AWS Big Data Blog
Building a modern lakehouse architecture: Yggdrasil Gaming’s journey from BigQuery to AWS
This is a guest post by Edijs Drezovs, CEO and Founder of GOStack, Viesturs Kols, Data Architect at GOStack, and Krisjanis Beitans, Senior Data Engineer at GOStack, in partnership with AWS.
Yggdrasil Gaming develops and publishes casino games globally, processing massive amounts of real-time gaming data for game performance analytics, player behavior insights, and industry intelligence. As Yggdrasil’s system grew, managing dual-cloud environments created operational overhead and limited their ability to implement advanced analytics initiatives. This challenge became critical ahead of the launch of the Game in a Box solution on AWS Marketplace, which generates increases in data volume and complexity.
Yggdrasil Gaming reduced multi-cloud complexity and built a scalable analytics foundation by migrating from Google BigQuery to AWS analytics services. In this post, you’ll discover how Yggdrasil Gaming transformed their data architecture to meet growing business demands. You will learn practical strategies for migrating from proprietary systems to open table formats such as Apache Iceberg while maintaining business continuity.
Yggdrasil worked with GOStack, an AWS Partner, to migrate to an Apache Iceberg-based lakehouse architecture. The migration helped reduce operational complexity and enabled real-time gaming analytics and machine learning.
Challenges
Yggdrasil faced several critical challenges that prompted their migration to AWS:
- Multi-cloud operational complexity: Managing infrastructure across AWS and Google Cloud created significant operational overhead, reducing agility and increasing maintenance costs. The data team had to maintain expertise in both environments and coordinate data movement between clouds.
- Architecture limitations: The existing setup couldn’t effectively support advanced analytics and AI initiatives. More critically, the launch of Yggdrasil’s Game in a Box solution required a modernized, scalable data environment capable of handling increased data volumes and enabling advanced analytics.
- Scalability constraints: The architecture lacked the unified data foundation with open standards and automation required to scale efficiently. As data volumes grew, costs increased proportionally, and the team needed an environment designed for modern analytics at scale.
Solution overview
Yggdrasil worked with GOStack, an AWS APN partner, to design their new lakehouse architecture. The following diagram shows the high level overview of this architecture.
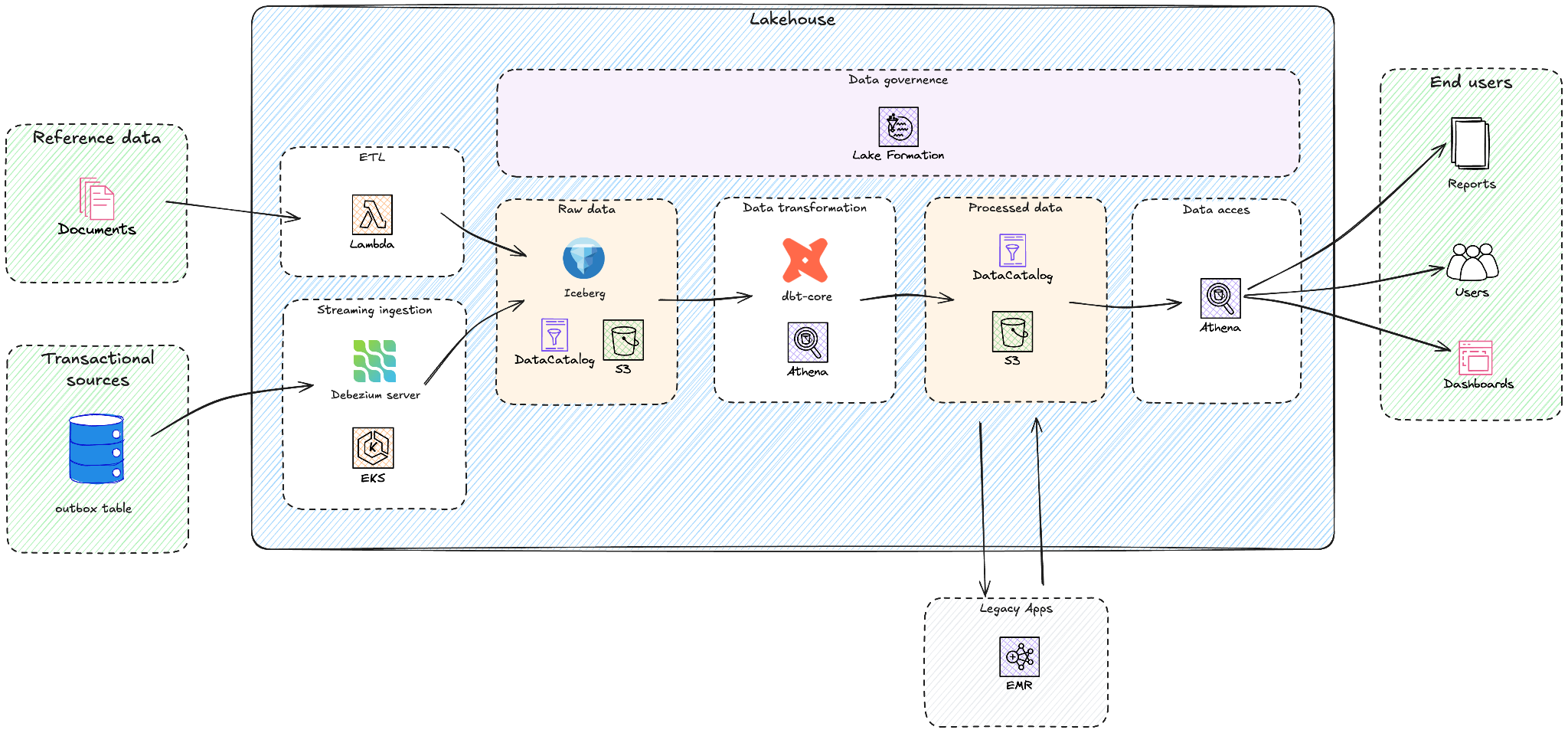
Yggdrasil successfully migrated from Google BigQuery to a data lakehouse architecture using Amazon Athena, Amazon EMR, Amazon Simple Storage Service (Amazon S3), AWS Glue Data Catalog, AWS Lake Formation, Amazon Elastic Kubernetes Service (Amazon EKS) and AWS Lambda. Their strategic approach aims to reduce multi-cloud complexity while building a scalable foundation for their Game in a Box solution and specific AI/ML initiatives like personalized game recommendations and fraud detection.
The combination of Amazon S3, Apache Iceberg, and Amazon Athena allowed Yggdrasil to move away from provisioned, always-on compute models. The Amazon Athena pay-per-query pricing charges only for data scanned, removing idle compute costs during off-peak periods. Internal cost modeling performed during the evaluation phase indicated that this architecture could reduce analytics system costs by 30–50% compared to compute-based warehouse pricing models of other solutions, particularly for bursty workloads driven by game launches, tournaments, and seasonal traffic. By adopting AWS-native analytics services, Yggdrasil reduced operational complexity through native integration with AWS Identity and Access Management (AWS IAM), Amazon EKS, and AWS Lambda, helping simplify security, governance, and automation across the analytics system.
The solution centers on a modern lakehouse architecture built on Amazon S3, which provides durable and cost-efficient storage for Iceberg tables in Apache Parquet format. Apache Iceberg table format provides ACID transactions, schema evolution, and time travel capabilities while maintaining an open standard. AWS Glue Data Catalog serves as the central technical metadata repository, while Amazon Athena acts as the serverless query engine used by dbt-athena and for ad-hoc data exploration. Amazon EMR runs Yggdrasil’s legacy Apache Spark application in a fully managed environment, and AWS Lake Formation provides centralized security and governance for data lakes, allowing fine-grained access control at database, table, column, and row levels.
The migration followed a phased approach:
- Establish lakehouse foundation – Set up Apache Iceberg-based architecture with Amazon S3 with AWS Glue Data Catalog
- Implement real-time data ingestion – Deploy Debezium connectors for real-time change data capture from EKS and Google Kubernetes Engine (GKE) clusters
- Migrate processing pipelines – Re-system ETL pipelines using AWS Lambda, and legacy data applications re-systemed on Amazon EMR
- Modernizing the transformation layer – Implement dbt with Amazon Athena for modular, reusable models
- Enable governance – Configure AWS Lake Formation for comprehensive data governance
Establish lakehouse foundation
The first phase of the migration focused on building a solid foundation for the new data lakehouse architecture on AWS. The goal was to create a scalable, secure, and cost-efficient environment that could support analytical workloads with open data formats and serverless query capabilities.
GOStack provisioned an Amazon S3-based data lake as the central storage layer, providing virtually unlimited scalability and fine-grained cost control. This storage-compute separation enables teams to decouple ingestion, transformation, and analytics processes, with each component scaling independently using the most appropriate compute engine.
To establish dataset interoperability and discoverability, the team adopted AWS Glue Data Catalog as the unified metadata repository. The catalog stores Iceberg table definitions and makes schemas accessible across services such as Amazon Athena and Apache Spark workloads on Amazon EMR. Most datasets, both batch and streaming, are registered here, enabling consistent metadata visibility across the lakehouse.
The data is stored in Apache Iceberg tables on Amazon S3, selected for its open table format, ACID transaction support, and powerful schema evolution features. Yggdrasil required ACID transactions for consistent financial reporting and fraud detection, schema evolution to accommodate rapidly changing gaming data models, and time travel queries to align with regulatory audit requirements.
GOStack built a custom schema conversion and table registration service. This internal tool converts source-system Avro schemas into Iceberg table definitions and manages the creation and evolution of raw-layer tables. By controlling schema translation and table registration directly, the team makes sure that metadata stays consistent with the source systems and provides predictable, versioned schema evolution aligned with ingestion needs.
The initial setup made the following components:
- Amazon S3 bucket structure design: Implemented a multi-layer layout (raw, curated, and analytics zones) aligned with data lifecycle best practices.
- AWS Glue Data Catalog integration: Defined database and table schemas with partitioning strategies optimized for Athena performance.
- Iceberg configuration: Enabled versioning and metadata retention policies to balance storage efficiency and query flexibility.
- Security and compliance: Configured encryption at rest using AWS Key Management Service (AWS KMS), helped enforce access controls via AWS IAM and Lake Formation, and implemented Amazon S3 bucket policies following the principle of least privilege.
The redesign of the previous GCP setup helped deliver price-performance improvements. Yggdrasil reduced ingestion and processing costs by approximately 60% while also lowering operational overhead through a more direct, event-driven pipeline.
Implement real-time data ingestion
After establishing the lakehouse architecture, the next step focused on enabling real-time data ingestion from Yggdrasil’s operational databases into the raw data layer of the lakehouse. The objective was to capture and deliver transactional changes as they occur, making sure that downstream analytics and reporting reflect the most up-to-date information.
To achieve this, GOStack deployed Debezium Server Iceberg, an open-source project that integrates change data capture (CDC) directly with Apache Iceberg tables. It was deployed as Argo CD applications on Amazon EKS and used Argo’s GitOps-based model for reproducibility, scalability, and seamless rollouts.
This architecture provides an efficient ingestion pathway – streaming data changes directly from the source system’s outbox tables into the Apache Iceberg tables registered in the AWS Glue Data Catalog and physically stored on Amazon S3, bypassing the need for intermediate brokers or staging services. By writing data in the Iceberg table format, the ingestion layer maintained transactional guarantees and immediate query availability through Amazon Athena.
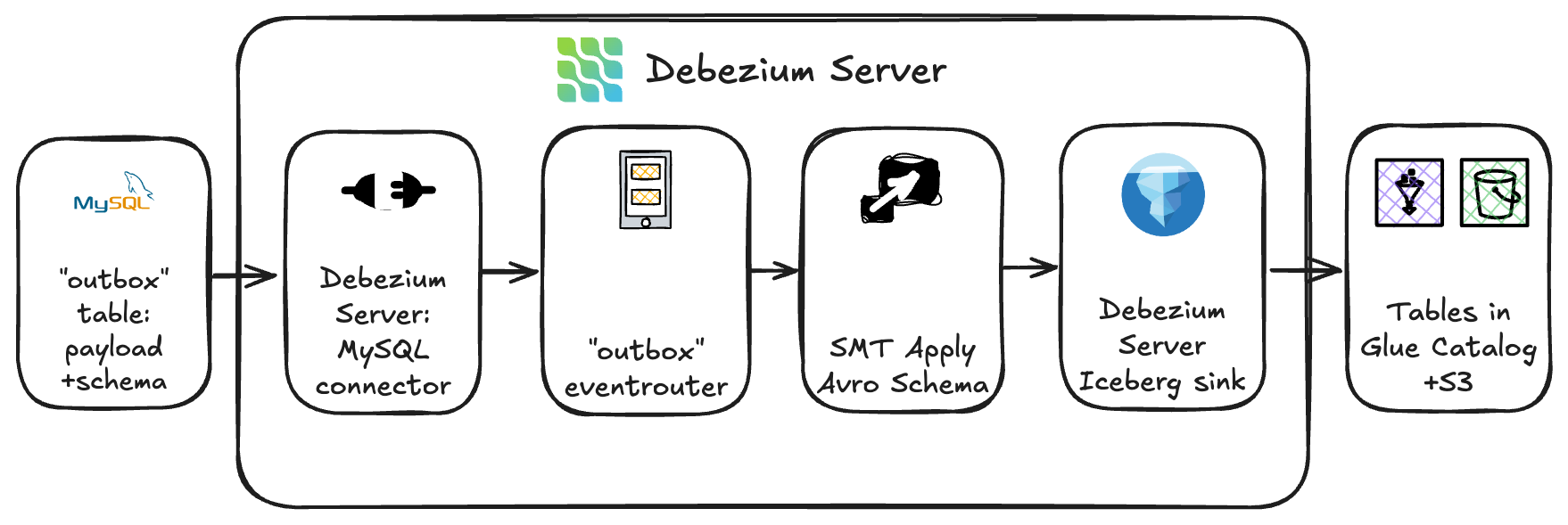
Because Yggdrasil’s source systems emitted outbox events containing Avro records, the team implemented a custom outbox-to-Avro transformation within Debezium. The outbox table stored two key components:
- The Avro schema definition
- The JSON-encoded payload of each record
The custom transformation module combined these elements into valid Avro records before persisting them into the target Iceberg tables. This approach preserved schema fidelity and verified compatibility with downstream processing tools.
To dynamically route incoming change events, the team leveraged Debezium’s event router configuration. Each record was routed to the appropriate Apache Iceberg table (backed by Amazon S3) based on topic and metadata rules, while table schemas and partitioning were governed on the AWS Glue side to maintain stability and alignment with the lakehouse’s data organization standards.
This setup helped deliver low-latency ingestion with end-to-end streaming from database outbox to S3-based Iceberg tables in near real time. The team managed operations end to end on Amazon EKS using Helm charts deployed via Argo CD in a GitOps model for fully declarative, version-controlled operations. ACID-compliant Iceberg writes verified that partially written data could not corrupt downstream analytics. The modular transformation logic allowed future expansion to new source systems or event formats without rearchitecting the ingestion pipeline.
This Debezium Server solution provides fast, real-time data ingestion. GOStack considers it an interim architecture. In the long term, the ingestion pipeline will evolve to use Amazon Managed Streaming for Apache Kafka (Amazon MSK) as the central event backbone. Debezium connectors will act as producers, publishing change events to Apache Kafka topics, while Apache Flink applications will consume, process, and write data into Iceberg tables.
This planned evolution toward a Kafka-based streaming architecture verifies Yggdrasil’s lakehouse remains not only scalable and cost-efficient today, but also future-ready – capable of supporting richer streaming analytics and broader data integration scenarios as the organization grows.
Migrate processing pipelines
Once real-time data ingestion was established, GOStack turned its focus to modernizing the data transformation layer. The goal was to simplify the transformation logic, reduce operational overhead, and unify the orchestration of analytical workloads within the new AWS-based lakehouse.
GOStack adopted a lift-and-shift approach for some of Yggdrasil’s data pipelines to support a fast and low-risk transition away from GCP. The lightweight Cloud Run functions that previously handled extraction tasks – pulling data from file shares, SharePoint, Google Sheets, and various third-party APIs – were re-implemented using AWS Lambda. These Lambda functions now integrate with the same external systems and write data directly into Iceberg tables.
For more complex processing, previous Apache Spark applications running on Dataproc were migrated to Amazon EMR with minimal code changes. This allowed it to preserve the existing transformation logic while benefiting from the managed scaling capabilities of EMR and improved cost control on AWS.
Over time, these processes will be gradually refactored and consolidated into containerized workflows on the EKS cluster, fully orchestrated by Argo Workflows. This phased migration allows Yggdrasil to move workloads to AWS quickly and decommission GCP resources sooner, while still leaving room for continuous improvement and modernization of the data system over time.
Finally, a lot of analytical transformations that previously lived as BigQuery stored procedures and scheduled queries, that were now rebuilt as modular dbt models executed with dbt-athena. This shift made transformation logic more transparent, maintainable, and version-controlled, improving both developer experience and long-term governance.
Modernizing the transformation layer
With the ingestion pipelines migrated to AWS, GOStack turned its focus to simplifying and modernizing Yggdrasil’s analytical transformations. Rather than replicating the previous stored-procedure–driven approach, the team rebuilt the transformation layer using dbt to help improve maintainability, lineage visibility, orchestration, and long-term governance.As part of this redesign, several data models were reshaped to fit the new lakehouse architecture. The most significant effort involved rewriting a critical Spark-based financial transformation into a set of SQL-driven dbt models. This shift not only aligned the logic with the lakehouse design but also removed the need for long-running Spark clusters, helping generate operational and cost savings.For the curated data layers, replacing the legacy warehouse, GOStack consolidated numerous scheduled queries and stored procedures into structured dbt models. This provides standardized, version-controlled transformations and clear lineage across the analytical stack.
Orchestration was simplified as well. Previously, coordination was split between Apache Airflow for Spark workloads and scheduled queries analytical transformations, creating operational friction and dependency risks. In the new architecture, Argo Workflows on Amazon EKS orchestrates dbt models centrally, consolidating the transformation logic within a single workflow engine. While most transformations still run on time-based schedules today, the system now supports event-driven execution through Argo Events, giving the opportunity to progressively adopt trigger-based workflows as the transformation layer evolves.
This unified orchestration framework can bring multiple benefits:
- Consistency: One orchestration layer for data workflows across ingestion and transformation.
- Automation: Event-driven dbt runs help remove manual scheduling and reduce operational overhead.
- Scalability: Argo Workflows scales with the EKS cluster, handling concurrent dbt jobs seamlessly.
- Observability: Centralized logging and workflow visualization help improve visibility into job dependencies and data freshness.
Through this transformation, Yggdrasil successfully unified its data lakes and warehouses into a modern lakehouse architecture, powered by open data formats, serverless query engines, and modular transformation logic. The move to dbt and Athena not only simplified operations but also helped pave the way for faster iteration, simpler governance, and greater developer productivity across the data environment.
Lakehouse performance optimizations
While performance tuning is an ongoing journey, as part of the transformation redesign, GOStack made few performance-oriented tweaks to make sure Athena queries can be fast and cost-efficient. The Apache Iceberg tables were stored in Parquet with ZSTD compression, providing strong read performance and reducing the amount of data scanned by Athena.
Partitioning strategies were also aligned to actual access patterns using Iceberg’s native partitioning. Raw data zones were partitioned by ingestion timestamp, enabling efficient incremental processing. Curated data used business-driven partition keys, such as player or game identifiers and date dimensions, to help optimize analytical queries. These designs made sure Athena could prune unneeded data and consistently scan only the relevant partitions.
Iceberg’s native partitioning features, including transforms such as bucketing and time slicing, replace traditional Hive partitioning patterns. Because Iceberg manages partitions internally in its metadata layer, not all Glue or Athena partition constructs apply. Relying on Iceberg’s native partitioning helps provide predictable pruning and consistent performance across the lakehouse without introducing legacy Hive behaviors.
To handle the high volume of small files produced by real-time ingestion, GOStack enabled AWS Glue Iceberg compaction. This automatically merges small Parquet files into larger segments, helping improve query performance and reduce metadata overhead without manual intervention.
Enable governance
The team adopted AWS Lake Formation as the primary governance layer for the curated zone of the lakehouse, leveraging Lake Formation hybrid access mode to manage fine-grained permissions alongside existing IAM-based access patterns. This hybrid mode provides an incremental and flexible pathway to adopt Lake Formation without forcing a full migration of legacy permissions or internal pipeline roles, making it an ideal fit for Yggdrasil’s phased modernization strategy.
Lake Formation offers centralized authorization, supporting database, table, column, and, critically for Yggdrasil, row-level permissions. These capabilities are essential because of the company’s multi-tenant operating model:
- Game development partners require access to data and reports pertaining only to their own games, facilitating both security and compliance alignment with partner agreements.
- iGaming operators integrating with Yggdrasil’s system must receive operational and financial insights exclusively for their own data, enforced automatically through reporting tools backed by curated Iceberg tables.
With Lake Formation hybrid access mode, tenant-specific row-level access policies are consistently enforced across Amazon Athena, AWS Glue, and Amazon EMR, without introducing breaking changes to existing IAM-based workloads. This allowed Yggdrasil to implement strong governance for external consumers while keeping internal operations stable and predictable.
Internally, Lake Formation is also used to grant the Analytics team and BI tools targeted access to curated datasets, straightforward but centrally managed to maintain consistency and reduce administrative overhead.
For ingestion and transformation workloads, the team continues to rely on IAM roles and policies. Services such as Debezium, dbt, and Argo Workflows require broad but controlled access to raw and intermediate storage layers, and IAM provides a straightforward, least-privilege mechanism for granting those permissions without involving Lake Formation in the internal pipeline path.
By adopting Lake Formation in hybrid access mode and combining it with IAM for internal services, Yggdrasil established a governance model that can balance strong security with operational flexibility – enabling the lakehouse to scale securely as the business grows.
Results and business impact
The new lakehouse, built on Amazon Athena, Amazon S3, and AWS Glue Data Catalog, now underpins advanced analytics and AI/ML use cases such as player behavior modeling, predictive game recommendations, and fraud detection.
The optimized lakehouse design allows Yggdrasil to rapidly onboard new analytics workloads and business use cases, helping deliver measurable outcomes:
- Reduced operational complexity through consolidation on AWS analytics services
- Cost optimization with a 60% reduction in data processing costs
- Improved data freshness with 75% lower latency for analytics results (from 2 hours to 30 minutes)
- Enhanced governance using the AWS Lake Formation fine-grained controls
- Future-ready architecture leveraging open formats and serverless analytics
Conclusion
Yggdrasil Gaming’s migration journey illustrates how organizations can successfully transition from proprietary analytics systems to an open, flexible lakehouse architecture. By following a phased approach guided by AWS Well-Architected Framework principles, Yggdrasil maintained business continuity while establishing a modern foundation for their data needs.
Based on this experience, several lessons emerged to help guide your own move to an AWS-based lakehouse:
- Assess your current state: Identify pain points in your existing data architecture and establish clear objectives for modernization.
- Start small: Begin with a pilot project using AWS analytics services to validate the lakehouse approach for your specific use cases.
- Design for openness: Leverage open table formats like Apache Iceberg to maintain flexibility and avoid vendor lock-in.
- Implement gradually: Follow a phased migration strategy similar to Yggdrasil’s, prioritizing high-value workloads.
- Optimize continuously: Use performance tuning techniques for Amazon Athena to help maximize efficiency and minimize costs.
To learn more about building modern lakehouse architectures, refer to “The lakehouse architecture of Amazon SageMaker”.