O blog da AWS
Desmembrando fluxos de trabalho monolíticos: Modularizando fluxos de trabalho do AWS Step Functions
Por Sahithi Ginjupalli, Cloud Support Eng. II e Harold Sun, Cloud Support Eng. II.
Você pode usar o AWS Step Functions para orquestrar problemas de negócios complexos. No entanto, à medida que os fluxos de trabalho crescem e evoluem, você pode se encontrar lidando com máquinas de estado monolíticas que se tornam cada vez mais difíceis de manter e atualizar. Nesta publicação, mostramos estratégias para decomposição de grandes fluxos de trabalho do Step Functions em componentes modulares e de fácil manutenção. Mergulhamos profundamente em padrões arquiteturais como fluxos de trabalho pai-filho, separação baseada em domínio e utilitários compartilhados que podem ajudá-lo a quebrar a complexidade mantendo a funcionalidade de negócios. Ao implementar essas técnicas de desacoplamento, você pode alcançar implantações mais rápidas, melhor isolamento de erros e redução de sobrecarga operacional – tudo isso mantendo seus fluxos de trabalho escaláveis e eficientes. Seja lidando com processamento de pagamentos, transformação de dados ou lógica de negócios complexa, esses padrões ajudarão você a construir aplicações Step Functions mais resilientes e gerenciáveis.
A Complexidade das Arquiteturas de Máquina de Estado Única
Embora fluxos de trabalho monolíticos possam ser adequados para processos simples e lineares com estados limitados e dependências claras, eles se tornam problemáticos ao lidar com lógica de negócios complexa em múltiplos domínios. Se seu fluxo de trabalho envolve mais de 15-20 estados, cruza múltiplos domínios de negócios ou requer atualizações frequentes de diferentes equipes, é um forte indicador de que você deve considerar uma abordagem decomposta em vez de uma monolítica. No entanto, fluxos de trabalho monolíticos permanecem uma escolha válida para cenários com lógica de negócios direta, propriedade de uma única equipe, mudanças pouco frequentes e fluxos de trabalho com menos de 15 estados – especialmente quando desenvolvimento rápido e depuração simplificada são prioridades.
Vamos examinar um exemplo do mundo real de tal fluxo de trabalho monolítico e entender os desafios que ele apresenta para equipes de desenvolvimento, eficiência operacional e agilidade de negócios. Abaixo está um exemplo de uma máquina de estado que é uma mistura de processos de pagamento, gerenciamento de inventário e mecanismos de notificação para uma implementação de e-commerce:
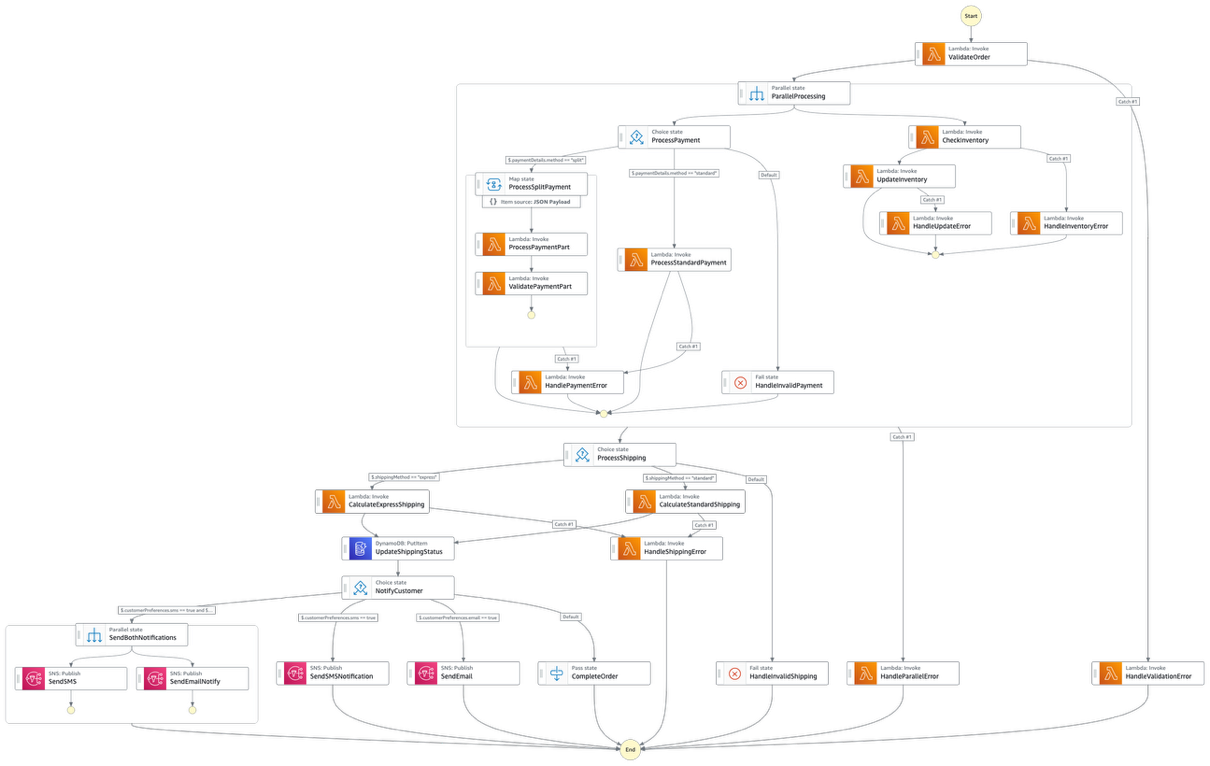
Figura 1: Uma máquina de estado que é uma mistura de processos de pagamento, gerenciamento de inventário e mecanismos de notificação para uma implementação de e-commerce
Explosão de Estados
Modificar um único estado em um fluxo de trabalho monolítico desencadeia uma cascata de mudanças em múltiplos estados interconectados devido ao seu acoplamento forte e dependências. Por exemplo, adicionar um novo método de pagamento exigiria modificações em vários estados incluindo validação, processamento e tratamento de erros, criando um efeito cascata em todo o fluxo de trabalho. Esta interdependência torna até mesmo mudanças simples complexas e arriscadas, pois alterar um componente pode ter consequências não intencionais em outras partes do fluxo de trabalho.
Olhando para a arquitetura fornecida, podemos ver um exemplo claro de explosão de estados onde um único fluxo de trabalho lida com múltiplos processos de negócios incluindo validação de pedidos, processamento de pagamentos, gerenciamento de inventário, cálculos de envio e notificações ao cliente. Isso cria uma teia complexa de estados dependentes que se torna cada vez mais difícil de gerenciar. O resultado é uma “teia de aranha” de estados que se torna progressivamente mais difícil de entender, depurar e manter.
Gerenciamento de Versões
O gerenciamento de versões em fluxos de trabalho monolíticos requer a implantação de todo o fluxo de trabalho mesmo para pequenas mudanças em componentes individuais, tornando difícil isolar e atualizar lógica de negócios específica. A arquitetura fornecida demonstra claramente o desafio do gerenciamento de versões. Por exemplo, se a lógica de cálculo de envio precisa de uma correção urgente, todo o fluxo de trabalho deve ser reimplantado, exigindo testes abrangentes de todos os componentes, incluindo os não modificados, para garantir que nada quebre no processo.
Limitações de Recursos
Embora não imediatamente visível no diagrama de arquitetura, fluxos de trabalho monolíticos enfrentam restrições operacionais à medida que crescem em complexidade, particularmente com transições de estado, tamanho máximo de payload de evento e tamanho do histórico de execução. Consulte a documentação de cotas de serviço para entender tais limites. Essas restrições se tornam gargalos críticos à medida que os fluxos de trabalho crescem em complexidade e lidam com volumes de transações aumentados. Na máquina de estado monolítica, operações de longa duração como processamento de pagamentos e cálculos de envio, combinadas com múltiplas transições de estado, poderiam se aproximar desses limites, especialmente para cenários de alto volume.
Além disso, também encontramos desafios genéricos de design como tratamento de erros. Na abordagem monolítica, fluxos de trabalho levam a blocos try-catch redundantes e configurações de retry em diferentes operações. Isso cria desafios na implementação de estratégias de erro distintas para diferentes cenários de negócios e torna difícil manter mecanismos adequados de rollback quando falhas ocorrem em estados intermediários.
Esses desafios coletivamente destacam a necessidade de uma abordagem mais modular para o design de fluxos de trabalho do Step Functions.
Transformando Fluxos de Trabalho Complexos Através da Decomposição
Ao transformar fluxos de trabalho monolíticos complexos em componentes mais gerenciáveis, você pode empregar várias estratégias de decomposição para alcançar melhor modularidade e manutenibilidade. Essas estratégias incluem o padrão pai-filho, que cria uma estrutura hierárquica de fluxos de trabalho, separação de domínio que decompõe fluxos de trabalho com base em capacidades de negócios, utilitários compartilhados que servem como componentes reutilizáveis para operações comuns, e fluxos de trabalho de erro especializados para tratamento centralizado de erros. Cada uma dessas estratégias pode ser implementada individualmente ou em combinação, dependendo dos requisitos específicos e complexidade da aplicação, permitindo que organizações criem fluxos de trabalho Step Functions mais eficientes, escaláveis e de fácil manutenção, garantindo separação adequada de responsabilidades e redução de sobrecarga operacional.
Padrão Pai-Filho
O padrão pai-filho representa uma abordagem hierárquica para organização de fluxos de trabalho onde um fluxo de trabalho principal (pai) orquestra múltiplos sub-fluxos de trabalho (filhos). Fluxos de trabalho pai gerenciam o processo de negócios geral e coordenação, enquanto fluxos de trabalho filho lidam com operações específicas de curta duração. Este padrão é particularmente eficaz quando você precisa equilibrar entre complexidade de orquestração e velocidade de execução.
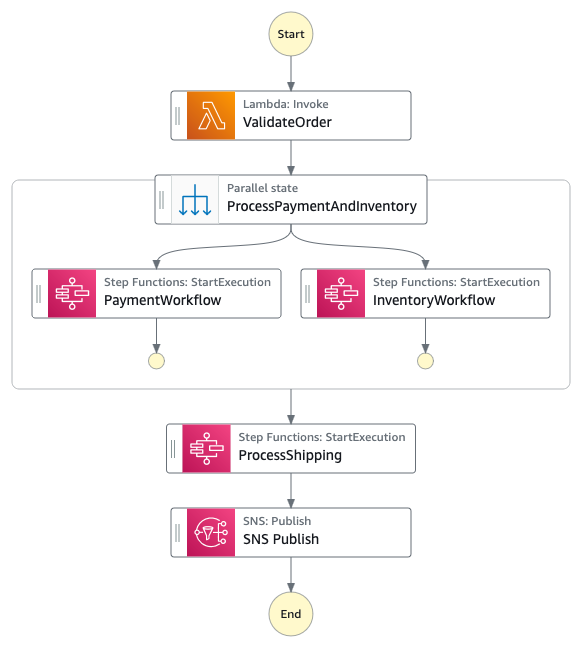
Figura 2 : Máquina de estado pai desacoplada
O fluxo de trabalho monolítico atual pode ser reestruturado criando um fluxo de trabalho pai focado na orquestração de pedidos enquanto delega operações específicas para fluxos de trabalho filho Express. O fluxo de trabalho pai manteria o fluxo de alto nível desde a validação do pedido até a conclusão, enquanto operações sensíveis ao tempo como ValidateOrder, ProcessPayment e ProcessShipping poderiam se tornar fluxos de trabalho filho Express.
