O blog da AWS
Aumentando a resiliência de aplicações baseadas em LLM na AWS com LiteLLM – Parte 1
Por Guilherme Ricci, Arquiteto de Soluções Sênior, para startups na AWS e Phelipe Fabres, Arquiteto de Soluções da AWS.
Os Foundation Models (FMs), seguidos dos Large Language Models (LLMs) revolucionaram aplicações empresariais, desde chatbots até sistemas de análise documental, tornando-se componentes críticos para operações que impactam diretamente receita e experiência do usuário. No entanto, essa rápida adoção trouxe desafios operacionais significativos que muitas organizações não previram durante o desenvolvimento.
As equipes de desenvolvimento que utilizam serviços que entregam FM enfrentam obstáculos como limitações de requisições por minuto (RPM) e tokens por minuto (TPM). Essas características únicas do uso de serviços de IA Generativa diferem significativamente das APIs tradicionais, comprometendo a estabilidade em produção.
Para aplicações críticas, esses problemas podem resultar em perdas diretas de receita, degradação da experiência do usuário e danos à reputação da marca. A dependência de um único modelo ou região cria pontos únicos de falha que comprometem toda a operação, tornando essencial a implementação de arquiteturas resilientes distribuídas.
Essa é a primeira parte que vai destacar como o LiteLLM consegue ajudar a aumentar a resiliência de aplicações que enfrentam essas dificuldades. Na parte 2, abordaremos técnicas avançadas de resiliencia com LiteLLM.
Maximizando Resiliência: Cross-Region Inference e Estratégias de Fallback
O Cross-Region Inference é uma funcionalidade nativa do Amazon Bedrock que distribui requisições entre múltiplas regiões AWS de forma transparente, otimizando os limites de requisições disponíveis e melhorando a resiliência do sistema. Por exemplo, configurar múltiplas regiões pode aumentar seus limites de requisições por minuto (RPM) em até duas vezes a quota da região padrão.
Esta estratégia oferece benefícios sem exigir modificações complexas no código existente, pois o Amazon Bedrock gerencia internamente o roteamento. Usuários em diferentes localizações são automaticamente direcionados para outra região quando um limite de quota surgir, resultando em tempos de resposta com aumento de dois dígitos de milissegundos, enquanto a distribuição geográfica fornece proteção natural contra falhas regionais. Pode conferir mais detalhes aqui.
Um fator técnico que denota o uso do Cross-Region é o prefixo da região no model Id. Por exemplo: o modelo DeepSeek R1 tem o model id como “deepseek.r1-v1:0”. Sua versão usando as regiões da América do Norte é definida pelo prefixo “us”, ficando: “us.deepseek.r1-v1:0” assim como da Europa é definida por “eu”, sendo: “eu.deepseek.r1-v1:0”. Os models Id e perfis de inferência podem ser consultados na documentação.
A Criticidade de Modelos LLM Alternativos para Continuidade Operacional
A escolha e implementação de modelos LLM alternativos representa uma das decisões arquiteturais mais críticas para aplicações empresariais que dependem de inteligência artificial. Diferentemente de APIs tradicionais que possuem padrões de disponibilidade previsíveis, os serviços de LLM enfrentam desafios únicos como limitações dinâmicas de RPM/TPM, indisponibilidade temporária de provedores externos e variações de performance entre diferentes horários e cargas de trabalho. Ter um modelo alternativo não é apenas uma medida preventiva, mas uma necessidade operacional que pode determinar a diferença entre manter a continuidade do negócio ou enfrentar interrupções custosas que impactam diretamente a receita e a experiência do usuário.
Como selecionar Modelos LLM Alternativos
1. Avaliando Compatibilidade de Modelos
Para identificar modelos alternativos compatíveis, comece analisando as capacidades fundamentais do seu modelo principal: tamanho do contexto suportado, habilidades multimodais (texto, imagem, código), capacidade de seguir instruções complexas e formato de resposta estruturada. Compare essas características com modelos candidatos – por exemplo, se seu modelo principal processa documentos longos, evite alternativas com contexto limitado; se trabalha com análise de código, priorize modelos com forte performance em tarefas técnicas.
Considere também a arquitetura subjacente: modelos da mesma família (como diferentes versões do Claude ou Llama) tendem a ter comportamentos mais consistentes, enquanto modelos de provedores diferentes podem oferecer maior diversidade de abordagem, que exigem mais validação.
2. Equilibrando Performance e Custos
A análise de performance deve considerar tanto latência quanto throughput em cenários reais de uso, testando os modelos candidatos com cargas de trabalho
representativas da sua aplicação. Modelos mais rápidos nem sempre são mais eficientes e alguns podem requerer mais iterações ou tokens para atingir a qualidade desejada, impactando o custo total por tarefa. Estabeleça métricas claras como tempo médio de resposta aceitável e custo máximo por requisição.
