- AWS Solutions Library
- Guidance for SAP Data Integration and Management on AWS
Guidance for SAP Data Integration and Management on AWS
Overview
How it works
Overview of Architecture Patterns
This reference architecture shows various options for ingesting data from SAP systems to AWS. These architecture patterns complement SAP supported mechanisms using AWS Services, SAP Products, and AWS Partner Solutions. For detailed architecture patterns, open the other tabs.
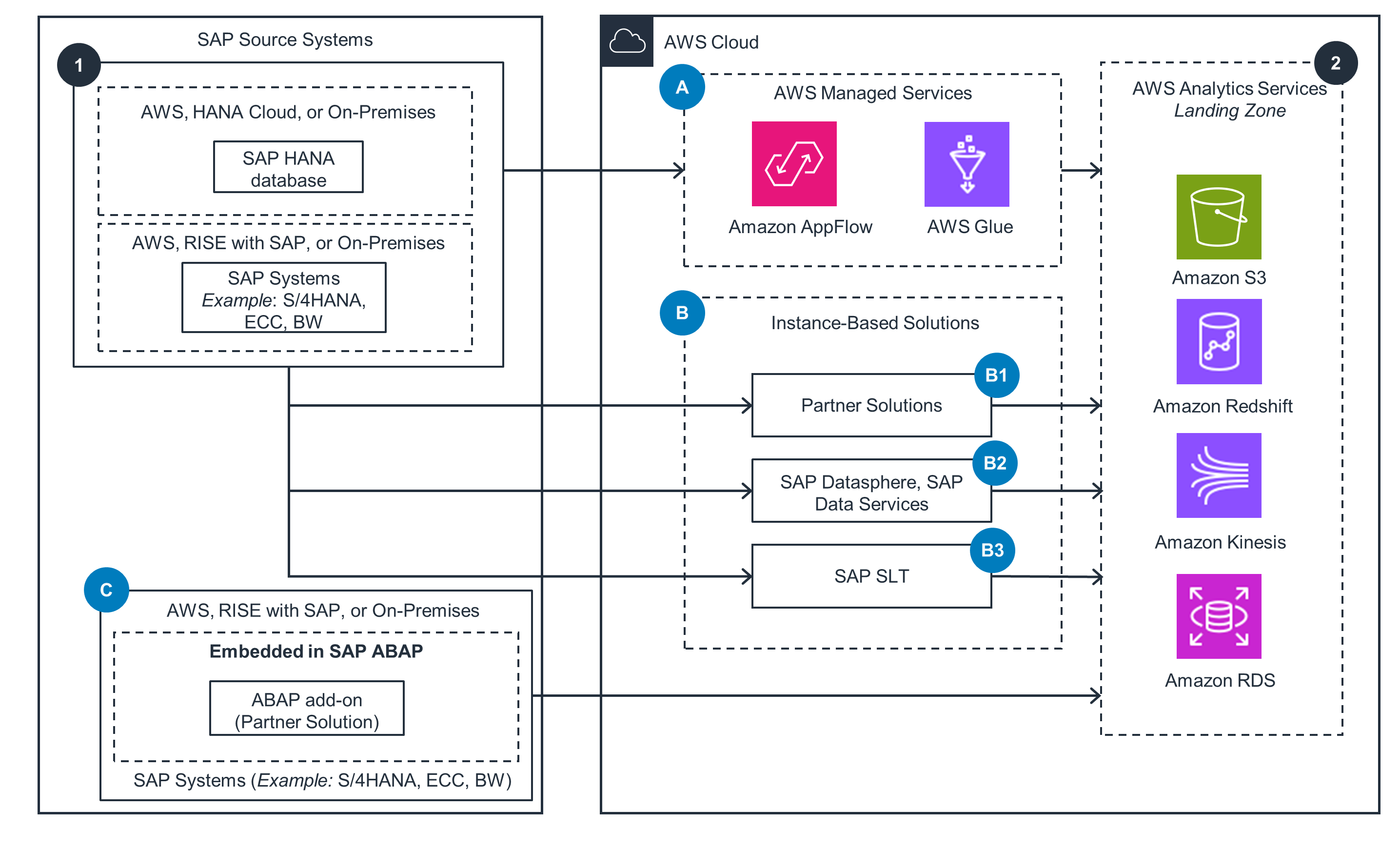
AWS Managed Services
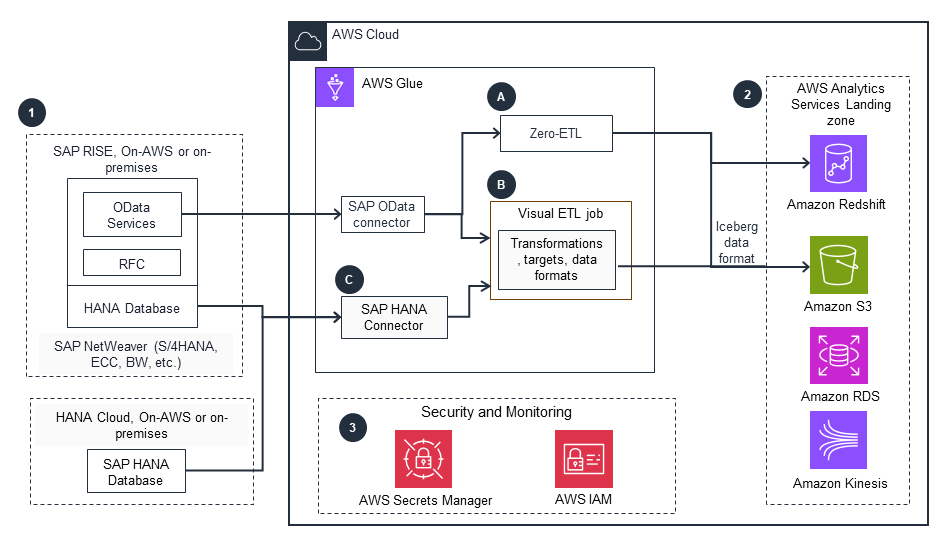
This architecture diagram shows how to ingest SAP data to AWS using AWS glue. For the other architecture patterns, open the other tabs.
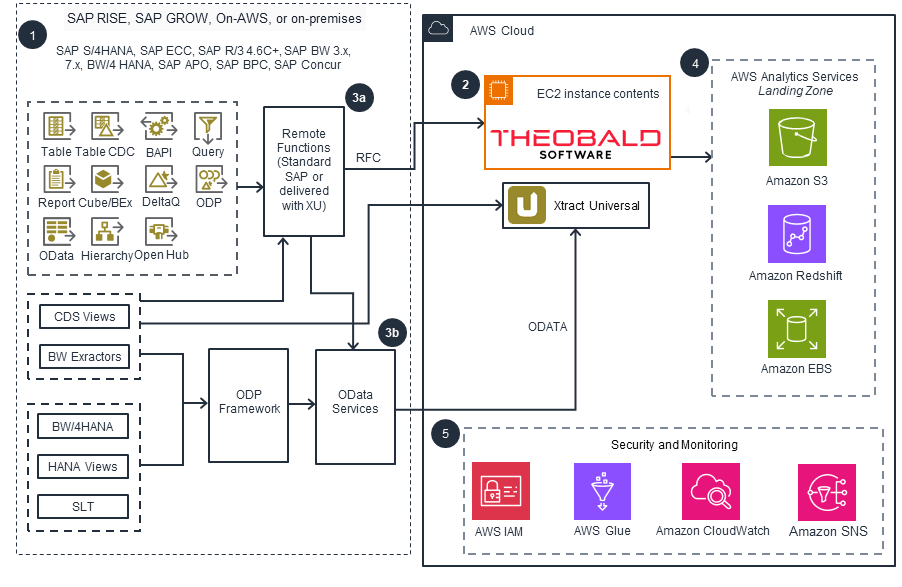
AWS Partner Solution - Theobald Xtract Universal
This architecture diagram shows how to ingest SAP data to AWS using the Partner Solution Theobald Software Xtract Universal.
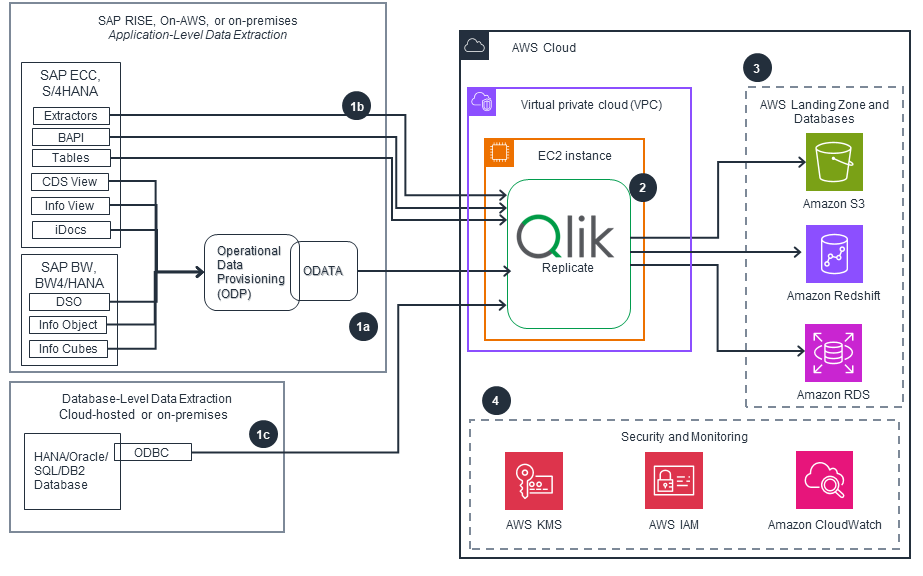
AWS Partner Solution - Qlik Replicate
This architecture diagram shows SAP ERP connectivity and data integration with Qlik Replicate.
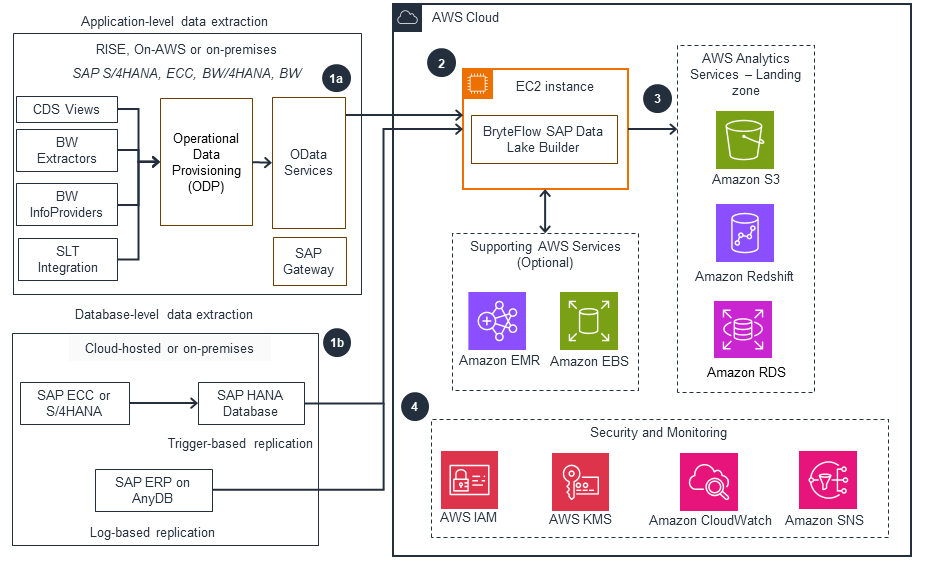
AWS Partner Solution - BryteFlow Ingest
This architecture diagram shows how to ingest SAP data to AWS using the AWS Partner Solution BryteFlow SAP Data Lake Builder.
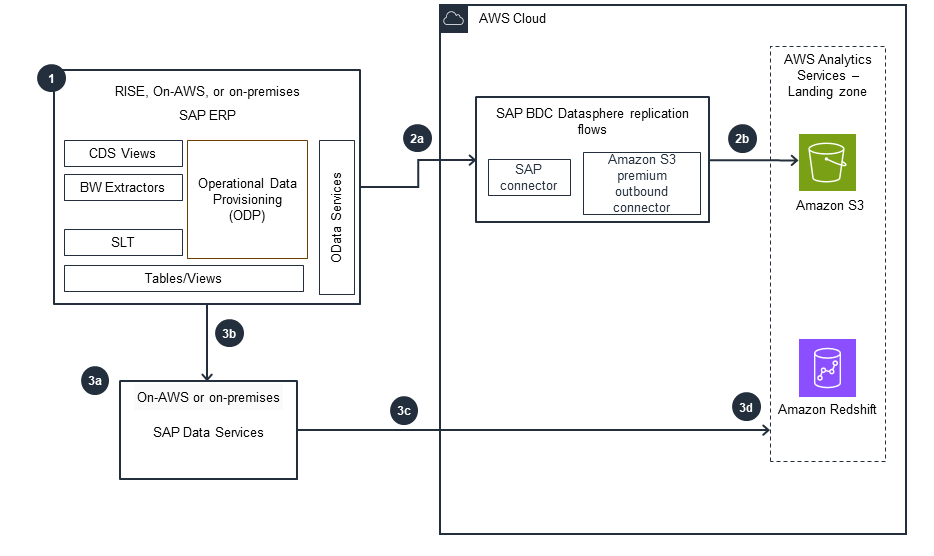
How it works (continued)
Using SAP BDC Datasphere, Data Services
This architecture diagram shows how to ingest SAP data to AWS using SAP Datasphere or SAP Data Services.
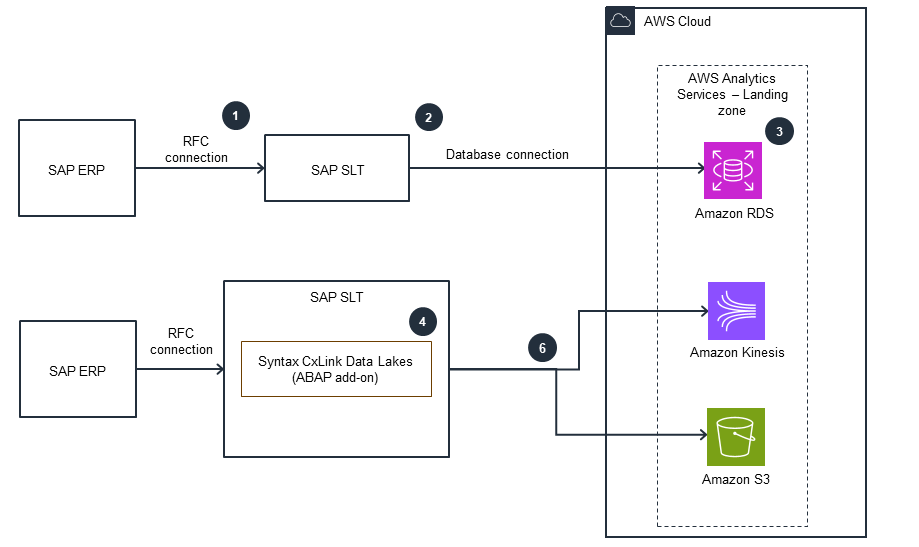
Using SLT
This architecture diagram shows how to ingest SAP data to AWS using SAP SLT.
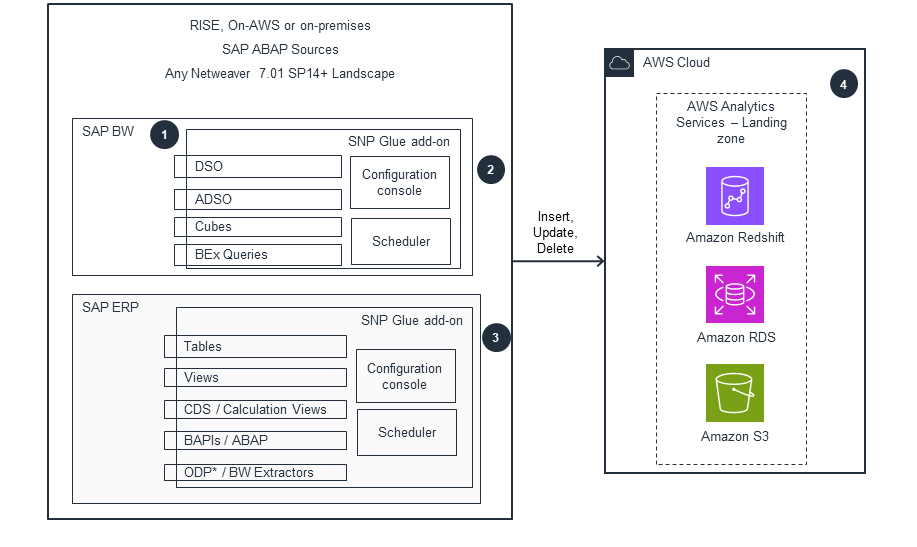
SNP GLUE, an SAP NetWeaver Add-On Solution by SNP
This architecture diagram shows how to use SAP NetWeaver add-on solution SNP Glue to extract data from SAP to AWS.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
AWS CloudFormation automates the deployment process, while CloudWatch provides observability, tracking, and tracing capabilities. The entire solution can be deployed using CloudFormation, which helps automate deployments across development, quality assurance, and production accounts. This automation can be integrated into your development pipeline, enabling iterative development and consistent deployments across your SAP landscape.
IAM secures AWS Glue and Amazon AppFlow through permission controls and authentication. These managed services access only specified data. Amazon AppFlow facilitates access to SAP workloads. Data is encrypted in transit and at rest. AWS CloudTrail logs API calls for auditing. S3 buckets and cross-region replication can store data. For enhanced security, run Amazon AppFlow over AWS PrivateLink with Elastic Load Balancing and SSL termination using AWS Certificate Manager.
Amazon AppFlow and AWS Glue can reliably move large volumes of data without breaking it down into batches. Amazon S3 provides industry-leading scalability, data availability, security, and performance for SAP data export and import. PrivateLink is a regional service, and as part of the Amazon AppFlow setup using PrivateLink, you will set up at least 50 percent of Availability Zones in the Region (minimum two Availability Zones per Region), providing an additional level of redundancy for ELB.
The SAP operational data provisioning framework captures changed data. Parallelization features in Amazon AppFlow and AWS Partner Solutions like BryteFlow and SNP enable customers to choose the number of parallel processes to run in the background, parallelizing large data volumes. Amazon S3 offers improved throughput with multi-part uploads through supported data integration mechanisms. The parallelization capabilities and seamless integration with Amazon S3 allow for efficient and scalable data ingestion from SAP systems into AWS.
By using serverless technologies like Amazon AppFlow or AWS Glue and Amazon EC2 auto scaling, you only pay for the resources you consume. To optimize costs further, extract only the required business data groups by leveraging semantic data models (for example, BW extractors or CDS views). Minimize the number of flows based on your reporting granularity needs. Implement housekeeping by setting up data tiering or deletion in Amazon S3 for old or unwanted data.
Data extraction workloads can be scheduled or invoked in real-time, eliminating the need for underlying infrastructure to run continuously. Using serverless and auto-scaling services is a sustainable approach for data extraction workloads, as these components activate only when needed. By leveraging managed services and dynamic scaling, you minimize the environmental impact of backend services. Adopt new options for Amazon AppFlow as they become available to optimize the volume and frequency of extraction.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages