이 글은 Artificial Intelligence 블로그에 게시된 글 (Unlocking video understanding with TwelveLabs Marengo on Amazon Bedrock)을 한국어로 번역 및 편집하였습니다.
미디어와 엔터테인먼트, 광고, 교육, 그리고 기업 교육에서 사용되는 콘텐츠는 시각, 청각, 그리고 동작 요소를 결합하여 이야기를 전달하고 정보를 전달합니다. 이러한 콘텐츠는 각 단어의 의미가 명확한 텍스트와 달리 훨씬 더 복잡합니다. 이로 인해 비디오 콘텐츠를 이해해야 하는 인공지능 시스템에는 고유한 도전 과제가 생깁니다. 비디오 콘텐츠는 다차원적이며, 시각적 요소(장면, 객체, 동작), 시간적 역학(움직임, 전환), 오디오 요소(대화, 음악, 음향효과), 그리고 텍스트 오버레이(자막, 캡션)를 결합합니다. 이러한 복잡성으로 인해 기업들은 비디오 아카이브를 검색하고, 특정 장면을 찾아내거나, 콘텐츠를 자동으로 분류하고, 미디어 자산으로부터 의사결정에 활용할 인사이트를 추출하는 과정에서 어려움을 겪게 만들기 때문에 상당한 비즈니스적 챌린지를 야기합니다.
이 모델은 콘텐츠의 다양한 모달리티별로 개별 임베딩을 생성하는 다중 벡터 아키텍처를 통해 문제를 해결합니다. 모든 정보를 하나의 벡터에 강제로 통합하는 대신, 각 모달리티의 특성을 반영한 임베딩을 별도로 생성합니다. 이러한 접근 방식은 비디오 데이터의 풍부하고 다층적인 특성을 유지하면서 시각적, 시간적, 오디오적 측면에서 더욱 정교한 분석을 가능하게 합니다.
Amazon Bedrock는 이제 동기식 추론을 통해 실시간 텍스트·이미지 처리를 지원하는 TwelveLabs Marengo Embed 3.0 모델을 제공하도록 기능을 확장했습니다. 이를 통해 기업은 자연어 질의를 활용한 고속 비디오 검색은 물론, 정교한 이미지 유사도 매칭을 기반으로 한 인터랙티브 상품 탐색 경험까지 구현할 수 있습니다.
이 포스트에서는 Amazon Bedrock의 TwelveLabs Marengo 임베딩 모델이 멀티모달 AI를 통해 비디오 이해를 어떻게 강화하는지 보여드리겠습니다. Marengo 임베딩과 Amazon OpenSearch Serverless 벡터 데이터베이스를 활용해, 단순 메타데이터 매칭을 넘어선 지능형 콘텐츠 발견을 실현하는 비디오 시맨틱 검색·분석 솔루션을 구축합니다.
비디오 임베딩 개념 이해하기
임베딩은 데이터를 고차원 공간에서 의미적으로 표현하는 밀집 벡터 표현입니다. 마치 콘텐츠의 핵심을 기계가 이해하고 서로 비교할 수 있도록 숫자로 표현한 지문과 같은 역할을 합니다. 텍스트의 경우 임베딩은 “king”과 “queen”이 관련 개념임을 포착하거나, “Paris”와 “France”의 지리적 관계를 이해할 수 있습니다. 이미지에서는 골든 리트리버와 래브라도가 서로 다른 외형임에도 둘 다 개라는 사실을 인식할 수 있습니다. 다음 히트맵은 “두 사람이 대화하는”, “남녀가 이야기하는”, “고양이와 개는 사랑스러운 동물이다”라는 문장 조각들 간의 의미적 유사도 점수를 보여줍니다.
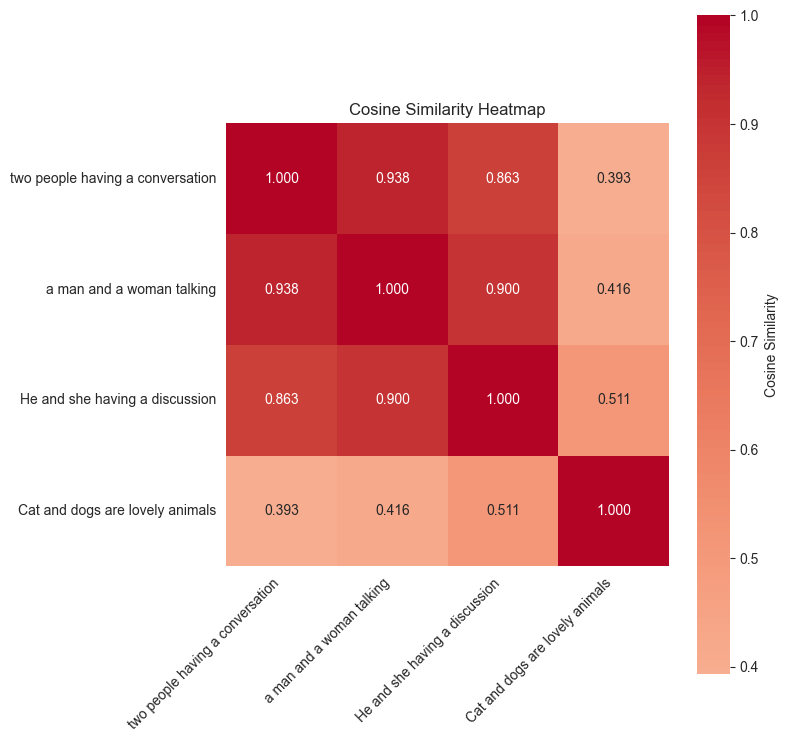
그림 1. 히트맵 (샘플 예제)
비디오 임베딩의 도전 과제
비디오는 본질적으로 멀티모달이기 때문에 고유한 도전 과제를 제시합니다:
- 시각 정보: 객체, 장면, 인물, 동작, 시각적 미학
- 오디오 정보: 음성, 음악, 음향 효과, 주변 소음
- 텍스트 정보: 자막, 화면상 텍스트, 음성 전사
기존의 단일 벡터로 임베딩하는 접근법은 이 모든 풍부한 정보를 하나의 표현으로 압축하면서 중요한 의미를 종종 상실합니다. 바로 이 점에서 TwelveLabs Marengo의 접근법이 이 문제를 효과적으로 해결하는 데 있어 독보적입니다.
Twelvelabs Marengo: 멀티 모달 임베딩 모델
Marengo 3.0 모델은 비디오 콘텐츠의 다양한 측면을 각각 포착하는 여러 개의 특화된 벡터를 생성합니다. 일반적인 영화나 TV 쇼는 시각적·청각적 요소를 결합해 통합된 스토리텔링 경험을 만듭니다. Marengo의 다중 벡터 아키텍처는 이러한 복잡한 비디오 콘텐츠 이해에 상당한 장점을 제공합니다. 각 벡터는 특정 모달리티를 담당해, 다양한 데이터 타입을 단일 표현으로 압축함으로써 발생하는 정보 손실을 방지합니다. 이를 통해 시각 전용, 오디오 전용, 또는 결합된 쿼리로 특정 콘텐츠 측면을 유연하게 검색할 수 있습니다. 특화된 벡터는 복잡한 멀티모달 시나리오에서 뛰어난 정확도를 제공하면서도 대규모 기업 비디오 데이터셋에 대한 효율적인 확장성을 유지합니다.
솔루션 개요: Marengo 모델 기능
다음 섹션에서는 코드 샘플을 통해 Marengo 임베딩 예시를 시연합니다. 이 예제들은 Marengo가 어떻게 다양한 콘텐츠 타입을 처리하고 뛰어난 검색 정확도를 제공하는지 보여줍니다. 전체 코드 샘플은 GitHub repository에서 확인할 수 있습니다.
사전 준비 사항
시작 전 아래 사항을 확인하세요.
샘플 비디오
Netflix Open Content는 Creative Commons Attribution 4.0 International 라이선스 하에 공개된 오픈소스 콘텐츠입니다. TwelveLabs Marengo 모델을 Amazon Bedrock에서 시연하기 위해 Meridian 비디오를 사용하겠습니다.

그림 2. Merdian 비디오 샘플
비디오 임베딩 생성
Amazon Bedrock은 Marengo 비디오 임베딩 생성을 위해 비동기 API를 사용합니다. 다음 Python 코드 스니펫은 S3 버킷에서 비디오를 가져오는 API 호출 예제를 보여줍니다. 전체 지원 기능은 공식 문서를 참조하세요.
#StartAsyncInvoke로 모델 실행
import boto3
bedrock_client = boto3.client("bedrock-runtime")
model_id = 'twelvelabs.marengo-embed-3-0-v1:0'
video_s3_uri = "<비디오가 저장된 S3위치>" # s3 URI로 대체
aws_account_id = "<버킷 소유자 계정>" # 버킷 소유자 ID로 대체
s3_bucket_name = "<s3 버킷 이름>" # S3 bucket 명으로 대체
s3_output_prefix = "<output 접두사>" # output 접두사로 대체
response = bedrock_client.start_async_invoke(
modelId=model_id,
modelInput={
"inputType": "video",
"video": {
"mediaSource": {
"s3Location": {
"uri": video_s3_uri,
"bucketOwner": aws_account_id
}
}
}
},
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": f's3://{s3_bucket_name}/{s3_output_prefix}'
}
}
)
위 예제는 단일 비디오에서 280개의 개별 임베딩을 생성합니다 – 각 세그먼트마다 하나씩, 정밀한 시간 기반 검색과 분석을 가능하게 합니다. 비디오의 다중 벡터 출력에서 생성되는 임베딩 타입은 다음과 같을 수 있습니다:
[
{'embedding': [0.053192138671875,...], 'embeddingOption': "visual", 'embeddingScope' : "clip", "startSec" : 0.0, "endSec" : 4.3 },
{'embedding': [0.053192138645645,...], 'embeddingOption': "transcription", 'embeddingScope' : "clip", "startSec" : 3.9, "endSec" : 6.5 },
{'embedding': [0.3235554er443524,...], 'embeddingOption': "audio", 'embeddingScope' : "clip", "startSec" : 4.9, "endSec" : 7.5 }
]
- visual – 비디오의 시각적 임베딩
- transcription – 전사된 텍스트 임베딩
- audio – 비디오 내 오디오 임베딩
오디오나 비디오 콘텐츠를 처리할 때, 임베딩 생성을 위한 각 클립 세그먼트 길이를 설정할 수 있습니다. 기본적으로 비디오 클립은 자연스러운 장면 전환(샷 바운더리)에서 자동 분할됩니다. 오디오 클립은 10초에 최대한 가까운 균등 세그먼트로 나뉩니다 – 예를 들어 50초 오디오는 5개의 10초 세그먼트, 16초 오디오는 2개의 8초 세그먼트가 됩니다.
단일 Marengo 비디오 임베딩 API는 기본적으로 visual-text, visual-image, audio 임베딩을 생성하지만 특정 임베딩 타입만 출력하도록 기본 설정도 변경 가능합니다. 다음 코드 스니펫을 사용해 Amazon Bedrock API로 설정 가능한 옵션과 함께 비디오 임베딩을 생성할 수 있습니다.
#상세 임베딩 설정
response = bedrock_client.start_async_invoke(
modelId=model_id,
modelInput={
"modelId": model_id,
"modelInput": {
"inputType": "video",
"video": {
"mediaSource": {
"base64String": "base64-encoded string", // base64String OR s3Location, exactly one
"s3Location": {
"uri": "s3://amzn-s3-demo-bucket/video/clip.mp4",
"bucketOwner": "123456789012"
}
},
"startSec": 0,
"endSec": 6,
"segmentation": {
"method": "dynamic", // dynamic OR fixed, 하나만 선택
"dynamic": {
"minDurationSec": 4
}
"method": "fixed",
"fixed": {
"durationSec": 6
}
},
"embeddingOption": [
"visual",
"audio",
"transcription"
], // optional, 기본값은 all
"embeddingScope": [
"clip",
"asset"
] // optional,1개 혹은 전부
},
"inferenceId": "some inference id"
}
}
)
벡터 데이터베이스: Amazon OpenSearch Serverless
예제에서는 주어진 비디오에서 Marengo 모델로 생성된 텍스트, 이미지, 오디오, 비디오 임베딩을 저장하기 위해 Amazon OpenSearch Serverless를 벡터 데이터베이스로 사용합니다. 벡터 데이터베이스로서 OpenSearch Serverless는 서버나 인프라 관리를 신경 쓰지 않고도 시맨틱 검색으로 유사 콘텐츠를 빠르게 찾을 수 있게 해줍니다. 다음 코드 스니펫은 Amazon OpenSearch Serverless 컬렉션을 생성하는 방법을 보여줍니다:
aoss_client = boto3_session.client('opensearchserverless')
try:
collection = self.aoss_client.create_collection(
name=collection_name, type='VECTORSEARCH'
)
collection_id = collection['createCollectionDetail']['id']
collection_arn = collection['createCollectionDetail']['arn']
except self.aoss_client.exceptions.ConflictException:
collection = self.aoss_client.batch_get_collection(
names=[collection_name]
)['collectionDetails'][0]
pp.pprint(collection)
collection_id = collection['id']
collection_arn = collection['arn']
OpenSearch Serverless 컬렉션이 생성되면 벡터 필드를 포함하는 속성을 가진 인덱스를 생성합니다.
index_mapping = {
"mappings": {
"properties": {
"video_id": {"type": "keyword"},
"segment_id": {"type": "integer"},
"start_time": {"type": "float"},
"end_time": {"type": "float"},
"embedding": {
"type": "dense_vector",
"dims": 1024,
"index": True,
"similarity": "cosine"
},
"metadata": {"type": "object"}
}
}
}
credentials = boto3.Session().get_credentials()
awsauth = AWSV4SignerAuth(credentials, region_name, 'aoss')
oss_client = OpenSearch(
hosts=[{'host': host, 'port': 443}],
http_auth=self.awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
timeout=300
)
response = oss_client.indices.create(index=index_name, body=index_mapping)
Marengo 임베딩 인덱싱
다음 코드 스니펫은 Marengo 모델로 부터 생성된 임베딩을 OpenSearch 인덱스에 수집하는 방법을 제공합니다.
documents = []
for i, segment in enumerate(video_embeddings):
document = {
"embedding": segment["embedding"],
"start_time": segment["startSec"],
"end_time": segment["endSec"],
"video_id": video_id,
"segment_id": i,
"embedding_option": segment.get("embeddingOption", "visual")
}
documents.append(document)
# Bulk index documents
bulk_data = []
for doc in documents:
bulk_data.append({"index": {"_index": self.index_name}})
bulk_data.append(doc)
# Convert to bulk format
bulk_body = "\n".join(json.dumps(item) for item in bulk_data) + "\n"
response = oss_client.bulk(body=bulk_body, index=self.index_name)
교차 모달 의미 검색 (Cross-modal semantic search)
Marengo의 멀티 벡터 설계로 단일 벡터 모델로는 불가능했던 다양한 모달리티 간 검색이 가능합니다. 시각, 오디오, 모션, 컨텍스트 요소에 대해 별도이지만 정렬된 임베딩을 생성하여, 원하는 입력 타입으로 비디오를 검색할 수 있습니다.
예시로 “재즈 음악 연주”로 검색하면 뮤지션 공연 영상 클립, 재즈 오디오 트랙, 그리고 콘서트홀 장면 모두를 반환합니다.
다음 예제들은 Marengo의 탁월한 크로스 모달 검색 기능을 보여줍니다:
텍스트 검색
다음은 텍스트로 교차 모달 의미 검색 기능을 선보이는 코드 스니펫을 보여줍니다.
text_query = "a person smoking in a room"
modelInput={
"inputType": "text",
"text": {
"inputText": text_query
}
}
response = self.bedrock_client.invoke_model(
modelId="us.twelvelabs.marengo-embed-3-0-v1:0",
body=json.dumps(modelInput))
result = json.loads(response["body"].read())
query_embedding = result["data"][0]["embedding"]
# Search OpenSearch index
search_body = {
"query": {
"knn": {
"embedding": {
"vector": query_embedding,
"k": top_k
}
}
},
"size": top_k,
"_source": ["start_time", "end_time", "video_id", "segment_id"]
}
response = opensearch_client.search(index=self.index_name, body=search_body)
print(f"\n Found {len(response['hits']['hits'])} matching segments:")
results = []
for hit in response['hits']['hits']:
result = {
"score": hit["_score"],
"video_id": hit["_source"]["video_id"],
"segment_id": hit["_source"]["segment_id"],
"start_time": hit["_source"]["start_time"],
"end_time": hit["_source"]["end_time"]
}
results.append(result)
텍스트 쿼리 “a person smoking in a room(방 안에서 담배를 피우는 사람)”에 대한 최상위 검색 결과는 다음과 같은 비디오 클립을 반환합니다.

그림 3. 반환된 비디오 클립 1
이미지 검색
다음 코드 스니펫은 아래 주어진 이미지에 대한 크로스 모달 의미 검색 기능을 시연합니다:
 그림 4. 샘플 이미지
그림 4. 샘플 이미지
s3_image_uri = f's3://{self.s3_bucket_name}/{self.s3_images_path}/{image_path_basename}'
s3_output_prefix = f'{self.s3_embeddings_path}/{self.s3_images_path}/{uuid.uuid4()}'
modelInput={
"inputType": "image",
"image": {
"mediaSource": {
"s3Location": {
"uri": s3_image_uri,
"bucketOwner": self.aws_account_id
}
}
}
}
response = self.bedrock_client.invoke_model(
modelId=self.cris_model_id,
body=json.dumps(modelInput),
)
result = json.loads(response["body"].read())
...
query_embedding = result["data"][0]["embedding"]
# Search OpenSearch index
search_body = {
"query": {
"knn": {
"embedding": {
"vector": query_embedding,
"k": top_k
}
}
},
"size": top_k,
"_source": ["start_time", "end_time", "video_id", "segment_id"]
}
response = opensearch_client.search(index=self.index_name, body=search_body)
print(f"\n Found {len(response['hits']['hits'])} matching segments:")
results = []
for hit in response['hits']['hits']:
result = {
"score": hit["_score"],
"video_id": hit["_source"]["video_id"],
"segment_id": hit["_source"]["segment_id"],
"start_time": hit["_source"]["start_time"],
"end_time": hit["_source"]["end_time"]
}
results.append(result)
위 이미지를 사용한 최상위 검색 결과는 다음과 같은 비디오 클립을 반환합니다.

그림 5. 반환된 비디오 클립 2
비디오에 텍스트와 이미지를 사용한 의미 검색 외에도, Marengo 모델은 대화와 음성에 초점을 맞춘 오디오 임베딩으로 비디오를 검색할 수 있습니다. 오디오 검색 기능은 특정 화자, 대화 내용, 음성 주제를 기반으로 비디오를 찾도록 도와주며, 이런 기능적 특징을 활용하여 텍스트·이미지·오디오를 결합한 종합 비디오 검색 경험을 제공합니다.
Conclusion
TwelveLabs Marengo와 Amazon Bedrock의 조합은 멀티 벡터·멀티모달 접근으로 비디오 이해의 새로운 가능성을 열어줍니다. 본 포스트에서는 이미지-비디오 검색(시간 정밀도 포함), 상세 텍스트-비디오 매칭 등의 실용적 예제를 살펴보았습니다. 단일 Bedrock API 호출로 하나의 비디오 파일을 336개 검색 가능한 세그먼트로 변환하여 텍스트·시각·오디오 쿼리에 즉시 응답합니다. 이러한 기능은 자연어 콘텐츠 발견, 효율적인 미디어 자산 관리, 그리고 조직이 대규모 비디오 콘텐츠를 더 잘 이해하고 활용할 수 있는 다양한 애플리케이션으로 이어집니다.
비디오가 디지털 경험을 지배하는 시대에, Marengo와 같은 모델은 더 지능적인 비디오 분석 시스템 구축의 탄탄한 기반을 제공합니다. 샘플 코드를 확인하여 멀티모달 비디오 이해가 애플리케이션을 어떻게 혁신할 수 있는지 발견해보세요.