AWS Big Data Blog
Author: Raghu Kuppala
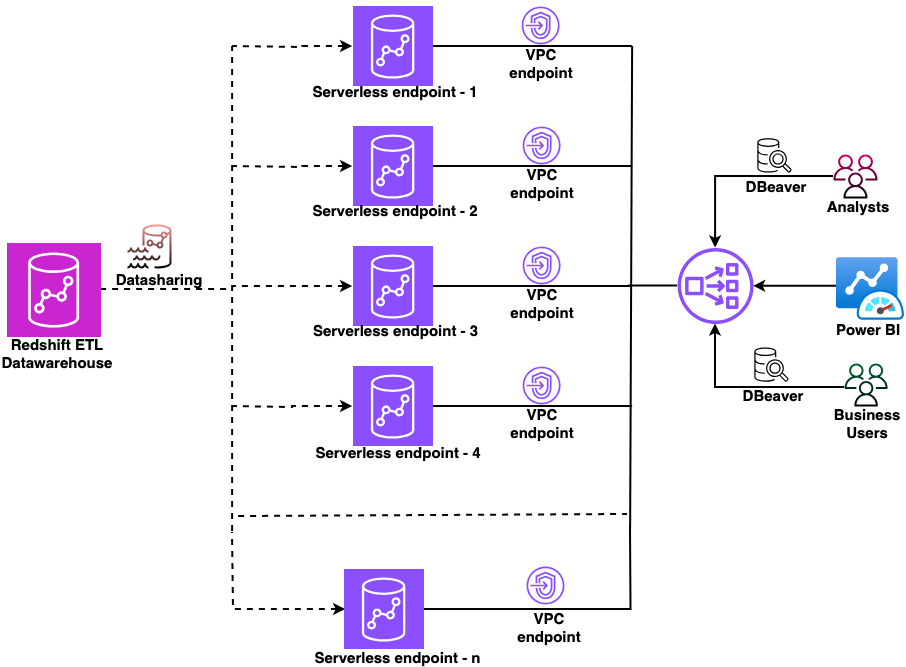
Secure multi-warehouse Amazon Redshift access behind a Network Load Balancer using Microsoft Entra ID
In this post, we show you how to configure a native identity provider (IdP) federation for Amazon Redshift Serverless using Network Load Balancer. You will learn how to enable secure connections from tools like DBeaver and Power BI while maintaining your enterprise security standards.

Scale fine-grained permissions across warehouses with Amazon Redshift and AWS IAM Identity Center
This post provides a comprehensive technical walkthrough for implementing Amazon Redshift federated permissions with AWS IAM Identity Center to help achieve scalable data governance across multiple data warehouses. It demonstrates a practical architecture where an Enterprise Data Warehouse (EDW) serves as the producer data warehouse with centralized policy definitions, helping automatically enforce security policies to consuming Sales and Marketing data warehouses without manual reconfiguration.

Enhance data ingestion performance in Amazon Redshift with concurrent inserts
Amazon Redshift employs columnar storage for database tables, reducing overall disk I/O requirements. This storage method significantly improves analytic query performance by minimizing data read during queries. This post showcases the key improvements in Amazon Redshift concurrent data ingestion operations.

Write queries faster with Amazon Q generative SQL for Amazon Redshift
In this post, we show you how to enable the Amazon Q generative SQL feature in the Redshift query editor and use the feature to get tailored SQL commands based on your natural language queries. With Amazon Q, you can spend less time worrying about the nuances of SQL syntax and optimizations, allowing you to concentrate your efforts on extracting invaluable business insights from your data.

Use custom domain names with Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. Amazon Redshift now supports custom URLs or custom domain names for your data warehouse. You might want to use a custom domain name […]