AWS Big Data Blog
Build multi-Region resilient Apache Kafka applications with identical topic names using Amazon MSK and Amazon MSK Replicator
Resilience has always been a top priority for customers running mission-critical Apache Kafka applications. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is deployed across multiple Availability Zones and provides resilience within an AWS Region. However, mission-critical Kafka deployments require cross-Region resilience to minimize downtime during service impairment in a Region. With Amazon MSK Replicator, you can build multi-Region resilient streaming applications to provide business continuity, share data with partners, aggregate data from multiple clusters for analytics, and serve global clients with reduced latency. This post explains how to use MSK Replicator for cross-cluster data replication and details the failover and failback processes while keeping the same topic name across Regions.
MSK Replicator overview
Amazon MSK offers two cluster types: Provisioned and Serverless. Provisioned cluster supports two broker types: Standard and Express. With the introduction of Amazon MSK Express brokers, you can now deploy MSK clusters that significantly reduce recovery time by up to 90% while delivering consistent performance. Express brokers provide up to 3 times the throughput per broker and scale up to 20 times faster compared to Standard brokers running Kafka. MSK Replicator works with both broker types in Provisioned clusters and along with Serverless clusters.
MSK Replicator supports an identical topic name configuration, enabling seamless topic name retention during both active-active or active-passive replication. This avoids the risk of infinite replication loops commonly associated with third-party or open source replication tools. When deploying an active-passive cluster architecture for regional resilience, where one cluster handles live traffic and the other acts as a standby, an identical topic configuration simplifies the failover process. Applications can transition to the standby cluster without reconfiguration because topic names remain consistent across the source and target clusters.
To set up an active-passive deployment, you have to enable multi-VPC connectivity for the MSK cluster in the primary Region and deploy an MSK Replicator in the secondary Region. The replicator will consume data from the primary Region’s MSK cluster and asynchronously replicate it to the secondary Region. You connect the clients initially to the primary cluster but fail over the clients to the secondary cluster in the case of primary Region impairment. When the primary Region recovers, you deploy a new MSK Replicator to replicate data back from the secondary cluster to the primary. You need to stop the client applications in the secondary Region and restart them in the primary Region.
Because replication with MSK Replicator is asynchronous, there is a possibility of duplicate data in the secondary cluster. During a failover, consumers might reprocess some messages from Kafka topics. To address this, deduplication should occur on the consumer side, such as by using an idempotent downstream system like a database.
In the next sections, we demonstrate how to deploy MSK Replicator in an active-passive architecture with identical topic names. We provide a step-by-step guide for failing over to the secondary Region during a primary Region impairment and failing back when the primary Region recovers. For an active-active setup, refer to Create an active-active setup using MSK Replicator.
Solution overview
In this setup, we deploy a primary MSK Provisioned cluster with Express brokers in the us-east-1 Region. To provide cross-Region resilience for Amazon MSK, we establish a secondary MSK cluster with Express brokers in the us-east-2 Region and replicate topics from the primary MSK cluster to the secondary cluster using MSK Replicator. This configuration provides high resilience within each Region by using Express brokers, and cross-Region resilience is achieved through an active-passive architecture, with replication managed by MSK Replicator.
The following diagram illustrates the solution architecture.

The primary Region MSK cluster handles client requests. In the event of a failure to communicate to MSK cluster due to primary region impairment, you need to fail over the clients to the secondary MSK cluster. The producer writes to the customer topic in the primary MSK cluster, and the consumer with the group ID msk-consumer reads from the same topic. As part of the active-passive setup, we configure MSK Replicator to use identical topic names, making sure that the customer topic remains consistent across both clusters without requiring changes from the clients. The entire setup is deployed within a single AWS account.
In the next sections, we describe how to set up a multi-Region resilient MSK cluster using MSK Replicator and also show the failover and failback strategy.
Provision an MSK cluster using AWS CloudFormation
We provide AWS CloudFormation templates to provision certain resources:
- Deploy this CloudFormation template in
us-east-1(primary) - Deploy this CloudFormation template in
us-east-2(secondary)
This will create the virtual private cloud (VPC), subnets, and the MSK Provisioned cluster with Express brokers within the VPC configured with AWS Identity and Access Management (IAM) authentication in each Region. It will also create a Kafka client Amazon Elastic Compute Cloud (Amazon EC2) instance, where we can use the Kafka command line to create and view a Kafka topic and produce and consume messages to and from the topic.
Configure multi-VPC connectivity in the primary MSK cluster
After the clusters are deployed, you need to enable the multi-VPC connectivity in the primary MSK cluster deployed in us-east-1. This will allow MSK Replicator to connect to the primary MSK cluster using multi-VPC connectivity (powered by AWS PrivateLink). Multi-VPC connectivity is only required for cross-Region replication. For same-Region replication, MSK Replicator uses an IAM policy to connect to the primary MSK cluster.
MSK Replicator uses IAM authentication only to connect to both primary and secondary MSK clusters. Therefore, although other Kafka clients can still continue to use SASL/SCRAM or mTLS authentication, for MSK Replicator to work, IAM authentication has to be enabled.
To enable multi-VPC connectivity, complete the following steps:
- On the Amazon MSK console, navigate to the MSK cluster.
- On the Properties tab, under Network settings, choose Turn on multi-VPC connectivity on the Edit dropdown menu.

- For Authentication type, select IAM role-based authentication.
- Choose Turn on selection.
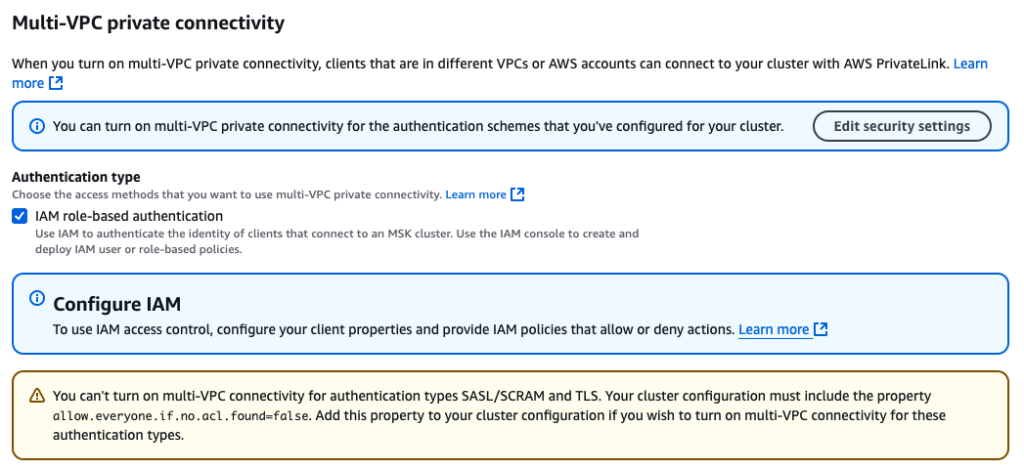
Enabling multi-VPC connectivity is a one-time setup and it can take approximately 30–45 minutes depending on the number of brokers. After this is enabled, you need to provide the MSK cluster resource policy to allow MSK Replicator to talk to the primary cluster.
- Under Security settings¸ choose Edit cluster policy.
- Select Include Kafka service principal.

Now that the cluster is enabled to receive requests from MSK Replicator using PrivateLink, we need to set up the replicator.
Create a MSK Replicator
Complete the following steps to create an MSK Replicator:
- In the secondary Region (
us-east-2), open the Amazon MSK console. - Choose Replicators in the navigation pane.
- Choose Create replicator.
- Enter a name and optional description.

- In the Source cluster section, provide the following information:
- For Cluster region, choose us-east-1.
- For MSK cluster, enter the Amazon Resource Name (ARN) for the primary MSK cluster.
For cross-Region setup, the primary cluster will appear disabled if the multi-VPC connectivity is not enabled and the cluster resource policy is not configured in the primary MSK cluster. After you choose the primary cluster, it automatically selects the subnets associated with primary cluster. Security groups are not required because the primary cluster’s access is governed by the cluster resource policy.

Next, you select the target cluster. The target cluster Region is defaulted to the Region where the MSK Replicator is created. In this case, it’s us-east-2.
- In the Target cluster section, provide the following information:
- For MSK cluster, enter the ARN of the secondary MSK cluster. This will automatically select the cluster subnets and the security group associated with the secondary cluster.
- For Security groups, choose any additional security groups.
Make sure that the security groups have outbound rules to allow traffic to your secondary cluster’s security groups. Also make sure that your secondary cluster’s security groups have inbound rules that accept traffic from the MSK Replicator security groups provided here.

Now let’s provide the MSK Replicator settings.
- In the Replicator settings section, enter the following information:
- For Topics to replicate, we keep the topics to replicate as a default value that replicates all topics from the primary to secondary cluster.
- For Replication starting position, we choose Earliest, so that we can get all the events from the start of the source topics.
- For Copy settings, select Keep the same topic names to configure the topic name in the secondary cluster as identical to the primary cluster.
This makes sure that the MSK clients don’t need to add a prefix to the topic names.

- For this example, we keep the Consumer group replication setting as default and set Target compression type as None.
Also, MSK Replicator will automatically create the required IAM policies.
- Choose Create to create the replicator.
The process takes around 15–20 minutes to deploy the replicator. After the MSK Replicator is running, this will be reflected in the status.
Configure the MSK client for the primary cluster
Complete the following steps to configure the MSK client:
- On the Amazon EC2 console, navigate to the EC2 instance of the primary Region (
us-east-1) and connect to the EC2 instancedr-test-primary-KafkaClientInstance1using Session Manager, a capability of AWS Systems Manager.
After you have logged in, you need to configure the primary MSK cluster bootstrap address to create a topic and publish data to the cluster. You can get the bootstrap address for IAM authentication on the Amazon MSK console under View Client Information on the cluster details page.
- Configure the bootstrap address with the following code:
- Configure the client configuration for IAM authentication to talk to the MSK cluster:
Create a topic and produce and consume messages to the topic
Complete the following steps to create a topic and then produce and consume messages to it:
- Create a
customertopic:
- Create a console producer to write to the topic:
- Produce the following sample text to the topic:
- Press Ctrl+C to exit the console prompt.
- Create a consumer with
group.idmsk-consumerto read all the messages from the beginning of the customer topic:
This will consume both the sample messages from the topic.
- Press Ctrl+C to exit the console prompt.
Configure the MSK client for the secondary MSK cluster
Go to the EC2 cluster of the secondary Region us-east-2 and follow the previously mentioned steps to configure an MSK client. The only difference from the previous steps is that you should use the bootstrap address of the secondary MSK cluster as the environment variable. Configure the variable $BS_SECONDARY to configure the secondary Region MSK cluster bootstrap address.
Verify replication
After the client is configured to talk to the secondary MSK cluster using IAM authentication, list the topics in the cluster. Because the MSK Replicator is now running, the customer topic is replicated. To verify it, let’s see the list of topics in the cluster:
The topic name is customer without any prefix.
By default, MSK Replicator replicates the details of all the consumer groups. Because you used the default configuration, you can verify using the following command if the consumer group ID msk-consumer is also replicated to the secondary cluster:
Now that we have verified the topic is replicated, let’s understand the key metrics to monitor.
Monitor replication
Monitoring MSK Replicator is very important to make sure that replication of data is happening fast. This reduces the risk of data loss in case an unplanned failure occurs. Some important MSK Replicator metrics to monitor are ReplicationLatency, MessageLag, and ReplicatorThroughput. For a detailed list, see Monitor replication.
To understand how many bytes are processed by MSK Replicator, you should monitor the metric ReplicatorBytesInPerSec. This metric indicates the average number of bytes processed by the replicator per second. Data processed by MSK Replicator consists of all data MSK Replicator receives. This includes the data replicated to the target cluster and filtered by MSK Replicator. This metric is applicable if you use Keep same topic name in the MSK Replicator copy settings. During a failback scenario, MSK Replicator starts to read from the earliest offset and replicates records from the secondary back to the primary. Depending on the retention settings, some data might exist in the primary cluster. To prevent duplicates, MSK Replicator processes the data but automatically filters out duplicate data.
Fail over clients to the secondary MSK cluster
In the case of an unexpected event in the primary Region in which clients can’t connect to the primary MSK cluster or the clients are receiving unexpected produce and consume errors, this could be a sign that the primary MSK cluster is impacted. You may notice a sudden spike in replication latency. If the latency continues to rise, it could indicate a regional impairment in Amazon MSK. To verify this, you can check the AWS Health Dashboard, though there is a chance that status updates may be delayed. Once you identify signs of a regional impairment in Amazon MSK, you should prepare to fail over the clients to the secondary region.
For critical workloads we recommend not taking a dependency on control plane actions for failover. To mitigate this risk, you could implement a pilot light deployment, where essential components of the stack are kept running in a secondary region and scaled up when the primary region is impaired. Alternatively, for faster and smoother failover with minimal downtime, a hot standby approach is recommended. This involves pre-deploying the entire stack in a secondary region so that, in a disaster recovery scenario, the pre-deployed clients can be quickly activated in the secondary region.
Failover process
To perform the failover, you first need to stop the clients pointed to the primary MSK cluster. However, for the purpose of the demo, we are using console producer and consumers, so our clients are already stopped.
In a real failover scenario, using primary Region clients to communicate with the secondary Region MSK cluster is not recommended, as it breaches fault isolation boundaries and leads to increased latency. To simulate the failover using the preceding setup, let’s start a producer and consumer in the secondary Region (us-east-2). For this, run a console producer in the EC2 instance (dr-test-secondary-KafkaClientInstance1) of the secondary Region.
The following diagram illustrates this setup.

Complete the following steps to perform a failover:
- Create a console producer using the following code:
- Produce the following sample text to the topic:
Now, let’s create a console consumer. It’s important to make sure the consumer group ID is exactly the same as the consumer attached to the primary MSK cluster. For this, we use the group.id msk-consumer to read the messages from the customer topic. This simulates that we are bringing up the same consumer attached to the primary cluster.
- Create a console consumer with the following code:
Although the consumer is configured to read all the data from the earliest offset, it only consumes the last two messages produced by the console producer. This is because MSK Replicator has replicated the consumer group details along with the offsets read by the consumer with the consumer group ID msk-consumer. The console consumer with the same group.id mimic the behaviour that the consumer is failed over to the secondary Amazon MSK cluster.
Fail back clients to the primary MSK cluster
Failing back clients to the primary MSK cluster is the common pattern in an active-passive scenario, when the service in the primary region has recovered. Before we fail back clients to the primary MSK cluster, it’s important to sync the primary MSK cluster with the secondary MSK cluster. For this, we need to deploy another MSK Replicator in the primary Region configured to read from the earliest offset from the secondary MSK cluster and write to the primary cluster with the same topic name. The MSK Replicator will copy the data from the secondary MSK cluster to the primary MSK cluster. Although the MSK Replicator is configured to start from the earliest offset, it will not duplicate the data already present in the primary MSK cluster. It will automatically filter out the existing messages and will only write back the new data produced in the secondary MSK cluster when the primary MSK cluster was down. The replication step from secondary to primary wouldn’t be required if you don’t have a business requirement of keeping the data same across both clusters.
After the MSK Replicator is up and running, monitor the MessageLag metric of MSK Replicator. This metric indicates how many messages are yet to be replicated from the secondary MSK cluster to the primary MSK cluster. The MessageLag metric should come down close to 0. Now you should stop the producers writing to the secondary MSK cluster and restart connecting to the primary MSK cluster. You should also allow the consumers to read data from the secondary MSK cluster until the MaxOffsetLag metric for the consumers is not 0. This makes sure that the consumers have already processed all the messages from the secondary MSK cluster. The MessageLag metric should be 0 by this time because no producer is producing records in the secondary cluster. MSK Replicator replicated all messages from the secondary cluster to the primary cluster. At this point, you should start the consumer with the same group.id in the primary Region. You can delete the MSK Replicator created to copy messages from the secondary to the primary cluster. Make sure that the previously existing MSK Replicator is in RUNNING status and successfully replicating messages from the primary to secondary. This can be confirmed by looking at the ReplicatorThroughput metric, which should be greater than 0.
Failback process
To simulate a failback, you first need to enable multi-VPC connectivity in the secondary MSK cluster (us-east-2) and add a cluster policy for the Kafka service principal like we did before.
Deploy the MSK Replicator in the primary Region (us-east-1) with the source MSK cluster pointed to us-east-2 and the target cluster pointed to us-east-1. Configure Replication starting position as Earliest and Copy settings as Keep the same topic names.
The following diagram illustrates this setup.

After the MSK Replicator is in RUNNING status, let’s verify there is no duplicate while replicating the data from the secondary to the primary MSK cluster.
Run a console consumer without the group.id in the EC2 instance (dr-test-primary-KafkaClientInstance1) of the primary Region (us-east-1):
This should show the four messages without any duplicates. Although in the consumer we specify to read from the earliest offset, MSK Replicator makes sure the duplicate data isn’t replicated back to the primary cluster from the secondary cluster.
You can now point the clients to start producing to and consuming from the primary MSK cluster.
Clean up
At this point, you can tear down the MSK Replicator deployed in the primary Region.
Conclusion
This post explored how to enhance Kafka resilience by setting up a secondary MSK cluster in another Region and synchronizing it with the primary cluster using MSK Replicator. We demonstrated how to implement an active-passive disaster recovery strategy while maintaining consistent topic names across both clusters. We provided a step-by-step guide for configuring replication with identical topic names and detailed the processes for failover and failback. Additionally, we highlighted key metrics to monitor and outlined actions to provide efficient and continuous data replication.
For more information, refer to What is Amazon MSK Replicator? For a hands-on experience, try out the Amazon MSK Replicator Workshop. We encourage you to try out this feature and share your feedback with us.
About the Author

Subham Rakshit is a Senior Streaming Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build streaming architectures so they can get value from analyzing their streaming data. His two little daughters keep him occupied most of the time outside work, and he loves solving jigsaw puzzles with them. Connect with him on LinkedIn.