Observe que durante uma reformulação de arquitetura, fluxos de trabalho Express são diferentes quando comparados a Fluxos de Trabalho Standard. Por exemplo, você não pode ter um fluxo de trabalho pai Express invocar um fluxo de trabalho filho Standard. Além disso, um fluxo de trabalho Express não suporta padrões de integração de serviço Job-run (.sync) ou Callback (.waitForTaskToken). Você pode consultar a documentação de diferenças entre fluxos de trabalho Standard e Express para escolher o padrão de arquitetura correto.
Por exemplo, a seção de processamento de pagamentos poderia ser transformada em um fluxo de trabalho filho Express que lida com todos os estados relacionados a pagamento (ProcessPayment, ProcessStandardPayment, ValidatePaymentPart) como uma única unidade. Um fluxo de trabalho express é mais adequado para seções como processamento de pagamentos, pois suas execuções são concluídas em 5 minutos. Portanto, isso também reduziria o custo geral do fluxo de trabalho. Da mesma forma, a lógica de cálculo de envio envolvendo CalculateExpressShipping e CalculateStandardShipping poderia ser consolidada em outro fluxo de trabalho filho Express, levando a custos reduzidos e atualizações mais fáceis da lógica de envio.
Separação de Domínio
A separação de domínio envolve decompor fluxos de trabalho com base em capacidades de negócios distintas ou áreas funcionais. Cada fluxo de trabalho específico de domínio se torna responsável por uma função de negócios completa, operando independentemente enquanto se comunica através de interfaces bem definidas. Esta abordagem se alinha estreitamente com princípios de arquitetura de microsserviços e design orientado a domínio. A arquitetura mostra limites claros entre diferentes domínios de negócios que podem ser separados em fluxos de trabalho independentes. Três domínios primários emergem:
- Domínio de Pagamento: Englobando ValidateOrder, ProcessPayment, ValidatePaymentPart e manipuladores de erro relacionados
- Domínio de Inventário: Incluindo CheckInventory, UpdateInventory e estados associados
- Domínio de Envio: Contendo ProcessShipping, cálculos de envio e atualizações de status de envio
Cada domínio se tornaria seu próprio fluxo de trabalho, com contratos claros de entrada/saída. Esta separação permitiria que equipes especializadas mantivessem e implantassem atualizações em seus fluxos de trabalho de domínio independentemente, garantindo implementação de políticas de retry específicas de domínio, tratamento de erros e regras de negócios sem afetar outros domínios. Por exemplo, a equipe de pagamento poderia aprimorar a lógica de processamento de pagamentos sem impactar operações de envio ou inventário.
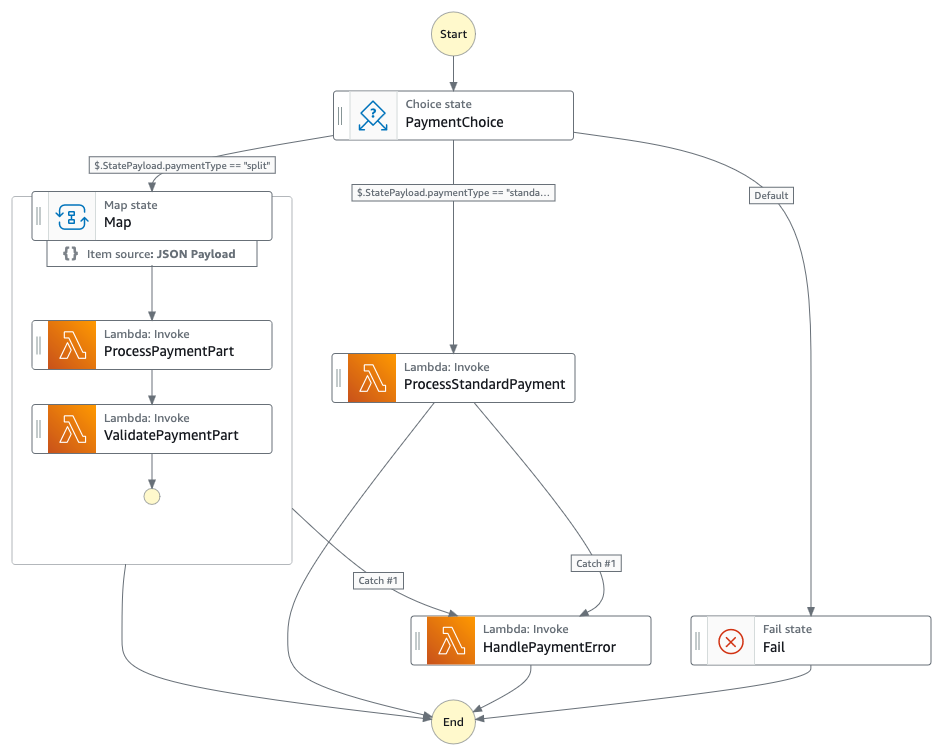
Figura 3 : Máquina de estado filho que lida com fluxo de trabalho de pagamento
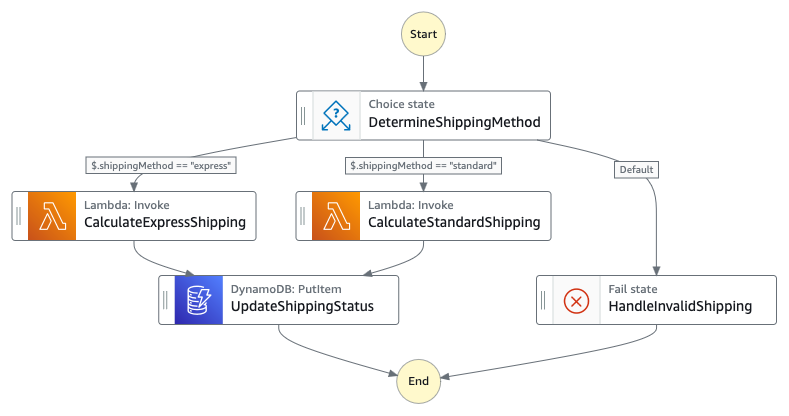
Figura 4 : Máquina de estado filho que lida com fluxo de trabalho de envio
Utilitários Compartilhados
Fluxos de trabalho de utilitários compartilhados servem como componentes reutilizáveis para operações comuns que aparecem em múltiplos processos de negócios. Esses fluxos de trabalho encapsulam funcionalidade padrão como tratamento de notificações, validação de dados, registro de logs ou criação de trilha de auditoria. Ao centralizar essas operações comuns, organizações podem garantir consistência e reduzir duplicação em suas aplicações Step Functions.
A arquitetura atual repete vários padrões comuns que poderiam ser extraídos em fluxos de trabalho de utilitários compartilhados. Mais notavelmente, a lógica de tratamento de notificações (SendEmail, SendSMSNotification, SendPushNotification) aparece como um cluster de estados no final do fluxo de trabalho. Isso poderia ser consolidado em um único fluxo de trabalho utilitário “NotificationManager” que lida com todos os tipos de notificações. Esses fluxos de trabalho utilitários poderiam então ser chamados de qualquer outro fluxo de trabalho no sistema, garantindo comportamento consistente e reduzindo duplicação de código.
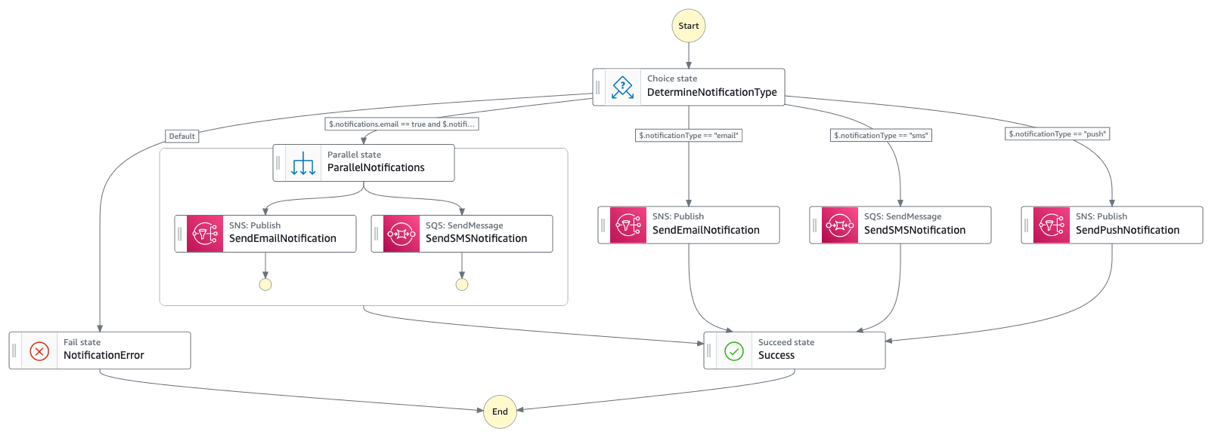
Figura 5 : Fluxo de trabalho de notificação reutilizável
Fluxos de Trabalho de Erro
Fluxos de trabalho de erro representam uma forma especializada de decomposição focada em centralizar lógica de tratamento de erros e recuperação. Em vez de incorporar tratamento de erros complexo em cada fluxo de trabalho de negócios, organizações podem criar fluxos de trabalho dedicados que gerenciam diferentes tipos de falhas, retentativas e ações de compensação. Esta abordagem fornece uma maneira consistente e de fácil manutenção para lidar com erros em toda a aplicação.
Cada uma dessas estratégias de decomposição pode ser usada individualmente ou em combinação, dependendo das necessidades específicas de sua aplicação. Por exemplo, a utilização do padrão de Separação de Domínio resultou em fluxos de trabalho de erro simplificados. A chave é escolher a combinação apropriada que fornece o equilíbrio certo de manutenibilidade, escalabilidade e eficiência operacional para seu caso de uso. No entanto, implementar todas as quatro estratégias em uma abordagem faseada forneceria a solução mais abrangente para manutenibilidade e escalabilidade de longo prazo.
Resultados:
A comparação entre abordagens monolíticas e desacopladas revela diferenças notáveis em desempenho e métricas operacionais. Para emular ambientes de teste similares entre máquinas de estado monolíticas e decompostas, testamos elas na região AWS us-east-1. Fizemos uso dos fluxos de trabalho mencionados anteriormente, tanto monolíticos quanto decompostos, para alcançar um objetivo final similar. A comparação de preços é baseada em um fluxo de trabalho monolítico processando 11 transições de estado por fluxo de trabalho em 30.000 solicitações mensais. Para a abordagem decomposta, os cálculos assumem fluxos de trabalho filho Express configurados com 64MB de memória e 100ms de duração de execução, enquanto o fluxo de trabalho pai lida com 8 transições de estado por fluxo de trabalho para o mesmo volume de 30.000 solicitações mensais. Estados de tarefa do AWS Lambda em ambas as abordagens são concluídos dentro de 2 segundos de tempo de execução.
Quando desacoplados, os fluxos de trabalho podem ser redesenhados para usar mecanismos Express ou Standard dependendo de seu tempo de execução e requisitos de padrão de integração. Neste caso de uso, identificamos múltiplos fluxos de trabalho como PaymentProcessing, CalculateExpressShipping que são reformulados para usar fluxos de trabalho Express conforme seu requisito. Embora a abordagem monolítica mostre uma duração de execução ligeiramente mais rápida de 11,5 segundos comparada a 13 segundos na abordagem decomposta, o preço mensal favorece significativamente a arquitetura desacoplada em $6,37 USD versus $11,90 USD para a abordagem monolítica. A abordagem desacoplada demonstra capacidades superiores de depuração com melhor isolamento de erros e depuração específica de domínio, contrastando com os desafios complexos de depuração da abordagem monolítica devido a payloads pesados e rastreamento de falhas em estados intermediários. Além disso, a arquitetura desacoplada se beneficia de tamanhos de payload menores através de tratamento distribuído de dados, enquanto o fluxo de trabalho monolítico carrega payloads maiores em suas 18 transições de estado.
| Abordagem Monolítica | Abordagem Desacoplada | |
| Duração de Execução | 11,5 segundos para execução completa do fluxo de trabalho | 13 segundos com processamento distribuído entre fluxos de trabalho pai-filho |
| Preço Mensal | $11,90 USD (476.000 transições de estado faturáveis) | $6,37 USD (Custo combinado de fluxo de trabalho pai Standard e fluxos de trabalho filho Express) |
| Esforço de Depuração | Alto – Depuração complexa devido a payloads pesados e dificuldade em rastrear falhas em estados intermediários. Não pode usar efetivamente ResultSelector quando o estado de notificação final precisa de todos os detalhes. | Menor – Mais fácil de depurar com domínios isolados e payloads menores. Melhor isolamento de erros e depuração específica de domínio. |
| Tamanho de Payload | Tamanho de payload maior durante toda a execução do fluxo de trabalho, pois todos os dados precisam ser transportados através de 18 transições de estado | Tamanho de payload menor devido à separação de domínio e tratamento distribuído de dados entre fluxos de trabalho pai-filho |
Conclusão
A necessidade de decompor fluxos de trabalho do Step Functions se torna evidente quando você enfrenta desafios com fluxos de trabalho monolíticos como explosão de estados, complexidades de gerenciamento de versões e limitações de recursos. Esses desafios resultam em eficiência operacional reduzida, complexidade de depuração aumentada e maior sobrecarga de manutenção, como demonstrado pelos resultados de comparação mostrando diferenças em duração de execução, preços, esforço de depuração e gerenciamento de payload. Organizações devem avaliar decomposição de fluxos de trabalho quando observam fluxos de trabalho excedendo 15-20 estados, envolvimento de múltiplas equipes na manutenção de fluxos de trabalho, atualizações independentes frequentes em diferentes domínios de negócios, requisitos complexos de tratamento de erros e necessidade de componentes reutilizáveis entre fluxos de trabalho. A implementação de estratégias de decomposição através do padrão pai-filho para organização hierárquica de fluxos de trabalho, separação de domínio para isolamento de capacidade de negócios, utilitários compartilhados para operações comuns e fluxos de trabalho de erro dedicados para tratamento centralizado de erros mostrou benefícios tangíveis em termos de custos reduzidos, melhor isolamento de erros e gerenciamento de payload mais eficiente.
Ao implementar estratégias de decomposição, organizações devem ter cuidado para evitar decomposição excessiva de fluxos de trabalho, manter acoplamento forte entre fluxos de trabalho e ignorar princípios fundamentais de design de acoplamento fraco e responsabilidade única. Esta abordagem estratégica para decomposição de fluxos de trabalho, em última análise, leva a aplicações Step Functions mais de fácil manutenção, escaláveis e econômicas que melhor atendem às necessidades de negócios enquanto reduzem a sobrecarga operacional. A transformação de fluxos de trabalho monolíticos para decompostos representa uma melhoria arquitetural significativa que permite que organizações gerenciem melhor processos de negócios complexos mantendo eficiência operacional e confiabilidade do sistema.
Este conteúdo foi traduzido do post original do blog, que pode ser encontrado aqui.
Autores
 |
Sahithi Ginjupalli, Cloud Support Eng. II |
 |
Harold Sun, Cloud Support Eng. II |
Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Revisor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |