AWS Big Data Blog
Achieve 2x faster data lake query performance with Apache Iceberg on Amazon Redshift
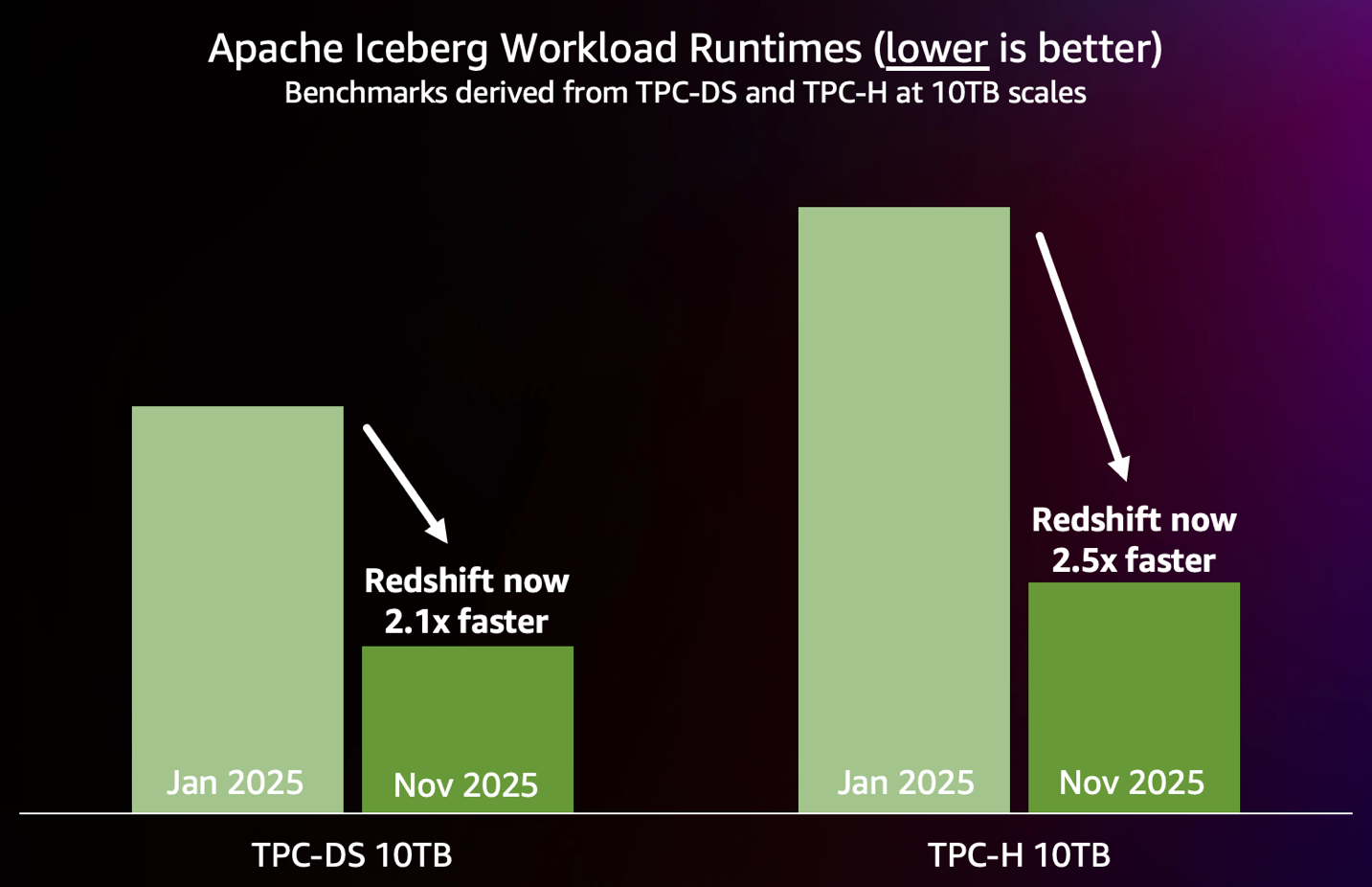
With the growing adoption of open table formats like Apache Iceberg, Amazon Redshift continues to advance its capabilities for open format data lakes. In 2025, Amazon Redshift delivered several performance optimizations that improved query performance over twofold for Iceberg workloads on Amazon Redshift Serverless, delivering exceptional performance and cost-effectiveness for your data lake workloads.
In this post, we describe some of the optimizations that led to these performance gains. Data lakes have become a foundation of modern analytics, helping organizations store vast amounts of structured and semi-structured data in cost-effective data formats like Apache Parquet while maintaining flexibility through open table formats. This architecture creates unique performance optimization opportunities across the entire query processing pipeline.
Performance enhancements
Our latest enhancements span multiple areas of the Amazon Redshift SQL query processing engine, including vectorized scanners that accelerate execution, optimal query plans powered by just-in-time (JIT) runtime statistics, distributed Bloom filters, and new decorrelation rules.
The following chart summarizes the performance improvements achieved so far in 2025, as measured by industry standard 10 TB TPC-DS and TPC-H benchmarks run on Iceberg tables on an 88 RPU Redshift Serverless endpoint.
Find the best performance for your workloads
The performance results presented in this post are based on benchmarks derived from the industry-standard TPC-DS and TPC-H benchmarks, and have the following characteristics:
- The schema and data of Iceberg tables are used unmodified from TPC-DS. Tables are partitioned to reflect real-world data organization patterns.
- The queries are generated using the official TPC-DS and TPC-H kits with query parameters generated using the default random seed of the kits.
- The TPC-DS test includes all 99 TPC-DS SELECT queries. It doesn’t include maintenance and throughput steps. The TPC-H test includes all 22 TPC-H SELECT queries.
- Benchmarks are run out of the box: no manual tuning or stats collection is done for the workloads.
In the following sections, we discuss key performance improvements delivered in 2025.
Faster data lake scans
To improve data lake read performance, the Amazon Redshift team built a completely new scan layer designed from the ground-up for data lakes. This new scan layer includes a purpose-built I/O subsystem, incorporating smart prefetch capabilities to reduce data latency. Additionally, the new scan layer is optimized for processing Apache Parquet files, the most commonly used file format for Iceberg, through fast vectorized scans.
This new scan layer also includes sophisticated data pruning mechanisms that operate at both partition and file levels, dramatically reducing the volume of data that needs to be scanned. This pruning capability works in harmony with the smart prefetch system, creating a coordinated approach that maximizes efficiency throughout the entire data retrieval process.
JIT ANALYZE for Iceberg tables
Unlike traditional data warehouses, data lakes often lack comprehensive table- and column-level statistics about the underlying data, making it challenging for the planner and optimizer in the query engine to choose up-front which execution plan will be most optimal. Sub-optimal plans can lead to slower and less predictable performance.
JIT ANALYZE is a new Amazon Redshift feature that automatically collects and uses statistics for Iceberg tables during query execution—minimizing manual statistics collection while giving the planner and optimizer in the query engine the information it needs to generate optimal query plans. The system uses intelligent heuristics to identify queries that will benefit from statistics, performs fast file-level sampling using Iceberg metadata, and extrapolates population statistics using advanced techniques.
JIT ANALYZE delivers out-of-the-box performance nearly equal to queries that have pre-calculated statistics, while providing the foundation for many other performance optimizations. Some TPC-DS queries improved by 50 times faster with these statistics.
Query optimizations
For correlated subqueries such as those that contain EXISTS/IN clauses, Amazon Redshift uses decorrelation rules to rewrite the queries. In many cases, these decorrelation rules were not producing optimal plans, resulting in query execution performance regressions. To address this, we introduced a new internal join type, SEMI JOIN, and a new decorrelation rule based on this join type. This decorrelation rule helps in producing the most optimal plans, thereby improving execution performance. For instance, one of the TPC-DS queries that contains EXIST clause ran 7 times faster with this optimization.
We introduced distributed Bloom filter optimization for data lake workloads. Distributed Bloom filters create Bloom filters locally in every compute node and then distributes them to every other node. Distributing Bloom filters can significantly reduce the amount of data that needs to be sent over the network for the join by filtering out the tuples earlier. This provides good performance gains for large, complex data lake queries that process and join large amounts of data.
Conclusion
These performance improvements for Iceberg workloads represent a major leap forward in Redshift data lake capabilities. By focusing on out-of-the-box performance, we’ve made it straightforward to achieve exceptional query performance without complex tuning or optimization.
These improvements demonstrate the power of deep technical innovation combined with practical customer focus. JIT ANALYZE reduces the operational burden of statistics management while providing optimal query planning information. The new Redshift data lake query engine on Redshift Serverless was rewritten from the ground up for best-in-class scan performance, and lays the groundwork for more advanced performance optimizations. Semi-join optimizations tackle some of the most challenging query patterns in analytical workloads. You can run complex analytical workloads on your Iceberg data and get fast, predictable query performance.
Amazon Redshift is committed to being the best analytics engine for data lake workloads, and these performance optimizations represent our continued investment in that goal.
To learn more about Amazon Redshift and its performance capabilities, visit the Amazon Redshift product page. To get started with Redshift, you can try Amazon Redshift Serverless and start querying data in minutes without having to set up and manage data warehouse infrastructure. For more details on performance best practices, see the Amazon Redshift Database Developer Guide. To stay up-to-date with the latest developments in Amazon Redshift, subscribe to the What’s New in Amazon Redshift RSS feed.
Special thanks to this post’s contributors: Martin Milenkoski, Gerard Louw, Konrad Werblinski, Mengchu Cai, Mehmet Bulut, Mohammed Alkateb, and Sanket Hase