AWS Thai Blog
Top Architecture Blog Posts of 2024-Thai Version
บทความแปลมาจาก Reference: Top Architecture Blog Posts of 2024 (English Version)
อยากจะขอนำเสนอ Blog ที่มีความน่าสนใจของปี 2024
โดยในปี2024 นับเป็นอีกหนึ่งปีแห่งประวัติศาสตร์! เราได้เห็นเห็น AI สร้างสรรค์ถูกนำมาใช้จริงและเปลี่ยนแปลงวงการเทคโนโลยีไปอย่างสิ้นเชิง
(แน่นอน AI/ML ครองอันดับโพสต์ยอดนิยมในปีนี้ แต่เราได้รับความสนใจอย่างมากจากผู้อ่านของเรา อย่างไรก็ดี ท่านสามารถศึกษาเพิ่มเติมได้ที่ AWS Machine Learning Blog)
ที่นี้เรามาดูTop post ของปี 2024 กันครับ เริ่มจากอันดับ 10 ก่อน
#10 Deploy Stable Diffusion ComfyUI on AWS elastically and efficiently
โพสต์นี้ พูดถึง การที่คุณเริ่มต้นใช้งาน ComfyUI ได้ และประสบความสำเร็จอย่างมากจนเราได้ทำโพสต์ต่อเนื่องในช่วงท้ายปีเกี่ยวกับวิธีสร้าง custom nodes workflow ด้วย ComfyUI บน EKS!
(คำอธิบายเพิ่ม) ComfyUI คือ Node-based interface สำหรับการใช้งาน Stable Diffusion ที่ให้ผู้ใช้สามารถสร้างและปรับแต่งการสร้างภาพด้วย AI ได้อย่างยืดหยุ่น
ตัวอย่างการเริ่มใช้งานพื้นฐาน: รันโปรแกรมผ่าน command line หรือ เปิดเว็บบราวเซอร์ไปที่ localhost:8188, เริ่มสร้าง workflow โดยการลาก nodes มาวางและเชื่อมต่อกัน, ใช้ Queue สำหรับงาน batch, Debug ตรวจสอบการเชื่อมต่อระหว่าง nodes
ตัวอย่าง Use Cases: สร้างภาพจาก text prompt, แก้ไขภาพที่มีอยู่ (img2img), การสร้างภาพแบบ batch, การทำ animation)
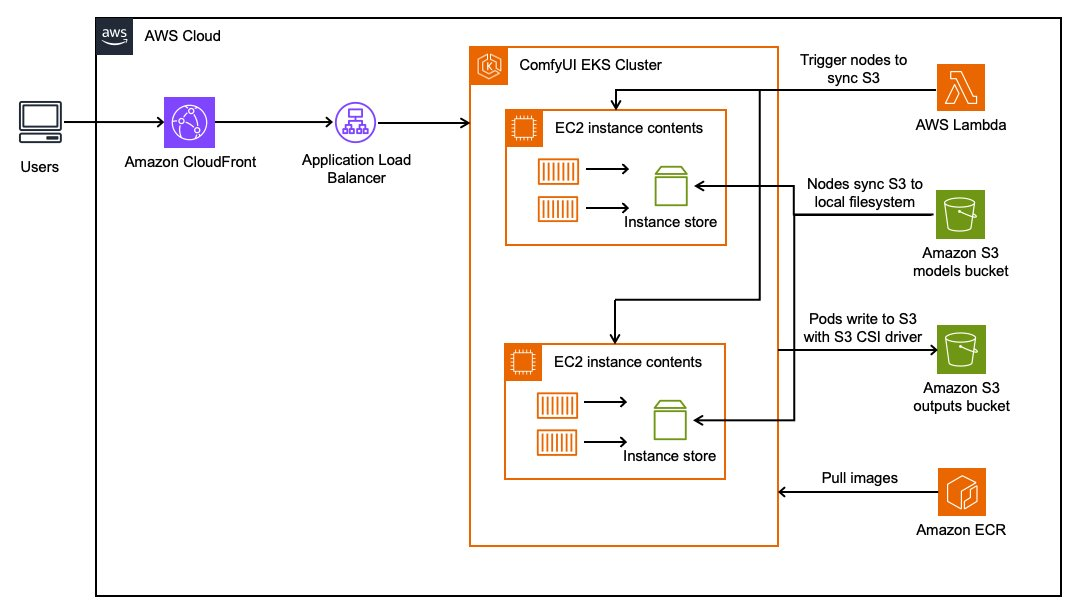
รูปที่ 1. สถาปัตยกรรมสำหรับการติดตั้งใช้งาน Stable Diffusion บน ComfyUI
[ผมขอสรุปให้สั้นๆนะครับ-สรุปใจความของบทความ]
การใช้งาน Stable Diffusion และ ComfyUI บนระบบคลาวด์ AWS กำลังได้รับความนิยมอย่างต่อเนื่อง ด้วยความสามารถในการสร้างภาพคุณภาพสูงและความยืดหยุ่นในการปรับแต่ง เพื่อรองรับการทำงานที่มีประสิทธิภาพสูงสุด
ระบบเริ่มต้นด้วยการใช้ Amazon EKS เป็นฐานในการรันคอนเทนเนอร์ (container workloads) และรองรับการปรับขนาดอัตโนมัติผ่าน Karpenter (Dynamic scaling) เพื่อลดต้นทุนและเพิ่มประสิทธิภาพการใช้งาน
*Karpenter คือ auto-scaling controller สำหรับ Kubernetes cluster ที่พัฒนาโดย AWS มีหน้าที่หลักในการจัดการ node scaling อัตโนมัติได้อย่างมีประสิทธิภาพ
(Storage) ดึง image จาก Amazon ECR ส่วนการเก็บโมเดลและผลลัพธ์ ของทั้ง Node และ Pods ได้จัดเก็บผลลัพธ์ไว้ใน Amazon S3 โดยตรง ผ่านการใช้งาน Persistent Volume Claim และ S3 CSI Driver บน instacnce store อีกด้วย
นอกจากนี้ ได้ใช้ Amazon EFS สำหรับแชร์ไฟล์ที่จำเป็น กับ EC2 instances (แบบ GPU Nodes) หลายเครื่อง ที่เป็นแบบ Autoscaling ซึ่งจะช่วยเพิ่มประสิทธิภาพ สูงสุด
(Security) ด้านความปลอดภัยจะใช้ IAM roles และ security groups พร้อมทั้งใช้ Amazon CloudWatch ในการติดตามประสิทธิภาพ การบันทึก log และตรวจสอบปัญหาอีกด้วย
ส่วนการประมวลผลrequest ที่มีการเปลี่ยนแปลงแบบเรียลไทม์ ผ่าน API endpoints สามารถใช้ CloudFront หรือ Application Load Balancer เสริมได้อีกด้วย
#9 Let’s Architect! Designing Well-Architected systems
อันต่อมา Blog จาก ซีรีส์ Let’s Architect! ผมขอนำเสนอเนื้อหาที่เราโปรดปรานอันแรกจากทั้งหมดสามชุด ของประจำปีนี้
ซึ่งจะให้ความรู้ ด้านการตั้งมาตรฐาน Well-Architected เพื่อไปประยุกต์ใช้ในการปฏิบัติงาน

รูปที่ 2. Let’s Architect
[สรุปใจความของบทความ]
บทความนี้นำเสนอแนวทางการออกแบบระบบคลาวด์ที่สอดคล้องกับมาตรฐาน AWS Well-Architected Framework ซึ่งประกอบด้วย 6 เสาหลัก ได้แก่
(1)ความเป็นเลิศในการดำเนินงาน (Operational Excellence)
(2)ความปลอดภัย (Security)
(3)ความน่าเชื่อถือ (Reliability)
(4)ประสิทธิภาพในการทำงาน (Performance Efficiency)
(5)การเพิ่มประสิทธิภาพต้นทุน (Cost Optimization)
(6)ความยั่งยืน (Sustainability) โดยมีเป้าหมายเพื่อช่วยให้ผู้พัฒนาสามารถออกแบบและดำเนินงานระบบที่มีความน่าเชื่อถือ ปลอดภัย มีประสิทธิภาพ และคุ้มค่าทางต้นทุนในคลาวด์
นอกจากนี้ยังมีการแนะนำ AWS Well-Architected Mergers and Acquisitions Lens ซึ่งเป็นแนวทางสำหรับการรวมระบบขององค์กรที่ได้มาหรือควบรวม โดยมุ่งเน้นการบูรณาการระบบ IT ของสององค์กรขึ้นไปอย่างมีประสิทธิภาพและสอดคล้องกับมาตรฐาน AWS
สุดท้าย บทความนี้แนะนำการใช้วิธีการทางคณิตศาสตร์เชิงพาณิชย์ (Formal Methods) เพื่อเพิ่มความมั่นใจในความถูกต้องและความยืดหยุ่นของระบบ โดยเฉพาะในระบบที่มีการกระจายตัว ซึ่งช่วยให้สามารถค้นหาข้อผิดพลาดในการออกแบบได้ตั้งแต่ระยะเริ่มต้นของการพัฒนา ซึ่งน่าสนใจมากครับ
#8 Let’s Architect! Learn About Machine Learning on AWS

รูปที่ 3. Let’s Architect
[สรุปใจความของบทความ]
การเรียนรู้เกี่ยวกับ Machine Learning บน AWS: มุมมองและการประยุกต์ใช้
Machine Learning (ML) ได้กลายเป็นเทคโนโลยีสำคัญที่องค์กรต่างๆ นำมาใช้เพิ่มประสิทธิภาพการทำงาน AWS ได้พัฒนาบริการที่ครอบคลุมความต้องการด้าน ML โดยมี Amazon SageMaker เป็นบริการหลักที่ช่วยให้การพัฒนาและฝึกฝนโมเดลเป็นเรื่องง่าย
เริ่มต้นด้วยการแนะนำแนวทาง “Working Backwards” ซึ่งเป็นกระบวนการที่ช่วยให้องค์กรสามารถกำหนดปัญหาและความต้องการของลูกค้าได้ชัดเจน ก่อนที่จะพัฒนาโซลูชันที่ตอบโจทย์ การใช้แนวทางนี้ช่วยให้การพัฒนา ML projects มีทิศทางที่ชัดเจนและมุ่งเน้นที่การสร้างคุณค่าจริงให้กับธุรกิจ
บทความได้พูดถึง การทำ MLOps engineering บน AWS, การ implementing ML บน AWS แบบสั้นๆ และ เวิร์กช็อป SageMaker Immersion Day ที่ให้ความรู้แบบครบวงจรในการสร้างและใช้งาน Machine Learning โดยครอบคลุม (การพัฒนาโมเดล,deploy โมเดล,Model debugging,Model monitoring)
#7 Creating an organizational multi-Region failover strategy
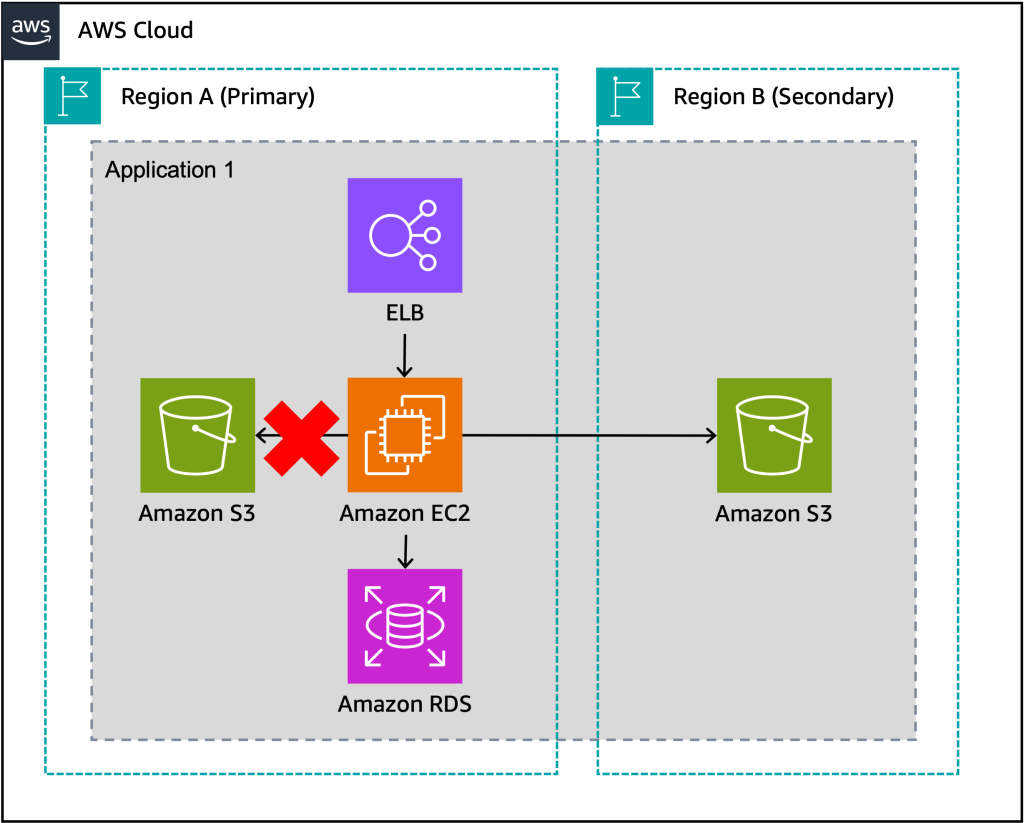
รูปที่ 4. เมื่อแอปพลิเคชันประสบปัญหาในการใช้ทรัพยากร S3 ในRegionหลัก (primary Region) ระบบจะสลับไปใช้ S3 bucket ในRegionรอง (secondary Region) แทน
[สรุปใจความของบทความ]
แนวทางการออกแบบfailoverระบบข้ามภูมิภาค (multi-region failover) สำหรับองค์กร
โดยเน้นที่การประสานกัน ระหว่างแอปพลิเคชันและส่วนประกอบต่าง ๆ
เพื่อให้สามารถรับมือกับเหตุการณ์ที่ส่งผลกระทบต่อ primary Region ได้อย่างมีประสิทธิภาพ
บทความแบ่งกลยุทธ์การfailover ออกเป็น 4 ระดับ ได้แก่:
-Component-level failover: การfailover บางส่วนของแอปพลิเคชัน เช่น infrastructure, code and config, data stores, and dependencies
-Individual application failover: การfailover อนุญาตให้แต่ละส่วนของแอปพลิเคชันสามารถfailover บางส่วนหรือทั้งหมด
-Dependency graph failover: เพื่อแก้ไขความซับซ้อนของกลยุทธ์ก่อนหน้านี้ คุณอาจตัดสินใจที่จะfailover ส่วนที่เกี่ยวข้องกัน อยู่ด้วยกัน
-Entire portfolio failover: การfailoverแอปพลิเคชันทั้งหมดขององค์กร ซึ่งง่ายต่อการจัดการ แต่ต้องการการลงทุนสูง
#6 Building a three-tier architecture on a budget
บทความนี้ คุยเรื่องการเพิ่มประสิทธิภาพด้านcost optimizationกัน โดยโพสต์นี้เกี่ยวกับสถาปัตยกรรมแบบ Three-Tier (Presentation Tier (ส่วนแสดงผล), Application Tier (ส่วนประมวลผล), Data Tier (ส่วนจัดการข้อมูล)) โดยใช้ AWS Free Tier
ซึ่งเป็นเคล็ดลับในการหลีกเลี่ยงค่าใช้จ่าย ซึ่งเป็นสิ่งที่ทุกคนที่ควรมองหา
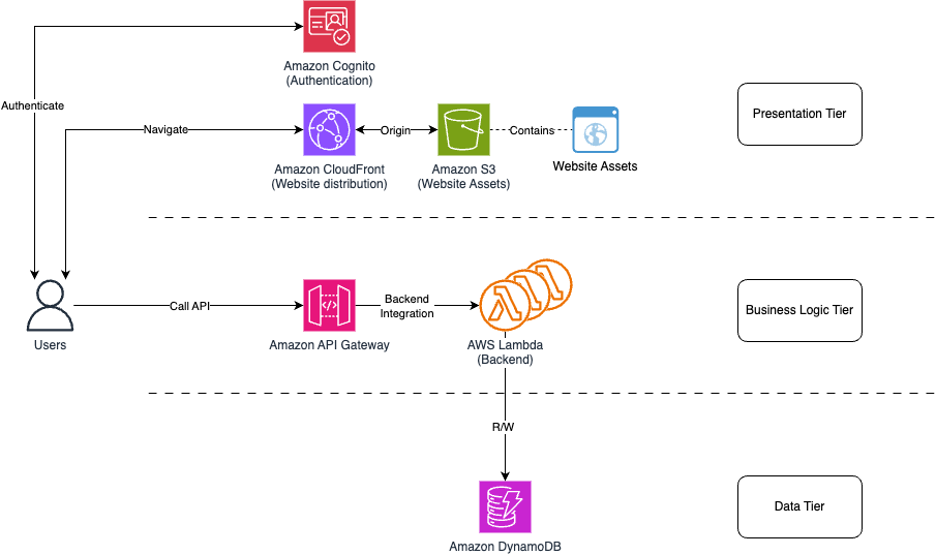
รูปที่ 5. ตัวอย่างการออกแบบระบบแบบ Three-Tier บน AWS (Presentation Tier (ส่วนแสดงผล), Application Tier (ส่วนประมวลผล), Data Tier (ส่วนจัดการข้อมูล))
[สรุปใจความของบทความ]
บทความอธิบาย วิธีการใช้บริการแบบ serverless ของ AWS ภายใต้ Free Tier เพื่อสร้างแอปพลิเคชันแบบThree-Tier
สถาปัตยกรรมแบบ serverless ของ AWS มีข้อดีทั้งในด้านการประหยัดค่าใช้จ่าย ความยืดหยุ่น และความสามารถในการปรับขนาด
นอกเหนือนี้ การใช้ CloudWatch สำหรับ monitoring และ AWS Systems Manager สำหรับจัดการระบบ ซึ่งช่วยลดค่าใช้จ่ายในการดูแลระบบ
#5 Announcing updates to the AWS Well-Architected Framework guidance
ผู้เขียน Haleh Najafzadeh ได้อธิบายการปรับปรุง update ของ Well-Architected Framework โดยมีความทันสมัยและใช้งานได้จริงอยู่เสมอ
![]()
รูปที่ 6.Well-Architected logo
[สรุปใจความของบทความ]
AWS ประกาศอัปเดตคู่มือการใช้งาน Well-Architected Framework เพื่อให้สอดคล้องกับความต้องการที่เปลี่ยนแปลงของลูกค้าและเทคโนโลยีที่พัฒนาขึ้น
โดยมุ่งเน้นการสร้างระบบคลาวด์ที่มีประสิทธิภาพ ปลอดภัย และยั่งยืน
โดยเสาหลัก Framework นี้ยังคงยึดหลัก 6 เสาหลัก ได้แก่ ความเป็นเลิศในการดำเนินงาน ความปลอดภัย ความน่าเชื่อถือ ประสิทธิภาพการทำงาน การเพิ่มประสิทธิภาพด้านต้นทุน และความยั่งยืน
แต่ได้เพิ่มแนวทางปฏิบัติที่ทันสมัยและครอบคลุมมากขึ้น
อีกทั้ง การอัปเดตครั้งนี้ประกอบด้วยการปรับปรุงคู่มือของ Framework รวมทั้งสิ้น 78 best practices และได้เพิ่มเติม ขยายคำแนะนำควบคุมสำหรับservicesต่างๆ มากยิ่งขึ้น โดยตามรายชื่อในblog
#4 Let’s Architect! Serverless developer experience in AWS
บทความคอลเลกชันของเครื่องมือสำหรับนักพัฒนานี้นำเสนอไอเดียใหม่ๆ เกี่ยวกับ AWS Lambda, Amazon Q Developer และ Amazon DynamoDB
รูปที่ 7.Let’s Architect
[สรุปใจความของบทความ]
การพัฒนาแอปพลิเคชันแบบ Serverless บน AWS กำลังได้รับความนิยมเพิ่มขึ้นอย่างต่อเนื่อง เนื่องจากช่วยลดภาระในการจัดการโครงสร้างพื้นฐานและเพิ่มประสิทธิภาพในการพัฒนา AWS ได้พัฒนาเครื่องมือและบริการที่ช่วยให้developerสามารถสร้างและจัดการแอปพลิเคชัน Serverless ได้อย่างมีประสิทธิภาพ
-การปรับปรุงเครื่องมือสำหรับการพัฒนา สำหรับ AWS Lambda
-การสร้างและทดสอบโค้ดอย่างรวดเร็วด้วย Amazon Q Developer
-หยุดการคาดเดาขนาดหน่วยความจำของ Lambda functions
-การใช้ program NoSQL Workbench สำหรับ Amazon DynamoDB
-ติดตั้งเครื่องมือสังเกตการณ์สำหรับ Lambda functions ด้วย Powertools
-แนะนำ AWS Serverless developer experience workshop
#3 London Stock Exchange Group uses chaos engineering on AWS to improve resilience
วิธีที่ LSEG designed failure scenarios เพื่อทดสอบความทนทาน(resilience)และความสามารถในการสังเกตการณ์(observability)ของระบบ
Chaos Engineering คือกระบวนการทดสอบระบบโดยเจตนา “สร้างความผิดปกติ” หรือ “จำลองความล้มเหลว” ในสภาพแวดล้อมที่ควบคุมได้ เพื่อศึกษาพฤติกรรมของระบบและตรวจสอบว่าระบบสามารถ ทนต่อเหตุการณ์ไม่คาดคิด ได้ดีเพียงใด เช่น:การหยุดทำงานของเซิร์ฟเวอร์ (EC2 instance crash),ปัญหาเครือข่าย (network latency),ฐานข้อมูลล่ม (RDS failover),ปริมาณโหลดสูงผิดปกติ (CPU spike หรือ traffic overload)
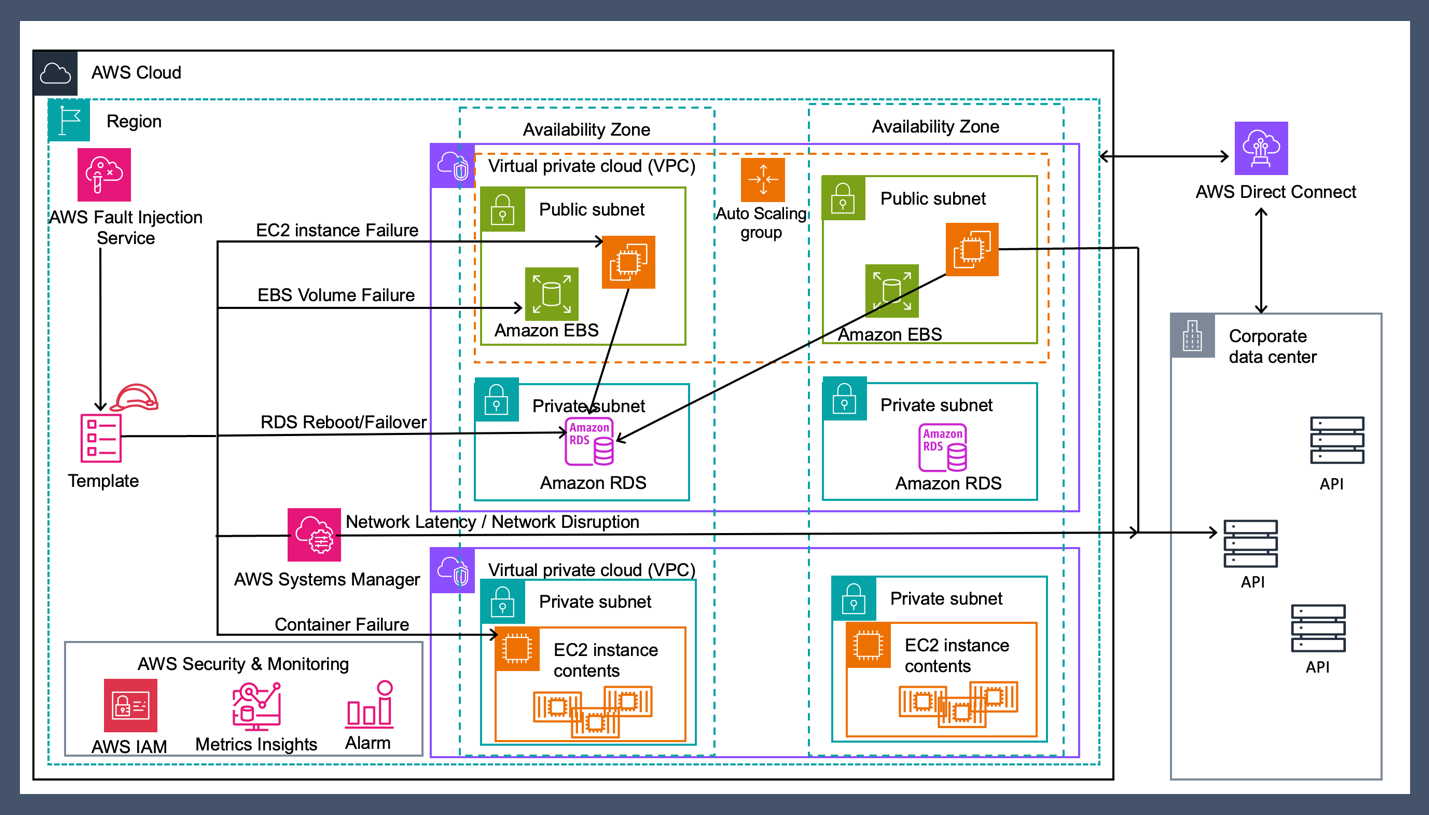
รูปที่ 8.Chaos engineering pattern for hybrid architecture (3-tier application)
[สรุปใจความของบทความ]
London Stock Exchange Group (LSEG) ผู้ให้บริการตลาดการเงินชั้นนำของโลก ได้นำเทคนิค Chaos Engineering มาใช้บนระบบ AWS เพื่อยกระดับความน่าเชื่อถือและความทนทานของระบบ โดยมุ่งเน้นการทดสอบระบบในสถานการณ์ที่ไม่คาดคิดและเตรียมพร้อมรับมือกับความผิดพลาดที่อาจเกิดขึ้น
การทดสอบครอบคลุมหลายสถานการณ์ เช่น การปิดบริการบางส่วน การจำลองปัญหาเครือข่าย และการทดสอบการทำงานของระบบสำรอง โดยใช้เครื่องมือต่างๆ บน AWS เช่น AWS Fault Injection Simulator และ Amazon CloudWatch เพื่อติดตามและวิเคราะห์ผลกระทบ
จากการทดสอบexperiment บน AWS ไม่เพียงช่วยให้ LSEG สามารถรักษามาตรฐานการให้บริการในระดับสูง แต่ยังช่วยสร้างวัฒนธรรมองค์กรที่ให้ความสำคัญกับความน่าเชื่อถือและการเตรียมพร้อมรับมือกับเหตุการณ์ไม่คาดคิด
#2 Achieving Frugal Architecture using the AWS Well-Architected Framework Guidance
Frugality และ Well-Architected? ช่างเป็นการผสมผสานที่ยอดเยี่ยม! บทความนี้ได้แรงบันดาลใจจากการปาฐกถาในงาน re:Invent 2023 โดยอธิบายถึง seven laws of Frugal Architecture
![]()
รูปที่ 9.Well-Architected logo
[สรุปใจความของบทความ]
กฎเจ็ดข้อสำหรับการออกแบบระบบแบบประหยัด(Seven laws of Frugal Architecture)
(กฎข้อที่ 1)ทำให้ต้นทุนเป็นข้อกำหนดที่ไม่เกี่ยวกับฟังก์ชัน
เราควรให้ความสำคัญกับต้นทุนตั้งแต่ขั้นตอนการวางแผน ไม่ใช่แค่มาควบคุมตอนที่ระบบถูกใช้งานไปแล้ว.
(กฎข้อที่ 2)ระบบที่จะอยู่ได้ในระยะยาวต้องมีต้นทุนที่สอดคล้องกับธุรกิจ
(กฎข้อที่ 3)การออกแบบสถาปัตยกรรมคือการตัดสินใจที่ต้องมีการแลกเปลี่ยน
(กฎข้อที่ 4)ระบบที่ไม่มีการติดตามหรือตรวจสอบจะทำให้ไม่สามารถควบคุมค่าใช้จ่ายได้
(กฎข้อที่ 5)การออกแบบระบบที่ใส่ใจเรื่องต้นทุนต้องมีมาตรการควบคุมค่าใช้จ่าย
(กฎข้อที่ 6)การปรับปรุงเพื่อลดต้นทุนต้องทำอย่างต่อเนื่องทีละขั้น
ทำการต่อเนื่อง, มีระบบติดตามผล, การปรับปรุงอย่างต่อเนื่อง
(กฎข้อที่ 7)ความสำเร็จที่ไม่เคยถูกทดสอบจะนำไปสู่การคาดเดาที่ผิดพลาด
ควรทำการการประเมินซ้ำ, เปิดใจรับวิธีการใหม่ๆ, แสวงหาวิธีที่ดีกว่าอยู่เสมอ
#1 How an insurance company implements disaster recovery of 3-tier applications
และแล้วก็มาถึงโพสต์ที่ดีที่สุดของปีนี้! ผู้เขียน Amit และ Luiz ได้นำเสนอกรณีศึกษาจากลูกค้าที่นำไปใช้งานจริง โดยต่อยอดจากแนวทางต่างๆ ที่เราได้แนะนำไว้ในโพสต์ก่อนหน้านี้! ยอดเยี่ยมมากเลย!
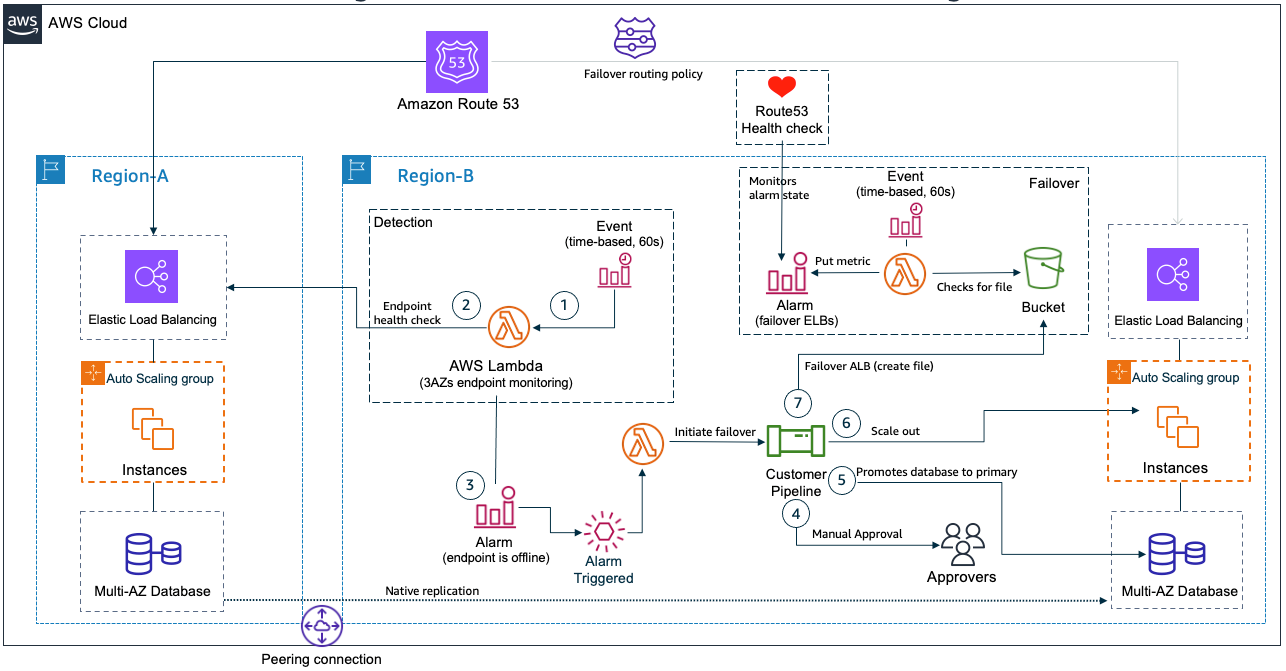
รูปที่ 10.รูปแบบ Pilot Light สำหรับระบบ 3-tier ที่มีการติดตั้งเซิร์ฟเวอร์แอปพลิเคชันและฐานข้อมูลในสองภูมิภาค
[สรุปใจความของบทความ]
วิธีการที่บริษัทประกันภัยจัดการป้องกันระบบ (disaster recovery ) สำหรับ 3-tier applications
โซลูชันสำหรับการกู้คืนระบบจากภัยพิบัติของแอปพลิเคชันแบบสามชั้นนี้ แสดงให้เห็นถึงความมุ่งมั่นของลูกค้าในภาคการเงินที่ต้องการรับประกันความต่อเนื่องทางธุรกิจและความยืดหยุ่นของระบบ
การออกแบบนี้แสดงให้เห็นถึงความสามารถขององค์กรในการปรับแต่งสถาปัตยกรรมให้ตรงกับความต้องการเฉพาะของตน
โดยการบรรลุเป้าหมาย RPO และ RTO ที่น้อยกว่า 15 นาทีสำหรับแอปพลิเคชันที่สำคัญ
ซึ่งถือเป็นความสำเร็จที่น่าทึ่ง อีกทั้งช่วยให้มั่นใจได้ว่าจะมีdowntimeของการดำเนินธุรกิจน้อยที่สุดในระหว่างที่เกิดปัญหาในระดับRegion outages