AWS Partner Network (APN) Blog
How to Tier Your Data in MongoDB Atlas to Reduce Storage Costs
By Benjamin Flast, Sr. Product Manager – MongoDB
 |
| MongoDB |
 |
Customers often reach out to our team at MongoDB to ask, “How can I control my data storage costs?”
With the proliferation of different, constantly changing applications, it’s become a challenge to innovate quickly while at the same time having a strategy in place to prevent ballooning storage costs.
Legacy archival and analytic tools often restrict developers and diminish the benefits of NoSQL’s handling of modern, rich data sources.
Developers and data engineers are often asked to apply strict schemas to data when migrating it into relational analytic tools. The need to bring in separate tooling or write your own to manage growing data volumes reduces agility and adds costs.
These customer challenges are top of mind for MongoDB, an AWS Data and Analytics Competency Partner. We are constantly coming up with new ways for customers to optimize their total cost of ownership (TCO) while allowing them to benefit from the flexibility of the document model.
Application teams are being asked to “do more” around analytics and data tiering. The requirements to manage an appropriate TCO and provide for new workloads while shielding existing use-case performance requirements continues to grow.
MongoDB is committed to making it easier for customers to scale and transform their data management solutions to make developers’ lives easier. I’m going to share three ways we do this in MongoDB Atlas.
Deleting Data? Are You Crazy?
Before I dive into possible solutions, let’s talk about deleting data. Often, we see developers in a situation where they’re quickly approaching some data limit event without having planned for the situation.
In these instances, it sometimes becomes necessary to delete data using bulk delete or a TTL index to prevent an outage or other operational impact. This is a worst-case scenario. Data is the life blood of today’s organizations, and it’s rarely advantageous for a company to delete it.
In MongoDB Atlas, there are simple alternatives to deleting your data.
Utilizing MongoDB Tools Like mongodump and mongoexport
Historically, customers have used tools like mongodump and mongoexport to solve data growth challenges.
It can be an effective solution to set up some automation using one of these tools to drop data into cloud object storage like Amazon Simple Storage Service (Amazon S3) for retrieval in the future, or for consumption by some other tool.
Here is an example of data export into JSON format using mongoexport:
The benefits of this approach are a fairly unparalleled level of flexibility around structure and cadence of data exfiltration. But it comes with a cost—these solutions need to be custom developed, maintained, and the underlying infrastructure managed and monitored.
The upfront development resources and ongoing costs can add up; over time, this can impede innovation. Maybe most significantly, they will not benefit from improvements continually being made to fully managed solutions.
While using these tools were historically a popular way of getting data out of MongoDB, I’m going to share two alternative, built-in solutions that are more cost effective and productive.
Automated Data Tiering with MongoDB Atlas Online Archive
While mongodump and mongoexport are great ways to get data out of your Atlas cluster, they don’t offer a fully managed and automated solution. In order to automate export of data, you would need to set up your own infrastructure, which then requires care and feeding.
It was with these challenges in mind that we designed MongoDB Atlas Online Archive. This allows you to take advantage of a fully managed solution for data tiering right in Atlas. You can create rules to automatically archive aged data to fully managed object storage, while preserving the ability to query all of your data through a single endpoint.
When you set up Online Archive in MongoDB Atlas, behind the scenes we:
- Set up a fully managed archival process on the cluster based on the archival rule you specified. The process runs every five minutes and archives up to two GB of data or 10,000 partitions. Data can be archived based on a date-based rule or on a custom filter you specify.
- The archive service then monitors your cluster over time. When data becomes eligible for archival, it begins to copy it out of the cluster and writes it to cloud object storage managed by MongoDB. Your data then gets deleted from your cluster once it’s in the Online Archive.
- We’ve created a variety of safeguards for this process to ensure your data is never lost and is only deleted from the cluster once we’ve verified it has been written to the archive.
- After your data is archived, you can query it at any time alongside your live cluster data using a single connection string.
How Nesto Software Reduced Storage Costs with Atlas Online Archive
To demonstrate how this works in practice, I’ll share how Nesto Software was able to reduce storage costs by 60% with MongoDB Atlas Online Archive.
The German-based startup powers a platform for hospitality management. It uses artificial intelligence (AI) to forecast staffing requirements and automate common tasks like time management and tracking of employee records.
Nesto was running its platform on MongoDB Atlas and looking for a data tiering solution that would allow it to comply with local data protection regulations, namely GDPR.
The team at Nesto had initially built a read auditing solution in Atlas to comply with the regulation, where each document mapped to a read audit log. Within a single year, the audit collection had reached over 50 million documents, making up nearly 80% of all storage and backup costs.
The team decided to set up an Online Archive to offload data to more cost-effective storage while retaining the ability to query their data; a requirement under GDPR. Today, Nesto has an archiving rule on any data older than 14 days, translating to approximately six million documents archived per month.
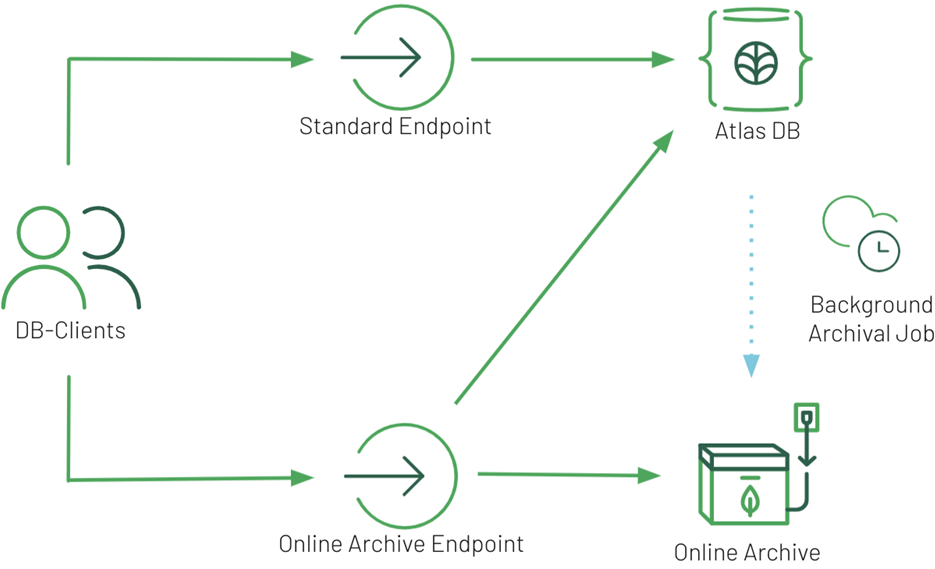
Figure 1 – Nesto Software architecture diagram.
With Online Archive, Nesto saved 60% in data storage costs and 70% in cloud backup costs. This represents a reduction of 35% on overall database spend.
“It was simple to deploy Online Archive and create a low-cost cold storage environment for data, which automates archiving and tiering from live clusters into fully managed storage,” says Martin Löper, a solutions architect at Nesto. “It’s an affordable, reliable, and scalable way to manage our growing data needs.”
To learn more about Online Archive, check out the documentation.
MongoDB Atlas Data Lake and Amazon S3
Another effective approach for easily offloading aged data is to take advantage of MongoDB Atlas Data Lake. This is a serverless, scalable query engine that makes it easy to work with data across MongoDB Atlas and Amazon S3.
In addition to providing powerful analytic capabilities, it offers a great alternative to Online Archive for data tiering. For customers looking to archive data to their own S3 buckets rather than fully managed storage, Data Lake is a great solution.
The archival process through Data Lake can be set up and automated using Scheduled Triggers, and data can even be written directly into Parquet format on S3 for improved future query performance.
You can configure your Data Lake to include Atlas clusters and S3 as sources, making it easy to move data and federate queries for fast insights.
Here’s an example of data archival to Data Lake using Scheduled Triggers:
In the example above, you can see the sample text for a scheduled Atlas trigger. It’s running on a schedule that has been specified and is doing a few tasks:
- Connecting to your Data Lake service, which is already connected to your S3 and Atlas cluster.
- “Matching” all data from the past hour using the MongoDB aggregation pipeline. We woud run this trigger every hour to get the past hours’ worth of data.
- Writing that data to your S3 bucket and doing two important formatting operations:
- In the “filename” field, you can see we are utilizing a field from the documents entering S3. That means that if we had a field like “age,” we’d write everyone who is 23 into one partition and everyone who is 56 into another partition. This becomes relevant for future query performance through the Data Lake.
- The other interesting piece is that in the “format” field we are writing in Parquet. For those of you not familiar with Parquet, it’s a powerful file format that’s highly compressible and stores metadata about the information stored in the file, which can have great benefits for query performance as well.
To learn more about MongoDB Atlas Data Lake and find step-by-step tutorials, check out the documentation.
Summary
There are many ways to manage your data footprint on MongoDB Atlas, and all of the options highlighted in this post are designed to keep you as productive as possible.
You can use Online Archive to automatically move data to fully managed, queryable storage, or leverage the power of Atlas Data Lake to archive data to your own Amazon S3 buckets.
With MongoDB’s application data platform, we’re looking to simplify how you work with all of your cloud data so you can spend less time managing infrastructure and more time accelerating development.
Sign up for Atlas and get set up using Atlas Online Archive or Atlas Data Lake in just a few minutes.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
MongoDB – AWS Partner Spotlight
MongoDB is an AWS Competency Partner. Their modern, general purpose database platform is designed to unleash the power of software and data for developers and the applications they build.
Contact MongoDB | Partner Overview | AWS Marketplace
*Already worked with MongoDB? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.