AWS Big Data Blog
Ensure availability of your data using cross-cluster replication with Amazon OpenSearch Service
Amazon OpenSearch Service is a fully managed service that you can use to deploy and operate OpenSearch and legacy Elasticsearch clusters, cost-effectively, at scale in the AWS Cloud. The service makes it easy for you to perform interactive log analytics, real-time application monitoring, website search, and more by offering the latest versions of OpenSearch, support for 19 versions of Elasticsearch (1.5 to 7.10 versions), and visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5 to 7.10 versions).
OpenSearch Service announced the support of cross-cluster replication on October 5, 2021. With cross-cluster replication for OpenSearch Service, you can replicate indices at low latency from one domain to another in the same or different AWS Regions without needing additional technologies. Cross-cluster replication provides sequential consistency while continuously copying data from the leader index to the follower index. Sequential consistency ensures the leader and the follower return the same result set after operations are applied on the indices in the same order. Cross-cluster replication is designed to minimize delivery lag between the leader and the follower index. Typical delivery times are less than a minute. You can continuously monitor the replication status via APIs. Additionally, if you have indices that follow an index pattern, you can create automatic follow rules and they will be automatically replicated.
In this post, we show you how to use these features to ensure availability of your data using cross-cluster replication with OpenSearch Service.
Benefits of cross-cluster replication
Cross-cluster replication is helpful for use cases regarding data proximity, disaster recovery, and multi-cluster patterns.
Data proximity helps reduce latency and response time by bringing the data closer to your user or application server. For example, you can replicate data from one Region, us-west-2 (leader), to multiple Regions across the globe acting as followers, eu-west-1, ap-south-1, ca-central-1, and so on, where the follower can poll the leader to sync new or updated data in the leader. In the following diagram, data is replicated from one production cluster in us-west-2 to multiple locally available clusters near the user or application.
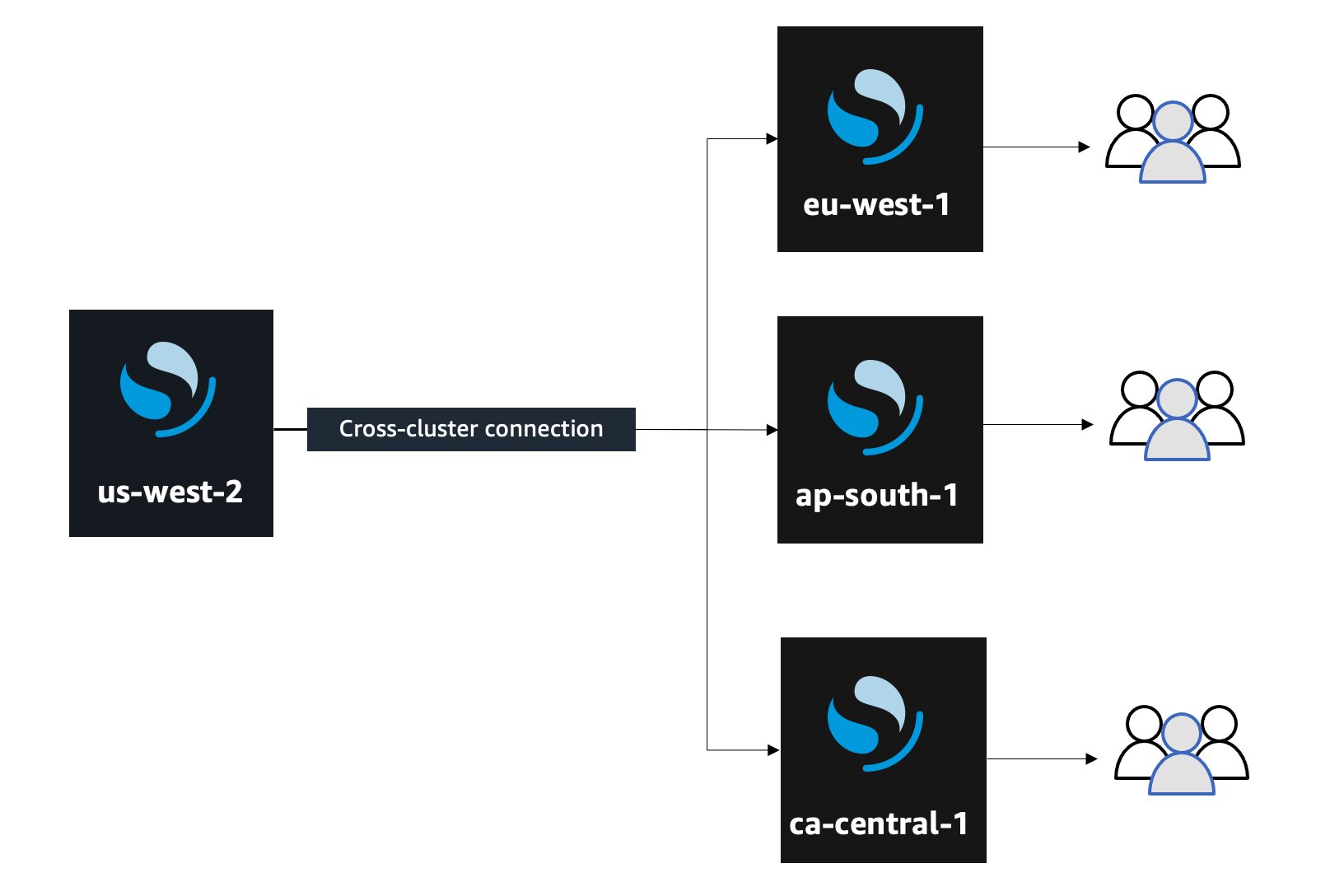
In the case of disaster recovery, you can have one or more follower clusters in the same Region or different Regions, and as long as you have one active cluster, you can serve read requests to the users. In the following diagram, data is replicated from one production cluster to two different disaster recovery clusters.
As of today, cross-cluster replication supports active/active read and active/passive write, as shown in the following diagram.

With this implementation, you can solve the problem of read if your leader goes down, but what about write? As of this writing, cross-cluster replication doesn’t support any kind of failover mechanism to make your follower the leader. In this scenario, you might need to do some extra housekeeping to make your follower domain become the leader and start accepting write requests. This post shows the steps to set up cross-cluster replication and minimize downtime by advancing your follower to be leader.
Set up cross-cluster replication
To set up cross-cluster replication, complete the following steps:
- Create two clusters across two Regions, for example
leader-east(leader) andfollower-west(follower).
Cross-cluster replication works on a pull model, where the user creates an outbound connection at the follower domain, and the follower keeps polling the leader to sync with new or updated documents for an index. - Go to the follower domain (
follower-west) and create a request for an outbound connection. Specify the alias for this connection asfollower-west. - Go to the leader domain, locate the inbound connection, and approve the incoming connection from
follower-west. - Edit the security configuration and add the following access policy to allow
ESCrossClusterGetin the leader domain, which isleader-east: - Create a leader index (on the leader domain), or ignore this step if you already have an index to replicate:
- Navigate to OpenSearch Dashboards for the follower-west domain.
- On the Dev Tools tab, run the following command (or use curl to connect directly):
- Confirm the replication:
- Index some documents in the leader index; the following command indexes documents to the catalog
indexwithid:1: - Now go to follower domain and confirm the documents are replicated by running the following search query:
Pause and stop the replication
When your replication is running, you can use these steps to pause and stop the replication.
You can use the following API to pause the replication, for example, while you debug an issue or load on the leader. Make sure to add an empty body with the request.
If you pause the replication, you must resume it within 12 hours. If you fail to resume it within 12 hours, you must stop replication, delete the follower index, and restart replication of the leader.
Stopping the replication makes the follower index unfollow the leader and become a standard index. Use the following code to stop replication:
Note that you can’t restart replication to this index after you stop it.
Auto-follow
You can define a set of replication rules against a single leader domain that automatically replicates indexes that match a specified pattern.
When an index on the leader domain matches one of the patterns (for example, logstash-*), a matching follower index is created on the follower domain. The following code is an example replication rule for auto-follow:
Delete the replication rule to stop replicating new indexes that match the pattern:
Monitor cross-cluster replication metrics
OpenSearch Service provides metrics to monitor cross-cluster replication that can help you know the status of the replication along with its performance. For example, ReplicationRate can help you understand the average rate of replication operations per second, and ReplicationNumSyncingIndices can help you know the number of indexes with the replication status SYNCING. For more details about all the metrics provided by OpenSearch Service for cross-cluster replication, refer to Cross-cluster replication metrics.
Recovering from failure
At this point, we have two OpenSearch Service domains running in two different Regions. Let’s consider a scenario in which some disastrous event happens in the Region with your leader domain and the leader goes down. At this point, you can still serve read traffic from the follower domain, but no additional updates are applied because the follower can’t read from the leader. In this scenario, you can use the following steps to advance your follower to be leader:
- Go to your follower domain and stop replication:
After replication stops on the follower domain, your follower index acts as a normal index.
- At this point, you can start sending write traffic to the follower.
This way, you can advance your follower domain to become leader and route your write traffic to the follower, which helps avoid the data loss for new sets of changes and updates.
Keep in mind that there is a small lag (less than a minute) between the leader-follower sync. Additionally, there could be small amount of data loss in the follower domain that was indexed to the leader and not synced to the follower (especially when the leader went down and the follower didn’t have a chance to poll the changes and updates). For this scenario, you should have a mechanism in your ingest pipeline to replay the data to the follower when your leader goes down.
Now, what if the leader comes back online after a certain period of time. At this time, you can’t start the replication again from your follower to sync the delta to the leader. Even if you try to set up the replication from follower to leader, it will fail with an error. After you have used an index for a leader-follower connection, you can’t use same index again to create a new replication. So, what do you do now?
In this scenario, you can use the following steps to set up a leader-follower connection in the opposite direction:
- Delete the index from the old leader.
- Set up cross-Region replication in the opposite direction with your new leader (
follower-west) and new follower (leader-east). - Start the replication on the new follower (which was your old leader) and sync the data.
This runs the sync for all data again for that index, and may take time depending upon the size of the index because it will bootstrap the index and start the replication from scratch. Additionally, you will incur standard AWS data transfer costs for the data transferred with this replication. This way, you can advance your follower (follower-west) to be leader and make your leader (leader-east) the new follower.
Conclusion
In this post, we showed you how you can use cross-cluster replication to sync data between leader and follower indices. We also demonstrated how you can advance your follower to become leader in case your leader goes down. This can help you serve traffic in the event of any disaster scenarios.
If you have feedback about this post, submit your comments in the comments section. If you have questions about this post, start a new thread on the Amazon OpenSearch Service forum or contact AWS Support.
About the Author
 Prashant Agrawal is a Search Specialist Solutions Architect with OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Search Specialist Solutions Architect with OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.