Artificial Intelligence
Building an end-to-end intelligent document processing solution using AWS
July 2023: This post was reviewed and updated for accuracy. The AWS CloudFormation template was updated.
As organizations grow larger in size, so does the need for having better document processing. In industries such as healthcare, legal, insurance, and banking, the continuous influx of paper-based or PDF documents (like invoices, health charts, and insurance claims) have pushed businesses to consider evolving their document processing capabilities. In such scenarios, businesses and organizations find themselves in a race against time to deploy a sophisticated document analysis pipeline that can handle these documents in an automated and scalable fashion.
You can use Amazon Textract and Amazon Augmented AI (Amazon A2I) to process critical documents and for your NLP-based entity recognition models with Amazon SageMaker Ground Truth, Amazon Comprehend, and Amazon A2I. This post introduces another way to create a retrainable end-to-end document analysis solution with Amazon Textract, Amazon Comprehend, and Amazon A2I.
This solution takes scanned images of physical documents as input and extracts the text using Amazon Textract. It sends the text to be analyzed by a custom entity recognizer trained in Amazon Comprehend. Machine Learning applications such as Amazon Comprehend work really well at scale, and in order to achieve 100% accuracy, you can use human reviewers to review and validate low confidence predictions. Additionally, you can use this human input to improve your underlying machine learning models. This is done by sending the output from Amazon Comprehend to be reviewed by human reviewers using Amazon A2I so that you can feed it back to retrain the models and improve the quality for future iterations. You can also use Amazon A2I to provide human oversight to your machine learning models and randomly send some data for human review to sample the output quality of your custom entity recognizer. This automated pipeline can scale to millions of documents with the help of these services and allow businesses to do more detailed analysis of their documents.
Solution overview
The following diagram illustrates the solution architecture.
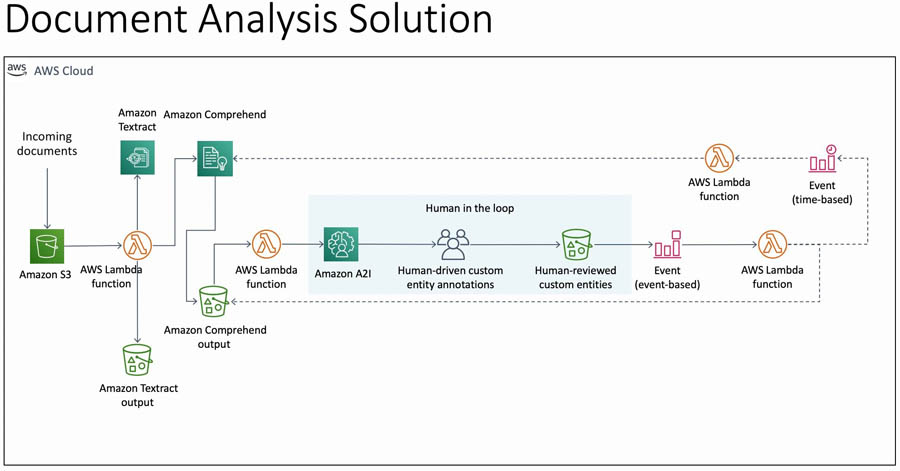
This solution takes images (scanned documents or screenshots or pictures of documents) as input. You can upload these files programmatically or through the AWS Management Console into an Amazon Simple Storage Service (Amazon S3) bucket in the input folder. This action triggers an AWS Lambda function, TextractComprehendLambda, through event notifications.
The TextractComprehendLambda function sends the image to Amazon Textract to extract the text from the image. When it acquires the results, it collates the results and sends the text to the Amazon Comprehend custom entity recognizer. The custom entity recognizer is a pre-trained model that identifies entities in the text that are valuable to your business. This post demonstrates how to do this, in detail, in the following sections.
The custom entity recognizer stores the results in a separate bucket, which acts as a temporary storage for this data. This bucket has another event notification, which triggers the ComprehendA2ILambda function. This Lambda function takes the output from the custom entity recognizer, processes it, and send the results to Amazon A2I by creating a human loop for review and verification.
Amazon A2I starts the human loop, providing reviewers an interface to double-check and correct the results that may not have been identified in the custom entity recognition process. These reviewers submit their responses through the Amazon A2I worker console. When the human loop is complete, Amazon A2I sends an Amazon CloudWatch event, which triggers the HumanReviewCompleted Lambda.
The HumanReviewCompleted function checks if the human reviewers have added any more annotations (because they found more custom entities). If the human reviewers found something that the custom entity recognizer missed, the function creates a new file called updated_entity_list.txt. This file contains all the entities that weren’t present in the previous training dataset.
At the end of each day, a CloudWatch alarm triggers the NewEntityCheck function. This function compares the entity_list.txt file and the updated_entity_list.txt file to check if any new entities were added in the last day. If so, it starts a new Amazon Comprehend custom entity recognizer training job and enables the CloudWatch time-based event trigger that triggers the CERTrainingCompleteCheck function every 15 minutes.
The CERTrainingCompleteCheck function checks if the Amazon Comprehend custom entity recognizer has finished training. If so, the function adds the entries from updated_entity_list.txt to entity_list.txt so it doesn’t train the model again, unless even more entities are found by the human reviewers. It also disables its own CloudWatch time-based event trigger, because it doesn’t need to check the training process until it starts again. The next invocation of the TextractComprehend function uses the new custom entity recognizer, which has learned from the previous reviews of the humans.
All these Lambda functions use AWS Systems Manager Parameter Store for sharing, retaining, and updating the various variables, like which custom entity recognizer is the current one and where all the data is stored.
We demonstrate this solution in the us-east-1 Region but, you can run it in any compatible Region. For more information about availability of services in your Region, see the AWS Region Table.
Prerequisites
This post requires that you have an AWS account with appropriate AWS Identity and Access Management (IAM) permissions to launch the AWS CloudFormation template.
Deploying your solution
To deploy your solution, you complete the following high-level steps:
- Create an S3 bucket.
- Create a custom entity recognizer.
- Create a human review workflow.
- Deploy the CloudFormation stack.
Creating an S3 bucket
You first create the main bucket for this post. You use it to receive the input (the original scans of documents), and store the outputs for each step of the analysis. The Lambda functions pick up the results at the end of each state and collate them for further use and record-keeping. For instructions on creating a bucket, see Create a Bucket.
Capture the name of the S3 bucket and save it to use later in this walkthrough. We refer this bucket as <primary_bucket> in this post. Replace this with the name of your actual bucket as you follow along.
Creating a custom entity recognizer
Amazon Comprehend allows you to bring your own training data, and train custom entity recognition models to customize the entity recognition process to your business-specific use cases. You can do this without having to write any code or have any in-house machine learning (ML) expertise. For this post, we provide a training dataset and document image, but you can use your own datasets when customizing Amazon Comprehend to suit your use case.
- Download the training dataset.
- Locate the bucket you created on the Amazon S3 console.
For this post, we use the bucket textract-comprehend-a2i-data-us-east-1, but you should use the name that you used for <primary_bucket>.

- Open the bucket and choose Create folder.
- For name, enter
comprehend_data.

- Uncompress the file you downloaded earlier and upload the files to the
comprehend_datafolder.

- On the Amazon Comprehend console, click on Launch Amazon Comprehend.

- Under Customization, choose Custom entity recognition.
- Click on Create new model.

- For Recognizer name, enter a name.
The name that you choose appears in the console hereafter, so something human readable and easily identifiable is ideal.
- For Custom entity types, enter your custom entity type (for this post, we enter
DEVICE).
At the time of this writing, you can have up to 25 entity types per custom entity recognizer in Amazon Comprehend.

- In the Training data section, select Using entity list and training docs.
- Add the paths to
entity_list.csvandraw_txt.csvfor your <primary_bucket>.

- In Test dataset – new section, leave Autosplit checked.
- In the IAM role section, select Create a new role.
- For Permissions to access, select “Training, test, and output data (if specified) in your S3 buckets” in the drop-down menu.
- For Name suffix, enter a suffix you can identify later (for this post, we enter
TDA). - Leave the remaining settings as default and choose Create.

- When the training is complete, choose your recognizer and copy the ARN for your custom entity recognizer for future use.

Creating a human review workflow
To create a human review workflow, you need to have three things ready:
- Reviewing workforce – A work team is a group of people that you select to review your documents. You can create a work team from a workforce, which is made up of Amazon Mechanical Turk workers, vendor-managed workers, or your own private workers that you invite to work on your tasks. Whichever workforce type you choose, Amazon A2I takes care of sending tasks to workers. For this post, you create a work team using a private workforce and add yourself to the team to preview the Amazon A2I workflow.
- Worker task template – This is a template that defines what the console looks like to the reviewers.
- S3 bucket – This is where the output of Amazon A2I is stored. You already created a bucket earlier, so this post uses the same bucket.
Creating a workforce
To create and manage your private workforce, you can use the Labeling workforces page on the Amazon SageMaker console. When following the instructions, you can create a private workforce by entering worker emails or importing a pre-existing workforce from an Amazon Cognito user pool.
If you already have a work team, you can use the same work team with Amazon A2I and skip to the following section.
To create your private work team, complete the following steps:
- Navigate to the Labeling workforces page on the Amazon SageMaker console.
- On the Private tab, choose Create private team.

- Choose Invite new workers by email.
- For this post, enter your email address to work on your document processing tasks.
You can enter a list of up to 50 email addresses, separated by commas, into the Email addresses box.
- Enter an organization name and contact email.
- Choose Create private team.

- After you create a private team, choose the Workers tab to invite new workers to your private workforce.
- On the Workers tab, choose Invite new workers.

- Enter the email addresses you want to add and choose Invite new workers.

After you add the workers (in this case, yourself), you get an email invitation. The following screenshot shows an example email.

After you choose the link and change your password, you’re registered as a verified worker for this private workforce. Choose the team to add new workers to your team. Your team is ready to review.

- Choose the link for Labeling Portal Sign-in URL and log in using the credentials generated in the previous step.

You should see a page similar to the following screenshot.

This is the Amazon A2I worker portal.
Creating a worker task template
You can use a worker template to customize the interface and instructions that your workers see when working on your tasks. To create a worker task template, complete the following steps:
- Navigate to the Worker task templates page on the Amazon SageMaker console.
For this post, we use Region us-east-1. For availability details for Amazon A2I and Amazon Translate in your preferred Region, see the AWS Region Table.
- Choose Create template.

- For Template name, enter
translate-a2i-template.

- In the Template editor field, enter the code from the following task-template.html.zip file:
- Choose Create

Creating a human review workflow
Human review workflows allow human reviewers to audit the custom entities that are detected using Amazon Comprehend on an ongoing basis. To create a human review workflow, complete the following steps:
- Navigate to the Human review workflow page the Amazon SageMaker console.
- Choose Create human review workflow.

- In the Workflow settings section, for Name, enter a unique workflow name.
- For S3 bucket, enter the S3 bucket where you want to store the human review results.
For this post, we use the same bucket that we created earlier, but add the suffix /a2i-raw-output. For example, if you created a bucket called textract-comprehend-a2i-data-us-east-1, enter the path s3://textract-comprehend-a2i-data-us-east-1/a2i-raw-output. This subfolder contains the edits that the reviewers make in all the human review workflow jobs that are created for Amazon Comprehend custom entity recognition. (Replace the bucket name with the value of <primary_bucket>)
- For IAM role, choose Create a new role from the drop-down menu.

Amazon A2I can create a role automatically for you.
- For S3 buckets you specify, select Specific S3 buckets.
- Enter the name of the S3 bucket you created earlier (<primary_bucket>).
- Choose Create.

You see a confirmation when role creation is complete and your role is now pre-populated in the IAM role drop-down menu.

- For Task type, select Custom.

- In the Worker task template section, for Template, choose custom-entity-review-template.
- For Task description, add a description that briefly describes the task for your workers.

- In the Workers section, select
- For Private teams, choose textract-comprehend-a2i-review-team.
- Choose Create.

You see a confirmation when human review workflow creation is complete.

Copy the workflow ARN and save it somewhere. You need this in the upcoming steps. You also need to keep the Amazon A2I Worker Portal (created earlier) open and ready after this step.
Deploying the CloudFormation stack
Launch the following CloudFormation stack to deploy the stack required for running the entire flow:
![]()
This creates the remaining elements for running your human review workflow for the custom entity recognizer. When creating the stack, enter the following values:
- CustomEntityRecognizerARN – The ARN for the custom entity recognizer.
- CustomEntityTrainingDatasetS3URI – The path to the training dataset that you used for creating the custom entity recognizer.
- CustomEntityTrainingListS3URI – The path to the entity list that you used for training the custom entity recognizer.
- FlowDefinitionARN – The ARN of the human review workflow.
- S3BucketName – The name of the bucket you created.
- S3ComprehendBucketName – A random name that must be unique so the template can create an empty S3 bucket to store temporary output from Amazon Comprehend in. You don’t need to create this bucket—the Cloudformation template does that for you, just provide a unique name here.

Choose the defaults of the stack deployment wizard. On the Review page, in the Capabilities and transforms section, select the three check-boxes and choose Create stack.

You can do so by navigating to the AWS CloudFormation console and looking for the stack you just launched.
When the status of the stack changes to CREATE_COMPLETE, you have successfully deployed the document analysis solution to your account.
Testing the solution
You can now test the end-to-end flow of this solution. To test each component, you complete the following high-level steps:
- Upload a file.
- Verify the Amazon Comprehend job status.
- Review the worker portal.
- Verify the changes were recorded.
Uploading a file
In real-world situations, when businesses receive a physical document, they scan, photocopy, email, or upload it to some form of an image-based format for safe-keeping as a backup mechanism. The following is the sample document we use in this post.

To upload the file, complete the following steps:
- Download the image.
- On the Amazon S3 console, navigate to your <primary_bucket>.
- Choose Create folder.
- For Name, enter
input. - Choose Create Folder.

- Upload the image you downloaded into this folder.

This upload triggers the TextractComprehendA2ILambda function, which sends the uploaded image to Amazon Textract and sends the response received from Amazon Comprehend.
Verifying Amazon Comprehend job status
You can now verify that the Amazon Comprehend job is working.
- On the Amazon Comprehend console, choose Analysis jobs.
- Verify that your job is in status
In progress.

When the status switches to Completed, you can proceed to the next step.

Reviewing the worker portal
You can now test out the human review worker portal.
- Navigate to the Amazon A2I worker portal that you created.
You should have a new job waiting to be processed.
- Select the job and choose Start working.

You’re redirected to the review screen.

- Tag any new entities that the algorithm missed.
- When you’re finished, choose Submit.

Verify that the changes were recorded
Now that you have added your inputs in the A2I console, the HumanWorkflowCompleted Lambda function adds the identified entities to the already existing file and stores it in a separate entity list in the S3 bucket. You can verify that this has happened by navigating to <primary_bucket> on the Amazon S3 console.
In the folder comprehend_data, you should see a new file called updated_entity_list.csv.

The NewEntityCheck Lambda function uses this file at the end of each day to compare against the original entity_list.csv file. If new entities are in the updated_entity_list.csv file, the model is retrained and replaces the older custom entity recognition model.
This allows the Amazon Comprehend custom entity recognition model to improve continuously by incorporating the feedback received from human reviewers through Amazon A2I. Over time, this can reduce the need for reviewers and manual intervention by analyzing documents in a more intelligent and sophisticated manner.
Cost
With this solution, you can now process scanned and physical documents at scale and do ML-powered analysis on them. The cost to run this example is less than $5.00. For more information about exact costs, see Amazon Textract pricing, Amazon Comprehend pricing, and Amazon A2I pricing.
Cleaning up
To avoid incurring future charges, delete the resources when not in use.
Conclusion
This post demonstrated how you can build an end-to-end document analysis solution for analyzing scanned images of documents using Amazon Textract, Amazon Comprehend, and Amazon A2I. This allows you to create review workflows for the critical documents you need to analyze using your own private workforce, and provides increased accuracy and context.
This solution also demonstrated how you can improve your Amazon Comprehend custom entity recognizer over time by retraining the models on the newer entities that the reviewers identify.
For the code used in this walkthrough, see the GitHub repo. For information about adding another review layer for Amazon Textract using Amazon A2I, see Using Amazon Textract with Amazon Augmented AI for processing critical documents.
About the Authors
 Purnesh Tripathi is an Account Director based out of New Zealand. He has been a data scientist and architect in his previous life, and is passionate about the benefits that Machine Learning and Artificial Intelligence can bring to a business. He works with Digital Native Businesses and helps them bring Kiwi innovation to world using AWS.
Purnesh Tripathi is an Account Director based out of New Zealand. He has been a data scientist and architect in his previous life, and is passionate about the benefits that Machine Learning and Artificial Intelligence can bring to a business. He works with Digital Native Businesses and helps them bring Kiwi innovation to world using AWS.
 Carmela Gambardella is a Sr Solutions Architect at AWS Italy Public Sector. Graduated in Computer Science at the Federico II University of Naples, she has worked with different roles in large IT companies. Main areas of interest: data protection, security and compliance, application security, software engineering. In April 2018, she joined the Solutions Architect – Public Sector team in Italy.
Carmela Gambardella is a Sr Solutions Architect at AWS Italy Public Sector. Graduated in Computer Science at the Federico II University of Naples, she has worked with different roles in large IT companies. Main areas of interest: data protection, security and compliance, application security, software engineering. In April 2018, she joined the Solutions Architect – Public Sector team in Italy.
 Elisabetta Castellano is Solutions Architect at Amazon Web Services. She works with customers providing guidance and best practices to design, deploy and manage workloads and applications in the AWS Cloud. Her focus area is Artificial Intelligence and Machine Learning, with the aim of democratizing its adoption, helping customers to develop solutions to business problems with AI and ML.
Elisabetta Castellano is Solutions Architect at Amazon Web Services. She works with customers providing guidance and best practices to design, deploy and manage workloads and applications in the AWS Cloud. Her focus area is Artificial Intelligence and Machine Learning, with the aim of democratizing its adoption, helping customers to develop solutions to business problems with AI and ML.