AWS Partner Network (APN) Blog
Automating Customer Onboarding with Lumiq’s Drishti Document AI and Amazon Textract
By Sampurn Rattan, Lead Data Scientist – Lumiq.ai
By Nieves Garcia, Strategic Initiatives BD – AWS
 |
The fourth industrial revolution is upon us, and the domino effect can be seen in the banking and insurance sector in India.
The Indian BFSI industry (Banking, Financial Services, and Insurance) as a whole is moving towards advanced automation to enhance productivity, achieve cost optimizations on manual efforts, and deliver a seamless customer experience.
The Indian BFSI market specifically is peculiar compared to other regions. Each leg of the insurance process has a long cycle, is riddled with complexity and evolving fraud risk, and has an inordinate amount of customer back-and-forth.
Innovations in artificial intelligence (AI) technologies are yielding novel approaches to automation that fit the Indian market. Lumiq is spearheading such efforts and leveraging deep domain knowledge of the industry and machine learning (ML) to help create solutions for the future, today.
Lumiq is an AWS Advanced Consulting Partner and a full stack data science company that has expertise in data engineering, data science, ML engineering, and MLOps. Lumiq helps enterprises make sense of their data and monetize it in the most optimal manner.
In this post, we’ll showcase how Drishti Document AI, an intelligent document parsing solution built on Amazon Textract, helps optimize and accelerate customer onboarding journeys.
Benefits for BFSI Organizations with AI/ML
Back in 2017, in an Intelligent Document Processing Automation article, McKinsey reported that organizations experimenting with AI were obtaining impressive results, including:
- Automating 50-70 percent of tasks, which had translated into 20-35 percent annual run-rate cost efficiencies.
- Reduction of straight-through process time of 50-60 percent with return on investment (ROI) most often in triple-digit percentages.
In India, we are seeing similar results. For example:
- Achieved 95 percent manual effort reduction in Auto PII Redaction for one of India’s leading life insurance players by automating AADHAAR numbers mandatory masking as per the Supreme Court of India mandate. The first eight digits of all AADHAAR numbers, irrespective of location, are redacted out.
- 67 percent reduction in data entry quality check process post introduction of AI-guided data entry process. Information from Know Your Customer (KYC) documents, handwritten proposal forms, and other relevant documents is extracted and auto-filled into a database, reducing manual labor.
- 90 percent automation of information extraction including tabular data for large private bank in India.
Automating Information Extraction from KYC Documents
For the purposes of this post, we assume you have prerequisite knowledge of AWS services (Amazon Textract, Amazon S3) and conceptual knowledge of ML algorithms.
The BFSI sector is one of the most regulated industries in India, and given the KYC mandate, the customer onboarding process is one of the most document-heavy steps in the industry. Automating instantaneous capture of data from unstructured and structured documents reduced turnaround times and the manual effort required.
KYC documents include application forms and supporting documents, such as government IDs, to validate the information provided in the application form.

Figure 1 – Sample handwritten application form (with dummy data).
Amazon Textract is pre-trained on millions of documents and dozens of document classes. It performs well on both printed and handwritten forms and other documents.
Image Pre-Processing
Pre-processing of documents can have a marked improvement on the quality of Amazon Textract output.
Based on the kind of document scans and images received, Lumiq decided on the following preprocessing steps before sending the documents to Amazon Textract to increase the overall accuracy of the text extraction:
- Document boundary detection using the UNet model.
- Orientation correction using the RotNet architecture.
- Document quality improvements including but not limited to blur reduction and contrast correction.
Text Post-Processing
Lumiq also perform post-processing on the results provided by Amazon Textract, such as post-OCR (optical character recognition) correction with domain knowledge. For example, based on Lumiq’s expertise in the insurance domain, if Amazon Textract gives us “police,” then we can be sure it’s in fact “policy” and correct for the same.
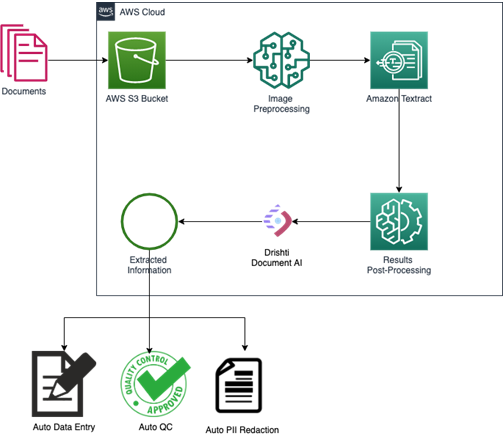
Figure 2 – Lumiq Document AI Engine solution architecture.
Information Extraction
The Lumiq Document AI Engine uses a novel deep learning architecture that takes as input not only the text extracted (from Amazon Textract), but also the interactions between text and the layout information. This is beneficial for a great number of real-world document image understanding tasks, such as information extraction from scanned documents.
The engine also uses image features such as font size, font-weight, font-family, and underlining to incorporate as much visual context as possible. This allows information to be extracted as easy-to-use key-value pairs directly from the document.
The extracted information can be used for multiple use cases, including automated data entry, auto data quality check, and auto Personal Identifiable Information (PII) redaction.
The solution has an overall accuracy of more than 95 percent:
- Unlike most OCR tools which are template-based, Amazon Textract is template-agnostic, and allows Lumiq Document AI Engine to be truly template-agnostic.
- Amazon Textract can capture checkboxes and radio button selections.
- The underlying Lumiq Document AI model keeps learning as more data is processed and progressively keeps improving the accuracy.
Key Takeaways
With the Lumiq Document AI Engine’s proprietary AI/ML techniques, you can achieve 95 percent accuracy and unlock a field-level confidence score divided into green (>95 percent), yellow (60-95 percent), and red zones (<60 percent). This allows any data entry and quality check (DEQC) operator to focus on just the poor quality (yellow and red) extractions enabling quick corrections in case required.
Following the template-agnostic philosophy, once the AI engine has “seen” a document class, it can extract information from any variant, and any template of that document class with little to no drop in accuracy levels.
The Lumiq Document AI Engine has a broad and varied catalog of document classes on which it’s trained on. To add new document classes to the catalog, the engine needs to be trained on as low as 50 documents, with a model training time of less than 24 hours.
Accuracy levels for other document classes won’t decrease in the slightest, and for the new document class you can see an initial accuracy greater than 95 percent. Accuracy improves as the engine sees more documents of the new class.
Conclusion
Rapid, relevant, and correct customer service is the cornerstone of all successful businesses.
“Customer onboarding processes across industries involve large amounts of document processing and, in most scenarios, the automation is limited to text extraction or OCR,” says Shoaib Mohammad, Lumiq’s CEO and Founder.
“Lumiq’s Drishti Document AI enables accurate text extraction and provides a high level of AI-driven business process automation, leading to high savings in terms of human effort, reduced turnaround time, and most importantly elevated customer experience.”
The Drishti Document AI engine is modular and portable: it can be deployed in-situ, which means in the field agent’s device itself.
- If there is any discrepancy in the documents (and information) provided by the customer, the agent can request clearer documents on the spot. This reduces to-and-fro between the DEQC operator and customer, reducing the onboarding time and preventing any embitterment on part of the customer.
- Furthermore, for any straight-through-processing applications, which are generally small-risk tickets, all rules and validations can be processed onsite and such applications can be cleared in minutes.
- If the device has access to historical data, deduplication of existing customers can be done at the time of onboarding itself.
- Multiple other use cases can be addressed, limited only by the imagination of the business.
You can learn more about Lumiq’s intelligent document processing capabilities and Drishti Document AI, as well as how you can build an end-to-end intelligent document processing solution using AWS.
.

.
Lumiq – AWS Partner Spotlight
Lumiq is an AWS Advanced Consulting Partner and data analytics company that powers end-to-end data-driven decision making and intelligent automation on AWS.
Contact Lumiq | Partner Overview
*Already worked with Lumiq? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.