3. Validação Prática com Dados Reais
Uma estratégia para validar a compatibilidade de modelos alternativos é começar com logs de requisições reais já capturadas e com informações pessoas devidamente removidas, da sua aplicação. Selecione uma amostra representativa de 50-100 interações diversas e execute-as tanto no modelo principal quanto no candidato a alternativo. Compare não apenas a qualidade das respostas, mas também aspectos como aderência ao tom desejado, estrutura de output e capacidade de manter contexto. Implemente essa validação de forma gradual: inicie com testes offline usando dados históricos, depois introduza o modelo alternativo em um pequeno percentual do tráfego real (5-10%) com monitoramento ativo de métricas de qualidade e satisfação do usuário, permitindo rollback imediato caso detecte degradação significativa na experiência.
O LiteLLM: Abstraindo a Complexidade de Múltiplos Provedores
O LiteLLM é uma biblioteca open-source desenvolvida para resolver os desafios de integração e gerenciamento de múltiplos provedores de LLM, suportando mais de 100 serviços diferentes, incluindo Amazon Bedrock, OpenAI, Anthropic e similares. Esta robusta ferramenta vai além da simples abstração de APIs, oferecendo funcionalidades avançadas como fallback automático entre modelos, balanceamento de carga configurável, lógica de retentativa sofisticada com diferentes estratégias de backoff, e monitoramento detalhado de métricas de performance, custos e taxa de erro.
O LiteLLM pode ser utilizado tanto como biblioteca Python integrada diretamente na aplicação quanto como proxy server containerizado com API REST. Além disso, oferece cache de respostas para otimização de custos, streaming para melhor experiência do usuário e integração nativa com sistemas de monitoramento como Amazon CloudWatch, formando uma solução completa para ambientes de produção que dependem criticamente de serviços de LLM.
O papel do Redis para o LiteLLM
O Redis desempenha um papel crítico na arquitetura do LiteLLM, funcionando como sistema de coordenação distribuída que permite que múltiplas instâncias compartilhem informações sobre o estado dos endpoints de LLM. Este componente é essencial para implementar um sistema de rate limiting distribuído que rastreia requisições e tokens consumidos em tempo real, permitindo que os limites dos provedores sejam respeitados mesmo em arquiteturas distribuídas. Além disso, o LiteLLM utiliza o Redis para armazenar métricas de performance e gerenciar circuit breakers, permitindo que o sistema tome decisões inteligentes de roteamento baseadas em uma visão global.
Para ambientes de produção na AWS, o Amazon ElastiCache oferece Redis OSS e Valkey gerenciado com alta disponibilidade, eliminando o risco de um ponto único de falha na camada de coordenação. Esta configuração é particularmente importante em cenários de alta concorrência, onde múltiplas instâncias da aplicação precisam tomar decisões coordenadas sobre roteamento de requisições, fallback entre provedores e distribuição eficiente de carga, evitando erros por limite de quota e possíveis bloqueios de API que poderiam comprometer a operação de sistemas baseados em LLMs.
Importância do timeout
Uma vez que o Amazon Bedrock possui métricas de controle de requisições por minuto (RPM), ao receber um erro de limite de quota, é recomendado que se aguarde pelo menos 60 segundos para uma nova requisição para o modelo em questão.
Logo, se faz relevante o uso de Redis para saber quando foi feita a última requisição e voltar apenas quando um tempo mínimo for cumprido. Um erro comum, é por exemplo, executar 3 requisições em sequência, com tempos de espera baixo como 5 a 10 segundos, não obter sucesso e devolver uma mensagem de erro ao usuário. Aqui técnicas como exponential backoff, onde a cada retentativa o tempo de espera é aumentado, aumenta a chance de sucesso na próxima tentativa. Outra técnica é o Jitter aleatório quando adicionamos tempos aleatórios entre chamadas, principalmente em arquiteturas com concorrência para evitar a competição e sincronismo.
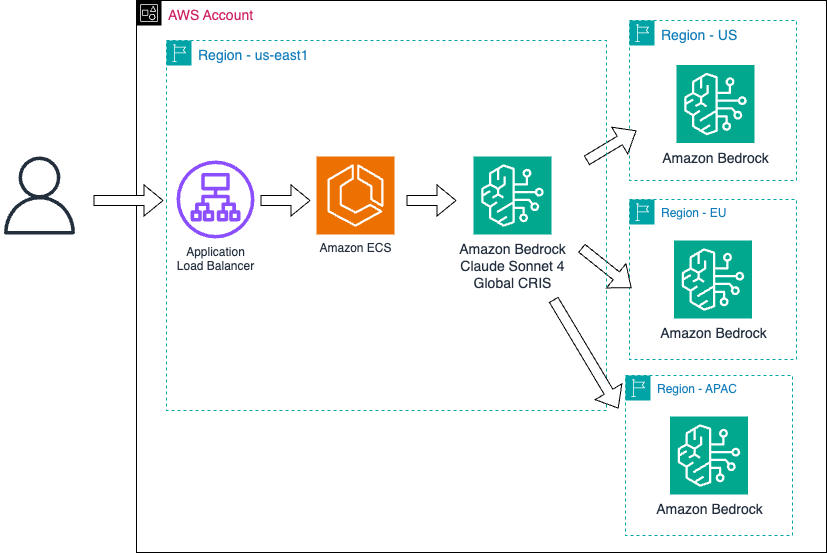
Configuração Cross-Region Inference
No momento dessa publicação, os modelos Claude Sonnet 4 e 4.5 possuem a opção de Cross-Region Inference Global, o que permite que ele alterne automaticamente entre as regiões da América do Norte, Europa e Ásia-Pacífica. Ressaltando que o Cross-region é de uso exclusivo do Amazon Bedrock e tem caso de uso para situações em que apenas um determinado modelo é válido para sua aplicação, por exemplo, um time que decide utilizar exclusivamente o modelo Claude Sonnet 4.5.
Veja um exemplo de código:
Implementando LiteLLM como Gateway para aumento de Throughput
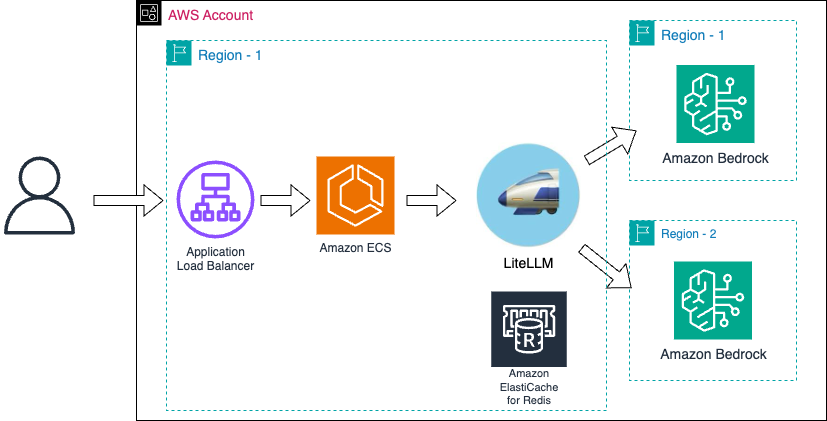
Baseado na primeira arquitetura apresentada, implementamos distribuição entre regiões AWS aproveitando o Cross-Region Inference do Bedrock. Aqui temos um exemplo que balanceia o Amazon Nova Pro entre as regiões de América do Norte e Europa.
Conclusão
Implementar estratégias robustas de resiliência para aplicações baseadas em LLMs não é apenas uma boa prática – é uma necessidade competitiva. Como vimos, o Amazon Bedrock oferece recursos nativos como Cross-Region Inference que, quando combinado com o poder do LiteLLM e estruturas de coordenação como o Redis via Amazon ElastiCache, criam sistemas capazes de sustentar operações mesmo durante interrupções regionais ou limitações de provedores específicos. Estas abordagens ajudam a proteger suas aplicações contra os desafios únicos dos LLMs, incluindo limitações de quota de uso.
Ainda existe a possibilidade de solicitar ao seu gerente de contas ou via AWS Support, um aumento dos limites como requisições por minuto (RPM) e tokens por minuto (TPM). Importante ressaltar que cada caso será analisado, portanto proveja o máximo de informações e detalhes para o time contatado.
O resultado é uma arquitetura que não apenas maximiza a disponibilidade, mas também otimiza custos através de balanceamento inteligente e fallback automático. O LiteLLM fornece a camada de abstração necessária para gerenciar a complexidade subjacente, permitindo que desenvolvedores alternem facilmente entre modelos e provedores sem modificações significativas de código.
Sobre os autores
 |
Guilherme Ricci é Arquiteto de Soluções Sênior, para startups na Amazon Web Services, especializado no Setor Financeiro, ajudando startups a modernizar e criar arquiteturas escaláveis resilientes e de baixo custo, além de modernizar suas aplicações. Com mais de 15 anos de experiência em empresas do setor financeiro, atualmente trabalha com a equipe de especialistas em AI. |
 |
Phelipe Fabres é Arquiteto de Soluções da AWS especializado em arquiteturas modernas Serverless e generative AI com Ph.D em Teoria dos Grafos. |
Sobre os revisores
| Yan Victor Marim é Arquiteto de Soluções Sênior especializado em Generative AI & Machine Learning na Amazon Web Services, focado nos setores Financeiro e Retail. Com mais de 5 anos de experiência, ajuda empresas a implementar soluções inovadoras de inteligência artificial e modernizar suas aplicações através de arquiteturas escaláveis, resilientes e otimizadas para custo. | |
 |
Renato Leal é Arquiteto Especialista em Inteligência Artificial na AWS. Com 12 anos de experiência em tecnologia, atuou em startups, big techs e consultorias internacionais. Hoje ele ajuda empresas de diversos segmentos como fornecedores independentes de software (ISVs), automotivo, manufatura, educação, saúde e governo a implementar soluções de IA. Fora do trabalho, Renato é apaixonado por esportes automotivos como a Fórmula 1. |