AWS Big Data Blog
How Amplitude implemented natural language-powered analytics using Amazon OpenSearch Service as a vector database
This is a guest post by Jeffrey Wang, Co-Founder and Chief Architect at Amplitude in partnership with AWS.
Amplitude is a product and customer journey analytics platform. Our customers wanted to ask deep questions about their product usage. Ask Amplitude is an AI assistant that uses large language models (LLMs). It combines schema search and content search to provide a customized, accurate, low latency, natural language-based visualization experience to end customers. Ask Amplitude has knowledge of a user’s product, taxonomy, and language to frame an analysis. It uses a series of LLM prompts to convert the user’s question into a JSON definition that can be passed to a custom query engine. The query engine then renders a chart with the answer, as illustrated in the following figure.
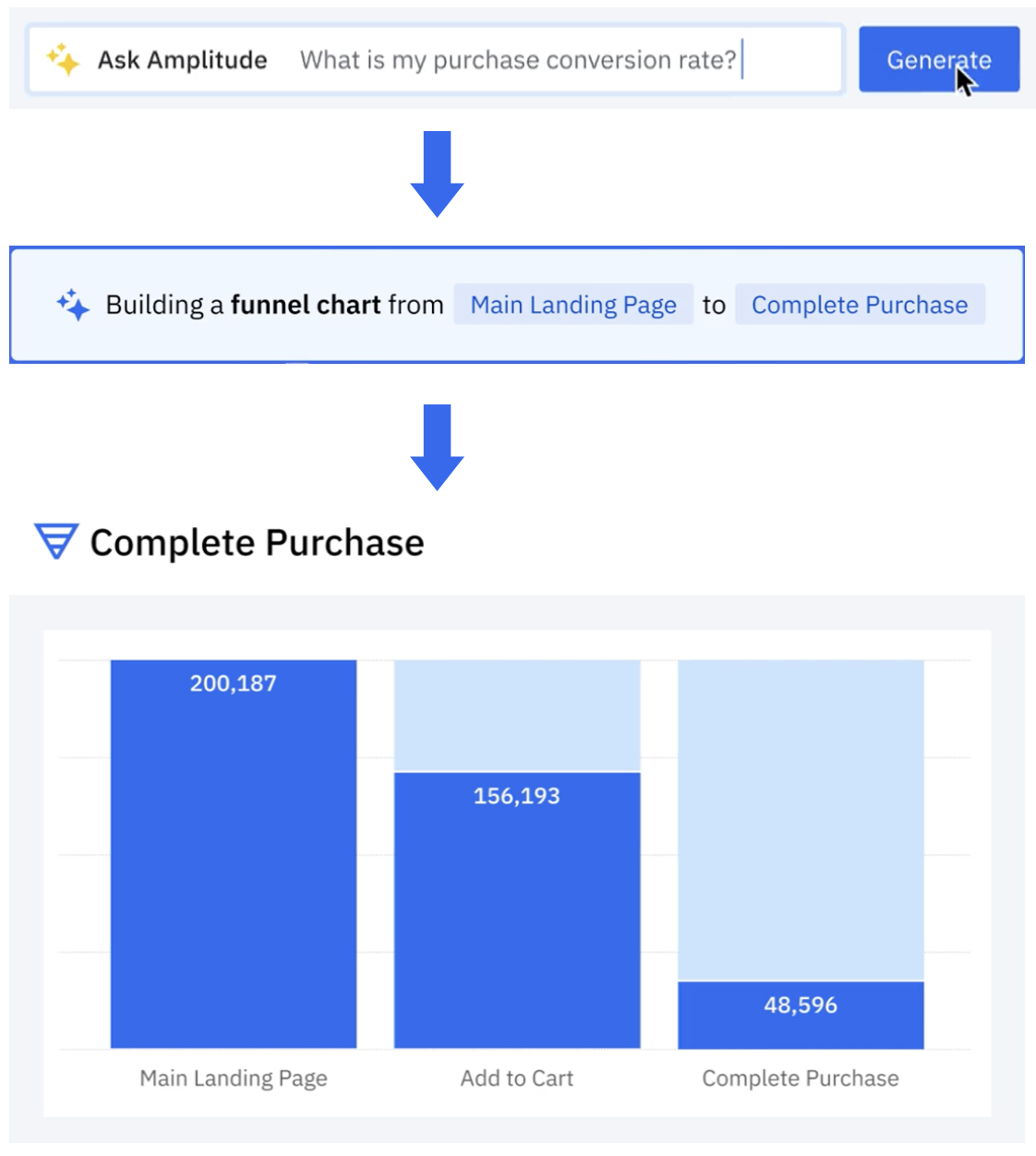
Amplitude’s search architecture evolved to scale, simplify, and cost-optimize for our customers, by implementing semantic search and Retrieval Augmented Generation (RAG) powered by Amazon OpenSearch Service. In this post, we walk you through Amplitude’s iterative architectural journey and explore how we address several critical challenges in building a scalable semantic search and analytics platform.
Our primary focus was on enabling semantic search capabilities and natural language chart generation at scale, while implementing a cost-effective multi-tenant system with granular access controls. A key objective was optimizing the end-to-end search latency to deliver rapid results. We also tackled the challenge of empowering end customers to securely search and use their existing charts and content for more sophisticated analytical inquiries. Additionally, we developed solutions to handle real-time data synchronization at scale, making sure constant updates to incoming data could be processed while maintaining consistently low search latency across the entire system.
RAG and vector search with Ask Amplitude
Let’s take a brief look at why Ask Amplitude uses RAG. Amplitude collects omnichannel customer data. Our end customers send data on user actions that are performed in their platforms. These actions are recorded as user-generated events. For example, in the case of retail and ecommerce customers, the types of user events include “product search,” “add to cart,” “checked out,” “shipping option,” “purchase,” and more. These events help define the customer’s database schema, outlining the tables, columns, and relationships between them. Let’s consider a user question such as “How many people used 2-day shipping?” The LLM needs to determine which elements of the captured user events are pertinent to formulating an accurate response to the query. When users ask a question to Ask Amplitude, the first step is to filter the relevant events from OpenSearch Service. Rather than feeding all event data to the LLM, we take a more selective approach for both cost and accuracy reasons. Because LLM usage is billed based on token count, sending complete event data would be unnecessarily expensive. More importantly, providing too much context can degrade the LLM’s performance—when faced with thousands of schema elements, the model struggles to reliably identify and focus on the relevant information. This information overload can distract the LLM from the core question, potentially leading to hallucinations or inaccurate responses. This is why RAG is the preferred approach. To retrieve the most relevant items from the product usage schema, a vector search is performed. This is effective even in situations when the question might not refer to the exact words that are in the customer’s schema. The following sections walk through the iterations of Amplitude’s search journey.
Initial solution: No semantic search
We used Amazon Relational Database Service (Amazon RDS) for PostgreSQL as the primary database to store our people, events, and properties data. However, as the following diagram shows, we had a separate, third-party store to implement keyword search. We had to bring in data from PostgreSQL to this third-party search index and keep it updated.
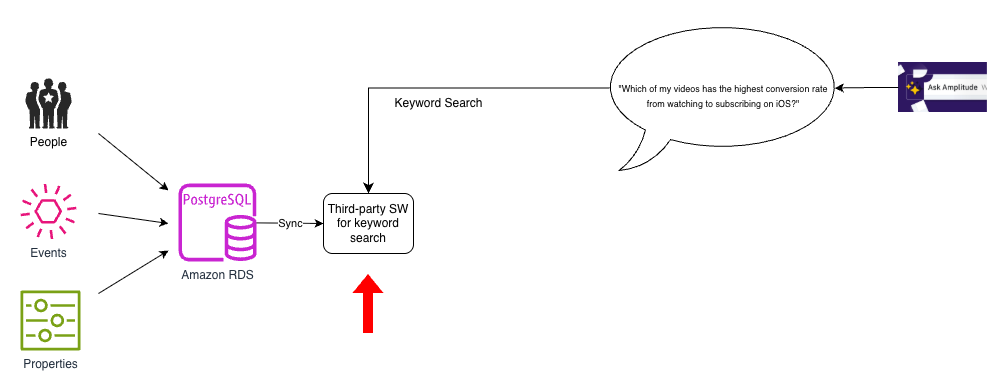
This architecture was simple but had two key shortcomings: there were no natural language capabilities in our search index, and the search index supported only keyword search.
