O blog da AWS
Category: Analytics

Como a IA da UNIP ajuda na escolha do curso superior
Por Fábio Velho, CEO da ITCORE Cloud Solutions; Marcello Vannini, CIO do Grupo Unip – Objetivo e Vanessa Fernandes, AWS Partner Solutions Architect. Introdução Escolher uma carreira é uma das decisões mais importantes e solitárias da vida de um jovem. No Brasil, a falta de orientação estruturada reflete um cenário crítico: o Mapa do Ensino Superior 2024 […]

Araujo acelera e democratiza análises de dados usando Amazon Quick Suite
Por Júlio Cesar Camargo, Transformação Digital e Data & Analytics e IA na Drogaria Araujo; Jonathas Castro, Product Manager Sênior e lidera a célula de prototipação da A3Data; Paulo Laurentys, Chief Operations Officer (COO) e sócio da A3Data e Michael Costa, arquiteto de Soluções na Amazon Web Services Brasil. As empresas enfrentam um desafio crítico na […]
Melhorando o throughput de cargas de trabalho serverless de streaming para Kafka
Por Anton Aleksandrov, Prin. SSA, Serverless e Alexander Vladimirov, Sr. SSA, Serverless. Aplicações orientadas a eventos frequentemente precisam processar dados em tempo real. Quando você usa AWS Lambda para processar registros de tópicos Apache Kafka, você frequentemente encontra dois requisitos típicos: você precisa processar volumes muito altos de registros em tempo quase real, e você […]
Apresentando ferramentas de mapeamento de origem de eventos do AWS Lambda no AWS Serverless MCP Server
Por Ben Freiberg, Sr. Solutions Architect e Shubham Nanda, Software Development Engineer. Aplicações Serverless modernas dependem cada vez mais de arquiteturas orientadas a eventos, onde funções AWS Lambda processam eventos de várias fontes como Amazon Kinesis, Amazon DynamoDB Streams, Amazon Simple Queue Service (Amazon SQS), Amazon Managed Streaming for Apache Kafka (Amazon MSK), e Apache […]
Orquestrando processamento de Big Data com AWS Step Functions Distributed Map
Por Biswanath Mukherjee, Sr. Solutions Architect e Rahul Sringeri, Technical Account Manager. Desenvolvedores buscam processar e enriquecer conjuntos de dados semi-estruturados de Big Data com fluxos de trabalho baseados em rede de orquestrados de forma durável. Por exemplo, durante a temporada de resultados trimestrais, organizações financeiras executam milhares de simulações de mercado simultaneamente para fornecer […]
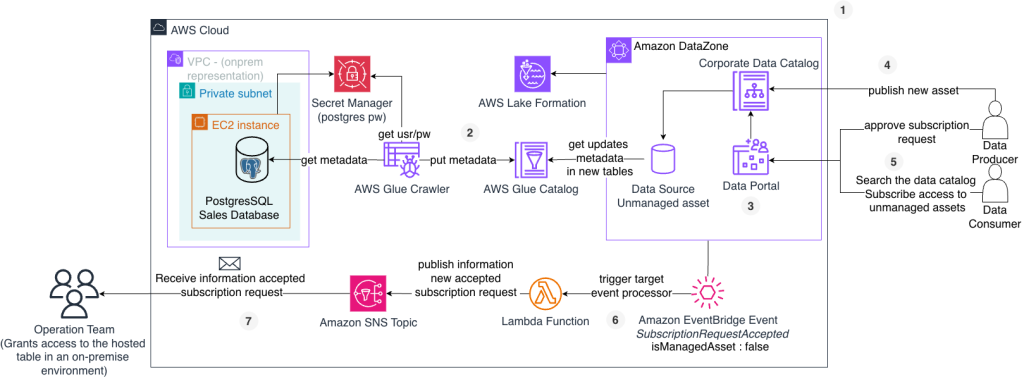
Como governar assets não gerenciados com Amazon DataZone
Por Nayra Gomes, Arquiteta de Soluções na AWS Brasil e Vinicius Batista, Arquiteto de Soluções Sr da AWS Brasil no time de Setor Público com foco em Governo. A governança de dados em ambientes híbridos representa um grande desafio para organizações que possuem sistemas on-premises e também sistemas em nuvem. Muitas empresas desejam centralizar a […]
AWS e SoftwareOne aprimoram Observabilidade e Operações na Nuvem com OneVision
Por Daniel Spinola, Diretor Sênior na SoftwareOne para a América Latina; Claviston Souza, Gerente de Entrega de Serviços da AWS; Renan Bueno, Especialista Sênior em Nuvem na SoftwareOne LATAM; Carlos Felicio, Senior Partner Technical Account Manager da AWS LATAM e Mateus Pereira, um Arquiteto de Soluções Sênior de Parceiros na AWS. Sobre a SoftwareOne A […]
Crie uma base de conhecimento just-in-time com o Amazon Bedrock
Por Steven Warwick, arquiteto sênior de soluções na AWS. Empresas que oferecem software como serviço (SaaS) com múltiplos clientes (tenants) enfrentam um desafio crucial: como extrair eficientemente insights relevantes de grandes volumes de documentos, mantendo os custos sob controle. As estratégias convencionais frequentemente resultam em desperdício de recursos de armazenamento e processamento não utilizados, comprometendo […]

O Poder dos Grafos: Como o Itaú Inovou ao Basear Sua Base de Bilhões de Documentos de Clientes no Amazon Neptune Para Realizar Buscas em Milissegundos
Por Roberto Perillo, arquiteto de soluções enterprise da AWS Brasil; Andressa Fernandes, Staff Engineer do Itaú-Unibanco S.A. e Thiago Wagner Caleme, Group Tech Manager do Itaú-Unibanco S.A. Neste blog post, exploramos a solução adotada no IU Docs, o sistema do Itaú responsável por informações referentes a documentos de clientes e como eles se relacionam. Exploramos […]

Caso de Sucesso – Saiba como o Open Finance Brasil processa mais de 1 bilhão de requisições por dia na AWS
Escrito por Thiarê Kiapine Costa, Head de Dados & Engenharia, Open Finance; Thomas de Almeida Rabelo, Tech Lead de Engenharia, Open Finance; Thiago Maciel, Engenheiro de Software, Darede; Laura Zitelli de Souza, Arquiteta de Soluções, AWS Brasil Setor Público; Isabela Gherson Monteiro, Arquiteta de Soluções, AWS Brasil Setor Público e Amanda Quinto, Arquiteta de Soluções, […]