O blog da AWS
Processando objetos do Amazon S3 em escala com o AWS Step Functions Distributed Map S3 prefix
Por Biswanath Mukherjee, Sr. Solutions Architect e Rahul Sringeri, Technical Account Manager.
Se você está construindo aplicações empresariais de grande escala, provavelmente já enfrentou as complexidades de processar grandes volumes de arquivos de dados. Seja analisando logs de aplicações, processando arquivos de dados de clientes ou transformando conjuntos de dados de machine learning, você conhece a complexidade envolvida na orquestração de workflows. Você provavelmente já escreveu workflows aninhados e código personalizado adicional para processar objetos de buckets do Amazon Simple Storage Service (Amazon S3).
Com o AWS Step Functions Distributed Map, você pode processar conjuntos de dados de grande escala executando iterações simultâneas de etapas de workflow em entradas de dados em paralelo, alcançando escala massiva com gerenciamento simplificado.
Com o novo recurso de iteração baseada em prefixo e o parâmetro de transformação LOAD_AND_FLATTEN para Distributed Map, seus workflows agora podem iterar sobre objetos S3 sob um prefixo especificado usando S3ListObjectsV2 para processar seus conteúdos em um único estado Map, evitando workflows aninhados e reduzindo a complexidade operacional.
Nesta publicação, você aprenderá como processar objetos do Amazon S3 em escala com os novos recursos de prefixo S3 e transformação do AWS Step Functions Distributed Map.
Caso de uso: Processamento e resumo de logs de aplicação
Você construirá uma máquina de estados do Step Functions que demonstra o processamento de todos os arquivos de log do prefixo S3 fornecido usando um Distributed Map. Você analisará todos os arquivos de log para construir um resumo de mensagens INFO, WARNING e ERROR no arquivo de log em base horária. O diagrama a seguir apresenta a máquina de estados do AWS Step Functions:
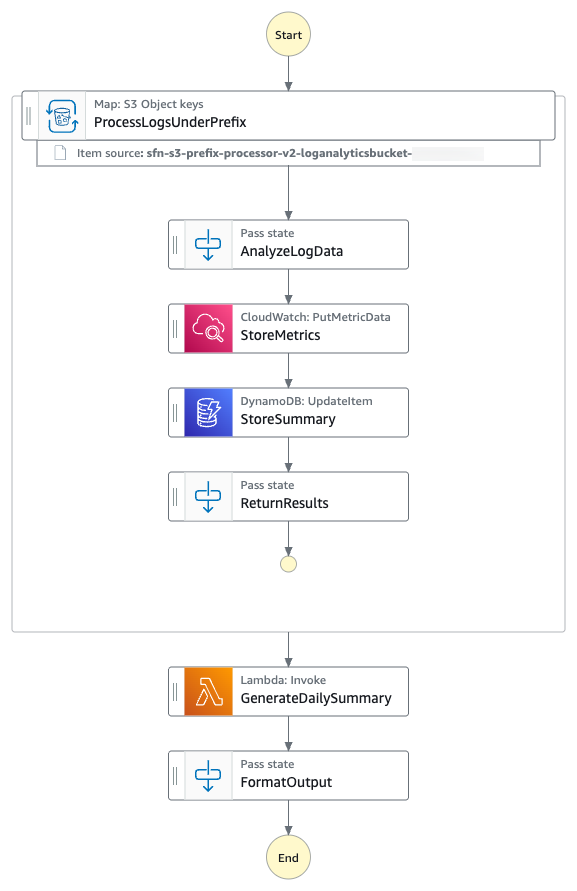
Workflow de processamento de arquivos de log
- A máquina de estados itera sobre todos os arquivos de log do prefixo S3 especificado usando S3
ListObjectsV2e os processa usando AWS Step Functions Distributed Map. - Para cada entrada de arquivo de log, a máquina de estados coloca a métrica horária
ErrorCountno Amazon CloudWatch. - A máquina de estados então armazena a contagem de métricas por hora em uma tabela do Amazon DynamoDB.
- A máquina de estados então invoca uma função AWS Lambda para realizar a agregação das métricas.
O seguinte é um exemplo dos parâmetros em um ItemReader configurado para iterar sobre o conteúdo de objetos S3 usando S3 ListObjectsV2.
Com a opção LOAD_AND_FLATTEN, sua máquina de estados fará o seguinte:
- Ler o conteúdo real de cada objeto listado pela chamada
ListObjectsV2do Amazon S3. - Analisar o conteúdo com base no
InputType(CSV, JSON, JSONL, Parquet). - Criar itens a partir do conteúdo dos arquivos (linhas/registros) em vez de metadados.
Recomendamos incluir uma barra final no seu prefixo. Por exemplo, se você selecionar dados com um prefixo de folder1, sua máquina de estados processará tanto folder1/myData.csv quanto folder10/myData.csv. Usar folder1/ processará estritamente apenas uma pasta. Todos os objetos listados por prefix precisam estar no mesmo formato de dados. Por exemplo, se você estiver selecionando InputType como JSONL, seu prefixo S3 deve conter apenas arquivos JSONL e não uma mistura de outros tipos.
O objeto de contexto é uma estrutura JSON interna que está disponível durante uma execução. O objeto de contexto contém informações sobre sua máquina de estados e execução. Seus workflows podem referenciar o objeto de contexto em uma expressão JSONata com $states.context.
Dentro de um estado Map, o objeto de contexto inclui os seguintes dados:
"Map": {
"Item": {
"Index" : Number,
"Key" : "String", // Only valid for JSON objects
"Value" : "String",
"Source": "String"
}
}Para cada iteração do Map, o Index contém o número de índice para o item do array que está sendo processado atualmente.
Uma Key está disponível apenas ao iterar sobre objetos JSON. Value contém o item do array sendo processado. Por exemplo, para o seguinte objeto JSON de entrada, Names será atribuído a Key e {“Bob”, “Cat”} será atribuído a Value.
Source contém um dos seguintes:
- Para entrada de estado:
STATE_DATA - Para Amazon S3
LIST_OBJECTS_V2comTransformation=NONE, o valor mostrará o URI S3 para o bucket. Por exemplo:S3://amzn-s3-demo-bucket1 - Para todos os outros tipos de entrada, o valor será o URI do Amazon S3. Por exemplo:
S3://amzn-s3-demo-bucket1/object-key
Usando LOAD_AND_FLATTEN e o campo Source, você pode conectar execuções filhas às suas origens.
Pré-requisitos
- Acesso a uma conta AWS através do AWS Management Console e da AWS Command Line Interface (AWS CLI). O usuário do AWS Identity and Access Management (IAM) que você usa deve ter permissões para fazer as chamadas de serviço AWS necessárias e gerenciar recursos AWS mencionados neste post. Ao fornecer permissões ao usuário IAM, siga o princípio do menor privilégio.
- AWS CLI instalada e configurada. Se você estiver usando credenciais de longo prazo como chaves de acesso, siga gerenciar chaves de acesso para usuários IAM e proteger chaves de acesso para melhores práticas.
- Git Instalado.
- AWS Serverless Application Model (AWS SAM) instalado.
- Python 3.13 ou posterior instalado.
Configurar e executar o workflow
Execute as seguintes etapas para implantar e testar a máquina de estados do Step Functions.
- Clone o repositório GitHub em uma nova pasta e navegue até a pasta do projeto.
- Execute os seguintes comandos para implantar a aplicação.
- Insira os seguintes detalhes:
Stack name: Nome da stack para CloudFormation (por exemplo, stepfunctions-s3-prefix-processor)AWS Region: Uma região AWS suportada (por exemplo, us-east-1)- Aceite todos os outros valores padrão.
As saídas do AWS SAM deploy serão usadas nas etapas subsequentes.
- Execute o seguinte comando para gerar arquivos de log de exemplo.
- Execute o seguinte comando para fazer upload dos arquivos de log para o bucket S3 com o prefixo
/logs/daily. Substituaamzn-s3-demo-bucket1pelo valor da saída dosam deploy. - Execute o seguinte comando para executar o workflow do Step Functions. Substitua o
StateMachineArnpelo valor da saída dosam deploy.
A máquina de estados do Step Functions itera sobre todos os arquivos de log com o prefixo S3 /logs/daily e os processa em paralelo. O workflow atualiza as métricas no CloudWatch, armazena a contagem de métricas horárias no DynamoDB e então invoca uma função AWS Lambda para agregar as métricas.
Monitorar e verificar resultados
Execute as seguintes etapas para monitorar e verificar os resultados do teste.
- Execute o seguinte comando para obter os detalhes da execução. Substitua
executionArnpelo ARN da sua máquina de estados. - Quando o status mostrar
SUCCEEDED, execute os seguintes comandos para verificar a saída processada da tabela DynamoDBLogAnalyticsSummaryTableName. Substitua o valorLogAnalyticsSummaryTableNamepelo valor da saída dosam deploy. - Verifique se as estatísticas horárias de logs
ERROR,WARNeINFOestão salvas na tabela DynamoDB. O seguinte é uma saída de exemplo: - Execute o seguinte comando para verificar a saída da execução da máquina de estados do Step Functions.
O seguinte é uma saída de exemplo:
A saída da máquina de estados do Step Functions mostra os insights de resumo diário dos arquivos de log criados pela função Lambda.
Limpeza
Para evitar custos, remova todos os recursos criados para este post quando terminar. Execute o seguinte comando após substituir amzn-s3-demo-bucket1 pelo nome do seu próprio bucket para excluir os recursos que você implantou para a solução deste post:
Conclusão
Nesta publicação, você aprendeu como o Distributed Map do AWS Step Functions pode usar iteração baseada em prefixo com transformação LOAD_AND_FLATTEN para ler e processar múltiplos objetos de dados de buckets do Amazon S3 diretamente. Você não precisa mais de uma etapa para processar metadados de objetos e outra para carregar os objetos de dados. Carregar e achatar em uma etapa é particularmente valioso para pipelines de processamento de dados, operações em lote e arquiteturas orientadas a eventos onde objetos são continuamente adicionados no S3. Ao eliminar a necessidade de manter manifestos de objetos, você pode construir workflows de processamento de dados mais resilientes e dinâmicos com menos código e menos partes móveis.
Novas fontes de entrada para Distributed Map estão disponíveis em todas as regiões comerciais da AWS onde o AWS Step Functions está disponível. Para começar, você pode usar o modo Distributed Map hoje no console do AWS Step Functions. Para saber mais, visite o guia do desenvolvedor do Step Functions.
Para mais recursos de aprendizado serverless, visite Serverless Land.
Este conteúdo foi traduzido do post original do blog, que pode ser encontrado aqui.
Autores
 |
Biswanath Mukherjee, Sr. Solutions Architect |
 |
Rahul Sringeri, Technical Account Manager |
Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Revisor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |