- AWS Solutions Library
- Guidance for Reading & Highlighting Web Content with Amazon Polly
Guidance for Reading & Highlighting Web Content with Amazon Polly
Overview
This Guidance demonstrates how to set up audio playback for a webpage using Amazon Polly, which can read the content of the webpage aloud for your visitors and highlight the text as it’s being narrated. This text-to-speech capability enhances accessibility for your users, representing a crucial step in your organization's accessibility strategy. Furthermore, audio-enriched content is more impactful and memorable, helping to drive increased traffic to your page and strengthen your brand.
How it works
Static Webpages
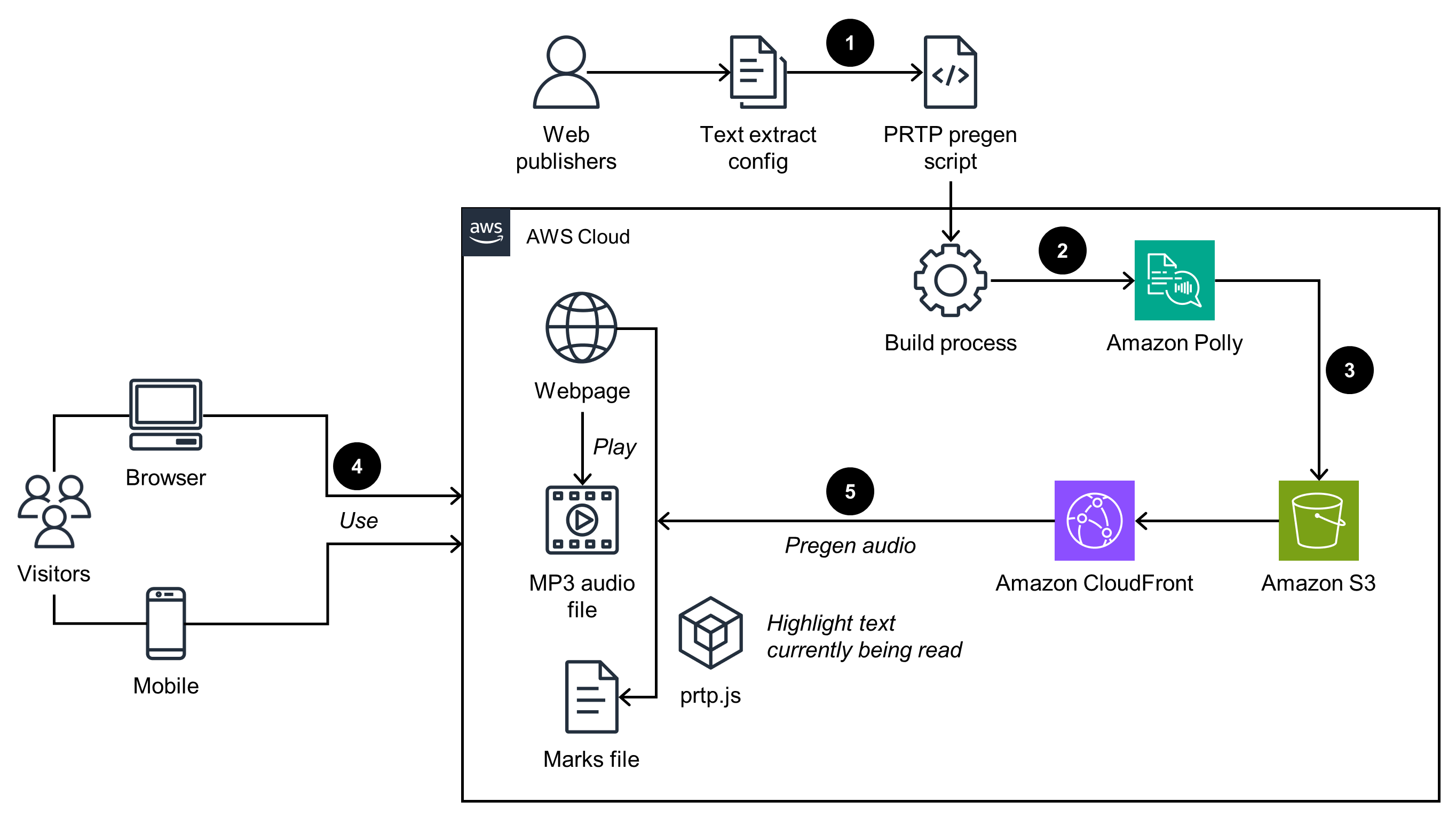
This architecture diagram shows how to use Amazon Polly to read and highlight content on static webpages. Amazon Polly outputs the files in a storage bucket. When you play the audio, the browser downloads the MP3.
Dynamic Webpages
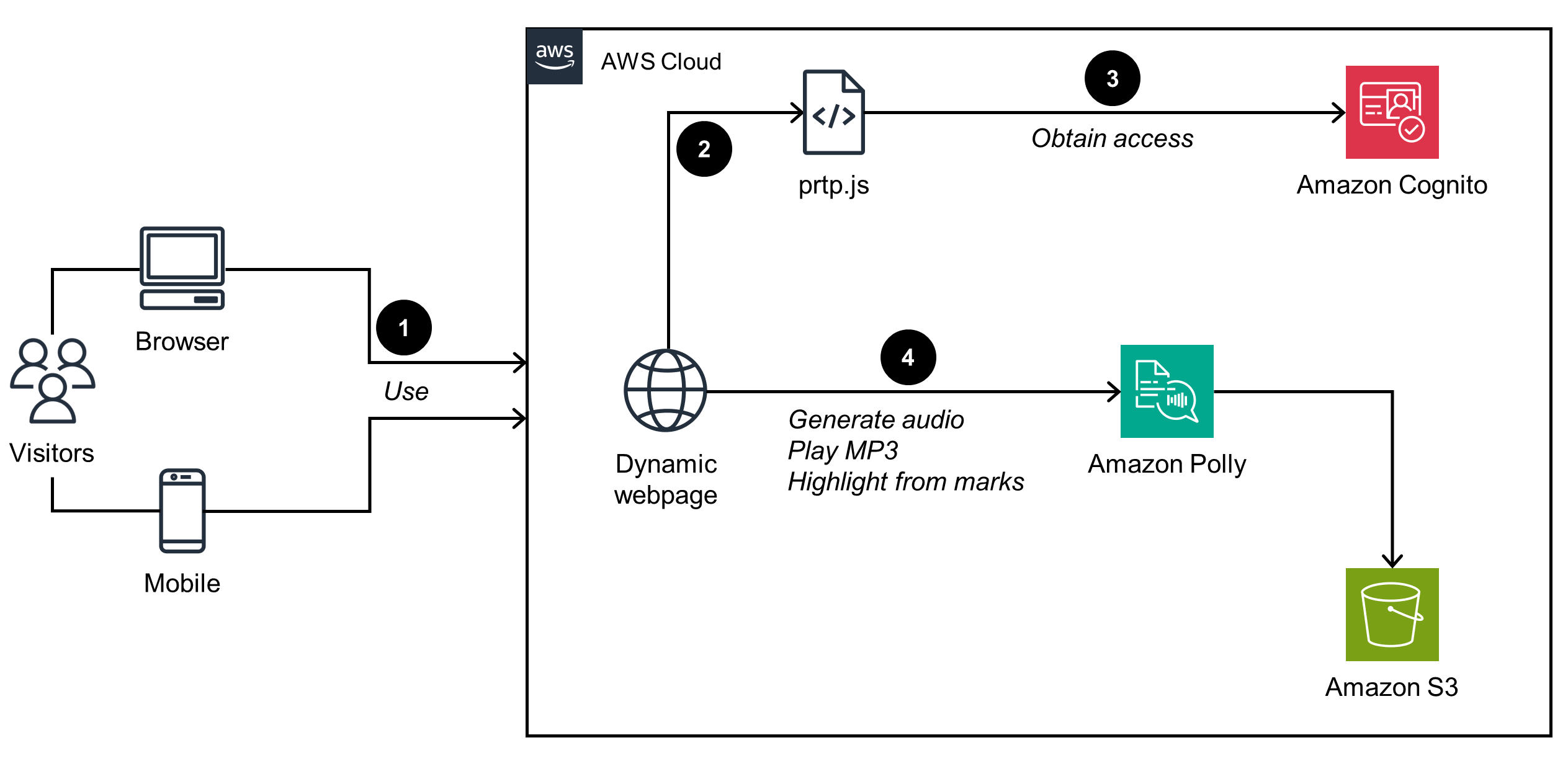
This architecture diagram shows how to use Amazon Polly to read and highlight content on dynamic webpages. When you play the audio, the page uses prtp.js to generate the audio in Amazon Polly, which highlights the synthesized audio using the same approach as for static pages.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
You can adjust and test the speech configuration for static and pre-generated speech in an environment outside of the web application. When you’re ready to deploy changes to your web application, you can link your webpages to the pre-generated speech files as part of your existing web publication process. You can also adjust and test dynamic generation in a test web environment by using a modified version of the client-side JavaScript provided in this Guidance. You can then deploy these changes to your production web server as part of your web application update process. Additionally, Amazon CloudWatch allows you to monitor the use of Amazon Polly and Amazon S3 resources. Notably, the Amazon Polly request character count increases as the number of requests for speech generation increases.
A Cognito identity pool provides unauthenticated users with sufficient access to Amazon Polly and Amazon S3 resources to generate speech from text on the webpage. You can modify this to provide access only to authenticated users. Alternatively, you can use CloudFront to distribute the audio content so that webpage visitors will not have direct access to the Amazon S3 bucket. This enables you to secure and restrict access, such as by using signed URLs or cookies, geographical restrictions, and AWS WAF protections.
This Guidance uses the 256-bit Advanced Encryption Standard (AES) to encrypt the Amazon S3 bucket, but you can modify this Guidance to use AWS Key Management Service (AWS KMS). For data in transit, access to Amazon Polly occurs through the AWS Command Line Interface (AWS CLI), an AWS software development kit (AWS SDK) tool for JavaScript, or an HTTPS or TLS connection. You can use an Amazon S3 bucket policy to mandate HTTPS to access the bucket.
Amazon S3 provides highly durable storage, and most storage classes replicate objects across three Availability Zones (AZs), increasing availability and decreasing the chance that a visitor is unable to access speech files. Additionally, an AWS SDK for JavaScript, which dynamically synthesizes speech, is equipped with throttling and retry capabilities.
To optimize this Guidance, first identify static content and use the provided pre-generation capability as outlined in the architecture diagram. This improves performance by eliminating the need for real-time speech synthesis. Static content can be served directly from an Amazon S3 bucket, either as a static website or as the origin for a CloudFront distribution. This avoids the need for additional processing or storage capacity on your web server to serve speech and audio files. It also benefits from low-latency access to this data through caching and the availability of that content at the edge. Next, customize the content selection for speech generation, utilizing the provided configuration examples.
To reduce latency, deploy this Guidance to the same AWS Region as your web application. Alternatively, if you use a CloudFront distribution, you can achieve low latency through caching or by serving content at the edge, closer to your web application’s visitors. Additionally, you can customize how content is selected for speech generation to control the text to be synthesized.
To optimize costs, you can identify static content and pre-generate speech files so that Amazon Polly only needs to convert text to speech once. You can also limit the number of spoken voices or languages that Amazon Polly can generate for your website. Data transfer charges depend on the size and frequency of downloads of generated MP3 and speech mark's files. You can reduce this cost by hosting pre-generated files in Amazon S3, thereby also reducing the storage capacity requirement for your web server.
You can also optimize costs through content caching, which is especially beneficial for popular content whose audio requires frequent access. You can test this approach and monitor costs using AWS Cost and Usage Reports (AWS CUR). Additionally, for content that is dynamic but small (fewer than 6,000 characters long), this Guidance generates speech marks synchronously, so you won’t need to store and download them from an Amazon S3 bucket, thereby reducing traffic costs.
This Guidance allows you to pre-generate speech for static content—a synthesize-once, listen-many approach that minimizes resource and energy use. Additionally, this Guidance uses serverless resources from Amazon Polly, Amazon S3, and Amazon Cognito, so you don’t need to overprovision compute and storage. You can also choose the Amazon S3 Express One Zone Storage Class rather than the default tier to reduce inter-AZ replication and your overall storage footprint.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages