AWS Big Data Blog
Author: Rajiv Gupta
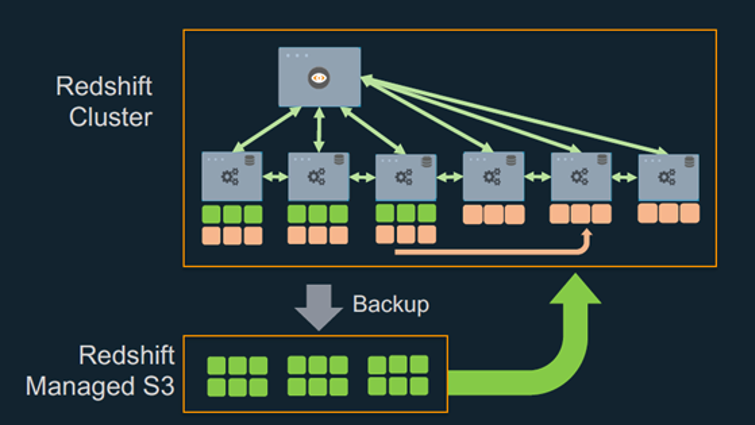
Getting the most out of your analytics stack with Amazon Redshift
Analytics environments today have seen an exponential growth in the volume of data being stored. In addition, analytics use cases have expanded, and data users want access to all their data as soon as possible. The challenge for IT organizations is how to scale your infrastructure, manage performance, and optimize for cost while meeting these […]

Accessing external components using Amazon Redshift Lambda UDFs
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse. It makes it simple and cost-effective to analyze all your data using standard SQL, your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day […]

Load ongoing data lake changes with AWS DMS and AWS Glue
April 2024: This post was reviewed for accuracy. July 2022: This blog post was reviewed and updated with an additional AWS CloudFormation stack to deploy MySQL database. Building a data lake on Amazon S3 provides an organization with countless benefits. It allows you to access diverse data sources, determine unique relationships, build AI/ML models to […]

Federate Amazon Redshift access with Okta as an identity provider
December 2022: This post was reviewed and updated for accuracy. Managing database users and access can be a daunting and error-prone task. In the past, database administrators had to determine which groups a user belongs to and which objects a user/group is authorized to use. These lists were maintained within the database and could easily […]