- AWS Solutions Library
- Guidance for Multi-Region Resilient Microservice on AWS
Guidance for Multi-Region Resilient Microservice on AWS
Launch a failover sequence deployment across multiple AWS Regions to protect workloads
Overview
This Guidance demonstrates how to build highly resilient web applications that can withstand disruptions, minimizing impact on revenue and application downtime. By leveraging a multi-Region architecture, automated failover orchestration, and comprehensive monitoring, this Guidance helps ensure critical web applications remain available and consistent, even in the face of significant impairments. You can reduce the blast radius of affected users, maintain data integrity, and make informed decisions on when to failover between primary and standby Regions to maximize uptime and protect business continuity.
How it works
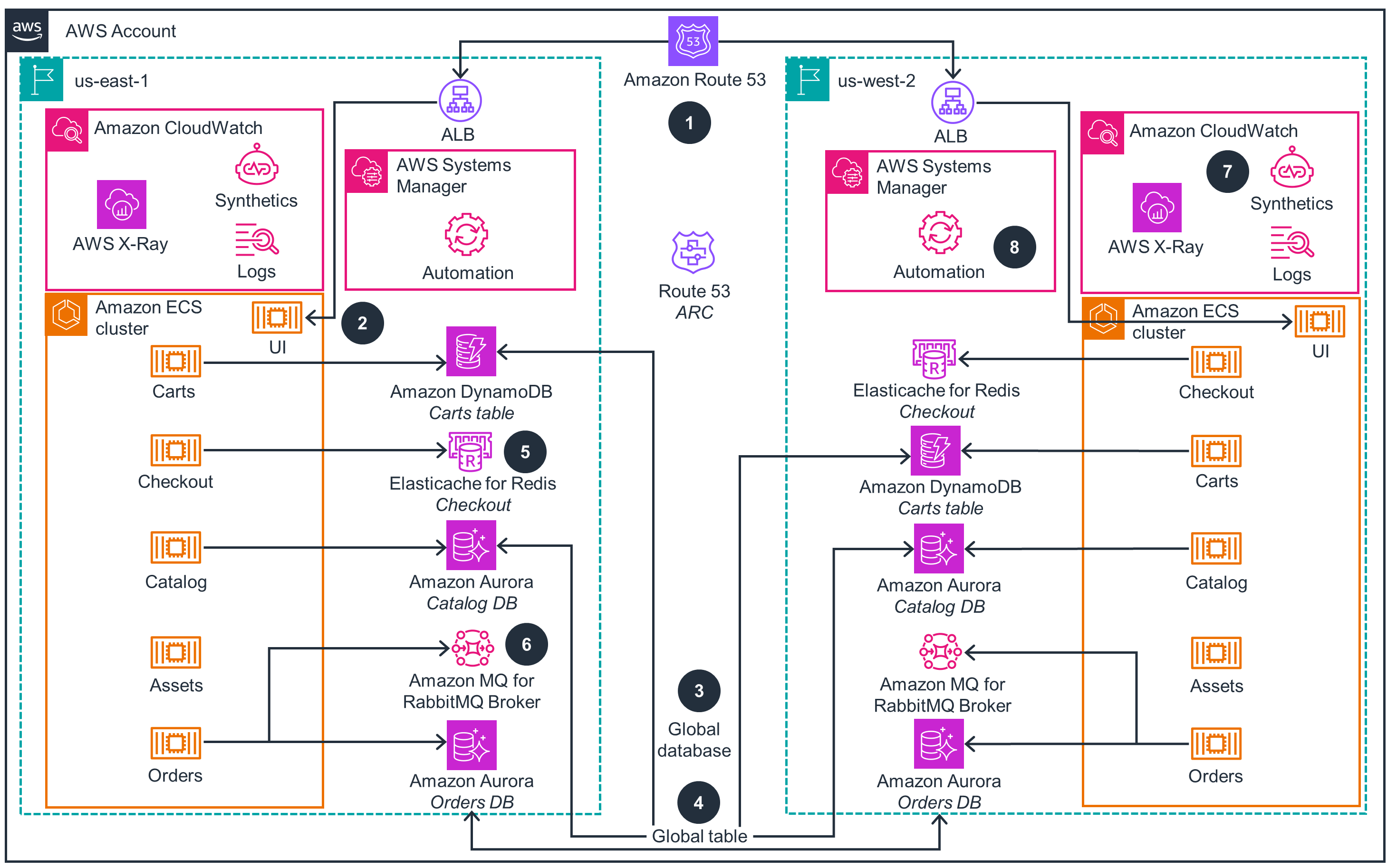
Active/Active State
This architecture diagram shows the active/active state across two AWS Regions.
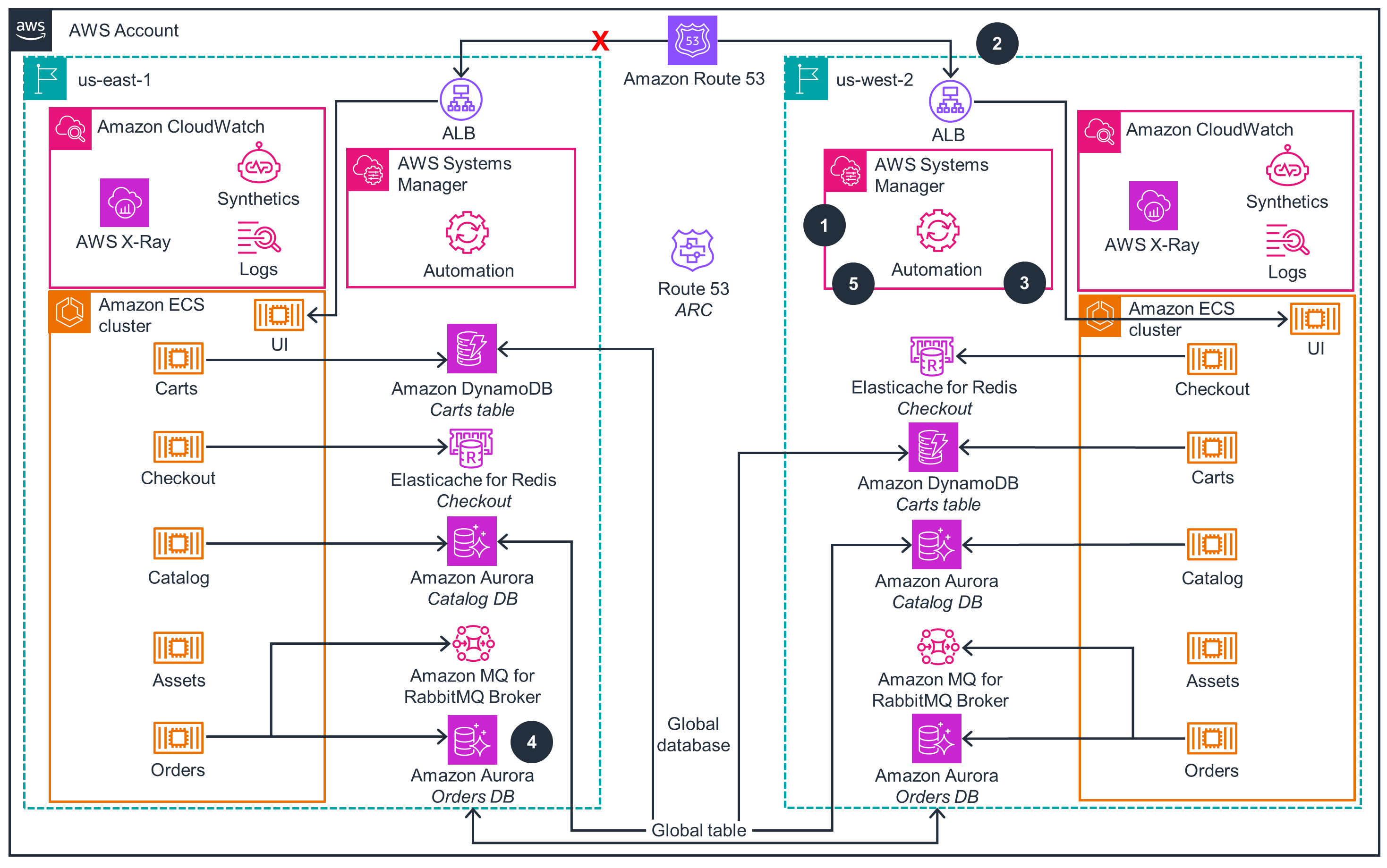
Failover Sequence
This architecture diagram shows the failover sequence when the workload fails over to us-west-2 from us-east-1 AWS Region.
Get started
Deploy this Guidance
Use sample code to deploy this Guidance in your AWS account
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
AWS X-Ray traces application calls from Amazon ECS tasks, visualizing communication flows of microservices and analyzing user requests as they travel through the UI to underlying microservices. CloudWatch Synthetics generates traffic to the application, creating metrics for setting thresholds and alerting if issues arise. Systems Manager runbooks automate failover and failback processes, minimizing human error and ensuring the application meets recovery time objective (RTO) and recovery point objective (RPO) requirements.
AWS Identity and Access Management (IAM) roles and policies secure microservices' interactions with AWS services, enforcing robust security through meticulously defined permissions. AWS Key Management Service (AWS KMS) encrypts data at rest across services, including Aurora and DynamoDB.
Elastic Load Balancing (ELB) routes traffic requests from the application's web interface to healthy Amazon ECS tasks, while Amazon ECS replaces unhealthy tasks and adds more tasks to handle increased load. Amazon Application Recovery Controller reliably enables and disables AWS Regions based on application traffic. DynamoDB global tables and Aurora global databases keep application data consistent within the RPO requirements across multiple AWS Regions. Systems Manager runbooks orchestrate components that need to be changed when shifting traffic from one AWS Region to another. Together, these services help ensure the application experiences minimal service interruptions.
ELB distributes incoming traffic across multiple targets, preventing any single instance from becoming overwhelmed and maintaining high performance. Aurora read replicas offload read traffic from the primary database instance, distributing the workload and improving overall performance. Aurora global databases extends the benefits of read replicas across multiple Regions, enabling read scaling and improved performance for geographically distributed applications. DynamoDB global tables replicate DynamoDB tables across multiple AWS Regions, enabling low-latency data access for users worldwide.
Auto scaling automatically adjusts the number of Amazon ECS tasks based on demand, so that you only pay for the resources needed. AWS Fargate for Amazon ECS eliminates the need to provision and manage servers, allowing you to run containers without the overhead of managing Amazon Elastic Compute Cloud (Amazon EC2) instances, leading to improved efficiency and reduced costs.
Auto scaling and DynamoDB On-Demand add capacity when needed and scale down when not required. On-demand services minimize the environmental impact of the workload by efficiently using only the necessary resources to meet the application's demands.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages