelveLabs로 시작하는 AI 영상 분석 2부 – 준실시간 환경에서 AWS Elemental을 활용한 분석 파이프라인 구축하기
TwelveLabs로 시작하는 AI 영상 분석 3부 – Strands Agents SDK기반의 에이전틱 비디오 분석 에이전트 만들기
TwelveLabs로 시작하는 AI 영상 분석 4부 – TwelveLabs Marengo 3.0 임베딩 및 검색 전략과 구현 가이드