AWS News Blog
Fast, Easy, Free Data Sync from RDS MySQL to Amazon Redshift

|
As you know, I’m a big fan of Amazon RDS. I love the fact that it allows you focus on your applications and not on keeping your database up and running. I’m also excited by the disruptive price, performance, and ease of use of Amazon Redshift, our petabyte-scale, fully managed data warehouse service that lets you get started for $0.25 per hour and costs less than $1,000 per TB per year. Many customers agree, as you can see from recent posts by Pinterest, Monetate, and Upworthy.
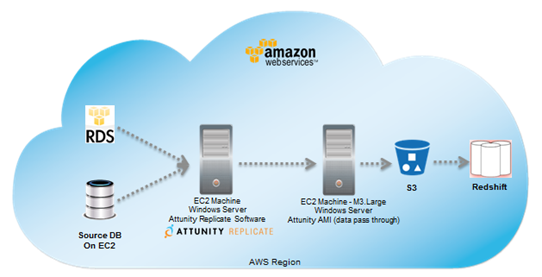
Many AWS customers want to get their operational and transactional data from RDS into Redshift in order to run analytics. Until recently, it’s been a somewhat complicated process. A few week ago, the RDS team simplified the process by enabling row-based binary logging, which in turn has allowed our AWS Partner Network (APN) partners to build products that continuously replicate data from RDS MySQL to Redshift.
Two APN data integration partners, FlyData and Attunity, currently leverage row-based binary logging to continuously replicate data from RDS MySQL to Redshift. Both offer free trials of their software in conjunction with Redshift’s two month free trial. After a few simple configuration steps, these products will automatically copy schemas and data from RDS MySQL to Redshift and keep them in sync. This will allow you to run high performance reports and analytics on up-to-date data in Redshift without having to design a complex data loading process or put unnecessary load on your RDS database instances.
If you’re using RDS MySQL 5.6, you can replicate directly from your database instance by enabling row-based logging, as shown below. If you’re using RDS MySQL 5.5, you’ll need to set up a MySQL 5.6 read replica and configure the replication tools to use the replica to sync your data to Redshift. To learn more about these two solutions, see FlyData’s Free Trial Guide for RDS MySQL to Redshift as well as Attunity’s Free Trial and the RDS MySQL to Redshift Guide. Attunity’s trial is available through the AWS Marketplace, where you can find and immediately start using software with Redshift with just a few clicks.
Informatica and SnapLogic also enable data integration between RDS and Redshift, using a SQL-based mechanism that queries your database to identify data to transfer to your Amazon Redshift clusters. Informatica is offering a 60-day free trial and SnapLogic has a 30 day free trial.
All four data integration solutions discussed above can be used with all RDS database engines (MySQL, SQL Server, PostgreSQL, and Oracle). You can also use AWS Data Pipeline (which added some recent Redshift enhancements), to move data between your RDS database instances and Redshift clusters. If you have analytics workloads, now is a great time to take advantage of these tools and begin continuously loading and analyzing data in Redshift.
Enabling Amazon RDS MySQL 5.6 Row Based Logging
Here’s how you enable row based logging for MySQL 5.6:
- Go to the Amazon RDS Console and click Parameter Groups in the left pane:
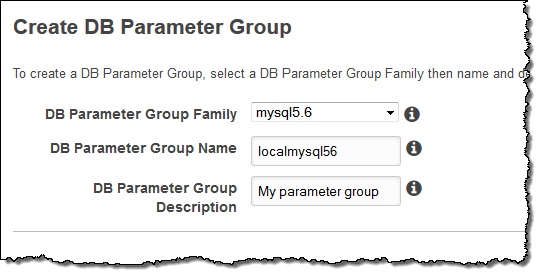
- Click on the Create DB Parameter Group button and create a new parameter group in the mysql5.6 family:
- Once in the detail view, click the Edit Parameters button. Then set the
binlog_formatparameter toROW: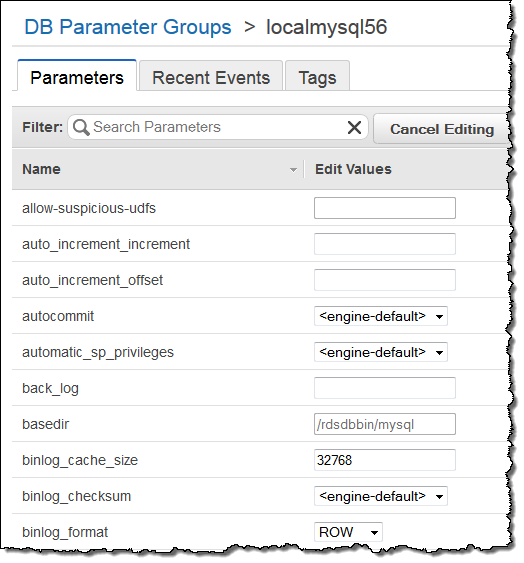
For more details please see Working with MySQL Database Log Files.
Free Trials for Continuous RDS to Redshift Replication from APN Partners
FlyData has published a step by step guide and a video demo in order to show you how to continuously and automatically sync your RDS MySQL 5.6 data to Redshift and you can get started for free for 30 days. You will need to create a new parameter group with binlog_format set to ROW and binlog_checksum set to NONE, and adjust a few other parameters as described in the guide above.
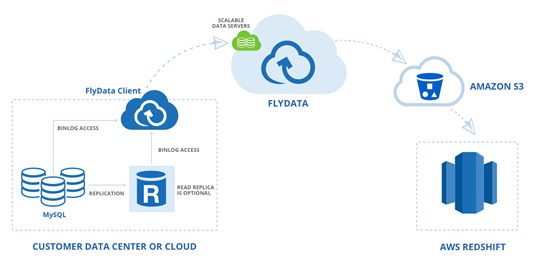
AWS customers are already using FlyData for continuous replication to Redshift from RDS. For example, rideshare startup Sidecar seamlessly syncs tens of millions of records per day to Redshift from two RDS instances in order to analyze how customers utilize Sidecar’s custom ride services. According to Sidecar, their analytics run 3x faster and the near-real-time access to data helps them to provide a great experience for riders and drivers. Here’s the data flow when using FlyData:
Attunity CloudBeam has published a configuration guide that describes how you can enable continuous, incremental change data capture from RDS MySQL 5.6 to Redshift (you can get started for free for 5 days directly from the AWS Marketplace. You will need to create a new parameter group with binlog_format set to ROW and binlog_checksum set to NONE.
For additional information on configuring Attunity for use with Redshift please see this quick start guide.
Redshift Free Trial
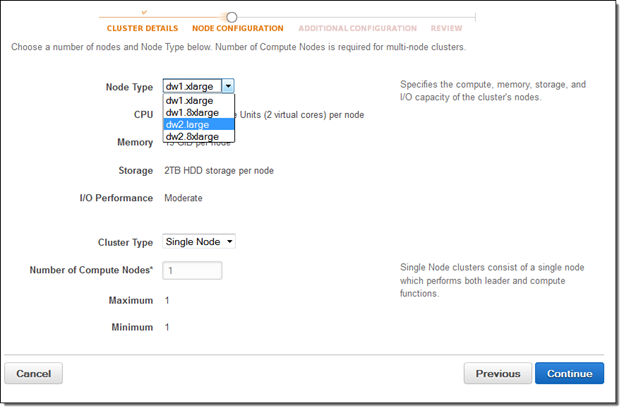
If you are new to Amazon Redshift, you’re eligible for a free trial and can get 750 free hours for each of two months to try a dw2.large node (16 GB of RAM, 2 virtual cores, and 160 GB of compressed SSD storage). This gives you enough hours to continuously run a single node for two months. You can also build clusters with multiple dw2.large nodes to test larger data sets; this will consume your free hours more quickly. Each month’s 750 free hours are shared across all running dw2.large nodes in all regions.
To start using Redshift for free, simply go to the Redshift Console, launch a cluster, and select dw2.large for the Node Type:
Big Data Webinar
If you want to learn more, do not miss the AWS Big Data Webinar showcasing how startup Couchsurfing used Attunitys continuous CDC to reduce their ETL process from 3 months to 3 hours and cut costs by nearly $40K.
— Jeff;