AWS Big Data Blog
How SumUp built a low-latency feature store using Amazon EMR and Amazon Keyspaces
This post was co-authored by Vadym Dolin, Data Architect at SumUp. In their own words, SumUp is a leading financial technology company, operating across 35 markets on three continents. SumUp helps small businesses be successful by enabling them to accept card payments in-store, in-app, and online, in a simple, secure, and cost-effective way. Today, SumUp card readers and other financial products are used by more than 4 million merchants around the world.
The SumUp Engineering team is committed to developing convenient, impactful, and secure financial products for merchants. To fulfill this vision, SumUp is increasingly investing in artificial intelligence and machine learning (ML). The internal ML platform in SumUp enables teams to seamlessly build, deploy, and operate ML solutions at scale.
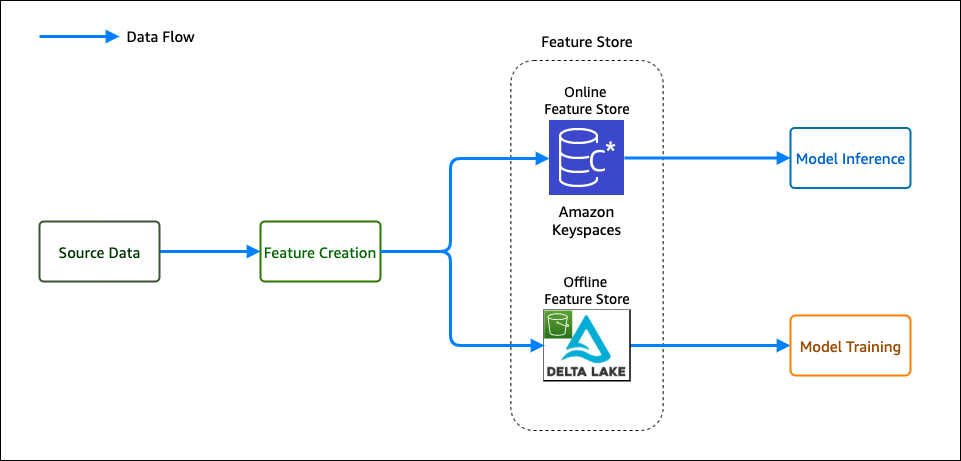
One of the central elements of SumUp’s ML platform is the online feature store. It allows multiple ML models to retrieve feature vectors with single-digit millisecond latency, and enables application of AI for latency-critical use cases. The platform processes hundreds of transactions every second, with volume spikes during peak hours, and has steady growth that doubles the number of transactions every year. Because of this, the ML platform requires its low-latency feature store to be also highly reliable and scalable.
In this post, we show how SumUp built a millisecond-latency feature store. We also discuss the architectural considerations when setting up this solution so it can scale to serve multiple use cases, and present results showcasing the setups performance.
Overview of solution
To train ML models, we need historical data. During this phase, data scientists experiment with different features to test which ones produce the best model. From a platform perspective, we need to support bulk read and write operations. Read latency isn’t critical at this stage because the data is read into training jobs. After the models are trained and moved to production for real-time inference, we have the following requirements for the platform change: we need to support low-latency reads and use only the latest features data.
To fulfill these needs, SumUp built a feature store consisting of offline and online data stores. These were optimized for the requirements as described in the following table.
| Data Store | History Requirements | ML Workflow Requirements | Latency Requirements | Storage Requirements | Throughput Requirements | Storage Medium |
| Offline | Entire History | Training | Not important | Cost-effective for large volumes | Bulk read and writes | Amazon S3 |
| Online | Only the latest Features | Inference | Single-digit millisecond | Not important | Read optimized | Amazon Keyspaces |
Amazon Keyspaces (for Apache Cassandra) is a serverless, scalable, and managed Apache Cassandra–compatible database service. It is built for consistent, single-digit-millisecond response times at scale. SumUp uses Amazon Keyspaces as a key-value pair store, and these features make it suitable for their online feature store. Delta Lake is an open-source storage layer that supports ACID transactions and is fully compatible with Apache Spark, making it highly performant at bulk read and write operations. You can store Delta Lake tables on Amazon Simple Storage Service (Amazon S3), which makes it a good fit for the offline feature store. Data scientists can use this stack to train models against the offline feature store (Delta Lake). When the trained models are moved to production, we switch to using the online feature store (Amazon Keyspaces), which offers the latest features set, scalable reads, and much lower latency.
Another important consideration is that we write a single feature job to populate both feature stores. Otherwise, SumUp would have to maintain two sets of code or pipelines for each feature creation job. We use Amazon EMR and create the features using PySpark DataFrames. The same DataFrame is written to both Delta Lake and Amazon Keyspaces, which eliminates the hurdle of having separate pipelines.
Finally, SumUp wanted to utilize managed services. It was important to SumUp that data scientists and data engineers focus their efforts on building and deploying ML models. SumUp had experimented with managing their own Cassandra cluster, and found it difficult to scale because it required specialized expertise. Amazon Keyspaces offered scalability without management and maintenance overhead. For running Spark workloads, we decided to use Amazon EMR. Amazon EMR makes it easy to provision new clusters and automatically or manually add and remove capacity as needed. You can also define a custom policy for auto scaling the cluster to suit your needs. Amazon EMR version 6.0.0 and above supports Spark version 3.0.0, which is compatible with Delta Lake.
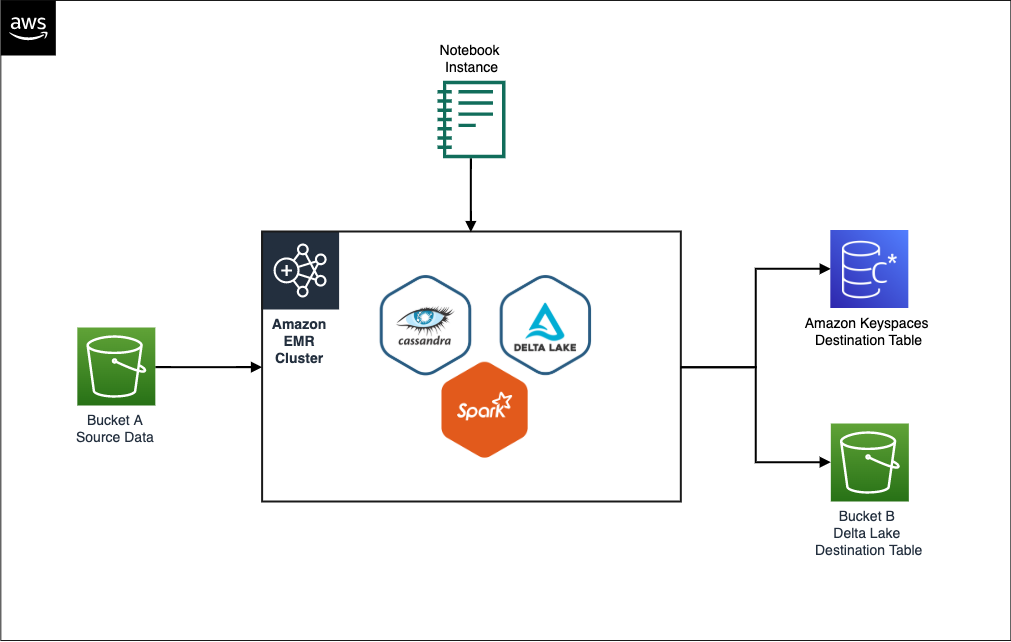
It took SumUp 3 months from testing out AWS services to building a production-grade feature store capable of serving ML models. In this post we share a simplified version of the stack, consisting of the following components:
- S3 bucket A – Stores the raw data
- EMR cluster – For running PySpark jobs for populating the feature store
- Amazon Keyspaces feature_store – Stores the online features table
- S3 Bucket B – Stores the Delta Lake table for offline features
- IAM role feature_creator – For running the feature job with the appropriate permissions
- Notebook instance – For running the feature engineering code
We use a simplified version of the setup to make it easy to follow the code examples. SumUp data scientists use Jupyter notebooks for exploratory analysis of the data. Feature engineering jobs are deployed using an AWS Step Functions state machine, which consists of an AWS Lambda function that submits a PySpark job to the EMR cluster.
The following diagram illustrates our simplified architecture.
Prerequisites
To follow the solution, you need certain access rights and AWS Identity and Access Management (IAM) privileges:
- An IAM user with AWS Command Line Interface (AWS CLI) access to an AWS account
- IAM privileges to do the following:
- Generate Amazon Keyspaces credentials
- Create a keyspace and table
- Create an S3 bucket
- Create an EMR cluster
- IAM Get Role
Set up the dataset
We start by cloning the project git repository, which contains the dataset we need to place in bucket A. We use a synthetic dataset, under Data/daily_dataset.csv. This dataset consists of energy meter readings for households. The file contains information like the number of measures, minimum, maximum, mean, median, sum, and std for each household on a daily basis. To create an S3 bucket (if you don’t already have one) and upload the data file, follow these steps:
- Clone the project repository locally by running the shell command:
- On the Amazon S3 console, choose Create bucket.
- Give the bucket a name. For this post, we use
featurestore-blogpost-bucket-xxxxxxxxxx(it’s helpful to append the account number to the bucket name to ensure the name is unique for common prefixes). - Choose the Region you’re working in.
It’s important that you create all resources in the same Region for this post. - Public access is blocked by default, and we recommend that you keep it that way.
- Disable bucket versioning and encryption (we don’t need it for this post).
- Choose Create bucket.
- After the bucket is created, choose the bucket name and drag the folders
DatasetandEMRinto the bucket.
Set up Amazon Keyspaces
We need to generate credentials for Amazon Keyspaces, which we use to connect with the service. The steps for generating the credentials are as follows:
- On the IAM console, choose Users in the navigation pane.
- Choose an IAM user you want to generate credentials for.
- On the Security credentials tab, under Credentials for Amazon Keyspaces (for Apache Cassandra), choose Generate Credentials.
A pop-up appears with the credentials, and an option to download the credentials. We recommend downloading a copy because you won’t be able to view the credentials again.We also need to create a table in Amazon Keyspaces to store our feature data. We have shared the schema for the keyspace and table in the GitHub project filesKeyspaces/keyspace.cqlandKeyspaces/Table_Schema.cql. - On the Amazon Keyspaces console, choose CQL editor in the navigation pane.
- Enter the contents of the file
Keyspaces/Keyspace.cqlin the editor and choose Run command. - Clear the contents of the editor, enter the contents of
Keyspaces/Table_Schema.cql, and choose Run command.
Table creation is an asynchronous process, and you’re notified if the table is successfully created. You can also view it by choosing Tables in the navigation pane.
Set up an EMR cluster
Next, we set up an EMR cluster so we can run PySpark code to generate features. First, we need to set up a trust store password. A truststore file contains the Application Server’s trusted certificates, including public keys for other entities, this file is generated by the provided script and we need to provide a password for protecting this file. Amazon Keyspaces provides encryption in transit and at rest to protect and secure data transmission and storage, and uses Transport Layer Security (TLS) to help secure connections with clients. To connect to Amazon Keyspaces using TLS, we need to download an Amazon digital certificate and configure the Python driver to use TLS. This certificate is stored in a trust store; when we retrieve it, we need to provide the correct password.
- In the file
EMR/emr_bootstrap_script.sh, update the following line to a password you want to use: - To point the bootstrap script to the one we uploaded to Amazon S3, update the following line to reflect the S3 bucket we created earlier:
- To update the app.config file to reflect the correct trust store password, in the file
EMR/app.config, update the value fortruststore-passwordto the value you set earlier: - In the file
EMR/app.config, update the following lines to reflect the Region and the user name and password generated earlier:We need to create default instance roles, which are needed to run the EMR cluster.
- Update the contents S3 bucket created in the pre-requisite section by dragging the EMR folder into the bucket again.
- To create the default roles, run the create-default-roles command:
Next, we create an EMR cluster. The following code snippet is an AWS CLI command that has Hadoop, Spark 3.0, Livy and JupyterHub installed. This also runs the bootstrapping script on the cluster to set up the connection to Amazon Keyspaces.
- Create the cluster with the following code. Provide the subnet ID to start a Jupyter notebook instance associated with this cluster, the S3 bucket you created earlier, and the Region you’re working in. You can provide the default Subnet, and to find this navigate to VPC>Subnets and copy the default subnet id.
Lastly, we create an EMR notebook instance to run the PySpark notebook Feature Creation and
loading-notebook.ipynb(included in the repo). - On the Amazon EMR console, choose Notebooks in the navigation pane.
- Choose Create notebook.
- Give the notebook a name and choose the cluster
emr_feature_store. - Optionally, configure the additional settings.
- Choose Create notebook.It can take a few minutes before the notebook instance is up and running.
- When the notebook is ready, select the notebook and choose either Open JupyterLab or Open Jupyter.
- In the notebook instance import, open the notebook
Feature Creation and loading-notebook.ipynb(included in the repo) and change the kernel to PySpark. - Follow the instructions in the notebook and run the cells one by one to read the data from Amazon S3, create features, and write these to Delta Lake and Amazon Keyspaces.
Performance testing
To test throughput for our online feature store, we run a simulation on the features we created. We simulate approximately 40,000 requests per second. Each request queries data for a specific key (an ID in our feature table). The process tasks do the following:
- Initialize a connection to Amazon Keyspaces
- Generate a random ID to query the data
- Generate a CQL statement:
- Start a timer
- Send the request to Amazon Keyspaces
- Stop the timer when the response from Amazon Keyspaces is received
To run the simulation, we start 245 parallel AWS Fargate tasks running on Amazon Elastic Container Service (Amazon ECS). Each task runs a Python script that makes 1 million requests to Amazon Keyspaces. Because our dataset only contains 5,560 unique IDs, we generate 1 million random numbers between 0–5560 at the start of the simulation and query the ID for each request. To run the simulation, we included the code in the folder Simulation. You can run the simulation in a SageMaker notebook instance by completing the following steps:
- On the Amazon SageMaker console, create a SageMaker notebook instance (or use an existing one).You can choose an ml.t3.large instance.
- Let SageMaker create an execution role for you if you don’t have one.
- Open the SageMaker notebook and choose Upload.
- Upload the Simulation folder from the repository. Alternatively, open a terminal window on the notebook instance and clone the repository
https://github.com/aws-samples/amazon-keyspaces-emr-featurestore-kit.git. - Follow the instructions and run the steps and cells in the
Simulation/ECS_Simulation.ipynbnotebook. - On the Amazon ECS console, choose the cluster you provisioned with the notebook and choose the Tasks tab to monitor the tasks.
Each task writes the latency figures to a file and moves this to an S3 location. When the simulation ends, we collect all the data to get aggregated stats and plot charts.
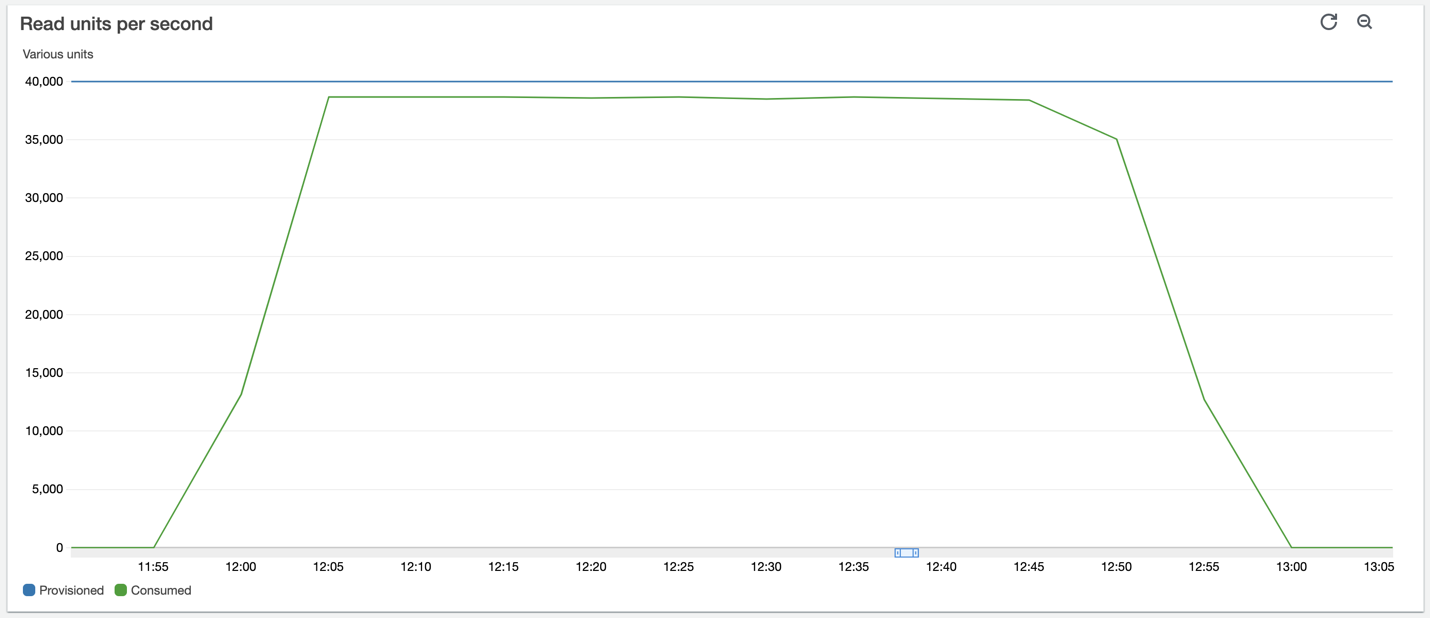
In our setup, we set the capacity mode for Amazon Keyspaces to Provisioned RCU (read capacity units) at 40000 (fixed). After we start the simulation, the RCU rise close to 40000. After we start the simulation, the RCU (read capacity units) rise close to 40000, and the simulation takes around an hour to finish, as illustrated in the following visualization.
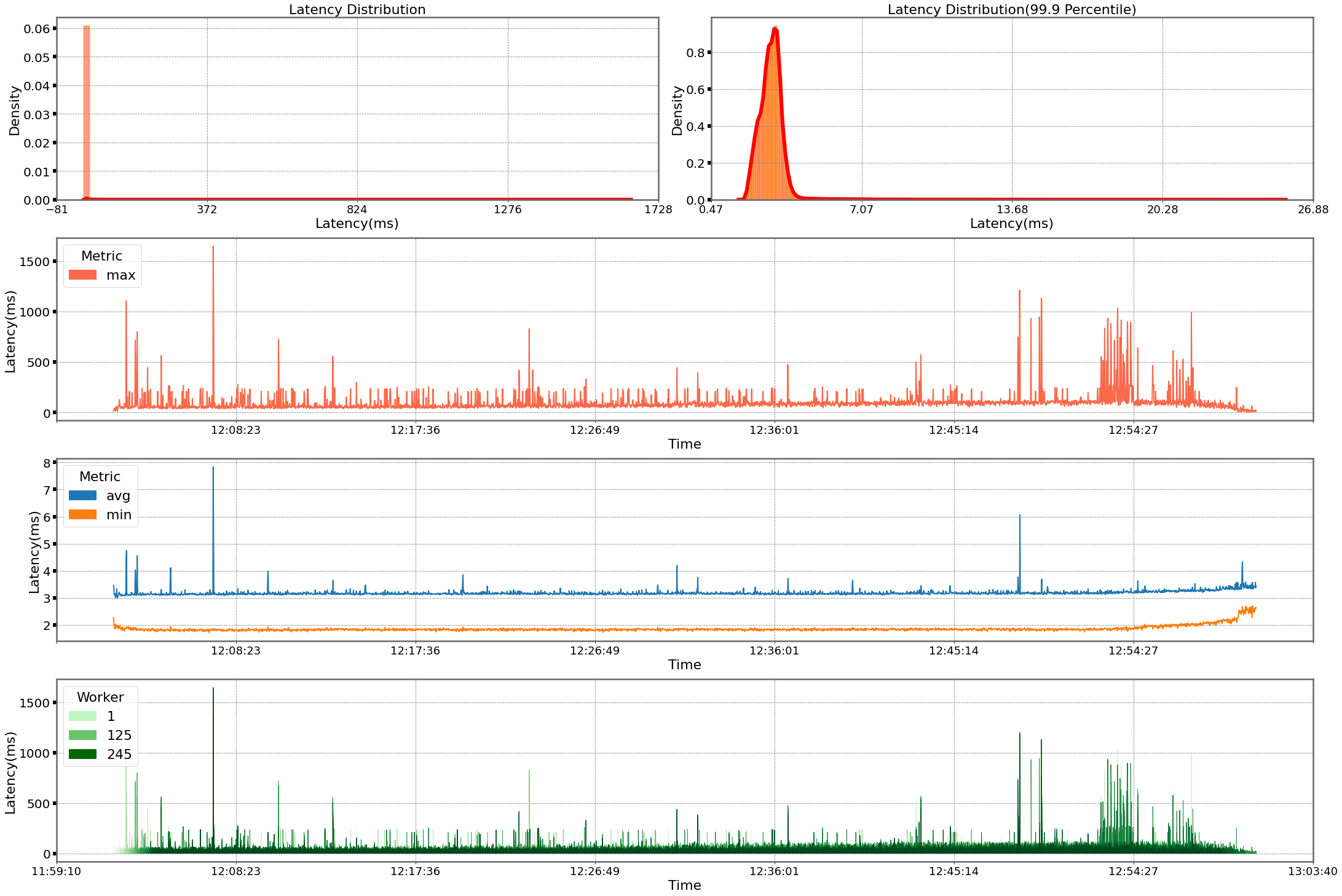
The first analysis we present is the latency distribution for the 245 million requests made during the simulation. Here the 99% percentile falls inside single-digit millisecond latency, as we would expect.
| Quantile | Latency (ms) |
| 50% | 3.11 |
| 90% | 3.61 |
| 99% | 5.56 |
| 99.90% | 25.63 |
For the second analysis, we present the following time series charts for latency. The chart at the bottom shows the raw latency figures from all the 245 workers. The chart above that plots the average and minimum latency across all workers grouped over 1-second intervals. Here we can see both the minimum and the average latency throughout the simulation stays below 10 milliseconds. The third chart from the bottom plots maximum latency across all workers grouped over 1-second intervals. This chart shows occasional spikes in latency but nothing consistent we need to worry about. The top two charts are latency distributions; the one on the left plots all the data, and the one on the right plots the 99.9% percentile. Due to the presence of some outliers, the chart on the left shows a peak close to zero and a very tailed distribution. After we remove these outliers, we can see in the chart on the right that 99.9% of requests are completed in less than 5.5 milliseconds. This is a great result, considering we sent 245 million requests.
Cleanup
Some of the resources we created in this blogpost would incur costs if left running. Remember to terminate the EMR cluster, empty the S3 bucket and delete it, delete the Amazon KeySpaces table. Also delete the SageMaker and Amazon EMR notebooks. The Amazon ECS cluster is billed on tasks and would not incur any additional costs.
Conclusion
Amazon EMR, Amazon S3, and Amazon Keyspaces provide a flexible and scalable development experience for feature engineering. EMR clusters are easy to manage, and teams can share environments without compromising compute and storage capabilities. EMR bootstrapping makes it easy to install and test out new tools and quickly spin up environments to test out new ideas. Having the feature store split into offline and online store simplifies model training and deployment, and provides performance benefits.
In our testing, Amazon Keyspaces was able to handle peak throughput read requests within our desired requirement of single digit latency. It’s also worth mentioning that we found the on-demand mode to adapt to the usage pattern and an improvement in read/write latency a couple of days from when it was switched on.
Another important consideration to make for latency-sensitive queries is row length. In our testing, tables with lower row length had lower read latency. Therefore, it’s more efficient to split the data into multiple tables and make asynchronous calls to retrieve it from multiple tables.
We encourage you to explore adding security features and adopting security best practices according to your needs and potential company standards.
If you found this post useful, check out Loading data into Amazon Keyspaces with cqlsh for tips on how to tune Amazon Keyspaces, and Orchestrate Apache Spark applications using AWS Step Functions and Apache Livy on how to build and deploy PySpark jobs.
About the authors
 Shaheer Mansoor is a Data Scientist at AWS. His focus is on building machine learning platforms that can host AI solutions at scale. His interest areas are ML Ops, Feature Stores, Model Hosting and Model Monitoring.
Shaheer Mansoor is a Data Scientist at AWS. His focus is on building machine learning platforms that can host AI solutions at scale. His interest areas are ML Ops, Feature Stores, Model Hosting and Model Monitoring.
 Vadym Dolinin is a Machine Learning Architect in SumUp. He works with several teams on crafting the ML platform, which enables data scientists to build, deploy, and operate machine learning solutions in SumUp. Vadym has 13 years of experience in the domains of data engineering, analytics, BI, and ML.
Vadym Dolinin is a Machine Learning Architect in SumUp. He works with several teams on crafting the ML platform, which enables data scientists to build, deploy, and operate machine learning solutions in SumUp. Vadym has 13 years of experience in the domains of data engineering, analytics, BI, and ML.
 Oliver Zollikofer is a Data Scientist at AWS. He enables global enterprise customers to build and deploy machine learning models, as well as architect related cloud solutions.
Oliver Zollikofer is a Data Scientist at AWS. He enables global enterprise customers to build and deploy machine learning models, as well as architect related cloud solutions.