Iteration 1: Brute force cosine similarity
To improve our search capability, we considered several prototypes. Because data volumes for most customers were not very large, it was quick to build a vector search prototype using PostgreSQL. We transformed user interaction data into vector embeddings and used array cosine similarity to compute similarity metrics across the dataset. This alleviated the need for custom similarity computation. The vector embeddings captured nuanced user behavior patterns using PostgreSQL capabilities without additional infrastructure overhead. This is generally called the brute force method, where an incoming query is matched against all embeddings to find its top (K) neighbors by a distance measure (cosine similarity in this case). The following diagram illustrates this architecture.
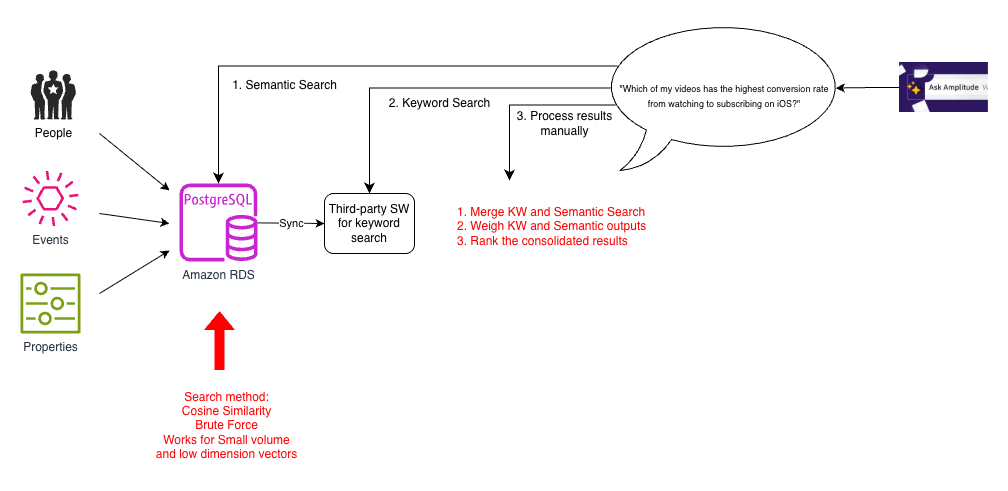
Enabling semantic search was a big improvement over traditional search for users who might use different terms to refer to the same concepts, such as “hours of video streamed” or “total watch time”. However, although this worked for small datasets, it was slow because the brute force method had to compute cosine similarity for all pairs of vectors. This was amplified as the number of elements in the events schema, the complexity of questions, and expectations of quality grew. Additionally, Ask Amplitude answers needed to blend both semantic and keyword search. To support this, each search query had to be implemented as a three-step process involving multiple calls to separate databases:
- Retrieve the semantic search results from PostgreSQL.
- Retrieve the keyword search results from our search index.
- In the application, semantic search results and keyword search results were combined using pre-assigned weights, and this output was dispatched to the Ask Amplitude UI.
This multi-step manual approach made the search process more complex.
Iteration 2: ANN search with pgvector
As Amplitude’s customer base grew, Ask Amplitude needed to scale to accommodate more customers and larger schemas. The goal was not just to answer the question at hand, but to teach the user how to build an end-to-end analysis by guiding them iteratively. To this end, the embeddings needed to store and index contextually rich semantic content. The team experimented with bigger, higher dimensionality embeddings and had anecdotal observations of vector dimensionality appearing to impact the effectiveness of the retrieval. Another requirement was to support multilingual embeddings.
To support a more scalable k-NN search, the team switched to pgvector, a PostgreSQL extension that provides powerful functionalities for with vectors in high-dimensional space. The following diagram illustrates this architecture.
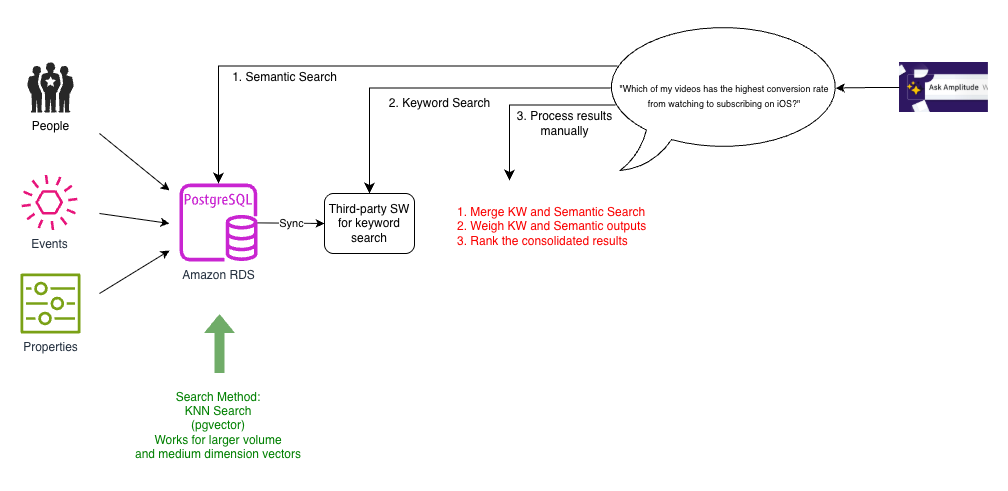
Pgvector was able to support k-nearest neighbor (k-NN) similarity search for larger dimensionality vectors. As the number of vectors grew, we switched to indexes that allowed approximate nearest neighbor (ANN) search, such as HNSW and IVFFlat.
For customers with larger schemas, calculating brute force cosine similarity was slow and expensive. We found a performance difference when we moved to ANN enabled by pgvector. However, we still needed to deal with the complexity introduced by the three-step process of querying PostgreSQL for semantic search, a separate search index for keyword search, and then stitching it all together.
Iteration 3: Dual sync to keyword and semantic search with OpenSearch Service
As the number of customers grew, so did the number of schemas. There were hundreds of millions of schema entries in the database, so we sought a performant, scalable, and cost-effective solution for k-NN search. We explored OpenSearch Service and Pinecone. We chose OpenSearch Service because we could combine keyword and vector search capabilities. This was convenient for four reasons:
- Simpler architecture – Positioning semantic search as a capability in an existing search solution, as we observed in OpenSearch Service, makes for a simpler architecture than treating it as a separate specialized service.
- Lower-latency search – The ability to effectively organize and catalog search data was fundamental to how we generated answers. Augmenting semantic search to our existing pipeline by combining both into one query provided lower latency querying.
- Reduced need for data synchronization – Keeping the database in sync with the search index was critical to the accuracy and quality of answers. With the alternatives that we looked at, we would have to maintain two synchronization pipelines, one for keyword search index and the other for a semantic search index, complicating the architecture and increasing the chances of experiencing out-of-sync results between keyword and semantic search results. Synchronizing them into one place was easier than synchronizing them into multiple places and then combining the signals at query time. With a combined keyword and vector search capabilities of OpenSearch Service, we now needed to synchronize only one primary database on PostgreSQL with the search index.
- Minimized performance impact to source data updates – We found that synchronizing data to another search index is a complex problem because our dataset changes constantly. With every new customer, we had hundreds of updates every second. We had to make sure the latency of these updates wasn’t impacted by the sync process. Collocating search data with vector embeddings obviated the need for multiple sync processes. This helped us avoid additional latency in the primary database, due to the sync processes encroaching upon database update traffic.
Although our previous third-party search engine specialized in fast ecommerce search, this wasn’t aligned with Amplitude’s specific needs. By migrating to OpenSearch Service, we simplified our architecture by reducing two synchronization processes to one. We phased out the current search platform gradually. This meant we temporarily continued to have two synchronization processes, one with current platform and another to the combined keyword and semantic search index on OpenSearch Service, as shown in the following diagram.
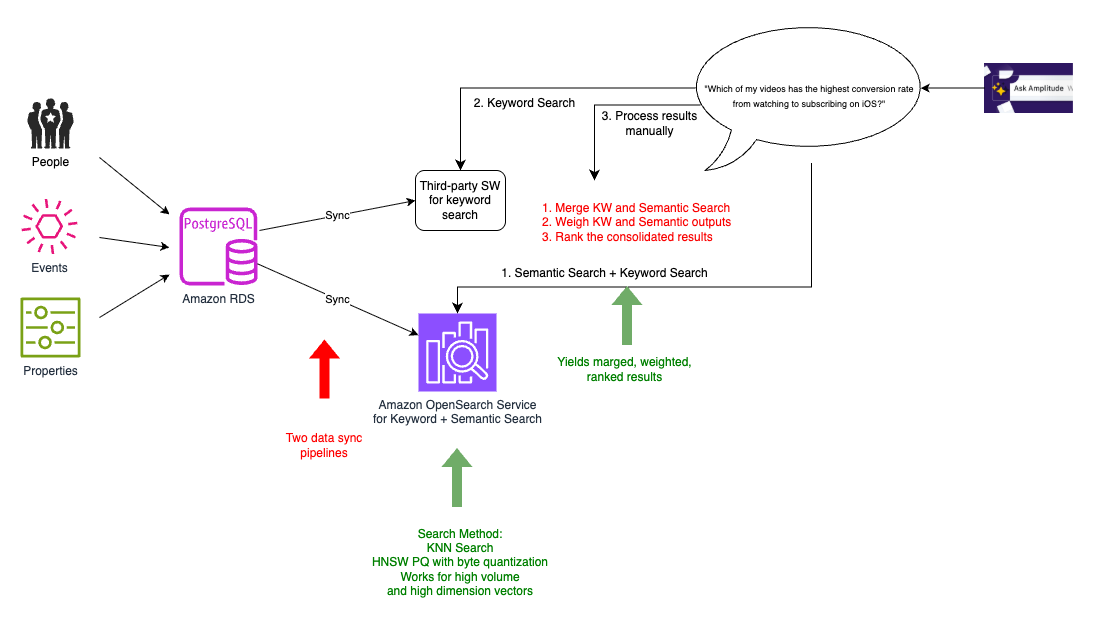
In addition to the pros of k-NN search identified in the previous iteration, moving to OpenSearch Service helped us realize three key benefits:
- Reduced latency – Instead of collocating the embeddings with primary data, we were able to collocate with our search index. The search index is where our application needed to run our queries to pick out user events that are relevant to the question being asked and send this as context sent to the LLM. Because the search text, metadata, and embeddings were all in one place, we needed only one hop for all our search requirements, thereby improving latency.
- Reduced compute power – We had anywhere between 5,000–20,000 elements in the user events schema. We didn’t need to send the entire schema to the LLM, because each user query required only 20–50 relevant elements. With the efficient filtering capabilities of OpenSearch Service, we were able to narrow down the vector search space by using tenant-specific metadata, significantly reducing compute requirements across our multi-tenant environment.
- Improved scalability – With OpenSearch Service, we could take advantage of additional capabilities such as HNSW product quantization (PQ) and byte quantization. Byte quantization made it possible to handle the scale of millions of vector entries with minimal reduction in recall, but with improvement to cost and latency.
However, in this interim solution, our data wasn’t fully migrated to OpenSearch Service yet. We still had the old pipeline along with the new pipeline, and had to perform dual syncing. This was only temporary, as we phased out the old search index, and the old pipeline served as a baseline to compare with in terms of performance and recall.
Iteration 4: Hybrid search with OpenSearch Service
In the final architecture, we were able to migrate all our data to OpenSearch Service, which also served as our vector database, as shown in the following diagram.
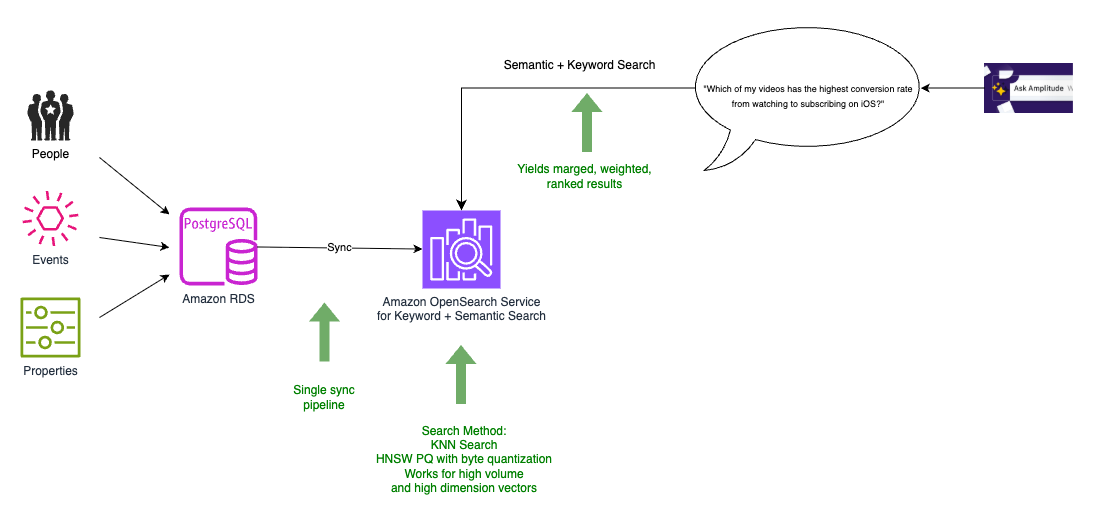
We now had to perform just one data synchronization from the PostgreSQL database to the combined search and vector index, allowing the resources on the database to focus on transactional traffic. OpenSearch Service provides merging, weighting, and ranking of the search results as part of the same query. This obviated the need to implement them as a separate module in our application, effectively resulting in a single, scalable hybrid search (combined keyword-based (lexical) search and vector-based (semantic) search). With OpenSearch Service, we could also experiment with the new integration with Amazon Personalize.
Evolving RAG to draw upon user-generated content
Our customers wanted to ask deeper questions about their product usage that couldn’t be answered just by looking at the schema (the structure and names of the data columns) alone. Simply knowing the column names in a database doesn’t necessarily reveal the meaning, values, or proper interpretation of that data. The schema alone provides an incomplete picture. A naïve approach would be to index and search all data values instead of searching just the schema. Amplitude avoids this for scalability reasons. The cardinality and volume of event data (potentially trillions of event records) makes indexing all values cost prohibitive. Amplitudes hosts about 20 million charts and dashboards across all Amplitude customers. This user-generated content is valuable. We observed that we can better understand the meaning and context by analyzing how other users have previously visualized data.For example, if a user asks about “2-day shipping,” Amplitude first checks if the data schema contains columns with relevant names like “shipping” or “shipping method”. If such columns exist, it then examines the potential values in those columns to find values related to 2-day shipping. Amplitude also searches user-created content (charts, dashboards, and more) to see if anyone else at the company has already visualized data related to 2-day shipping. If so, it can use that existing chart as a reference for how to properly filter and analyze the data to answer the question. To search this content efficiently, Amplitude employs a hybrid approach combining keyword and vector similarity (semantic) searches. For tenant isolation and pruning, we use metadata to filter by customer first, and then vector search.
Conclusion
In this post, we showed you how Amplitude built Ask Amplitude, an AI assistant using OpenSearch Service as a vector database to enable natural language queries of product analytics data. We evolved our system through four iterations, ultimately consolidating keyword and semantic search into OpenSearch Service, which simplified our architecture from multiple sync pipelines to one, reduced query latency by combining search operations, and enabled efficient multi-tenant vector search at scale using features like HNSW PQ and byte quantization. We extended the system beyond schema search to index 20 million user-generated charts and dashboards, using hybrid search to provide richer context for answering customer questions about product usage.
As natural language interfaces become increasingly prevalent, Amplitude’s iterative journey demonstrates the potential for harnessing LLMs and RAG using vector databases such as OpenSearch Service to unlock rich conversational customer experiences. By gradually transitioning to a unified search solution that combines keyword and semantic vector search capabilities, Amplitude overcame scalability and performance challenges while reducing architecture complexity. The final architecture using OpenSearch Service enabled efficient multi-tenancy and fine-grained access control and also facilitated low-latency hybrid search. Amplitude is able to deliver more natural and intuitive analytics capabilities to its customers by generating deeper insights and contextualizing data.
To learn more about how Ask Amplitude helps you express Amplitude-related concepts and questions in natural language, refer to Ask Amplitude. To get started with OpenSearch Service as a vector database, refer to Amazon OpenSearch Service as a Vector Database.