- Amazon SageMaker AI›
- Amazon SageMaker HyperPod›
- Features
Amazon SageMaker HyperPod features
Scale and accelerate generative AI model development across thousands of AI accelerators
Checkpointless training
Checkpointless training on Amazon SageMaker HyperPod enables automatic recovery from infrastructure faults in minutes without manual intervention. It mitigates the need for a checkpoint-based job-level restart for fault recovery which requires pausing the entire cluster, fixing issues, and recovering from a saved checkpoint. Checkpointless training maintains forward training progress despite failures as SageMaker HyperPod automatically swaps faulty components and recovers training using peer-to-peer transfer of model and optimizer states from healthy AI accelerators. It enables over 95% training goodput on clusters with thousands of AI accelerators. With checkpointless training, save millions on compute costs, scale training to thousands of AI accelerators, and bring your models to production faster.
Elastic training
Elastic training on Amazon SageMaker HyperPod automatically scales training jobs based on the availability of compute resources, saving hours of engineering time per week that was previously spent reconfiguring training jobs. The demand for AI accelerators constantly fluctuates as inference workloads scale with traffic patterns, completed experiments release resources, and new training jobs shift workload priorities. SageMaker HyperPod dynamically expands running training jobs to absorb idle AI accelerators, maximizing infrastructure utilization. When higher-priority workloads such as inference or evaluation need resources, training is scaled down to continue with fewer resources without halting entirely, yielding the required capacity based on priorities established through task governance policies. Elastic training helps you accelerate AI model development while reducing cost overruns from underutilized compute.
Task governance
Flexible training plans
Amazon SageMaker HyperPod Spot Instances
Spot Instances on SageMaker HyperPod enable you to access compute capacity at significantly reduced costs. Spot Instances are ideal for fault-tolerant workloads such as batch inference jobs. Prices vary by region and instance type, typically offering a discount of up to 90% off compared to SageMaker HyperPod On-Demand pricing. Spot Instance prices are set by Amazon EC2 and adjust gradually based on long-term trends in supply and demand for Spot Instance capacity. You pay the Spot price that's in effect for the time period your instances are running, with no upfront commitment required. To learn more about estimated Spot Instance prices and instance availability, visit the EC2 Spot Instances pricing page. Note that only instances that are also supported on HyperPod are available for Spot usage on HyperPod.
Optimized recipes to customize models
With SageMaker HyperPod recipes, data scientists and developers of all skill levels benefit from state-of-the-art performance and can quickly start training and fine-tuning publicly available foundation models, including Llama, Mixtral, Mistral, and DeepSeek models. In addition, you can customize Amazon Nova models, including Nova Micro, Nova Lite, and Nova Pro, using a suite of techniques including Supervised Fine-Tuning (SFT), Knowledge Distillation, Direct Preference Optimization (DPO), Proximal Policy Optimization, and Continued Pre-Training— with support for both parameter-efficient and full-model training options across SFT, Distillation, and DPO. Each recipe includes a training stack that has been tested by AWS, saving you weeks of tedious work testing different model configurations. You can switch between GPU-based and AWS Trainium–based instances with a one-line recipe change, enable automated model checkpointing for improved training resiliency, and run workloads in production on SageMaker HyperPod.
Amazon Nova Forge is a first-of-its-kind program that offers organizations the easiest and most cost-effective way to build their own frontier models using Nova. Access and train from intermediate checkpoints of Nova models, mix Amazon- curated datasets with proprietary data during training, and use SageMaker HyperPod recipes to train your own models. With Nova Forge you can use your own business data to unlock use- case specific intelligence and price-performance improvements for your tasks.
High-performing distributed training
Advanced observability and experimentation tools
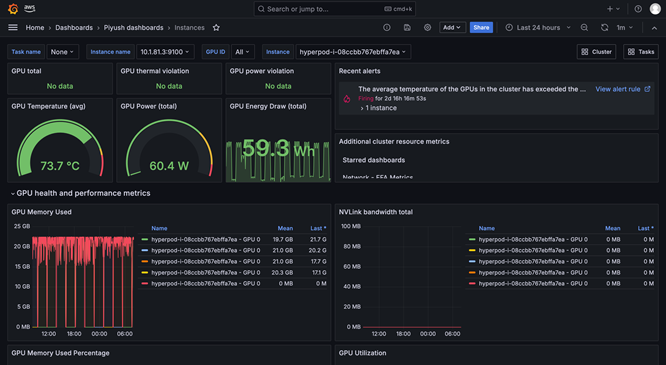
SageMaker HyperPod observability provides a unified dashboard preconfigured in Amazon Managed Grafana, with the monitoring data automatically published to an Amazon Managed Prometheus workspace. You can see real-time performance metrics, resource utilization, and cluster health in a single view, allowing teams to quickly spot bottlenecks, prevent costly delays, and optimize compute resources. SageMaker HyperPod is also integrated with Amazon CloudWatch Container Insights, providing deeper insights into cluster performance, health, and use. Managed TensorBoard in SageMaker helps you save development time by visualizing the model architecture to identify and remediate convergence issues. Managed MLflow in SageMaker helps you efficiently manage experiments at scale.
Workload scheduling and orchestration
Automatic cluster health check and repair
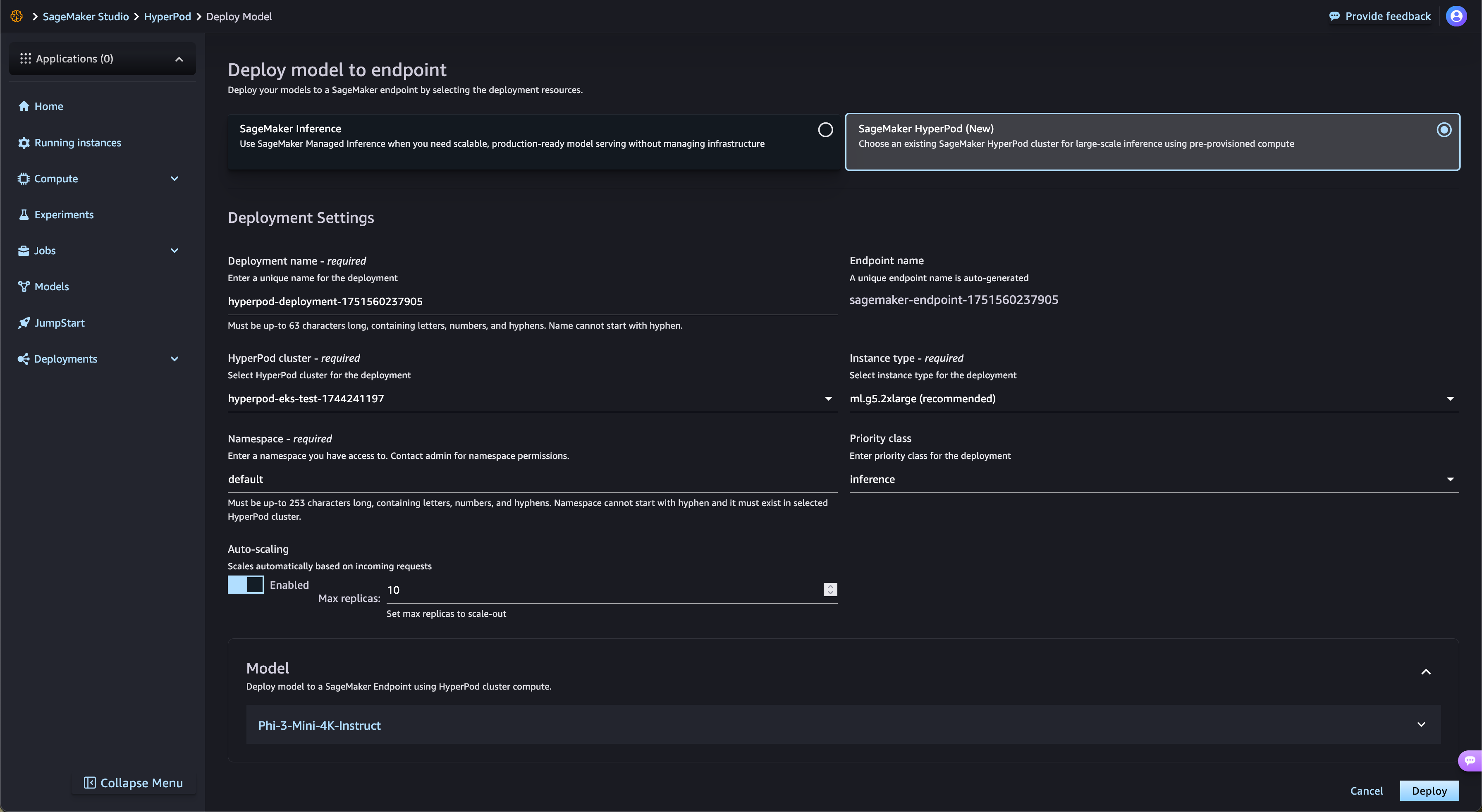
Accelerate open-weights model deployments from SageMaker Jumpstart
SageMaker HyperPod automatically streamlines the deployment of open-weights FMs from SageMaker JumpStart and fine-tuned models from Amazon S3 and Amazon FSx. SageMaker HyperPod automatically provisions the required infrastructure and configures endpoints, eliminating manual provisioning. With SageMaker HyperPod task governance, endpoint traffic is continuously monitored and dynamically adjusts compute resources while simultaneously publishing comprehensive performance metrics to the observability dashboard for real-time monitoring and optimization.
Managed tiered checkpointing
SageMaker HyperPod managed tiered checkpointing uses CPU memory to store frequent checkpoints for rapid recovery, while periodically persisting data to Amazon Simple Storage Service (Amazon S3) for long-term durability. This hybrid approach minimizes training loss and significantly reduces the time to resume training after a failure. Customers can configure checkpoint frequency and retention policies across both in-memory and persistent storage tiers. By storing frequently in memory, customers can recover quickly while minimizing storage costs. Integrated with PyTorch's Distributed Checkpoint (DCP), customers can easily implement checkpointing with only a few lines of code, while gaining the performance benefits of in-memory storage.
Maximize resource utilization with GPU partitioning
SageMaker HyperPod enables administrators to partition GPU resources into smaller, isolated compute units to maximize GPU utilization. You can run diverse generative AI tasks on a single GPU instead of dedicating full GPUs to tasks that only need a fraction of the resources. With real-time performance metrics and resource utilization monitoring across GPU partitions, you gain visibility into how tasks are using compute resources. This optimized allocation and simplified setup accelerates generative AI development, improves GPU utilization, and delivers efficient GPU resource usage across tasks at scale.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages