Veri Etiketleme nedir?
Veri etiketleme nedir?
Makine öğreniminde veri etiketleme, ham verileri (görüntüler, metin dosyaları, videolar vb.) Tanımlama ve bir makine öğrenimi modelinin ondan öğrenebilmesi için bağlam sağlamak için bir veya daha fazla anlamlı ve bilgilendirici etiket ekleme işlemidir. Örneğin, etiketler bir fotoğrafta kuş mu yoksa araba mı olduğunu, bir ses kaydında hangi kelimelerin söylendiğini veya bir röntgen filminde tümör olup olmadığını belirtebilir. Veri etiketleme; bilgisayarlı görü, doğal dil işleme ve konuşma tanıma dahil olmak üzere çeşitli kullanım örnekleri için gereklidir.
Veri etiketleme nasıl çalışır?
Günümüzde çoğu pratik makine öğrenimi modeli, bir girişi bir çıktıya eşlemek için bir algoritma uygulayan denetimli öğrenmeyi kullanır. Denetimli öğrenmenin çalışması için modelin doğru kararlar vermek üzere öğrenebileceği etiketli bir veri kümesine ihtiyacınız vardır. Veri etiketleme genellikle insanlardan belirli bir etiketlenmemiş veri parçası hakkında karar vermelerini isteyerek başlar. Örneğin, etiketleyicilerden "fotoğrafta kuş var mı" sorusunun doğru olduğu bir veri kümesindeki tüm görüntüleri etiketlemeleri istenebilir. Etiketleme, basit bir evet/hayır kadar yüzeysel veya kuşla ilişkili görüntüdeki belirli pikselleri tanımlamak kadar ayrıntılı olabilir. Makine öğrenimi modeli, "model eğitimi" adı verilen bir süreçte temel kalıpları öğrenmek için insanlar tarafından sağlanan etiketleri kullanır. Sonuçta yeni veriler hakkında tahminlerde bulunmak için kullanılabilecek eğitimli bir model elde edilir.
Makine öğreniminde, belirli bir modeli eğitmek ve değerlendirmek için nesnel standart olarak kullandığınız, uygun şekilde etiketlenmiş bir veri kümesine genellikle "kesin referans" denir. Eğitilmiş modelinizin doğruluğu, kesin referansınızın doğruluğuna bağlıdır, bu nedenle son derece doğru veri etiketlemesini sağlamak için zaman ve kaynak harcamak çok önemlidir.
Bazı yaygın veri etiketleme türleri nelerdir?
Bilgisayarlı Görü
Bir bilgisayarlı görü sistemi oluştururken eğitim veri kümenizi oluşturmak için öncelikle görüntüleri, pikselleri veya ana noktaları etiketlemeniz ya da sınırlayıcı kutu olarak bilinen, dijital görüntüyü tamamen çevreleyen bir kenarlık oluşturmanız gerekir. Örneğin, görüntüleri kalite türüne (ürün ve yaşam tarzı görüntüleri gibi) veya içeriğe (görüntüde aslında ne olduğuna) göre sınıflandırabilir ya da bir görüntüyü piksel düzeyinde segmentlere ayırabilirsiniz. Daha sonra bu eğitim verilerini görüntüleri otomatik olarak kategorilere ayırmak, nesnelerin konumunu tespit etmek, bir görüntüdeki ana noktaları tanımlamak veya bir görüntüyü segmentlere ayırmak için kullanılabilecek bir bilgisayarlı görü modeli oluşturmak için kullanabilirsiniz.
Doğal Dil İşleme
Doğal dil işleme, eğitim veri kümenizi oluşturmak için önce metnin önemli bölümlerini manuel olarak tanımlamanızı veya metni belirli etiketlerle etiketlemenizi gerektirir. Örneğin, bir metin tanıtımının analizini veya amacını tanımlamak, konuşma bölümlerini tanımlamak, yerler ve kişiler gibi özel isimleri sınıflandırmak ve görüntülerdeki, PDF'lerdeki veya diğer dosyalardaki metni tanımlamak isteyebilirsiniz. Bunu yapmak için metnin etrafına sınırlayıcı kutular çizebilir ve ardından eğitim veri kümenizdeki metni manuel olarak kopyalayabilirsiniz. Doğal dil işleme modelleri duygu analizi, varlık adı tanıma ve optik karakter tanıma için kullanılır.
Ses İşleme
Ses işleme; konuşma, vahşi yaşam sesleri (havlama, düdük veya cıvıltı) ve bina sesleri (cam kırılması, taramalar veya alarmlar) gibi her türlü sesi makine öğreniminde kullanılabilecek şekilde yapılandırılmış bir biçime dönüştürür. Ses işleme genellikle önce manuel olarak yazılı metne dönüştürmenizi gerektirir. Daha sonra, etiketler ekleyerek ve sesi kategorize ederek ses hakkında daha ayrıntılı bilgiler edinebilirsiniz. Bu kategorize edilmiş ses, eğitim veri kümeniz haline gelir.
Veri etiketleme için bazı en iyi uygulamalar nelerdir?
Veri etiketlemenin verimliliğini ve doğruluğunu artırmanın birçok tekniği vardır. Bu tekniklerden bazıları şunlardır:
- İnsan etiketleyiciler için bilişsel yükü ve bağlam değiştirmeyi en aza indirmeye yardımcı olmak üzere sezgisel ve kolaylaştırılmış görev arabirimleri.
- Bireysel açıklama ekleyicilerin hatasını/önyargısını önlemeye yardımcı olmak için etiketleyici fikir birliği. Etiketleyici fikir birliği, her bir veri kümesi nesnesinin birden çok açıklama ekleyiciye gönderilmesini ve ardından yanıtlarını ("ek açıklamalar" olarak adlandırılır) tek bir etikette birleştirmeyi içerir.
- Etiketlerin doğruluğunu onaylamak ve gerektiğinde bunları güncellemek için etiket denetimi.
- İnsanlar tarafından etiketlenecek en yararlı verileri belirlemek üzere makine öğrenimini kullanarak veri etiketlemeyi daha verimli hale getirmek için aktif öğrenme.
Veri etiketleme nasıl verimli bir şekilde yapılabilir?
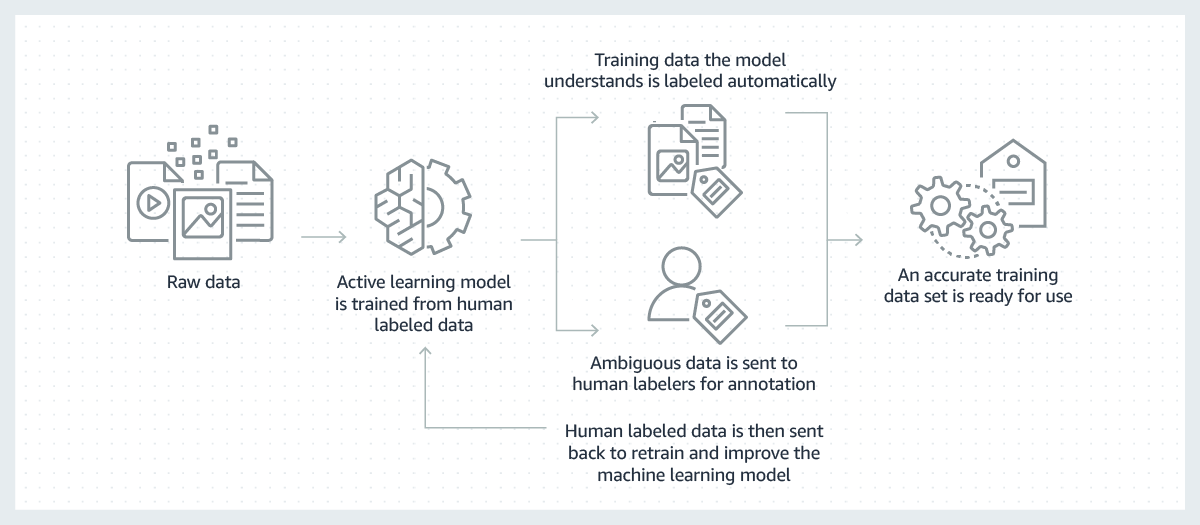
Başarılı makine öğrenimi modelleri, yüksek hacimli ve yüksek kaliteli eğitim verileriyle oluşturulur. Ancak bu modelleri oluşturmak için gerekli olan eğitim verilerini toplama süreci genellikle yüksek maliyetlidir, karmaşıktır ve çok zaman alır. Günümüzde oluşturulan modellerin çoğu, bir insanın verileri, modelin doğru kararları nasıl vereceğini öğrenmesini sağlayacak şekilde manuel olarak etiketlemesini gerektirir. Bu zorluğun üstesinden gelmek üzere verileri otomatik olarak etiketlemek için bir makine öğrenimi modeli kullanılarak etiketleme daha verimli hale getirilebilir.
Bu süreçte, verileri etiketlemek için bir makine öğrenimi modeli ilk olarak ham verilerinizin insanlar tarafından etiketlenmiş bir alt kümesi üzerinde eğitilir. Etiketleme modelinin o zamana kadar öğrendiklerine dayanarak sonuçlarına yüksek güven duyulduğu durumlarda, ham verilere otomatik olarak etiketler uygulayacaktır. Etiketleme modelinin sonuçlarına daha düşük güven duyulduğu durumlarda, etiketlemeyi yapmak için verileri insanlara iletecektir. İnsan tarafından oluşturulan etiketler daha sonra, bir sonraki ham veri kümesini otomatik olarak etiketleyebilmeyi öğrenmesi ve geliştirmesi için etiketleme modeline geri beslenir. Zamanla, model giderek daha fazla veriyi otomatik olarak etiketleyebilir ve eğitim veri kümelerinin oluşturulmasını önemli ölçüde hızlandırabilir.
AWS, veri etiketleme gereksinimlerinizi nasıl destekleyebilir?
Amazon SageMaker Ground Truth, eğitim için veri kümeleri oluşturmak üzere gerekli zamanı ve çabayı önemli ölçüde azaltır. SageMaker Ground Truth, şirketinizde çalışan veya dışarıdan destek aldığınız etiketleme sorumlularına erişim sağlamasının yanı sıra yaygın etiketleme görevleri için yerleşik iş akışları ve arabirimler sunar. SageMaker Ground Truth'u kullanmaya başlamak çok kolaydır. Kullanmaya Başlama öğreticisi, ilk etiketleme işinizi dakikalar içinde oluşturmak için kullanılabilir.
Hemen bir hesap oluşturarak AWS'de Veri Etiketlemeyi kullanmaya başlayın.
AWS'de Sonraki Adımlar
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages