O blog da AWS
Orquestrando processamento de Big Data com AWS Step Functions Distributed Map
Por Biswanath Mukherjee, Sr. Solutions Architect e Rahul Sringeri, Technical Account Manager.
Desenvolvedores buscam processar e enriquecer conjuntos de dados semi-estruturados de Big Data com fluxos de trabalho baseados em rede de orquestrados de forma durável. Por exemplo, durante a temporada de resultados trimestrais, organizações financeiras executam milhares de simulações de mercado simultaneamente para fornecer insights oportunos para planejamento de cenários ou gerenciamento de riscos—essas cargas de trabalho requerem coordenação entre conjuntos de dados brutos e servidores on-premise para fornecer as informações mais recentes do mercado.
O AWS Step Functions é um serviço de fluxo de trabalho (workflow) visual capaz de orquestrar mais de 14.000 ações de API de mais de 220 serviços AWS para construir aplicações distribuídas. Agora, o Step Functions Distributed Map simplifica a transformação de conjuntos de dados de Big Data, processando arquivos de manifesto de dados do Amazon Athena e Parquet diretamente. Usando seu recurso Distributed Map, você pode processar conjuntos de dados em grande escala executando iterações concorrentes através de entradas de dados em paralelo. No modo Distributed, o estado Map processa os itens no conjunto de dados em iterações chamadas execuções de fluxo de trabalho filho. Você pode especificar o número de execuções de fluxo de trabalho filho que podem ser executadas em paralelo. Cada execução de fluxo de trabalho filho tem seu próprio histórico de execução separado do fluxo de trabalho pai. Por padrão, Step Functions executa 10.000 execuções de fluxo de trabalho filho em paralelo.
Distributed Map pode processar arquivos de manifesto de dados do AWS Athena e Parquet diretamente, eliminando a necessidade de pré-processamento personalizado. Você também agora tem visibilidade do uso do seu Distributed Map com novas métricas do Amazon CloudWatch: Approximate Open Map Runs Count, Open Map Run Limit e Approximate Map Runs Backlog Size.
Nesta publicação, você aprenderá como usar AWS Step Functions Distributed Map para processar arquivos de manifesto de dados do Athena e Parquet através de uma demonstração passo a passo.
Esta publicação faz parte de uma série de posts sobre AWS Step Functions Distributed Map:
|
Caso de uso: Processamento de dados de sensores IoT
Você construirá uma aplicação que demonstra o processamento de dados de sensores IoT em formato Parquet usando Step Functions Distributed Map. Esses arquivos de dados Parquet e um arquivo de manifesto contendo a lista dos arquivos de dados são exportados do Athena. Os dados incluem temperatura, umidade e nível de bateria de diferentes dispositivos. A tabela a seguir mostra uma amostra de dados de sensores:
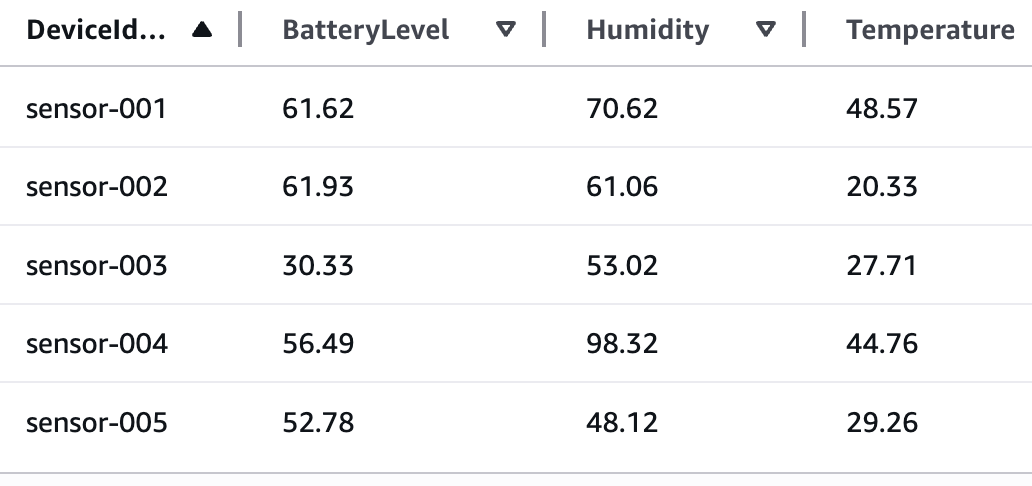
Exemplo de dados de sensores IoT
Seu objetivo é usar o arquivo de manifesto de dados do Athena, obter a lista de arquivos Parquet e iterar sobre os dados nos arquivos para detectar anomalias e também transmitir os dados processados através do Amazon Kinesis Data Firehose para um bucket do Amazon S3 para análises adicionais usando consultas do Athena. A seguir está o critério para detectar anomalias:
- Condições de bateria baixa: menos de 20%
- Anomalias de umidade: mais de 95% ou menos de 5%
- Picos de temperatura: mais de 35°C ou menos de -10°C
O diagrama a seguir representa a máquina de estados do AWS Step Functions:
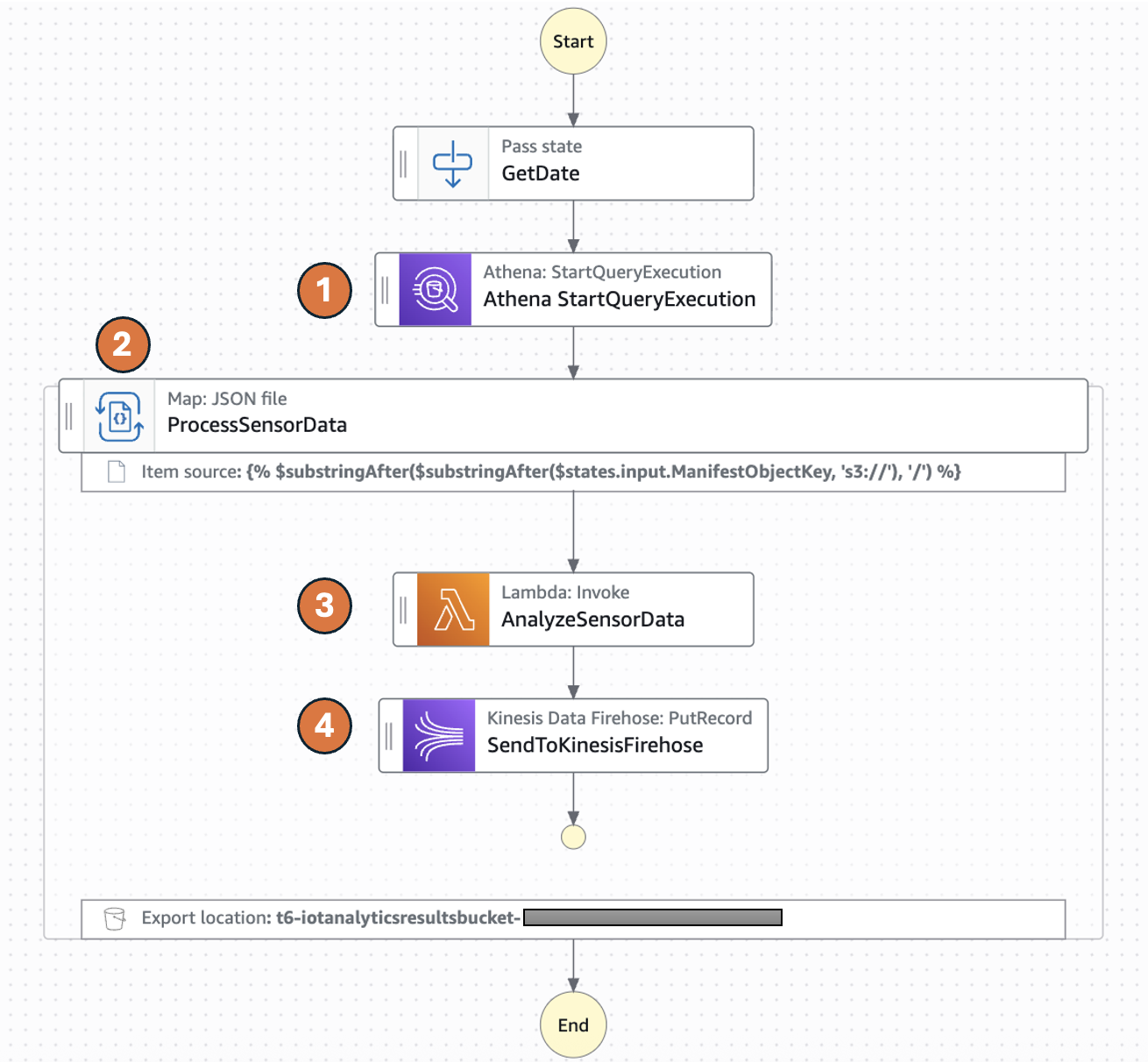
Fluxo de trabalho de processamento de arquivos Parquet
- O Distributed Map executa uma consulta do Athena que gera arquivos de dados Parquet e um arquivo de manifesto do Athena (csv). O arquivo de manifesto contém a lista de arquivos de dados Parquet.
- Distributed Map processa esses arquivos de dados Parquet em paralelo usando execuções de fluxo de trabalho filho. Você pode controlar o número de execuções de fluxo de trabalho filho que podem ser executadas em paralelo usando o parâmetro MaxConcurrency. Consulte cotas de serviço do Step Functions para saber mais sobre limites de concorrência.
- Cada execução de fluxo de trabalho filho invoca uma função AWS Lambda para processar o respectivo arquivo Parquet. A função Lambda processa leituras individuais de sensores e detecta anomalias de acordo com a lógica anterior e retorna uma resposta de resumo de dados de sensores processados.
- O fluxo de trabalho filho envia o registro de resposta de resumo para o stream do Amazon Kinesis Firehose que armazena os resultados em um bucket S3 de resultados especificado.
O seguinte estado Athena Start QueryExecution executa uma consulta UNLOAD para gerar arquivos de dados em formato Parquet e um arquivo de manifesto em CSV. A saída será armazenada no bucket S3 especificado na consulta UNLOAD e o arquivo de manifesto será armazenado no bucket S3 configurado para o workgroup do Athena.
O seguinte ItemReader está configurado para usar um tipo de manifesto “ATHENA_DATA” com entrada de dados “PARQUET”.
Opções adicionais de InputType suportadas são CSV e JSONL. Todos os objetos referenciados em um único arquivo de manifesto devem ter o mesmo formato InputType. Você especifica a localização do bucket do Amazon S3 do arquivo CSV de manifesto do Athena em Arguments.
O objeto de contexto contém informações em uma estrutura JSON sobre sua máquina de estados e execução. Seus fluxos de trabalho podem referenciar o objeto de contexto em uma expressão JSONata com $states.context.
Dentro de um Map state, o objeto Context inclui os seguintes dados:
Para cada iteração do Map state, Index contém o número de índice do item do array que está sendo processado atualmente, Key está disponível apenas ao iterar sobre objetos JSON, Value contém o item do array sendo processado, e Source contém um dos seguintes:
- Para entrada de estado, o valor será: STATE_DATA
- Para Amazon S3 LIST_OBJECTS_V2 com Transformation=NONE, o valor mostrará o URI S3 para o bucket. Por exemplo: S3://amzn-s3-demo-bucket.
- Para todos os outros tipos de entrada, o valor será o URI do Amazon S3. Por exemplo: S3://amzn-s3-demo-bucket/object-key.
Usando este campo Source recém-introduzido no objeto de contexto, você pode conectar as execuções filho com o objeto de origem.
Pré-requisitos
- Acesso a uma conta AWS através do AWS Management Console e da AWS Command Line Interface (AWS CLI). O usuário do AWS Identity and Access Management (IAM) que você usa deve ter permissões para fazer as chamadas de serviço AWS necessárias e gerenciar recursos AWS mencionados neste post. Ao fornecer permissões ao usuário IAM, siga o princípio do menor privilégio.
- AWS CLI instalada e configurada. Se você estiver usando credenciais de longo prazo como chaves de acesso, siga gerenciar chaves de acesso para usuários IAM e proteger chaves de acesso para melhores práticas.
- Git Instalado
- AWS Serverless Application Model (AWS SAM) instalado
- Python 3.13+ instalado
Configurar a máquina de estados e dados de exemplo
Execute as seguintes etapas para implantar a máquina de estados do Step Functions.
- Clone o repositório GitHub em uma nova pasta e navegue até a pasta raiz do projeto.
- Execute o seguinte comando para instalar as dependências Python necessárias para a função Lambda.
- Construa a aplicação.
- Implante a aplicação
- Insira os seguintes detalhes:
- Stack name: O nome da pilha CloudFormation (por exemplo, sfn-parquet-file-processor)
- AWS Region: Uma região AWS suportada (por exemplo, us-east-1)
- Mantenha o restante dos componentes com valores padrão.Anote as saídas do AWS SAM deploy. Você as usará nas etapas subsequentes.
- Execute o seguinte comando para gerar dados de exemplo em formato csv e carregá-los em um bucket S3. Substitua
<IoTDataBucketName>pelo valor da saída dosam deploy.
Criar o banco de dados e tabelas do Athena
Antes de poder executar consultas, você deve configurar um banco de dados e tabela do Athena para seus dados.
- Do console do Amazon Athena, navegue até workgoups, selecione o workgroup chamado “primary”. Selecione Edit em Actions. Na seção de configuração de resultados de consulta, selecione as opções da seguinte forma:
- Management of query results – selecione customer managed
- Location of query results – insira s3://<IoTDataBucketName>. Substitua
<IoTDataBucketName>pelo valor da saída dosam deploy. - Escolha Save para salvar as alterações no workgroup
- Selecione a aba Query editor e execute os seguintes comandos para criar banco de dados e tabelas
- Crie uma tabela do Athena no banco de dados iotsensordata que referencia o bucket S3 contendo os dados brutos do sensor. Neste caso será
<IoTDataBucketName>. Substitua<IoTDataBucketName>pelo valor da saída dosam deploy. - Crie uma tabela do Athena no banco de dados iotsensordata que referencia o bucket S3 contendo os resultados de análise transmitidos do Kinesis Data Firehose. Substitua
<IoTAnalyticsResultsBucket>pelo valor da saída dosam deploy.E substitua<year>pelo ano atual (por exemplo, 2025).
Iniciar sua máquina de estados
Agora que você tem os dados prontos e o Athena configurado para consultas, inicie sua máquina de estados para recuperar e processar os dados.
- Execute o seguinte comando para iniciar a execução do Step Functions. Substitua o
<StateMachineArn>e<IoTDataBucketName>pelo valor da saída do sam deploy.A máquina de estados do Step Functions tem o estado Athena
StartQueryExecutionque tem uma consultaUNLOADque gera os arquivos de dados do sensor em formato parquet e um arquivo de manifesto em formato CSV. O manifesto terá 5 linhas referenciando os 5 arquivos parquet. A máquina de estados processará esses 5 arquivos parquet em uma execução de map. - Execute o seguinte comando para obter os detalhes da execução. Substitua o
executionArndo comando anterior. - Depois de ver o status
SUCCEEDED, execute o seguinte comando do editor de consultas do Athena para verificar a saída processada do Kinesis Data Firehose que foi transmitida para o bucket S3 referenciado pela tabela do Athena criada na etapa 4 da seção anterior.
Se algum dos dados do sensor exceder os limites, o atributo healthstatus será definido como “anomalies_detected”. O fluxo de trabalho produziu uma tabela de resumo de metadados que você agora pode consultar para relatórios.
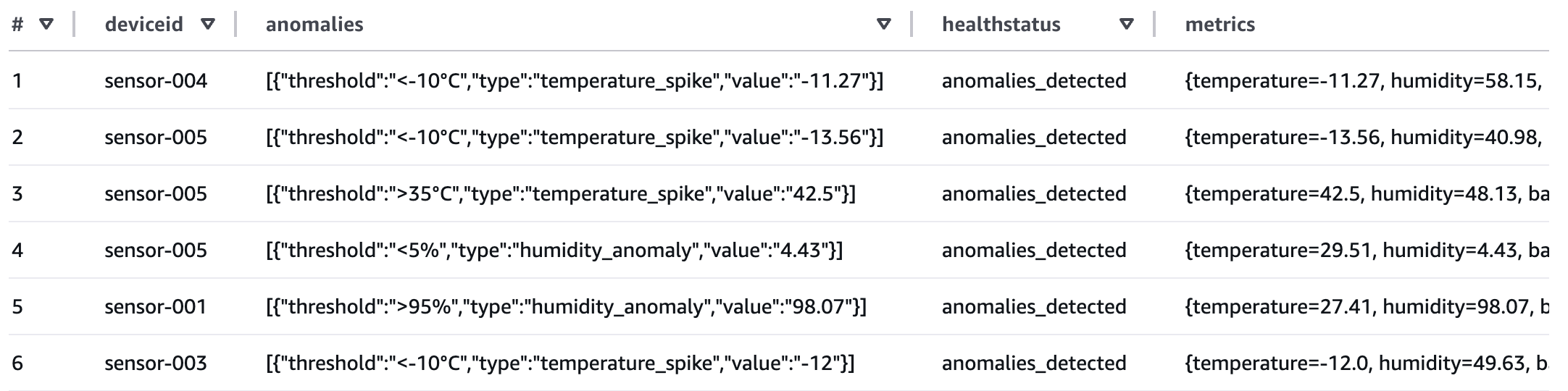
Revisar o desempenho do fluxo de trabalho
Usando as seguintes métricas de observabilidade, você pode revisar o comportamento de desempenho chave do seu fluxo de trabalho de processamento de dados.
O namespace AWS/States inclui as seguintes novas métricas para todas as execuções de Map do Step Functions.
OpenMapRunLimit: Este é o número máximo de execuções de Map abertas permitidas na conta AWS. O valor padrão é 1.000 execuções e é um limite rígido. Para mais informações, consulte Cotas relacionadas a contas.ApproximateOpenMapRunCount: Esta métrica rastreia o número aproximado de execuções de Map atualmente em andamento dentro de uma conta. Configurar um alarme nesta métrica usando a estatística Maximum com um limite de 900 ou superior pode ajudá-lo a tomar ações proativas antes de atingir oOpenMapRunLimitde 1.000. Esta métrica permite que equipes operacionais implementem medidas preventivas, como escalonar novas execuções ou otimizar a concorrência do fluxo de trabalho, para manter a estabilidade do sistema e evitar acúmulo de backlog.ApproximateMapRunBacklogSize: Esta métrica aparece quando oApproximateOpenMapRunCountatingiu 1.000 e há execuções de Map em backlog aguardando para serem executadas. Execuções de Map em backlog aguardam no evento MapRunStarted até que o número total de execuções de Map abertas seja menor que a cota.
A imagem a seguir mostra um exemplo dessas novas métricas. Use a estatística máxima para visualizar essas métricas. As métricas de ApproximateMapRunBacklogSize aparecem depois que as contas começam a ser limitadas no limite OpenMapRunLimit. O OpenMapRun (linha laranja) é o limite rígido da conta de 1.000 mostrado como uma linha estática. O ApproximateOpenMapRunCount (linha violeta) é o número atual de execuções OpenMap ativas. O ApproximateMapRunBacklogSize (linha verde) indica as execuções de map aguardando em backlog para serem processadas. Quando o ApproximateOpenMapRunCount está abaixo de 1000 (limite OpenMapRun) não há execuções de map em backlog. No entanto, quando a contagem atinge o limite OpenMapRun, o backlog de execuções de map começa a se acumular. Depois que as execuções ativas são concluídas, o backlog começará a drenar e novas execuções começarão a execução.
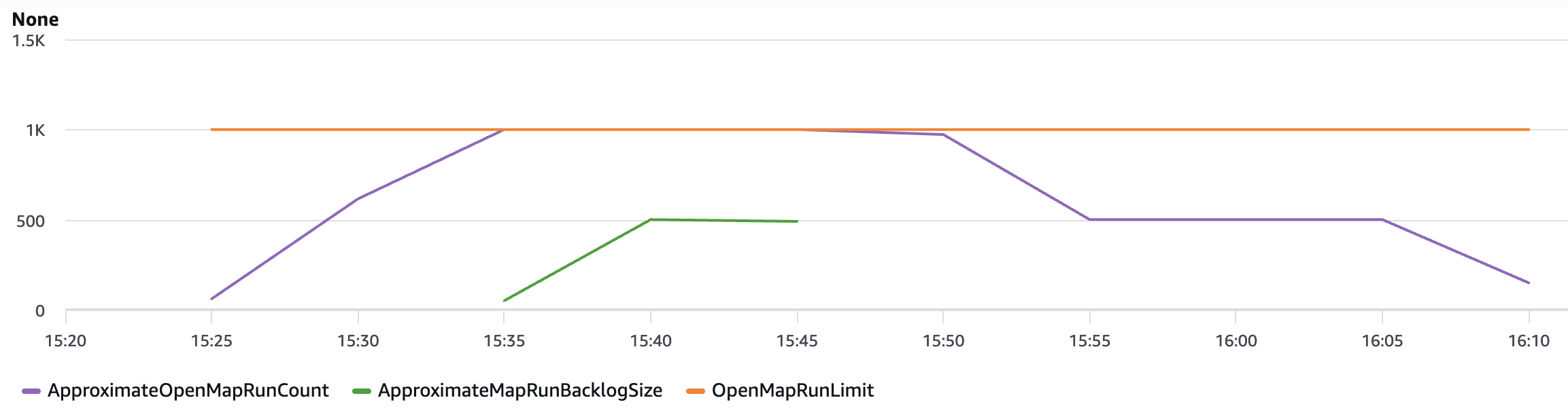
Métricas em gráfico do Amazon CloudWatch
Limpeza
Para evitar custos, remova todos os recursos criados para este post quando terminar. Do editor de consultas do Athena, execute os seguintes comandos:
Execute os seguintes comandos da AWS CLI após substituir a variável <placeholder> para excluir os recursos que você implantou para a solução deste post:
Conclusão
Com esta atualização, Distributed Map agora suporta entradas de dados adicionais, para que você possa orquestrar fluxos de trabalho de análise e ETL em grande escala. Você agora pode processar arquivos de manifesto de dados do Amazon Athena e Parquet diretamente, eliminando a necessidade de pré-processamento personalizado. Você também agora tem visibilidade do uso do seu Distributed Map com as seguintes métricas: Approximate Open Map Runs Count, Open Map Run Limit e Approximate Map Runs Backlog Size.
Novas fontes de entrada para Distributed Map estão disponíveis em todas as regiões comerciais da AWS onde AWS Step Functions está disponível. Para uma lista completa de regiões AWS onde Step Functions está disponível, consulte a Tabela de Regiões AWS. A observabilidade aprimorada do uso do seu Distributed Map com novas métricas está disponível em todas as regiões AWS. Para começar, você pode usar o modo Distributed Map hoje no console do AWS Step Functions. Para saber mais, visite o guia do desenvolvedor do Step Functions.
Para mais recursos de aprendizado serverless, visite Serverless Land.
Este conteúdo foi traduzido do post original do blog, que pode ser encontrado aqui.
Autores
 |
Biswanath Mukherjee, Sr. Solutions Architect |
 |
Rahul Sringeri, Technical Account Manager |
Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |