AWS Big Data Blog
Category: AWS Big Data
Announcing Amazon Redshift federated querying to Amazon Aurora MySQL and Amazon RDS for MySQL
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in April 2020, we announced general availability for federated querying to Amazon Aurora PostgreSQL and Amazon Relational Database Service (Amazon RDS) […]

Building high-quality benchmark tests for Amazon Redshift using SQLWorkbench and psql
In the introductory post of this series, we discussed benchmarking benefits and best practices common across different open-source benchmarking tools. In this post, we discuss benchmarking Amazon Redshift with the SQLWorkbench and psql open-source tools. Let’s first start with a quick review of the introductory installment. When you use Amazon Redshift to scale compute and […]
Getting the most out of your analytics stack with Amazon Redshift
Analytics environments today have seen an exponential growth in the volume of data being stored. In addition, analytics use cases have expanded, and data users want access to all their data as soon as possible. The challenge for IT organizations is how to scale your infrastructure, manage performance, and optimize for cost while meeting these […]

Working with timestamp with time zone in your Amazon S3-based data lake
With a data lake built on Amazon Simple Storage Service (Amazon S3), you can use the purpose-built analytics services for a range of use cases, from analyzing petabyte-scale datasets to querying the metadata of a single object. AWS analytics services support open file formats such as Parquet, ORC, JSON, Avro, CSV, and more, so it’s […]

Using pipes to explore, discover and find data in Amazon OpenSearch Service with Piped Processing Language
System developers, DevOps engineers, support engineers, site reliability engineers (SREs), and IT managers make sure that the underlying infrastructure powering the applications and systems within an organization is available, reliable, secure, and scalable. To achieve these goals, you need to perform a fast and deep analysis on the underlying logs, monitoring, and observability data. Amazon […]
Introducing Amazon Redshift RA3.xlplus nodes with managed storage
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in December 2019, we announced our third-generation RA3 node type to provide you the ability to scale and pay for compute […]
Amazon EMR Studio (Preview): A new notebook-first IDE experience with Amazon EMR
We’re happy to announce Amazon EMR Studio (Preview), an integrated development environment (IDE) that makes it easy for data scientists and data engineers to develop, visualize, and debug applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools like Spark UI and YARN Timeline Service to simplify debugging. […]

Get up to 3x better price performance with Amazon Redshift than other cloud data warehouses
Since we announced Amazon Redshift in 2012, tens of thousands of customers have trusted us to deliver the performance and scale they need to gain business insights from their data. Amazon Redshift customers span all industries and sizes, from startups to Fortune 500 companies, and we work to deliver the best price performance for any use case. Earlier […]
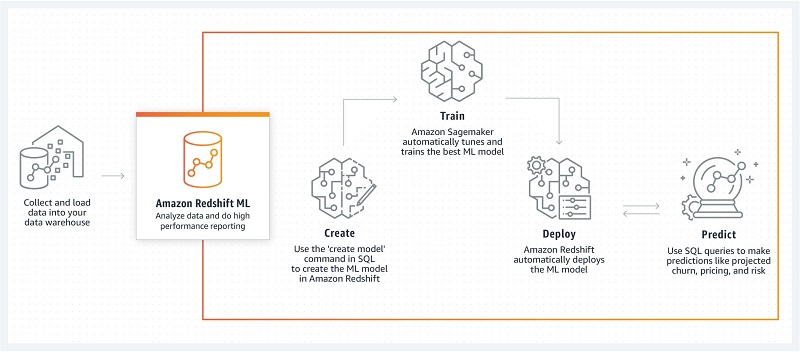
Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML
December 2022: Post was reviewed and updated to announce support of Prediction Probabilities for Classification problems using Amazon Redshift ML. Amazon Redshift is a fast, petabyte-scale cloud data warehouse data warehouse delivering the best price–performance. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. […]

How the Allen Institute uses Amazon EMR and AWS Step Functions to process extremely wide transcriptomic datasets
This is a guest post by Gautham Acharya, Software Engineer III at the Allen Institute for Brain Science, in partnership with AWS Data Lab Solutions Architect Ranjit Rajan, and AWS Sr. Enterprise Account Executive Arif Khan. The human brain is one of the most complex structures in the universe. Billions of neurons and trillions of […]